PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili

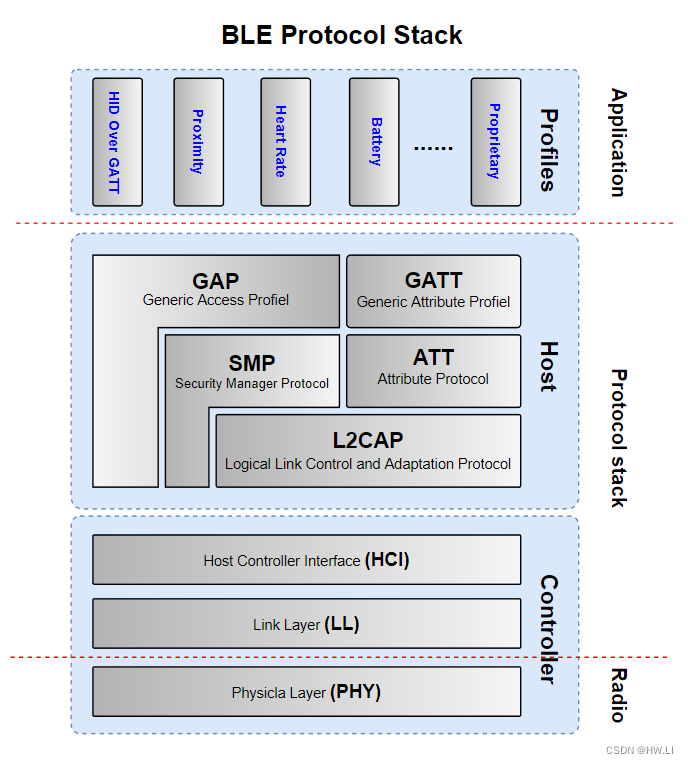
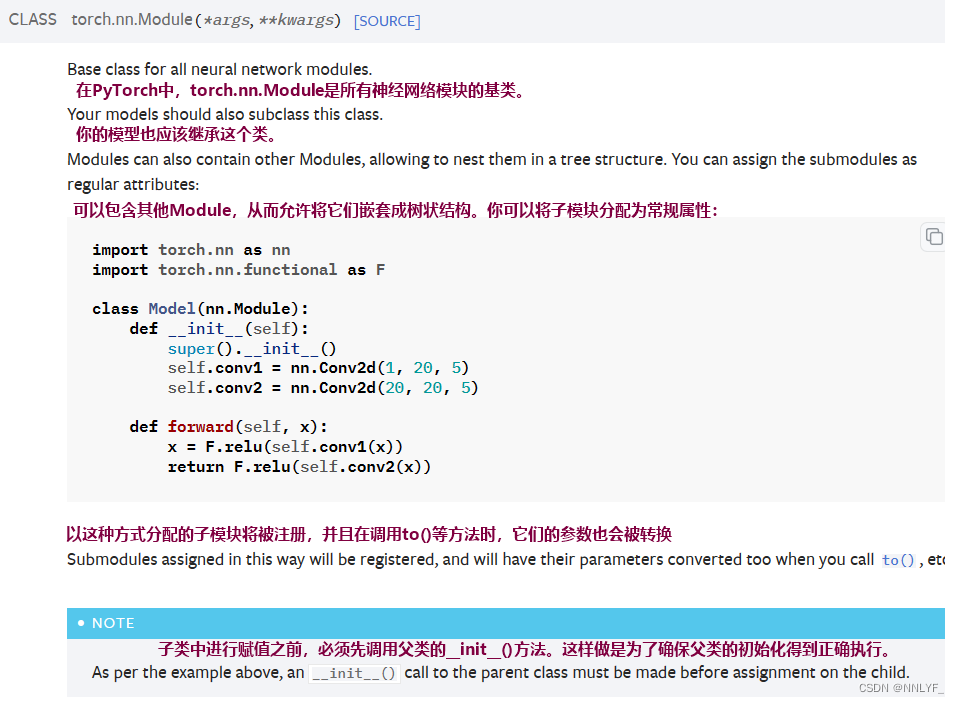
一、神经网络的基本骨架 --nn.Module
Neutral network
torch.nn — PyTorch 2.2 documentation

*
import torch
from torch import nnclass xiaofan(nn.Module):def __init__(self):super().__init__()def forward(self,input):output = input + 1return outputXiaofan = xiaofan()
x=torch.tensor(1.0)
output = Xiaofan(x)
print(output)
# 搭建神经网络
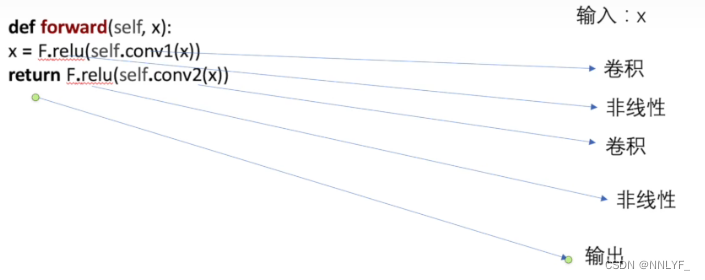
class Xiaofan(nn.Module):def __init__(self):super(Xiaofan,self).__init__()self.relu1=ReLU()def forward(self,input):output=self.relu1(input)return output
xiaofan=Xiaofan()
Python中,类是对象的模板,而实例是根据类创建的具体对象。
变量xiaofan就代表了这个Xiaofan类的实例,你可以通过这个变量来访问实例的属性和方法。

新项目创建时要注意环境的选择

ctrl + p 查看函数所需参数

使用tensorboard可视化时,如果路径里哟空格要加上双引号以免报错
二、卷积层(Convolution Layers)
图像处理中,卷积是一种数学操作,常用于图像的滤波、特征提取和图像增强等任务。卷积操作可以看作是两个函数之间的一种数学运算,用于描述一个函数与另一个函数的重叠部分。
-
图像滤波:通过应用不同的卷积核(也称为滤波器)对图像进行滤波,可以实现图像的模糊、锐化、边缘检测等效果。例如,高斯滤波器用于模糊图像,而Sobel、Prewitt等滤波器用于边缘检测。
-
特征提取:卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像分类、物体检测和图像分割等任务。CNN中的卷积层通过学习不同的卷积核,可以有效地提取图像中的特征。
-
图像增强:通过设计特定的卷积核,可以增强图像的某些特性,如增强边缘、增加图像的对比度等。
torch.nn.functional.conv2d — PyTorch 2.2 documentation

1.卷积核
卷积核是卷积神经网络(Convolutional Neural Network,CNN)中的一个重要概念,也称为滤波器(filter)或卷积矩阵(convolution matrix)。它是CNN中用于提取图像特征的关键组件。
卷积核可以理解为一个小型的矩阵,通常是二维的,其大小可以根据具体任务和网络设计进行定义。卷积核中的每个元素(权重)表示了对应位置上的像素与输出特征图对应位置上的连接权重。通过将卷积核与输入图像进行卷积操作,可以在不同位置提取局部特征并生成对应的输出特征图。
在卷积操作中,卷积核滑动(或移动)到输入图像的每个位置,并与输入图像对应的局部区域进行逐元素相乘,然后将所有相乘的结果相加,得到输出特征图中对应位置的值。这个过程可以看作是对局部像素进行加权求和,从而捕捉到输入图像的局部特征。
2. input
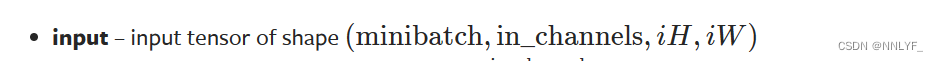
-
minibatch:表示每次训练时输入的样本数量。例如,如果一个minibatch包含64个样本,则minibatch的值为64。
-
in_channels:表示输入张量的通道数,也即输入图像的颜色通道数。对于彩色图像,通常有3个通道(红色、绿色和蓝色),所以in_channels为3;对于灰度图像,通常只有1个通道。
-
iH:表示输入图像的高度(Height)。
-
iW:表示输入图像的宽度(Width)。
假设我们有一个minibatch包含32个样本,每个样本是一个彩色图像,图像的尺寸是224x224,那么输入张量的形状可以表示为:
[ (32, 3, 224, 224) ]
这意味着这个输入张量包含32个样本,每个样本有3个颜色通道,图像的高度和宽度分别为224个像素。
3.stride (步幅)
指卷积核在对输入进行卷积操作时每次移动的步长。具体来说,stride决定了在进行卷积操作时,卷积核在水平和垂直方向上移动的距离。
stride可以是一个单独的数值,也可以是一个包含两个元素的元组(sH,sW),分别表示在垂直方向(Height)和水平方向(Width)上的步幅。例如,如果stride为2,则在进行卷积操作时,卷积核每次水平和垂直方向上移动两个像素。
设置不同的stride值会影响到卷积操作后输出的特征图的大小。一般来说,较大的stride值会导致输出特征图尺寸减小,而较小的stride值会导致输出特征图尺寸保持较大。
默认情况下,stride通常设置为1,这意味着卷积核在对输入进行卷积操作时每次水平和垂直方向上移动一个像素。这样可以确保输出特征图具有与输入特征图相似的空间尺寸。
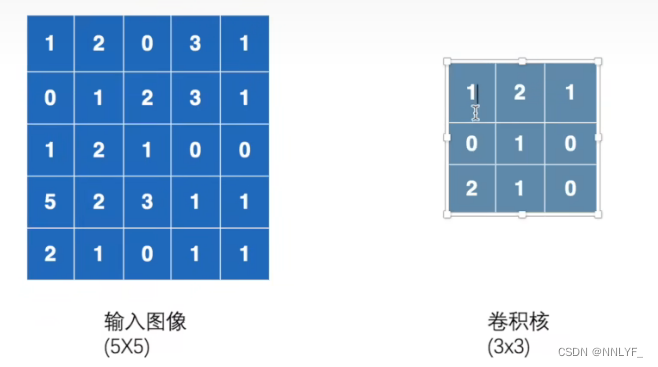

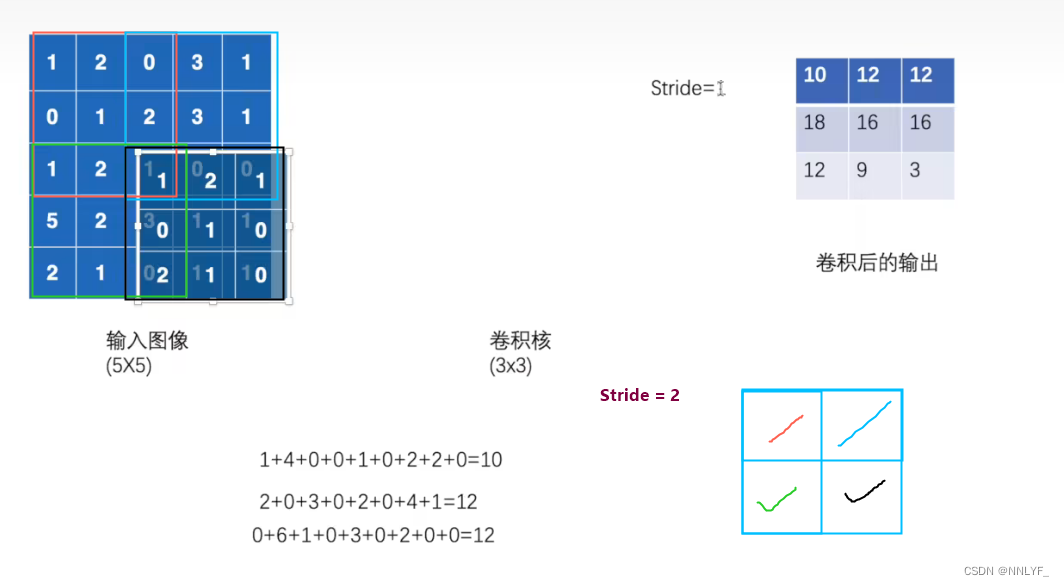
代码实现:
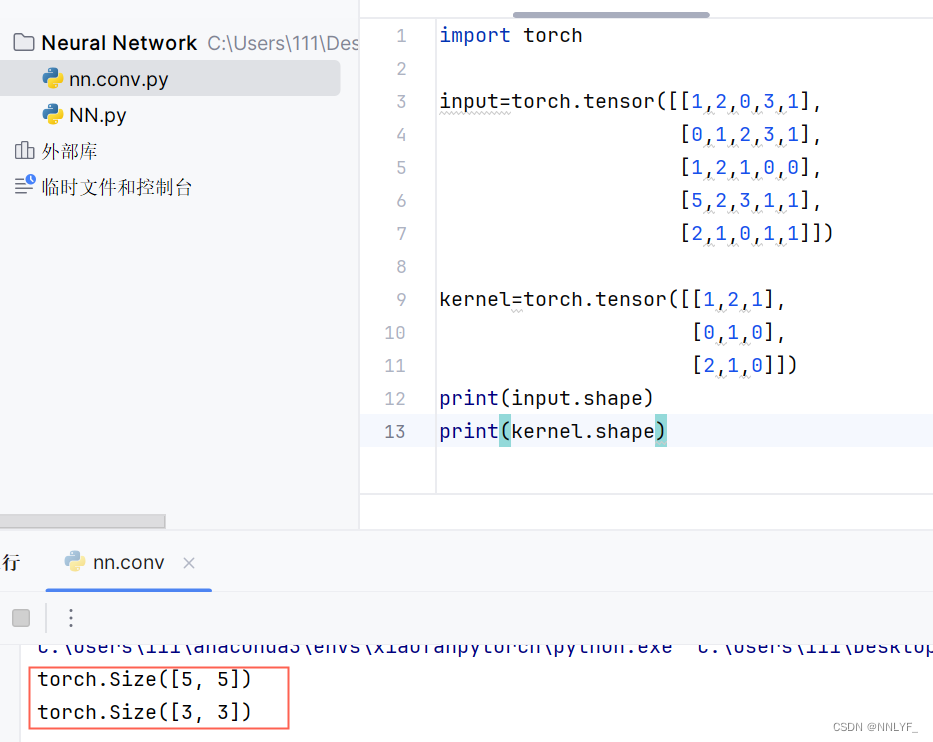
输入格式不符合
使用torch.reshape函数进行格式修改
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])kernel=torch.tensor([[1,2,1],[0,1,0],[2,1,0]])input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))print(input.shape)
print(kernel.shape)output = F.conv2d(input,kernel,stride=1)
output2=F.conv2d(input,kernel,stride=2)
print (output)
print(output2)测试:

4.padding(填充)

padding(填充)是一种在输入数据周围添加额外值(通常是0)的技术。padding可以用于卷积神经网络(CNN)中的卷积操作,以及其他一些涉及边缘数据的操作中。在PyTorch中,padding可以通过卷积层的参数进行设置。
在给定的情况下,对于padding参数,可以有三种不同的设置方式:
-
字符串
{‘valid’, ‘same’}:这两个字符串分别表示“有效填充”和“相同填充”。-
padding='valid':表示有效填充,即不进行填充操作。在这种情况下,输入数据的周围不会进行额外的填充,卷积操作会尽可能多地覆盖输入数据,输出尺寸会受到卷积核大小和步幅的影响而变化。 -
padding='same':表示相同填充,即填充输入数据以使输出具有与输入相同的形状。在这种情况下,会自动计算所需的填充量,以确保卷积操作后输出的尺寸与输入相同。但需要注意的是,这种模式下不支持除了步幅为1之外的其他步幅值。
-
-
单个数字:表示在每个维度上应用相同的填充量。
-
元组
(padH, padW):表示在高度和宽度维度上分别应用不同的填充量。
使用padding的目的通常是确保在卷积操作中能够处理边缘像素,并且控制卷积后输出的尺寸。填充可以帮助保留输入数据的空间信息,减少边缘效应对模型性能的影响。
output3=F.conv2d(input,kernel,stride=1,padding=1)
print(output3)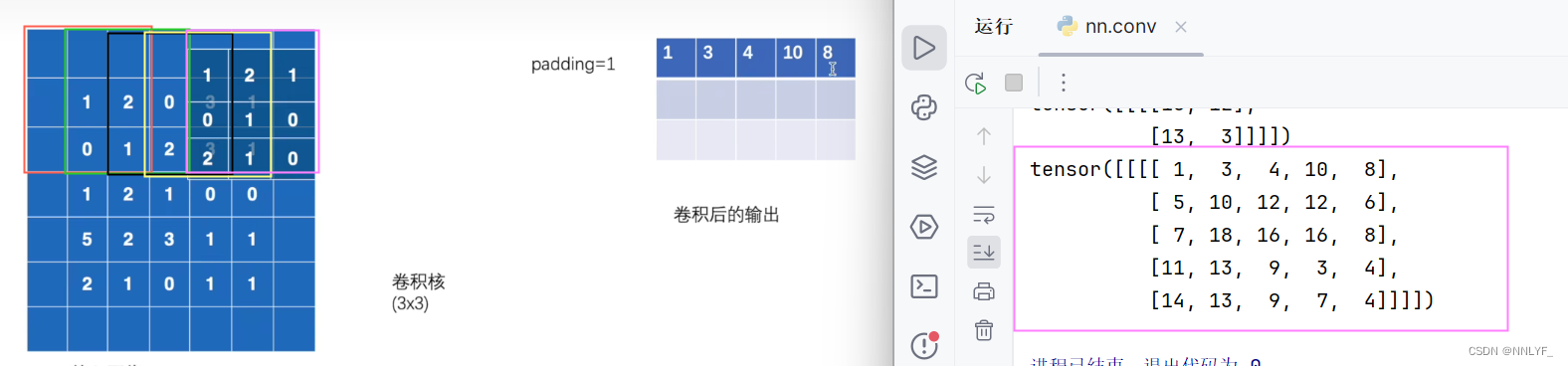
三、Pooling layers (池化层)
池化层(Pooling Layer)是深度学习神经网络中的一种常用层,通常用于减少特征图的尺寸,从而降低模型的复杂度并提高计算效率。池化层通过在局部区域上进行聚合操作来减少特征图的空间尺寸,从而保留主要特征并减少计算量。
常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。在最大池化中,每个池化窗口内的最大值被保留,而在平均池化中,每个池化窗口内的平均值被计算并保留。
池化层的主要作用包括:
-
降维: 池化层可以通过降低特征图的空间维度来降低模型的计算复杂度,从而加快训练速度和推理速度。
-
不变性: 池化层可以增加模型对输入的平移、缩放和旋转等变换的不变性,从而提高模型的泛化能力。
-
减少过拟合: 池化层可以通过降低特征图的维度和参数数量来减少模型的过拟合风险,从而提高模型的泛化能力。
池化层通常与卷积层交替使用,构成深度神经网络的基本结构。在卷积神经网络(CNN)中,池化层通常位于卷积层之后,用于逐渐减少特征图的空间尺寸,并逐渐提取更高级别的特征。

1.ceil_mode
ceil_mode 参数是一个布尔值,用于确定计算输出形状时是使用向下取整(floor)还是向上取整(ceil)的方式。当 ceil_mode 设置为 True 时,会使用向上取整来计算输出形状,而当设置为 False(默认值)时,则使用向下取整。


![]()
N: 表示输入的样本数量(batch size)。在一个批次(batch)中可能有多个样本,N就代表了批次中样本的数量。C: 表示输入特征图的通道数(channels)。通道数即特征图的深度,每个通道包含了一种特征的响应图。Hin: 表示输入特征图的高度(height)。Win: 表示输入特征图的宽度(width)。
代码实现:
input = torch.tensdor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])
input = torch.reshape(input,(-1,1,5,5))
reshape中参数的设定:
1.将 N 设置为 -1 , PyTorch 会根据其他维度的大小自动推断批量大小。
具体来说,你的 input 张量原本是一个形状为 (5, 5) 的二维张量,然后你将其调整为一个四维张量,其中第一个维度(批量维度)的大小由 -1 来表示,PyTorch 将根据其他维度的大小自动推断该维度的大小。
在这种情况下,PyTorch 将会根据输入张量中的元素数量以及其他维度的大小来确定批量大小。因为输入张量中共有 25 个元素(5 * 5),而其他维度的大小已经被指定为 (1, 5, 5),所以 PyTorch 会自动计算出批量大小为 1。因此,最终的形状将是 (1, 1, 5, 5)。
总之,将 N 设置为 -1 的意思是让 PyTorch 自动推断批量大小,以保持张量的总元素数量不变。
2.将C设置为1:
深度学习中,特别是在使用卷积神经网络 (CNN) 进行图像处理任务时,通常将输入张量的每个通道视为一张图像。因此,如果你将一个输入张量的通道数设置为 3,那么可以将其理解为输入数据由三张图像组成。
通常情况下,这三张图像可以表示为彩色图像的不同通道(例如红、绿、蓝),或者是不同的特征图,每个特征图对应网络学习到的不同特征。
因此,你可以将输入张量的通道数视为输入数据包含的图像数量,每个通道代表其中的一张图像。
import torch
from torch import nn
from torch.nn import MaxPool2dinput = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])
input = torch.reshape(input,(-1,1,5,5))class Xiaofan(nn.Module):def __init__(self):super().__init__()self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)def forward(self,input):output=self.maxpool1(input)return outputxiaofan=Xiaofan()
output=xiaofan(input)
print(output)

四、非线性激活
激活函数:
在神经网络中,激活函数通常被应用于神经元的输出,用于将神经元的输入转换为输出。它的作用是引入非线性映射,从而使得神经网络可以学习和表示复杂的非线性关系,例如分类、回归等任务。
1.ReLU(修正线性单元)
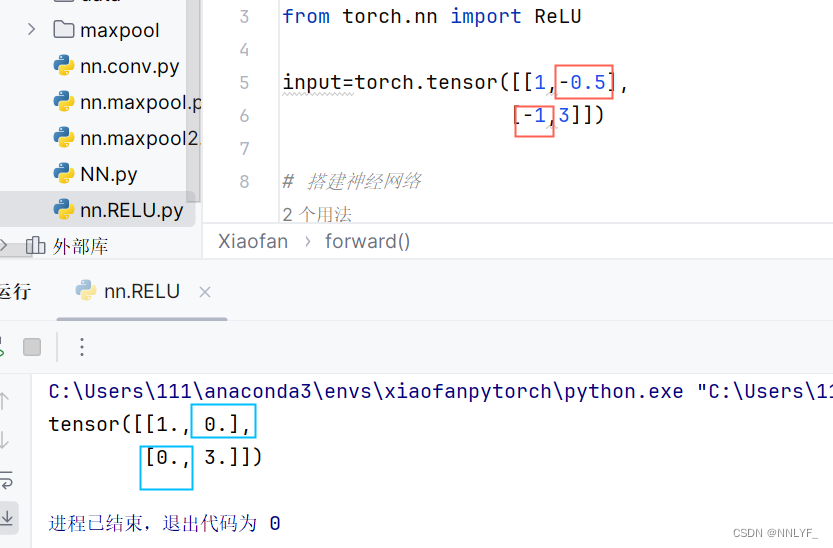
它的作用是将输入的每个元素与0比较,如果大于0,则输出原始值,否则输出0。换句话说,ReLU函数将负数部分截断为0,保留正数部分不变。




import torch
from torch import nn
from torch.nn import ReLUinput=torch.tensor([[1,-0.5],[-1,3]])# 搭建神经网络
class Xiaofan(nn.Module):def __init__(self):super(Xiaofan,self).__init__()self.relu1=ReLU()def forward(self,input):output=self.relu1(input)return outputxiaofan=Xiaofan()
output=xiaofan(input)
print(output)测试结果:
2.Sigmoid
它的作用是将输入的每个元素进行逐元素的操作,将其压缩到[0, 1]的范围内。这使得Sigmoid函数特别适用于将输出解释为概率值的情况,因为它可以将任何实数映射到[0, 1]范围内的概率值。

dataset = torchvision.datasets.CIFAR10("../data", train=False,download=True,transform=ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
import torch
import torchvision
from torch import nn
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import ToTensor
from torchvision.utils import make_griddataset = torchvision.datasets.CIFAR10("../data", train=False,download=True,transform=ToTensor())
dataloader = DataLoader(dataset, batch_size=64)# 搭建神经网络
class Xiaofan(nn.Module):def __init__(self):super(Xiaofan, self).__init__()self.sigmoid = Sigmoid()def forward(self, input):output = self.sigmoid(input)return output
# 创建实例(神经网络模型的对象)
xiaofan = Xiaofan()writer = SummaryWriter("log_sig")step = 0
for data in dataloader:imgs, targets = datawriter.add_image("input", make_grid(imgs), global_step=step)output = xiaofan(imgs)writer.add_image("output", make_grid(output), step)step += 1writer.close()



五、线性层(Linear Layers)
、






*flatten函数

![]()

import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensordataset=torchvision.datasets.CIFAR10("../data",train=False,download=True,transform=ToTensor())
dataloader=DataLoader(dataset,batch_size=64)class XiaoFan(nn.Module):def __init__(self):super(XiaoFan,self).__init__()self.linear=Linear(196608,10)def forward(self,x):output=self.linear(x)return output# 创建实例(神经网络模型的对象)
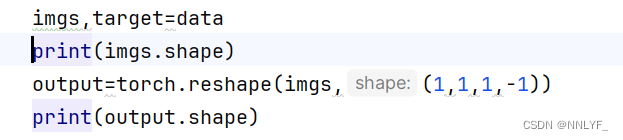
xiaofan=XiaoFan()for data in dataloader:# 对数据加载器进行迭代,每次迭代返回一个批次的数据# data包含一个批次的数据,这里让imgs设为一个批次的图像数据,target设置为对应的标签数据imgs,target=dataprint(imgs.shape)# output=torch.reshape(imgs,(1,1,1,-1))output=torch.flatten(imgs)print(output.shape)output=xiaofan(output)print(output.shape)测试结果:

六、搭建小实战和Sequential的使用
Conv2d-dilation


part1
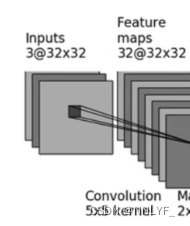


self.conv1=Conv2d(3,32,5,padding=2)part-3
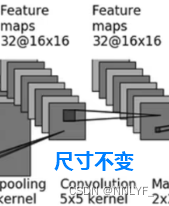 和part-1计算相同 padding取2
和part-1计算相同 padding取2
Flatten
import torch
from torch import nn
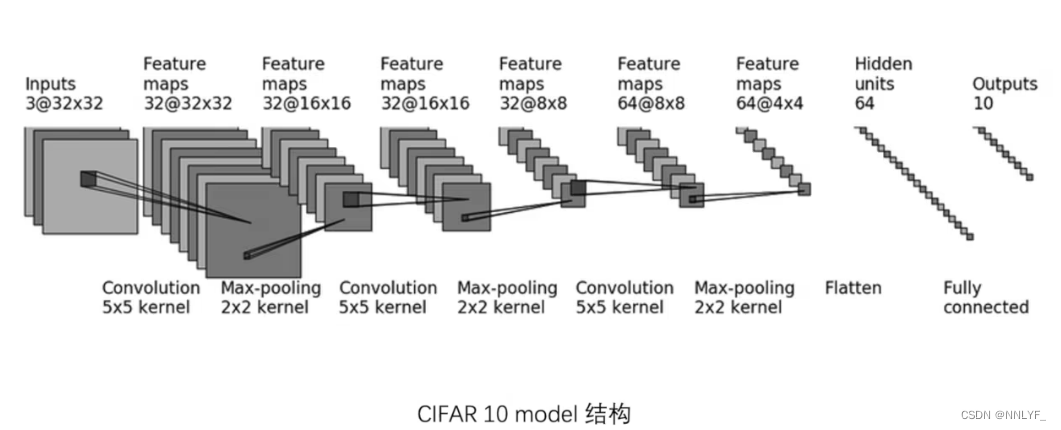
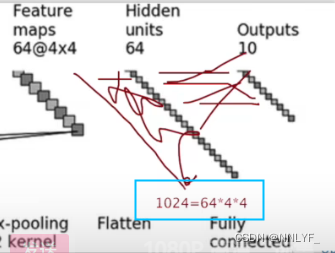
from torch.nn import Conv2d, MaxPool2d, Flatten,Linearclass XiaoFan(nn.Module):def __init__(self):super(XiaoFan,self).__init__()self.conv1=Conv2d(3,32,5,padding=2)self.maxpool1=MaxPool2d(2)self.conv2=Conv2d(32,32,5,padding=2)self.maxpool2=MaxPool2d(2)self.conv3=Conv2d(32,64,5,padding=2)self.maxpool3=MaxPool2d(2)self.flatten = Flatten()self.linear1=Linear(1024,64)self.linear2 = Linear(64, 10)def forward(self,x):x=self.conv1(x)x=self.maxpool1(x)x=self.conv2(x)x=self.maxpool2(x)x=self.conv3(x)x=self.maxpool3(x)x=self.flatten(x)x=self.linear1(x)x=self.linear2(x)return xxiaofan=XiaoFan()
print(xiaofan)

-
首先,输入数据经过一系列的卷积层和池化层,通过这些层的处理,图像的特征逐渐被提取和压缩。
-
然后,经过最后一个池化层后的特征图被展平成一维向量,以便输入到线性层中。
-
最后,在神经网络的末端,通常会连接全连接层,全连接层的作用是将前面层提取到的特征进行组合和映射,以便对输入数据进行分类或回归等任务。这些全连接层可以看作是一个特征提取器和分类器的组合,它们将前面层的高维特征映射到最终输出所需要的低维空间。self.linear1的输入维度是1024,输出维度是64,self.linear2的输入维度是64,输出维度是10。输出是一个包含10个值的向量,每个值表示输入图片属于对应类别的概率。换句话说,神经网络会给出输入图片属于每个可能类别的可能性大小。
input=torch.ones((64,3,32,32))
output=xiaofan(input)
print(output.shape)![]()

使用sequential简化代码
import torch
from torch import nn
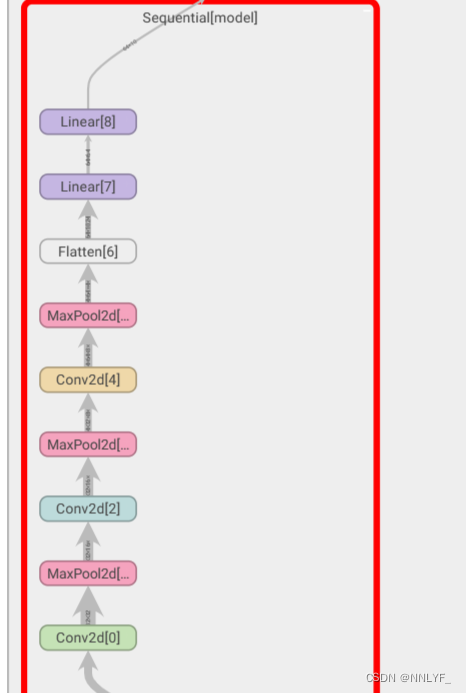
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialclass XiaoFan(nn.Module):def __init__(self):super(XiaoFan,self).__init__()self.model=Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self,x):x=self.model(x)return xxiaofan=XiaoFan()
print(xiaofan)
input=torch.ones((64,3,32,32))
output=xiaofan(input)
print(output.shape)
可视化:
完整代码:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriterclass XiaoFan(nn.Module):def __init__(self):super(XiaoFan,self).__init__()self.model=Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self,x):x=self.model(x)return xxiaofan=XiaoFan()
print(xiaofan)
input=torch.ones((64,3,32,32))
output=xiaofan(input)
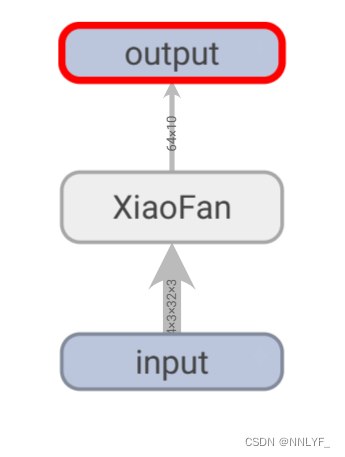
print(output.shape)writer=SummaryWriter("../log_seq")
writer.add_graph(xiaofan,input)
writer.close()



注意有空格的部分加上双引号
![]()
路漫漫其修远兮,吾将上下而求索。
:)