论文:Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
⭐⭐⭐⭐⭐
地址:https://selfrag.github.io/
文章目录
- 论文速读
- 实现细节
- 1. 问题的形式化概述
- 2. Self-RAG 的 inference 过程
- 3. Self-RAG 的训练
- 3.1 Critic Model 的训练 ⭐
- 3.2 LLM Generator 的训练
- 4. Self-RAG 在 inference 阶段的可以施加的控制
- 4.1 带阈值的自适应检索
- 4.2 带批判标记的树状解码
- 实验结果
- 任务和数据集
- 实验结果
- 总结
论文速读
以往 RAG 的缺点:以往的 RAG 方案是不加区分地检索文档并使用固定数量的几个文档,而不管问题是否需要检索,以及检索的文档是否有用。
本工作提出了“自我反思检索-增强生成”(Self-RAG)的框架,通过检索增强和自我反思来提高 LLM 生成文本的质量和事实性。
Self-RAG 框架包括两个模型:
- LLM Generator:就像 GPT 一样做 next token prediction
- Critic Model:用来对 LLM 的行为进行评判(不在 inference 阶段起作用,只用于训练阶段)
在 Self-RAG 的文字生成中,我们可以认为模型是一个文本段一个文本段地生成。在 LLM 每次准备生成一个文本段前,都会让判断一下“是否需要检索”,如果不需要检索,那让 Generator 就像 standard LM 一样继续 next token prediction 直到生成出一个文本段;而如果需要检索的话,就先让 Retriver 进行检索得到多个外部候选文档,接下来并行的针对每个候选文档把 prompt + document 输入给 LLM 让其生成一个“回答问题”的候选文本段,然后再评判检索的候选文档与问题是否相关以及 LLM 的生成回答是否合适,这样每个检索到的外部候选文档以及对应的候选生成文本段都可以得到一个评分,根据评分排序,从多个 LLM 输出的候选文本段中选出一个最合适的作为这一轮输出的文本段。重复上面步骤继续得到下一个文本段,一直循环直到回答结束。整个过程的图示如下:
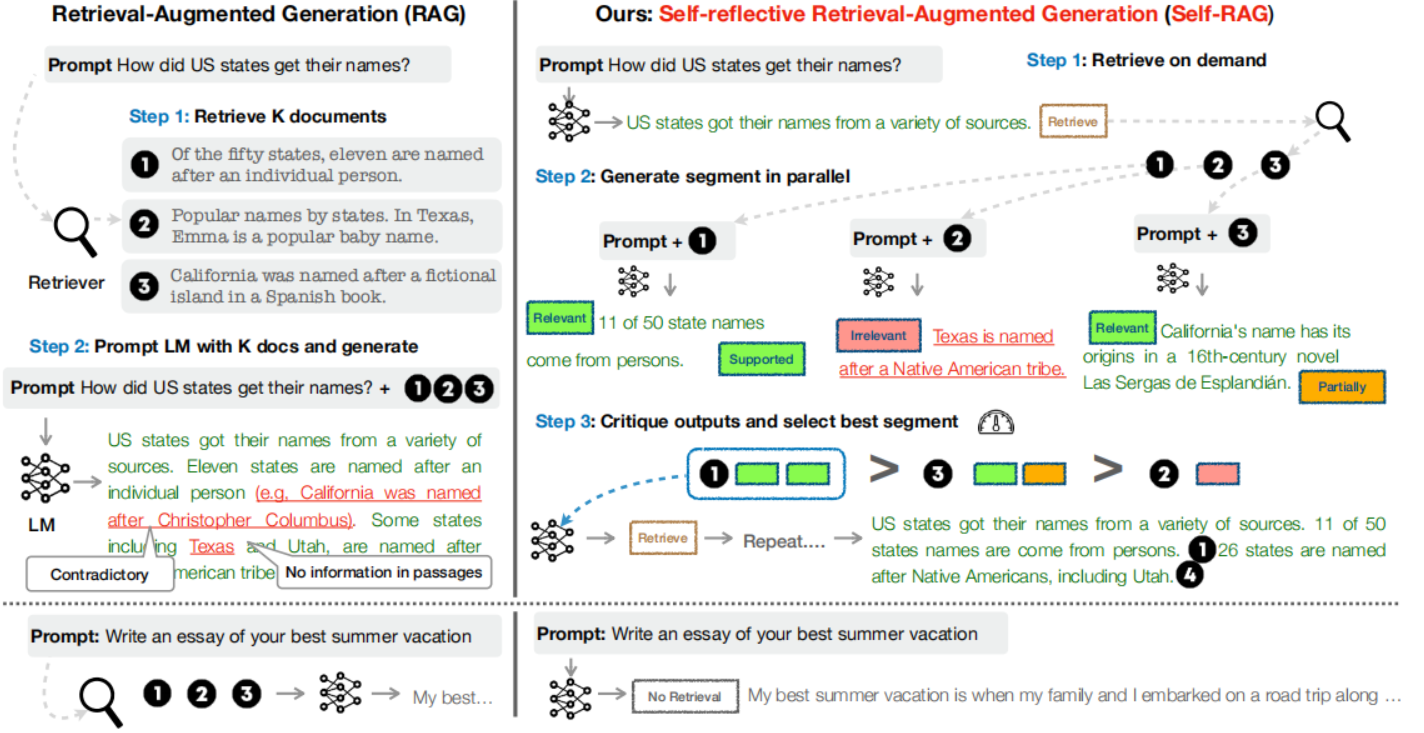
右边的就是 Self-RAG,整个流程就是我们上面解释的那一段。
具体详细的介绍可以参考后面的“inference 阶段”的介绍
为了实现“检索”和“自我反思”,引入了特殊标记 reflection tokens,也就是上图中那些带颜色的方块,分为如下两类:
- retrieval token:指示了是否需要进行检索,有如下三种取值:
yes:表示接下来需要进行检索,因此会下面会触发 Retriver 来检索相关的文档no:表示接下来不需要检索,因此接下来会像标准的 LM 一样做 next token predictioncontinue:代表模型可以继续使用之前检索到的信息片段。这通常发生在一个检索到的段落包含丰富的事实信息,可以用于生成多个文本段的情况下。在这种情况下,模型不需要检索新的信息片段,而是继续利用已有的检索结果来生成文本。
- critique token:用来评估检索的结果和 LLM 生成的文本的好坏,具体来说,ctrique token 又分成了三类:
- IS_REL:根据问题 x 和检索到的文档 d,指示了 d 是否为解决 x 提供了有用的信息。取值集合:
{relevant, irrelevant} - IS_SUP:根据问题 x、检索到的文档 d、LLM 生成的回答 y,指示了 y 是否被文档 d 支持了。取值集合:
{fully supported, partially supported, no support} - IS_USE:根据问题 x 和 LLM 生成的回答 y,指示了 y 是否对 x 有用。取值集合:
{5, 4, 3, 2, 1}
- IS_REL:根据问题 x 和检索到的文档 d,指示了 d 是否为解决 x 提供了有用的信息。取值集合:
这些 reflection token 的值其实就是通过 Critic Model 评判出来的。原论文对这些 reflection token 的解释如下:

从上面的介绍可以看出,Self-RAG 有如下的优点:
- 按需检索:没有说固定要检索多少个文档,而是根据具体问题来决定是否检索、检索多少次、对检索的文档是否使用。
- 对 LLM 生成的质量进行二次检查:每次 LLM 生成一个文本段结束后,Critic Model 都会对其生成内容进行检测并评分,每一轮会从多个候选文本段中选出一个最合适的作为本论生成的文本段。
- 为生成的每个段落提供引文:因为我们是每次检索后生成一个文本段,这样就很容易地匹配一个文本段的参考文档,进而可以为用户生成引文。
如下是 Self-RAG 的 input 与 output 的示例:

实现细节
1. 问题的形式化概述
形式上,将用户的问题输入记为 x x x,我们训练一个 LLM Generator M M M 去顺序生成含有多个文本段的文本输出 y = [ y 1 , y 2 , … , y T ] y = [y_1, y_2, \dots, y_T] y=[y1,y2,…,yT],其中 y T y_T yT 表示第 t 个文本段,每个文本段是一个 tokens 的序列。
2. Self-RAG 的 inference 过程
原文使用下面这个算法清晰地列出了 Self-RAG 的 inference 过程:

简单来说就是,目前有输入 x x x 和已经生成的多个文本段 y 1 , … , y t − 1 y_1, \dots, y_{t-1} y1,…,yt−1,接下来要生成文本段 y t y_t yt,inference 的步骤如下:
- 首先让 LLM Genertor 去生成 retrieval token 的值,如果:
- if
retrieval token == no:表示 Genertaor LLM 只需要向 standard LM 一样去 next prediction token 来生成出一个文本段 y t y_t yt - if
retrieval token == yes:让 Retriever 去做检索,检索出多个候选文档,针对每个候选文档,都生成一个候选文本段,并由 LLM 生成 critique token 来作为评判每个候选文档与问题的相关性和候选文本段是否合适的结果,之后根据 critique token 计算出 score 来并排序,选出一个最好的候选文本段作为这一轮的生成结果
- if
- 得到一个生成的文本段后,重复以上步骤来得到下一个文本段,直至结束,所有生成的文本段拼在一起就是最终输出的回答。
3. Self-RAG 的训练
以往的语料中没有本论文提到的 reflection token 这种特殊标记,而 LLM Generator 的训练却需要这种标记作为训练语料(因为在 inference 阶段,这些 reflection token 都是由 LLM Generator 生成的),所以我们需要额外训练一个 Critic Model,这个 model 专门根据 input 来生成 reflection token,从而标记语料,在语料中插入 reflection token。
所以,总共需要训练两个模型:Critic Model C C C 和 LLM Generator M M M。
3.1 Critic Model 的训练 ⭐
Critic Model 就是被训练用于根据 input 生成 reflection token,不同的 reflection token 有不同的定义和 input,如下图:
训练 Critic Model 的数据从哪来呢?其实在本文工作中,这些数据是 GPT-4 生成的,因为论文说对于一个场景下 reflection token 的取值,GPT-4 与人类有着高度一致的答案,所以这里就是针对每种 reflection token 专门设计了一种 prompt,借助于 In-Context learning,给出一些 few-shot 的 exemplars 后,让 GPT-4 根据 input 输出它所认为的 reflection token。
针对每个 reflection token 都设定一个专门的 prompt,这块是整个数据准备的关键。
比如下图是通过指令让 GPT-4 生成 retrieval token 的示例:

按照上面的方式,就可以准备出来用于训练 Critic Model 的数据了。Critic model 被初始化为一个预训练的语言模型,然后在收集到的带有 reflection token 的数据上进行训练。训练的目标是最大化预测反思标记的准确性。
论文评估了训练完成后的 Critic model 预测 reflection token 的表现,发现其与 GPT-4 的表现很接近了。将 GPT-4 的预测结果作为 ground-true prediction,那我们训练的 Critic Model 的准确率可以达到下面的水平:
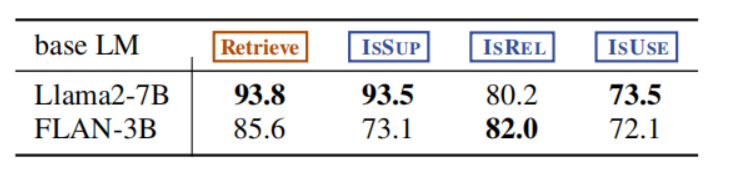
所以,接下来我们就可以使用 Critic Model 来为还没有添加 reflection token 的语料库插入上 reflection token,得到新的带有 reflection token 的训练数据,并用于训练 LLM Generator。
下图是使用 Critic Model 在原生语料库上插入 reflection token 的过程示例:
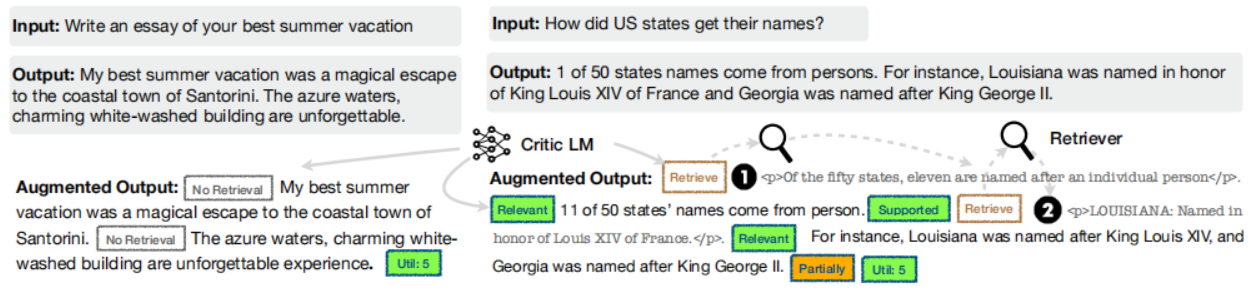
- 针对每个文本段,运行 C C C 来判断是否需要检索增强,并添加上 retrieval token
- 如果需要检索,就使用 Retriever 检索出 top K 的 passages D D D,对每一个 passage, C C C 进一步评估得到 critique token 并附加到原文本中
3.2 LLM Generator 的训练
LLM Generator 的训练所用的语料就是目前我们已有的所有带有 reflection token 的语料库,包括用于训练 Critic Model 的那部分和 Critic Model 新创建的那部分。
在 LLM Generator M M M 的学习中,与 Critic Model C C C 的训练目标不同, M M M 是学习预测文本输出和 reflection token,所以在训练过程的计算损失时会屏蔽掉检索到的文本块,并且会使用把我们扩展的 reflection token 扩展到原始词汇表中。
4. Self-RAG 在 inference 阶段的可以施加的控制
在 inference 阶段,Self-RAG 通过生成反射标记来自我评估输出结果,从而使其行为适应不同的任务要求。在不同的任务背景下,我们对模型的输出往往有着不同的期待:
- 对于要求事实准确性的任务,目标是让模型更频繁地检索段落,以确保输出结果与可用证据密切吻合。
- 在开放性较强的任务中,如撰写个人经历文章,重点则转向减少检索次数,优先考虑整体创造性或实用性得分。
所以,Self-RAG 支持在 inference 过程中施加控制来满足这些不同的目标:
4.1 带阈值的自适应检索
Self-RAG 根据生成的 retrieval token 的值来动态决定是否进行检索。而我们可以控制 P ( r e t r i e v a l _ t o k e n ) P(retrieval\_token) P(retrieval_token) 概率的阈值来控制模型是更倾向于检索增强生成(会更加事实准确)还是更倾向于直接生成(会更加具有创造力)。
Self-RAG 是根据下面的判断条件来决定 retrieval token 的取值:
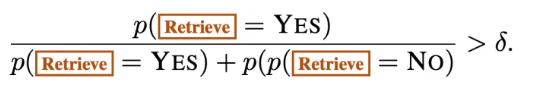
所以这个阈值越高,模型就越倾向于直接生成,反之则倾向于检索增强生成。
4.2 带批判标记的树状解码
在 inference 时,检索阶段会检索到多个候选文档,针对每个文档,LLM Generator 都会尝试一个新的可能的文本生成路径,就像树干分出多个树枝一样。每个树枝代表一个可能的文本生成方向。最终模型会对这些不同生成路径进行评估,选出得分最高的路径来继续生成文本。
这里每个生成路径的“得分”是根据这个路径的 critique token 按照一定权重计算出来的。为了满足不同任务的需求,可以在推理时调整 critique token 的权重。例如,如果任务需要更高的事实准确性,可以增加支持程度(IS_SUP)的权重,使模型更倾向于选择那些有强证据支持的文本路径。
实验结果
任务和数据集
该工作在一系列下游任务上对 SELF-RAG 和各种 baseline 进行了评估,用旨在评估整体正确性、事实性和流畅性的指标对输出进行了整体评估。
- 封闭集任务包括两个数据集,即关于公共卫生的事实验证数据集(PubHealth)和根据科学考试创建的多选推理数据集(ARC-Challenge),使用准确率作为评估指标,并对测试集进行报告。
- 两个开放域问题解答(QA)数据集:PopQA和TriviaQA-unfiltered,其中系统需要回答有关事实知识的任意问题。
- 长式生成任务包括传记生成任务和长式质量保证任务ALCE-ASQA,使用FactScore来评估传记,并使用基于MAUVE的官方指标正确性、流畅性以及引用精度和召回率来评估ASQA。
实验结果
下图列出了各种对比效果:
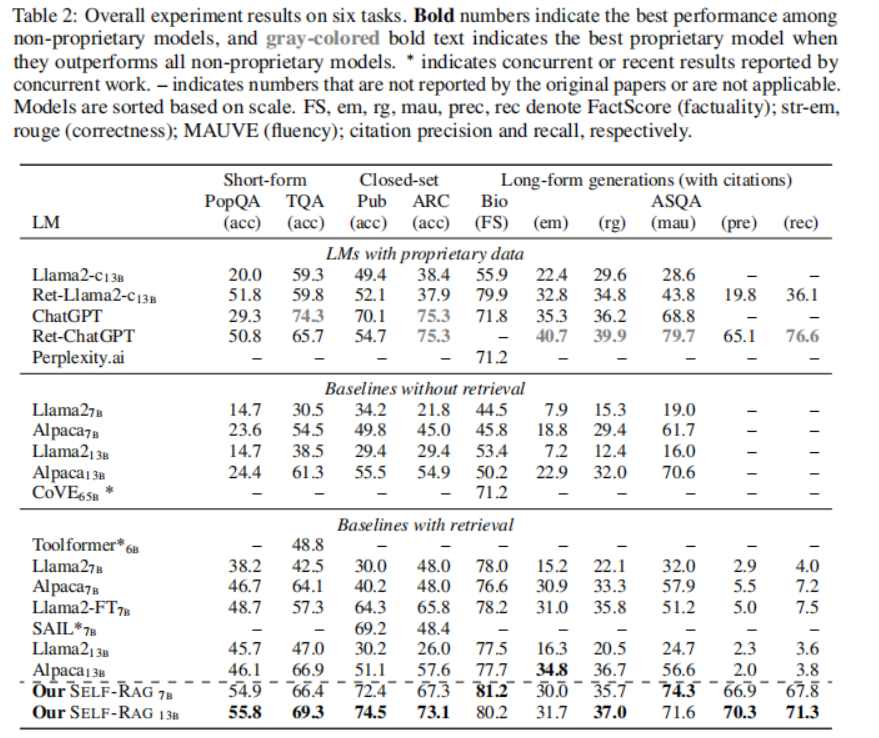
从实验结果可以得出如下结论:
- 在 PubHealth 和 ARC-Challenge 上,有检索功能的基线与没有检索功能的基线相比,性能提升并不明显。
- 大多数带检索的基线模型在提高引用准确率方面都很吃力。
- 在实际精确度的度量上,SELF-RAG7B 偶尔会优于 13B,这是因为较小的 SELF-RAG 通常倾向于生成精确且较短的输出。
- Llama2-FT7B 是在与 SELF-RAG 相同的指令-输出对上训练的基准 LM,不进行检索或自我反省,仅在测试时进行检索增强,它落后于 SELF-RAG。这一结果表明,SELF-RAG 的收益并非完全来自训练数据,并证明了 SELF-RAG 框架的有效性。
总结
这个工作提出的 Self-RAG 框架,通过在 next token prediction 加入了新的特殊标记(reflection token)来让 LLM 决定是否检索、评价自己的文本段落生成,从而使用“检索增强生成”的思路提高 LLM 的质量和事实性。
其实现思路与 ToolFormer 十分类似,可以结合起来看。
参考阅读:
- 也看引入自我反思的大模型RAG检索增强生成框架:SELF-RAG的数据构造及基本实现思路 | 老刘 NLP




![[python数据处理系列]详解独热编码与标签编码的区别及在Pandas中的实现](https://img-blog.csdnimg.cn/direct/50230b56e8654a4aa5a027d1357a0946.png)