文章目录
- ChatGLM-Med是什么
- 数据集构建
- 推理部署
- python环境
- 切换到安装好的conda环境
- 下载github数据
- 切换目录
- 在infer.py修改模型路径
- 启动推理
- 解决infer.py报错
- 修改后再次启动推理完成
- 微调部署
- 安装evaluate包
- 修改模型路径
- 启动微调
ChatGLM-Med是什么
经过中文医学指令精调/指令微调(Instruct-tuning) 的ChatGLM-6B模型。我们通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,并在此基础上对ChatGLM-6B进行了指令微调,提高了ChatGLM在医疗领域的问答效果。
数据集构建
采用了公开和自建的中文医学知识库,主要参考了cMeKG。医学知识库围绕疾病、药物、检查指标等构建,字段包括并发症,高危因素,组织学检查,临床症状,药物治疗,辅助治疗等。知识库示例如下:
{"中心词": "偏头痛", "相关疾病": ["妊娠合并偏头痛", "恶寒发热"], "相关症状": ["皮肤变硬", "头部及眼后部疼痛并能听到连续不断的隆隆声", "晨起头痛加重"], "所属科室": ["中西医结合科", "内科"], "发病部位": ["头部"]}
我们利用GPT3.5接口围绕医学知识库构建问答数据,设置了多种Prompt形式来充分利用知识。
指令微调的训练集数据示例如下:
"问题:一位年轻男性长期使用可卡因,突然出现胸痛、呕吐、出汗等症状,经检查发现心电图反映心肌急性损伤,请问可能患的是什么疾病?治疗方式是什么?"
回答: 可能患的是心肌梗塞,需要进行维拉帕米、依普利酮、硝酸甘油、ß阻滞剂、吗啡等药物治疗,并进行溶栓治疗、低分子量肝素、钙通道阻滞剂等辅助治疗。此外需要及时停用可卡因等药物,以防止病情加重。"
推理部署
python环境
python环境建议3.9+
$ python --version
Python 3.10.12
切换到安装好的conda环境
source activate
conda activate chatglm-6b
下载github数据
git clone https://github.com/SCIR-HI/Med-ChatGLM.git

切换目录
cd Med-ChatGLM
在infer.py修改模型路径
此处改成"/data/sim_chatgpt/ChatGLM-Med/"
import torch
from transformers import AutoTokenizer, AutoModel
from modeling_chatglm import ChatGLMForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("/data/sim_chatgpt/ChatGLM-Med/", trust_remote_code=True)
model = ChatGLMForConditionalGeneration.from_pretrained("/data/sim_chatgpt/ChatGLM-Med").half().cuda()
while True:a = input("请输入您的问题:(输入q以退出)")if a.strip() == 'q':exit()response, history = model.chat(tokenizer, "问题:" + a.strip() + '\n答案:', max_length=256, history=[])print("回答:", response)
启动推理
python infer.py

解决infer.py报错
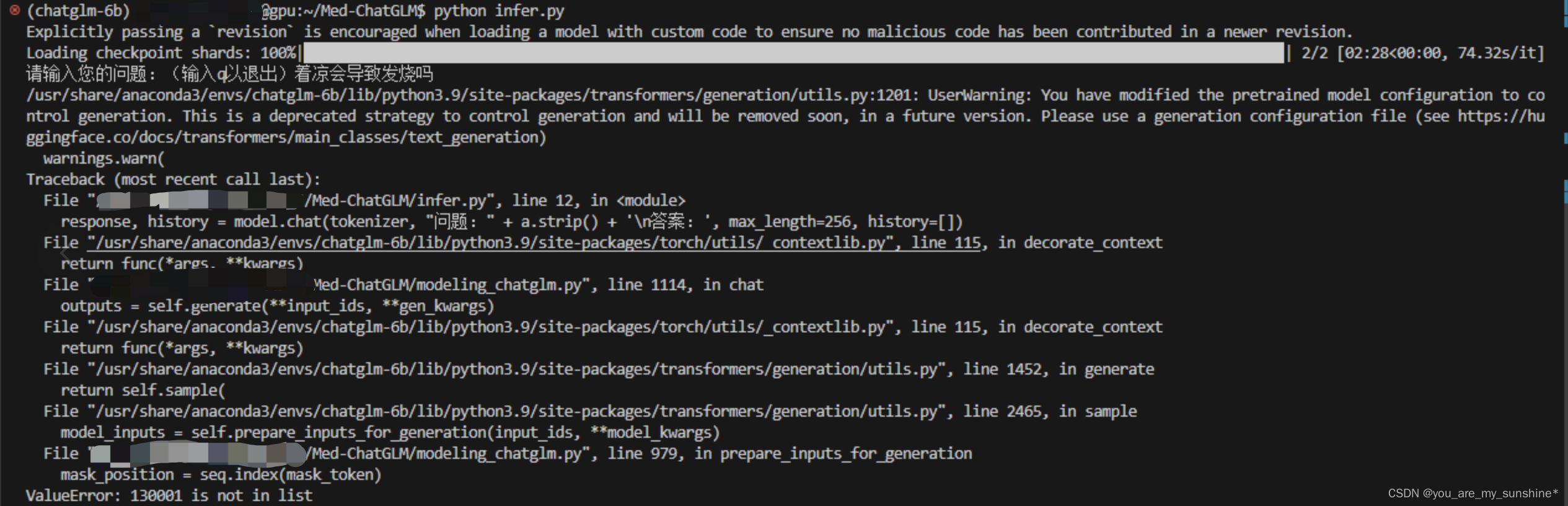
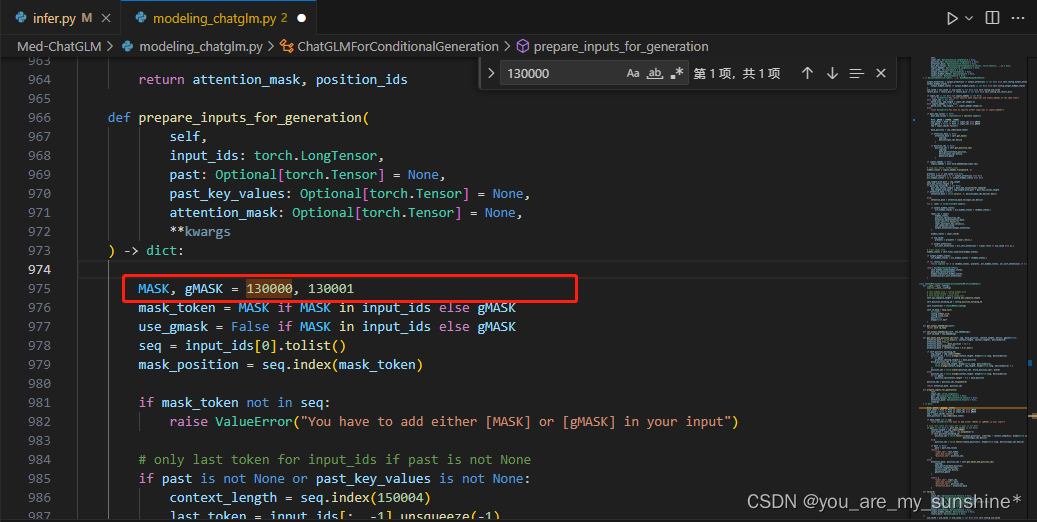
在 modeling_chatglm.py 文件下,修改的831行,975行
将130000、130001分别改成150000、150001,再次运行即可
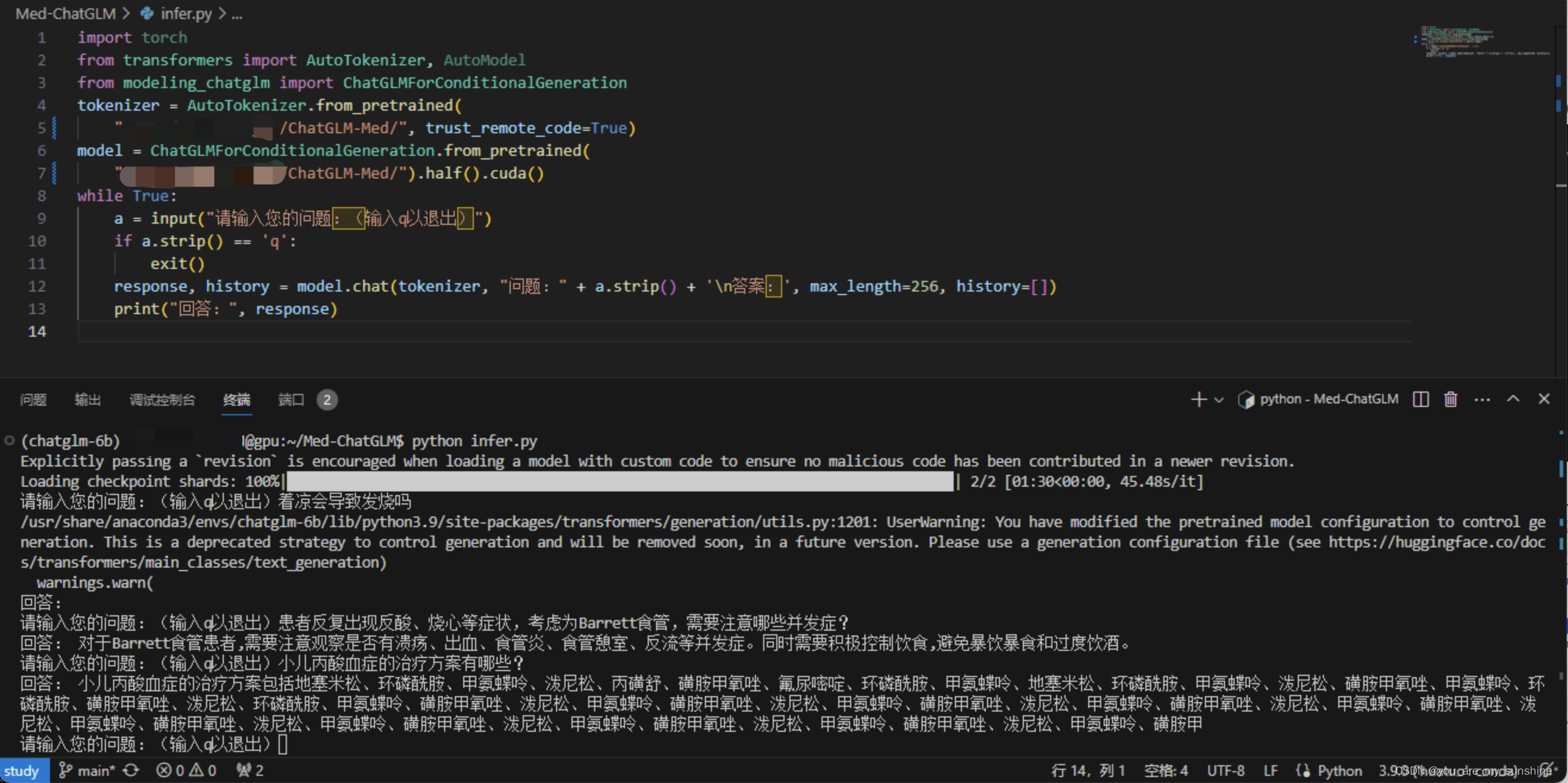
修改后再次启动推理完成
微调部署
安装evaluate包
pip install evaluate
pip install wandb
修改模型路径
在scripts/sft_medchat.sh下,修改要运行文件中的model_name_or_path,修改为 /data/sim_chatgpt/chatglm-6b,如下:
wandb online
exp_tag="chatglm_tuning"python run_clm.py \--model_name_or_path /data/sim_chatgpt/chatglm-6b \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--train_file ./data/train.txt \--max_seq_length 256 \--output_dir ./output/ \--do_train \--logging_steps 30 \--log_file ./log/$exp_tag \--gradient_accumulation_steps 2 \--learning_rate 5e-5 \--group_by_length False \--num_train_epochs 3 \--lr_scheduler_type linear \--warmup_ratio 0.1 \--logging_dir ./log \--logging_steps 10 \--save_strategy epoch \--seed 2023 \--remove_unused_columns False \--torch_dtype auto \--adam_epsilon 1e-3 \--report_to wandb \--run_name $exp_tag
启动微调
sh scripts/sft_medchat.sh
将batch_size及epochs等参数值调小,per_device_train_batch_size、per_device_eval_batch_size、num_train_epochs等,仍旧执行不起来,内存超出,故需要更大资源去做微调(目前GPU是P100)
学习的参考资料:
Repo for Chinese Medical ChatGLM 基于中文医学知识的ChatGLM指令微调
基于ChatGLM-Med与HuaTuo的微调部署
![[华为OD] 给航天器一侧加装长方形或正方形的太阳能板 100](https://img-blog.csdnimg.cn/direct/51754d605de44c40aec2e6d0fecada95.png)