资源是Terraform中最核心的部分,使用Terraform的目的就是用于管理资源。
在Terraform中,资源使用resource块定义。
一个resource可以定义一个或多个基础设施资源对象,如:VPC,虚拟机,DNS记录,Consul的键值对数据等。
资源语法
资源通过resource块定义,首先阐述定义单个资源的场景。
resource "aws_instance" "web" {ami = "ami-a1b2c3d4"instance_type = "t2.micro"
}紧跟在resource关键字后面的是资源类型,如上例子中的资源类型为:aws_instance。后面是资源的Local Name,如上例子中就是web。
Local Name可以在同一模块内的代码里被用来引用该资源,但类型加Local Name的组合在当前模块内必须是唯一的,不同类型的Local Name可以相同。
随后花括号内的内容就是创建资源所用到的各种参数的值,如上例子中定义了创建虚拟机所使用的镜像id(ami)和虚拟机尺寸(instance_type)。
在上述资源定义的语法中涉及了2个概念:资源类型和资源参数,如下进行详细阐述。
资源类型
在上述例子中使用的资源类型为aws_instance,那么这个资源类型是从哪里知道的呢?换句话说我们在使用Terraform创建资源时在什么地方去查阅相关的资源信息?
我们知道Terraform只是一个云服务编排工具,通过它来管理的云服务资源通常都是各个云服务厂商提供的,那么云服务厂商能够提供哪些资源以及如何使用这些资源都是各个云服务厂商来告诉我们,具体来说就是在各云服务厂商提供的Terraform Provider文档中会进行说明,每一个Terraform Provider都有自己的文档,用以描述它所支持的资源类型种类,以及每种资源类型所支持的属性列表。
大部分公共的Provider都是通过Terraform Registry连带文档一起发布的,当我们在Terraform Registry站点上浏览一个Provider的页面时,我们可以点击”Documentation”链接来浏览相关文档。Provider的文档都是版本化的,我们可以选择特定版本的Provider文档。
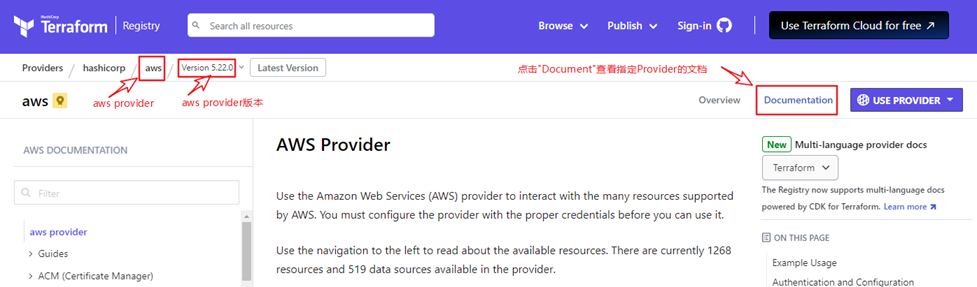
需要注意的是,Provider文档曾经是直接托管在terraform.io站点上的,也就是Terraform核心主站的一部分。但目前Terraform Rregistry才是所有公共Provider文档的主站(唯一的例外是用来读取其他Terraform状态数据的内建的terraform provider,它的文档目前不在Terraform Registry上)。
以AWS Provider为例,在它提供的Terraform Provider文档中,左侧列展示的就是AWS能够支持使用Terraform进行管理的资源列表。
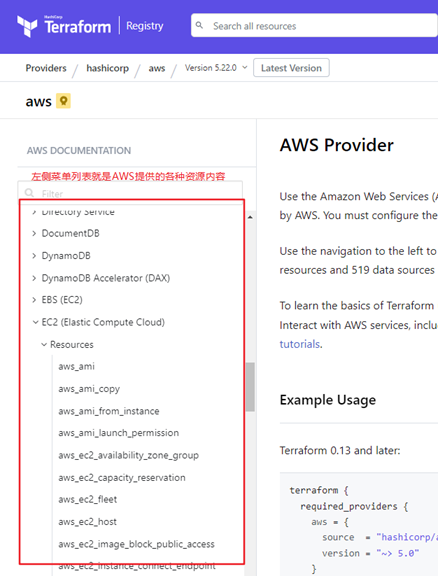
如上图,以EC2资源为例子,点击 EC2 (Elastic Compute Cloud)菜单后在Resources下展示的就是各种EC2资源类型,其中就有在上述例子中使用的aws_instance类型。
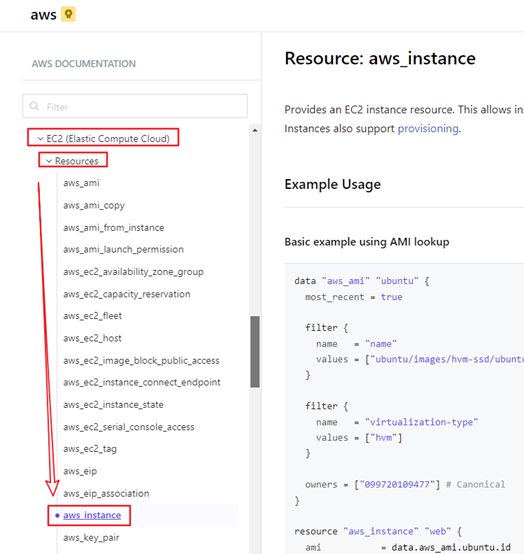
资源参数
通过上述步骤找到指定类型的资源之后,在右侧中点击Argument Reference就可以查看该资源支持的各种参数定义。
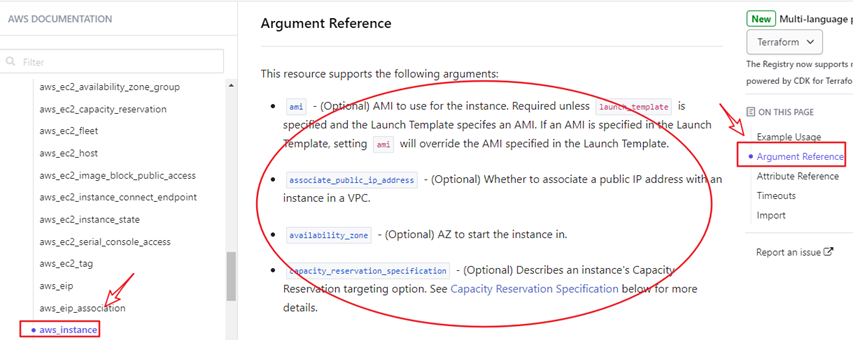
有些参数是必填的,有些参数是可选的。
以AWS的aws_instance资源为例,它的参数几乎都是选填的。
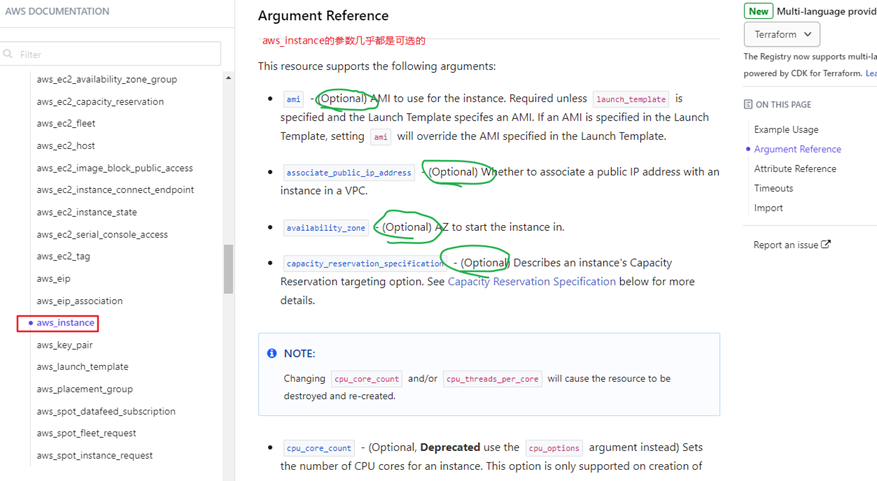
在使用某种类型的资源之前可以通过阅读相关文档了解其参数列表以及它们的含义,赋值约束条件等。
参数值可以是简单的字面量,也可以是一个复杂的表达式。
资源的行为
一个resource块可以声明想要创建的一个指定类型的基础设施对象,以及其各项属性值。如果正在编写一个新的Terraform代码文件,那么代码定义的资源仅仅在代码中存在,并没有与之对应的实际的基础设置资源存在。
关于资源的行为描述如下:
“对一组Terraform代码执行terraform apply后才会创建,更新或者销毁与之对应的实际的基础设施对象,Terraform会制定并执行变更计划,以使得实际的基础设施符合代码的定义。每当Terraform按照一个resource块创建了一个新的基础设施对象,这个实际的对象的id会被保存进Terraform状态文件中,使得将来Terraform可以根据变更计划对它进行更新或是销毁操作。如果一个resource块描述的资源在状态文件中已有记录,那么Terraform会比对记录的状态与代码描述的状态,如果有必要,Terraform会制定变更计划以使得资源状态能够符合代码的描述。”
这种行为适用于所有资源而无关其类型,虽然创建、更新、销毁一个资源的细节会根据资源类型而不同,但是这个行为规则却是普适的。
资源的输出属性
资源不但可以通过参数传值,成功创建的资源还对外输出一些通过调用API才能获得的只读数据,经常包含了一些我们在实际创建一个资源之前无法获知的数据,比如云主机的id等。在Terraform Provider文档中将资源的输出属性称之为Attribute。
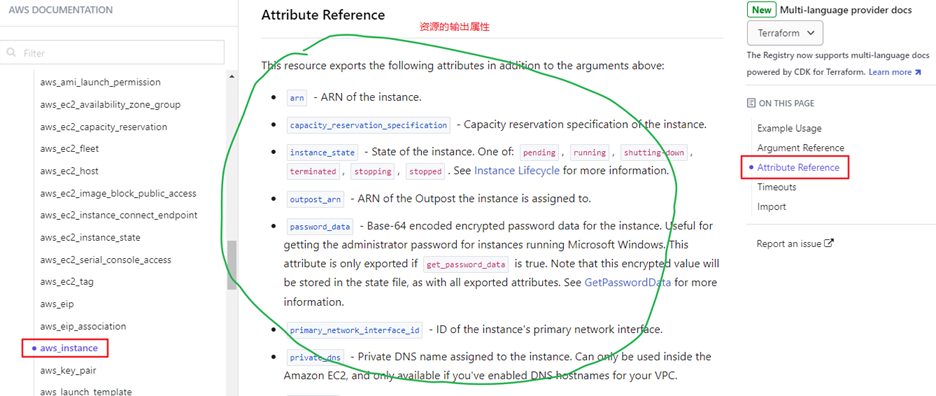
可以在同一模块内的代码中引用资源的输出属性来创建其他资源或是表达式,在表达式中引用资源属性的语法是<RESOURCE TYPE>.<Local NAME>.<ATTRIBUTE>。
resource "aws_instance" "web" {ami = "ami-a1b2c3d4"instance_type = "t2.micro"
}如上示例,引用aws_instance的输出属性public_ip:aws_instance.web.public_ip。
资源的依赖关系
一般来说在Terraform代码定义的资源之间不会有特定的依赖关系,Terraform可以并行地对多个无依赖关系的资源执行变更,默认情况下这个并行度是10。
然而,创建某些资源所需要的信息依赖于另一个资源创建后的输出属性,又或者必须在某些资源成功创建后才可以被创建,这时资源之间就存在依赖关系。
大部分资源间的依赖关系可以被Terraform自动处理,Terraform会分析resource块内的表达式,根据表达式的引用链来确定资源之间的引用,进而计算出资源在创建、更新、销毁时的执行顺序。
大部分情况下不需要显式指定资源之间的依赖关系。
然而,有时候某些依赖关系是无法从代码中推导出来的。例如,Terraform必须要创建一个访问控制权限资源,以及另一个需要该权限才能成功创建的资源。后者的创建依赖于前者的成功创建,然而这种依赖在代码中没有表现为数据引用关联,这种情况下需要用元参数depends_on来显式声明这种依赖关系。
元参数
resource块支持几种元参数声明,这些元参数可以被声明在所有类型的resource块内,它们将会改变资源的行为:
depends_on:显式声明依赖关系count:创建多个资源实例for_each:迭代集合,为集合中每一个元素创建一个对应的资源实例provider:指定非默认Terraform Provider实例lifecycle:自定义资源的生命周期行为provisioner和connection:在资源创建后执行一些额外的操作
depends_on
使用depends_on可以显式声明Terraform无法自动推导出的资源之间的依赖关系,只有当资源间确实存在依赖关系,但是彼此间又没有数据引用的场景下才有必要使用depends_on。
如下示例:
# 声明一个AWS IAM角色
resource "aws_iam_role" "example" {name = "example"assume_role_policy = "..."
}# 将IAM角色绑定在一个主机实例配置文件上
resource "aws_iam_instance_profile" "example" {role = aws_iam_role.example.name
}# 为IAM角色添加对S3存储服务的完全控制权限
resource "aws_iam_role_policy" "example" {name = "example"role = aws_iam_role.example.namepolicy = jsonencode({"Statement" = [{"Action" = "s3:*","Effect" = "Allow",}],})
}resource "aws_instance" "example" {ami = "ami-a1b2c3d4"instance_type = "t2.micro"# 这个赋值使得Terraform能够判断出虚拟机依赖于主机实例配置文件iam_instance_profile = aws_iam_instance_profile.example# 为了确保虚拟机创建时S3权限一定已经存在,用depends_on显式声明它们的依赖关系depends_on = [aws_iam_role_policy.example,]
}虚拟机实例由于绑定了主机实例配置文件,从而在运行时拥有了一个IAM角色,而这个IAM角色又被赋予了S3的权限。但是虚拟机实例的声明代码中并没有引用S3权限的任何输出属性,这将导致Terraform无法理解他们之间存在依赖关系,进而可能会并行地创建两者,如果虚拟机实例被先创建了出来,内部的程序开始运行时,它所需要的S3权限却还没有创建完成,那么就将导致程序运行错误。为了确保虚拟机创建时S3权限一定已经存在,用depends_on显式声明它们的依赖关系。
depends_on的赋值必须是包含同一模块内声明的其他资源名称的列表,不允许包含其他表达式,例如不允许使用其他资源的输出属性。depends_on只能作为最后的手段使用,如果使用了depends_on,应该用注释记录使用它的原因,以便今后代码的维护者能够理解隐藏的依赖关系。
count
通常,1个resource块定义了1个对应的实际基础设施资源对象。
如果希望创建多个相似的对象,比如创建一组虚拟机,Terraform提供了2个元参数可以实现这个目标:count与for_each。count参数可以是任意自然数,Terraform会创建count个资源实例,每一个实例都对应了一个独立的基础设施对象,并且在执行Terraform代码时,这些对象是被分别创建、更新或者销毁的。
resource "aws_instance" "server" {# 创建4个相同规格的虚拟机实例count = 4ami = "ami-a1b2c3d4"instance_type = "t2.micro"tags = {Name = "Server ${count.index}"}
}可以在resource块中的表达式里使用count对象来获取当前的count索引号,count对象只有一个属性:count.index(代表当前对象对应的count下标索引,从0开始)
如果一个resource块定义了count参数,那么Terraform会把这种多资源实例对象与没有count参数的单资源实例对象区别开:
- 访问单资源实例对象:
<TYPE>.<NAME>,例如:aws_instance.server - 访问多资源实例对象:
<TYPE>.<NAME>[<INDEX>],例如:aws_instance.server[0],aws_instance.server[1]
声明了count或for_each参数的资源必须使用下标索引或者键来访问。
count参数可以是任意自然数,但是count的值在Terraform进行任何远程资源操作(增删改查)之前必须是已知的,故count参数的表达式不可以引用任何其他资源的输出属性(例如由其他资源对象创建时返回的一个唯一的ID)。count的表达式中可以引用来自data返回的输出属性,只要该data可以不依赖任何其他resource进行查询。
for_each
for_each是Terraform 0.12.6开始引入的新特性,一个resource块不允许同时声明count和for_each。for_each参数值可以是一个map或是一个set(string),Terraform会为集合中每一个元素都创建一个独立的基础设施资源对象,和count一样,每一个基础设施资源对象在执行Terraform代码时都是独立创建、修改、销毁的。
使用map的例子:
resource "azurerm_resource_group" "rg" {for_each = {a_group = "eastus"another_group = "westus2"}name = each.keylocation = each.value
}使用set(string)的例子:
resource "aws_iam_user" "the-accounts" {for_each = toset( ["Todd", "James", "Alice", "Dottie"] )name = each.key
}可以在声明了for_each参数的resource块内使用each对象来访问当前的迭代器对象:
each.key:map的键,或是set中的值each.value:map的值,或是set中的值
如果for_each的值是一个set,那么each.key和each.value是相等的。
使用for_each时,map的所有键、set的所有string值都必须是已知的,也就是状态文件中已有记录的值。所以有时候可能需要在执行terraform apply时添加-target参数,实现分步创建。另外,for_each所使用的键集合不能够包含或依赖非纯函数,也就是反复执行会返回不同返回值的函数,例如uuid、bcrypt、timestamp等。
当一个resource声明了for_each时,Terraform会把这种多资源实例对象与没有for_each参数的单资源实例对象区别开:
- 访问单资源实例对象:
<TYPE>.<NAME>,例如:aws_instance.server - 访问多资源实例对象:
<TYPE>.<NAME>[<KE>],例如:aws_instance.server[“ap-northeast-1”],aws_instance.server[“ap-northeast-2”]
声明了count或for_each参数的资源必须使用下标索引或者键来访问。
由于Terraform没有用以声明set的字面量,所以我们有时需要使用toset函数把list(string)转换为set(string):
locals {# 使用toset函数将list(string)转换为set(string)subnet_ids = toset(["subnet-abcdef","subnet-012345",])
}resource "aws_instance" "server" {# for_each参数值引用的是局部值set集合for_each = local.subnet_idsami = "ami-a1b2c3d4"instance_type = "t2.micro"subnet_id = each.key # note: each.key and each.value are the same for a settags = {Name = "Server ${each.key}"}
}用toset函数把一个list(string)转换成了set(string),在转换过程中,list中所有重复的元素会被抛弃,只剩下不重复的元素,例如toset(["b", "a", "b"])的结果只有”a”和”b”,并且set的元素没有特定顺序。
如果把一个输入变量赋值给for_each,可以直接定义变量的类型约束来避免显式调用toset函数进行类型转换:
variable "subnet_ids" {# 明确定义输入变量类型type = set(string)
}resource "aws_instance" "server" {# for_each参数值为一个输入变量,类型为set(string)for_each = var.subnet_ids
}count和for_each的选择
如果创建的资源实例彼此之间几乎完全一致,那么count比较合适;如果彼此之间的参数差异无法直接从count的下标派生,那么使用for_each会更加安全。
在Terraform引入for_each之前,经常使用count.index搭配length函数和list来创建多个资源实例:
variable "subnet_ids" {type = list(string)
}resource "aws_instance" "server" {# count参数值为list类型长度count = length(var.subnet_ids)ami = "ami-a1b2c3d4"instance_type = "t2.micro"subnet_id = var.subnet_ids[count.index]tags = {Name = "Server ${count.index}"}
}这种实现方法是脆弱的,因为资源仍然是以他们的下标而不是实际的string值来区分的。如果从subnet_ids列表的中间移除了一个元素,那么从该位置起后续所有的aws_instance都会发现它们的subnet_id发生了变化,结果就是所有后续的aws_instance都需要更新。这种场景下如果使用for_each就更为妥当,如果使用for_each,那么只有被移除的subnet_id对应的aws_instance会被销毁。
provider
如果声明了同一类型Provider的多个实例,那么在创建资源时可以通过指定provider参数选择要使用的Provider实例。
如果没有指定provider参数,那么Terraform默认使用资源类型名中第一个单词所对应的Provider实例,例如google_compute_instance的默认Provider实例就是google,aws_instance的默认Provider就是aws。
指定provider参数的例子:
# 默认provider
provider "google" {region = "us-central1"
}# 另一个provider,指定了别名
provider "google" {alias = "europe"region = "europe-west1"
}resource "google_compute_instance" "example" {# 在resource块中明确指定要使用的Provider实例provider = google.europe
}provider参数期待的赋值是<PROVIDER>或是<PROVIDER>.<ALIAS>,不需要双引号,除了这两种以外的表达式是不被接受的。
lifecycle
可以用lifecycle块来指定一个资源声明周期的行为,如下示例:
resource "azurerm_resource_group" "example" {lifecycle {# 只有在新对象成功创建并取代老对象后再销毁老对象create_before_destroy = true}
}lifecycle块和它的内容都属于元参数,可以被声明于任意类型的资源块内部。
Terraform支持如下几种lifecycle:
create_before_destroy(bool):默认情况下,当Terraform需要修改一个由于服务端API限制导致无法直接升级的资源时,Terraform会删除现有资源对象,然后用新的配置参数创建一个新的资源对象取代之。create_before_destroy参数可以修改这个行为,使得Terraform首先创建新对象,只有在新对象成功创建并取代老对象后再销毁老对象。这并不是默认的行为,因为许多基础设施资源需要有一个唯一的名字或是别的什么标识属性,在新老对象并存时也要符合这种约束。有些资源类型有特别的参数可以为每个对象名称添加一个随机的前缀以防止冲突。Terraform不能默认采用这种行为,故在使用create_before_destroy前必须了解每一种资源类型在这方面的约束。prevent_destroy (bool)::这个参数是一个保险措施,只要它被设置为true时,Terraform会拒绝执行任何可能会销毁该基础设施资源的变更计划。这个参数可以预防意外删除关键资源,例如错误地执行了terraform destroy,或者是意外修改了资源的某个参数,导致Terraform决定删除并重建新的资源实例。在resource块内声明了prevent_destroy = true会导致无法执行terraform destroy,所以对它的使用要节制。需要注意的是,该措施无法防止删除resource块后Terraform删除相关资源,因为对应的prevent_destroy = true声明也被一并删除了。ignore_changes(list(string)):默认情况下,Terraform检测到代码描述的配置与真实基础设施对象之间有任何差异时都会计算一个变更计划来更新基础设施对象,使之符合代码描述的状态。在一些非常罕见的场景下,实际的基础设施对象会被Terraform之外的流程所修改,这就会使得Terraform不停地尝试修改基础设施对象以弥合和代码之间的差异。这种情况下,我们可以通过设定ignore_changes来指示Terraform忽略某些属性的变更。ignore_changes的值定义了一组在创建时需要按照代码定义的值来创建,但在更新时不需要考虑值的变化的属性名,例如:
resource "aws_instance" "example" {lifecycle {# 忽略对aws_instance资源tags属性的更新ignore_changes = [tags,]}
}可以忽略map中特定的元素,例如tags["Name"],要注意的是,如果想忽略map中特定元素的变更,那么必须首先确保map中含有这个元素。如果一开始map中并没有这个键,而后外部系统添加了这个键,那么Terraform还是会把它当成一次变更来处理。比较好的方法是在代码中先为这个键创建一个占位元素来确保这个键已经存在,这样在外部系统修改了键对应的值以后Terraform会忽略这个变更。
resource "aws_instance" "example" {tags = {Name = "placeholder"}lifecycle {# 忽略对map中特定的元素的修改,前提:一开始创建资源的时候map中就有对应的Key存在ignore_changes = [tags["Name"],]}
}除了使用一个list(string),也可以使用关键字”all”,这时Terraform会忽略资源一切属性的变更,这样Terraform只会创建或销毁一个对象,但绝不会尝试更新一个对象。只能在ignore_changes里忽略所属的resource的属性,ignore_changes不可以赋予它自身或是其他任何元参数。
-
replace_triggered_by (包含资源引用的列表):强制Terraform在引用的资源或是资源属性发生变更时替换声明该块的父资源,值为一个包含了托管资源、实例或是实例属性引用表达式的列表。当声明该块的资源声明了count或是for_each时,可以在表达式中使用count.index或是each.key来指定引用实例的序号。replace_triggered_by可以在以下几种场景中使用:- 如果表达式指向多实例的资源声明(声明
count或for_each),那么这组资源中任意实例发生变更或被替换时都将引发声明replace_triggered_by的资源被替换 - 如果表达式指向单个资源实例,那么该实例发生变更或被替换时将引发声明
replace_triggered_by的资源被替换 - 如果表达式指向单个资源实例的单个属性,那么该属性值的任何变化都将引发声明
replace_triggered_by的资源被替换
在
replace_triggered_by中只能引用托管资源,这允许在不引发强制替换的前提下修改这些表达式。resource "aws_appautoscaling_target" "ecs_target" {lifecycle {replace_triggered_by = [aws_ecs_service.svc.id]} } - 如果表达式指向多实例的资源声明(声明
配置lifecycle块影响了Terraform如何构建并遍历依赖图。作为结果,lifecycle内赋值仅支持字面量,因为它的计算过程发生在Terraform计算的极早期。
这就是说,例如prevent_destroy、create_before_destroy的值只能是true或者false,ignore_changes、replace_triggered_by的列表内只能是硬编码的属性名。
precondition和postcondition
precondition与postcondition是从Terraform v1.2.0开始被引入的功能。
在lifecycle块中声明precondition与postcondition块可以为资源、数据源以及输出值创建自定义的验证规则。
Terraform在计算一个对象之前会首先检查该对象关联的precondition,并且在对象计算完成后执行postcondition检查。
Terraform会尽可能早地执行自定义检查,但如果表达式中包含了只有在terraform apply阶段才能知晓的值,那么该检查也将被推迟执行。
每一个precondition与postcondition块都需要一个condition参数,该参数是一个表达式,在满足条件时返回true,否则返回false。该表达式可以引用同一模块内的任意其他对象,只要这种引用不会产生环依赖。在postcondition表达式中也可以使用self对象引用声明postcondition的资源实例的属性。
如果condition表达式计算结果为false,Terraform会生成一条错误信息,包含了error_message表达式的内容。
如果声明了多条precondition或postcondition,Terraform会返回所有失败条件对应的错误信息。
如下演示通过postcondition检测调用者是否不小心传入了错误的AMI参数:
data "aws_ami" "example" {id = var.aws_ami_idlifecycle {# 检查该资源的tags["Component"]属性值是否为"nomad-server"postcondition {condition = self.tags["Component"] == "nomad-server"error_message = "tags[\"Component\"] must be \"nomad-server\"."}}
}在resource或data块中的lifecycle块可以同时包含precondition与postcondition块。
- Terraform会在计算完
count和for_each元参数后执行precondition块,这使得Terraform可以对每一个实例独立进行检查,并允许在表达式中使用each.key、count.index等。Terraform还会在计算资源的参数表达式之前执行precondition检查,precondition可以用来防止参数表达式计算中的错误被激发。 - Terraform在计算和执行对一个托管资源的变更之后执行
postcondition检查,或是在完成数据源读取后执行它关联的postcondition检查,postcondition失败会阻止其他依赖于此失败资源的其他资源的变更。
大多数情况下不建议在同一配置文件中同时包含表示同一个对象的data块和resource块,这样做会使得Terraform无法理解data块的结果会被resource块的变更所影响。
然而,当需要检查一个resource块的结果,恰巧该结果又没有被资源直接输出时,可以使用data块并在块中直接使用postcondition来检查该对象。这等于告诉Terraform该data块是用来检查其他什么地方定义的对象的,从而允许Terrform以正确的顺序执行操作。
provisioner和connection
某些基础设施对象需要在创建后执行特定的操作才能正式工作,比如:主机实例必须在上传了配置或是由配置管理工具初始化之后才能正常工作。
像这样创建后执行的操作可以使用预置器(Provisioner),预置器是由Terraform所提供的另一组插件,每种预置器可以在资源对象创建后执行不同类型的操作。
使用预置器需要节制,因为他们采取的操作并非Terraform声明式的风格,所以Terraform无法对他们执行的变更进行建模和保存。
预置器也可以声明为资源销毁前执行,但会有一些限制。
作为元参数,provisioner和connection可以声明在任意类型的resource块内。
如下示例:
resource "aws_instance" "web" {provisioner "file" {source = "conf/myapp.conf"destination = "/etc/myapp.conf"connection {type = "ssh"user = "root"password = var.root_passwordhost = self.public_ip}}
}在aws_instance中定义了类型为file的预置器,该预置器可以将本机文件或文件夹拷贝到目标机器的指定路径下。
在预置器内部定义了connection块,类型是ssh。对connection的host赋值self.public_ip,在这里self代表预置器所在的母块,也就是aws_instance.web,所以self.public_ip代表着aws_instance.web.public_ip,也就是创建出来的主机的公网ip。
file类型预置器支持ssh和winrm两种类型的connection。
预置器根据运行的时机分为两种类型:创建时预置器和销毁时预置器。
创建时预置器
默认情况下,资源对象被创建时会运行预置器,在对象更新、销毁时则不会运行,预置器的默认行是为了引导一个系统。
如果创建时预置器失败了,那么资源对象会被标记污点,一个被标记污点的资源在下次执行terraform apply命令时会被销毁并重建。Terrform的这种设计是因为当预置器运行失败时标志着资源处于半就绪的状态,由于Terraform无法衡量预置器的行为,所以唯一能够完全确保资源被正确初始化的方式就是删除重建,可以通过设置on_failure参数来改变这种行为。
销毁时预置器
如果设置预置器的when参数为destroy,那么预置器会在资源被销毁时执行:
resource "aws_instance" "web" {provisioner "local-exec" {when = destroycommand = "echo 'Destroy-time provisioner'"}
}销毁时预置器在资源被实际销毁前运行,如果运行失败,Terraform会报错,并在下次运行terraform apply操作时重新执行预置器。在这种情况下,需要仔细关注销毁时预置器以使之能够安全地反复执行。
销毁时预置器只有在存在于代码中的情况下才会在销毁时被执行,如果一个resource块连带内部的销毁时预置器块一起被从代码中删除,那么被删除的预置器在资源被销毁时不会被执行,要解决这个问题,需要使用多个步骤来绕过这个限制:
- 修改资源声明代码,添加
count = 0参数 - 执行
terraform apply,运行删除时预置器,然后删除资源实例 - 删除resource块
- 重新执行
terraform apply,此时应该不会有任何变更需要执行
预置器失败行为
默认情况下,预置器运行失败会导致terraform apply执行失败,可以通过设置on_failure参数来改变这一行为,可以设置的值为:
- continue:忽视错误,继续执行创建或是销毁
- fail:报错并终止执行变更(这是默认行为),如果这是一个创建时预置器,则在对应资源对象上标记污点
示例:
resource "aws_instance" "web" {provisioner "local-exec" {command = "echo The server's IP address is ${self.private_ip}"on_failure = continue}
}本地资源
虽然大部分资源类型都对应的是通过远程基础设施API控制的一个资源对象,但也有一些资源对象他们只存在于Terraform进程自身内部,用来计算生成某些结果,并将这些结果保存在状态中以备日后使用。
例如,可以用tls_private_key生成公私钥,用tls_self_signed_cert生成自签名证书,或者是用random_id生成随机id。虽不像其他“真实”基础设施对象那般重要,但这些本地资源也可以成为连接其他资源有用的黏合剂。
本地资源的行为与其他类型资源是一致的,但是他们的结果数据仅存在于Terraform状态文件中,“销毁”这种资源只是将结果数据从状态文件中删除。
超时设置
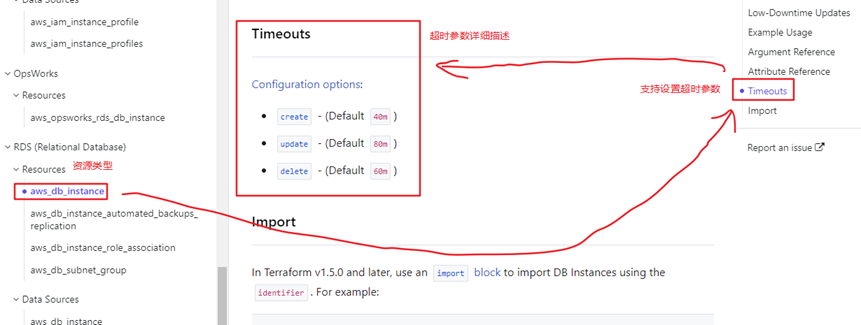
有些资源类型提供了特殊的timeouts内嵌块参数,用于配置允许操作持续多长时间,超时将被认定为失败。比如说,aws_db_instance资源允许分别为create,update,delete操作设置超时时间,详见db_instance#timeouts。
超时完全由资源对应的Provider来处理,但支持超时设置的Provider一般都遵循相同的传统,那就是由一个名为timeouts的嵌入块参数定义超时设置,timeouts块内可以分别设置不同操作的超时时间。超时时间由string描述,比如”60m”代表60分钟,”10s”代表10秒,”2h”代表2小时。
如下示例:
resource "aws_db_instance" "example" {timeouts {create = "60m"delete = "2h"}
}大部分资源类型不支持设置超时,使用超时前请先查阅相关文档,通常在资源详情页面中可以看到,如下图所示: