湖仓一体 - Apache Arrow的那些事
Arrow是高性能列式内存格式标准。它的优势:高效计算:所有列存的通用优势,CPU缓存友好、SIMD向量化计算友好等;零序列化/反序列化:arrow的任何数据结构都是一段连续的内存,在跨进程/跨及其传输数据时直接发送/接收整段内存即可,不需要序列化和反序列化;完善的数据类型和生态;支持跨语言跨系统互操作。
Arrow代码库分为3个层次:core层,提供数据类型表示,这一层非常稳定,新版本完全兼容之前版本;Compute层,提供计算算子,相对稳定,但有bug,使用一些比较高级指令集如AVX512时,会有一些内存对齐问题;Acero层,是最新执行引擎,不够稳定更适合开发测试。
本文关注arrow执行器式如何实现高性能。重点关注两方面的功能:Gandiva表达式JIT;Acero流式执行引擎:基于push的引擎
1、Gandiva
传统数据库执行器基于火山模型,一次仅处理一条数据,存在大量虚函数调用,会造成非确定性跳转指令,CPU无法做分支预测,打断CPU流水线;计算中无法确定类型,算子中存在很多动态类型判断,执行过程中,需要频繁对类型进行识别;递归函数调用打断计算过程。所以使用LLVM代码生成技术进行动态即时编译以及SIMD向量化,提升数据处理性能。首先表达式编译器将抽象语法树转换为中间字节码;然后执行时JIT编译器将其进一步转换成最终的机器码。
Gandiva采用C++实现,同时也提供了Python和java的绑定接口。有评论说该项目差不多已经死了。
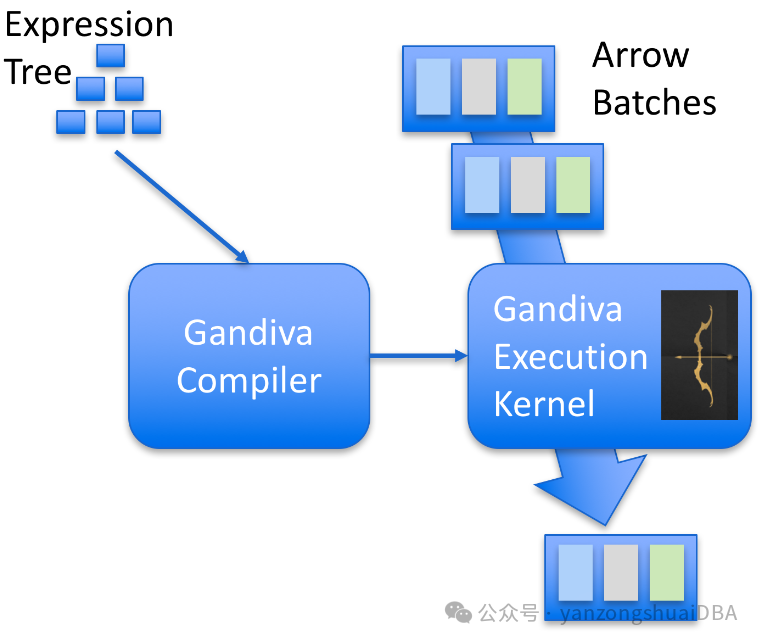
应用程序将一个表达式树提交给Gandiva编译器,可以在运行时进行编译。从而控制Gandiva执行内核,处理Arrow buffers中的batches。
表达式库支持的操作比如:目前它的表达式库除了基本的算数运算符以外,还拥有超过100个内置函数及布尔运算符,主要用于投影和过滤。

支持表达式、投影和过滤。利用TreeExprBuilder构建表达式树,包括函数节点、if-else逻辑和布尔表达式的创建。然后,利用Projector或者Filter执行内核高效处理这些表达式。
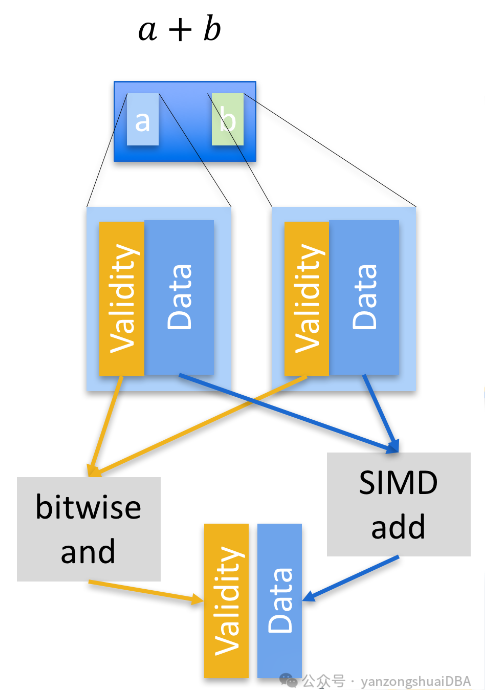
对于混有NULL值的批量处理方式:将NULL的标记从数据中分离,使用bitmap来表示,减少CPU的分支预测代价。数据可以使用SIMD进行批量处理,bitmap也单独进行计算,两者结合起来就是最终计算结果。
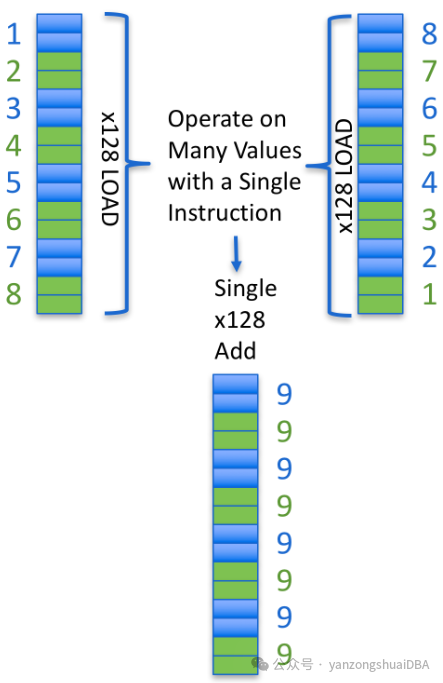
下面是一个简单的SIMD加法例子:使用AVX-128,一次操作可以处理8个两字节的值。
附炎凰数据在DataFun上分享演讲回答的几个问题:
Q1:Gandiva 生成的 LLVM 是标量值,有用到向量值,就是 SIMD(单指令多数据流)或者 AVX(高级向量扩展)等技术吗?
A1:这是一个非常好的问题,有些人可能会对采用 Gandiva 协助生成 LLVM IR 的代码存在一定担忧,是否能达到预期的性能要求。因为在常规执行过程中,人们通常期望拥有准确、高效的向量化支持。针对这个问题,Gandiva 已经做出了妥善的处理,生成的 LLVM-IR 中间形式均具备向量化支持,以确保所需的功能得以保留。
这些技术使得处理器能够同时处理多个数据,从而大大提高了程序的执行效率。在 Gandiva 中,LLVM IR(中间表示)被转换为可执行代码的序列,这些代码可以由 SIMD 指令集执行。因此,Gandiva 生成的 LLVM IR 序列可以在支持 SIMD 指令集的处理器上高效运行。
Q2:Gandiva 一生成出来就是 LLVM 的形式?就是向量化的执行代码?
A2:是的。它是经过优化的,实际执行的和我刚刚给大家展示的 Arrow code 是不一样的,后者代表了初始的呈现方式,然而在实际执行过程中都是有向量化支持的。
Gandiva 生成的是 LLVM 的形式,并且可以生成向量化的执行代码。Gandiva 是一个开源项目,旨在为 Apache Arrow 提供高效的数据处理功能。它使用 LLVM 作为后端,通过 LLVM 编译器将源代码编译为高效的机器码,并利用 SIMD 指令集实现向量化的执行代码,从而提高数据处理性能。因此,Gandiva 生成的代码可以在支持 SIMD 指令集的处理器上高效运行,实现高性能的数据处理。
Q3:Arrow 社区提供了 compute API 以及各种语言的高性能实现以供基于 Arrow 格式进行数据操作的向量化复用,跟 Gandiva 生成的 LLVM 的形式的向量化有什么区别和联系?
A3:这也是一个很好的问题,Arrow 有自己的一套执行框架,叫做 Arrow Acero,它对向量化的支持是非常友好的。
Arrow 社区提供的 compute API 以及各种语言的高性能实现,是基于 Arrow 格式进行数据操作的开发人员可以直接复用的工具。这些工具可以帮助开发人员更高效地处理数据,并提高程序的执行效率。
而 Gandiva 生成的 LLVM 形式,是利用 LLVM 编译器将源代码编译为高效的机器码,并利用 SIMD 指令集实现向量化的执行代码。这种生成方式可以使得 Gandiva 生成的代码在支持 SIMD 指令集的处理器上高效运行,从而提高数据处理性能。
两者的主要区别在于,Arrow 社区提供的工具主要是提供API和各种语言的高性能实现,而 Gandiva 生成的 LLVM 形式则是通过编译源代码来实现高效的数据处理。另外,Gandiva 生成的 LLVM 形式是向量化的执行代码,可以充分利用处理器的 SIMD 指令集,而 Arrow 社区提供的工具则不一定是向量化的。
所以我们的整个执行引擎在经过了很多次迭代之后完全切到了一个新式的、对流式计算有一个更好的支持的引擎,这个引擎也是基于 Arrow compute 构建的。
2、Acero执行引擎
Push-based向量化执行引擎,是一个C++库。目前支持的算子:Source、Sink、HashJoin、Project、Filter、Sort、 Agg、pivot_longer、asofjoin、union。不提供分布式执行,并且是一个开发版本,并不稳定。他将计算表示为“execution plan”即ExecPlan,接收零个或多个输入数据,输出一个数据流。Plan描述了数据在通过这个节点时,是怎么转换的,也就是计算的。比如下面的例子:使用一个公共列合并两个数据流;以现有列为基础通过表达式计算产生一个额外列;以分区布局形式将数据流写入磁盘。Substrait是一个构建查询计划的项目,Acero作为它的消费者,执行它产生的执行计划并产生数据。
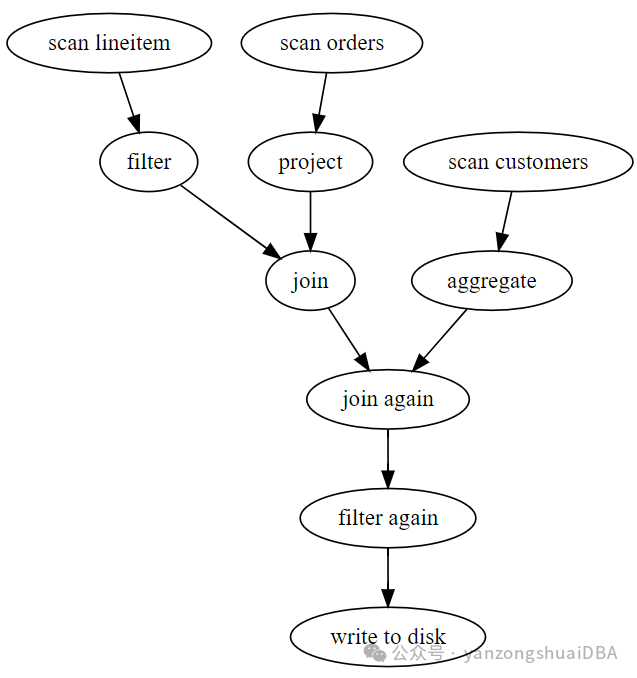
Acero中最基本的概念是ExecNode:如果有0个输入,就称为source;若无输出就称为sink。有多种其他的节点,每个节点以不同方式将输出进行转换,例如:
1)Scan节点就是一个从文件中读数据的source节点;
2)Aggregate节点进行聚合计算
3)Filter节点根据过滤表达式进行过滤计算
4)Table Sink节点累积数据到一个表
一批数据使用ExecBatch类进行表示。一个ExecBatch是一个二维结构,和RecordBatch类似。可以有零个或者多列,并且每列必须有相同长度。RecordBatch和ExecBatch的几个关键区别:
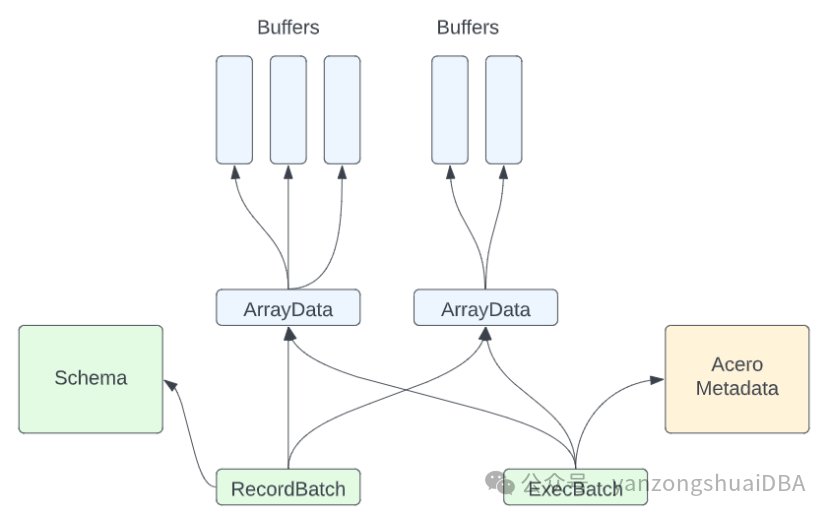
1)ExecBatch没有schema。假设他是一个batch流的一部分,并且流假设是由一个持久的schema。因此该schema通常存储在ExecNode中
2)ExecBatch中的列要么是一个Array,要么是标量。若是标量,意味着该列的一个batch种仅一行值。它还有一个长度属性,描述batch中的行数。
3)ExecBatch还有额外信息以供执行器使用。例如一个index和用来描述有序流中一个batch的位置。还可以包含比如selection vector。
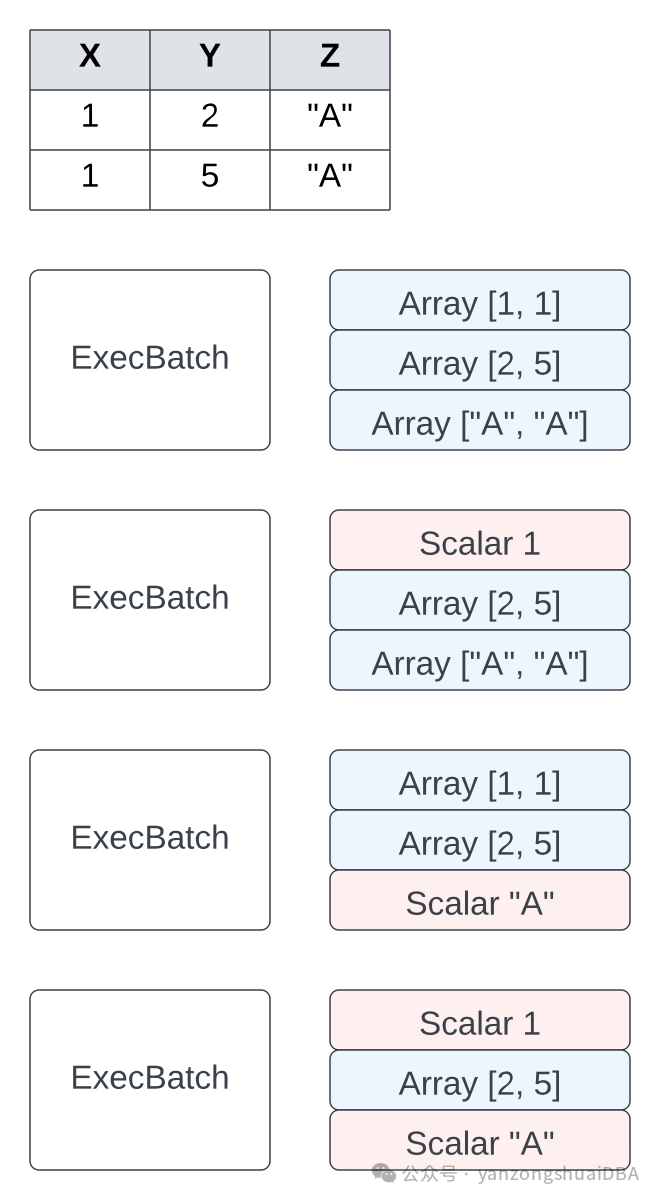
Record batch到exec batch的转换是零拷贝,RecordBatch和ExecBatch都引用完全相同的arrays。
ExecPlan表示ExecNode的对象图。一个有效的ExecPlan至少有一个source,但从技术上将,它不需要有一个sink节点。ExecPlan包含有所有节点共享的资源,有公共函数控制节点的启动和停止执行。ExecPlan和ExecNode都和单个执行的生命周期相关联。
Declaration描述一个执行计划。
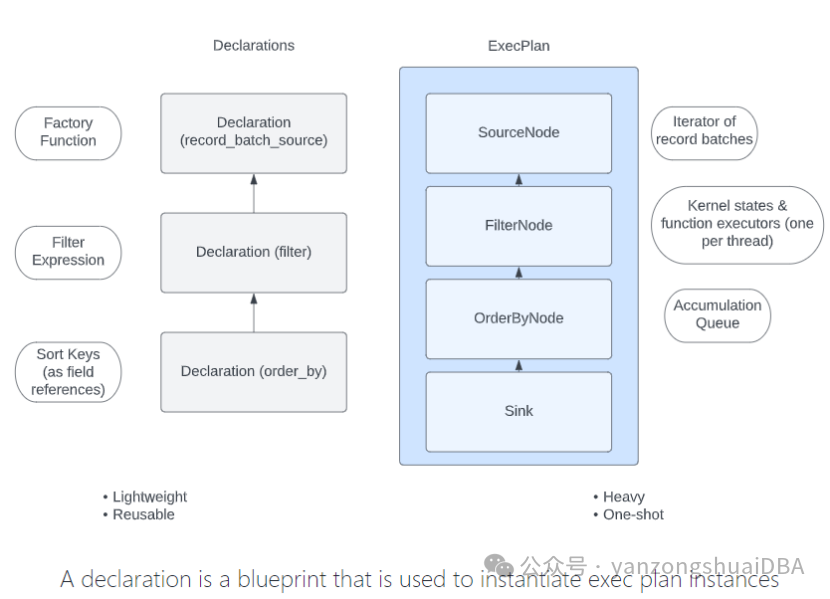
Acero基本流程:
1)创建一组Declaration对象,描述该执行计划
2)调用DeclarationToXyz方法执行该Declaration
(1)根据Declarations创建一个新的ExecPlan。每个Delaration对应该计划中的一个ExecNode。同时依赖于使用哪种DeclarationToXyz方法,添加一个sink节点
(2)执行ExecPlan。通常这是DeclarationToXyz调用的一部分,在DeclarationToReader中,reader在计划执行完成之前返回。
(3)一旦执行完该计划,就进行销毁。
节点内部可以执行并行。比如Scan节点可以并行decode列。Hash join节点可以用于并行构建hash表,还可以并行排序。
参考
https://www.modb.pro/db/1765921255731073024
https://zhuanlan.zhihu.com/p/655305778?utm_id=0
https://github.com/apache/arrow
https://arrow.apache.org/docs/cpp/
https://www.dremio.com/blog/announcing-gandiva-initiative-for-apache-arrow/
https://zhuanlan.zhihu.com/p/678108750
https://cloud.tencent.com/developer/article/2322115
https://zhuanlan.zhihu.com/p/635751399