第五章 深度学习
九、图像分割
3. 常用模型
3.4 DeepLab 系列
3.4.3 DeepLab v3(2017)
在DeepLab v3中,主要进行了以下改进:
- 使用更深的网络结构,以及串联不同膨胀率的空洞卷积,来获取更多的上下文信息
- 优化Atrous Spatial Pyramid Pooling
- 去掉条件随机场
3.4.3.1 串联结构
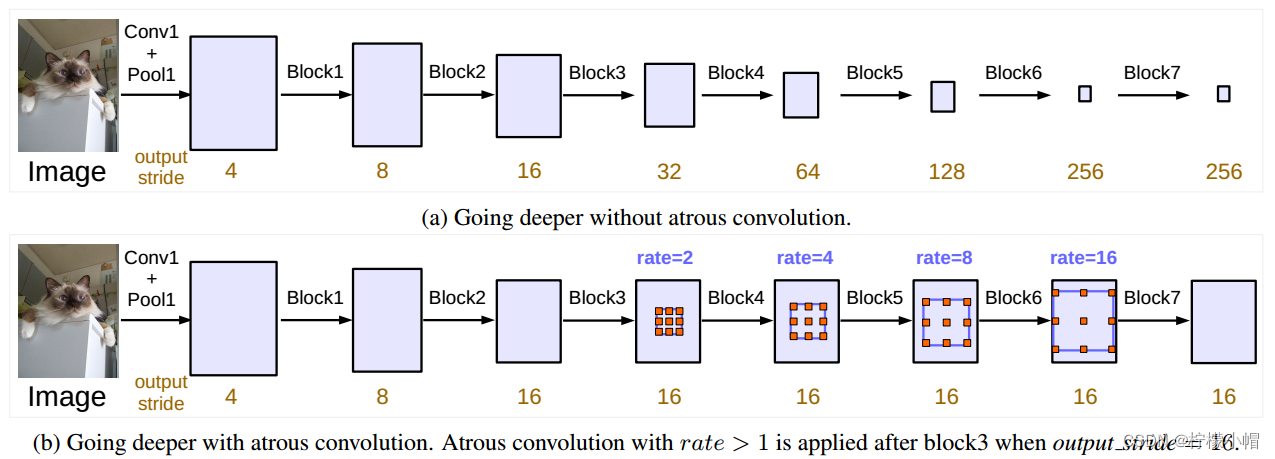
上图演示了ResNet结构中,不使用空洞卷积(上)和使用不同膨胀率的空洞卷积(下)的差异,通过在Block3后使用不同膨胀率的空洞卷积,保证在扩大视野的情况下,保证特征图的分辨率。
3.4.3.2 并行结构
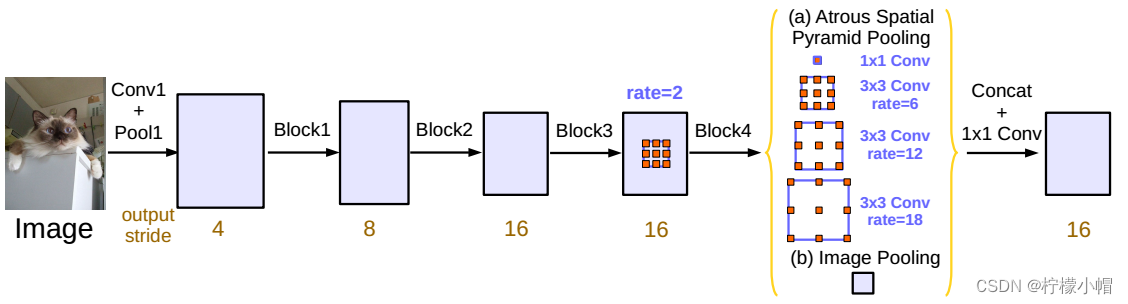
作者通过实验发现,膨胀率越大,卷积核中的有效权重越少,当膨胀率足够大时,只有卷积核最中间的权重有效,即退化成了1x1卷积核,并不能获取到全局的context信息。为了解决这个问题,作者在最后一个特征上使用了全局平均池化(global everage pooling)(包含1x1卷积核,输出256个通道,正则化,通过bilinear上采样还原到对应尺度)。修改后的ASPP结构图如下:
3.4.3.3 Mult-grid策略
作者考虑了multi-grid方法,即每个block中的三个卷积有各自unit rate,例如Multi Grid = (1, 2, 4),block的dilate rate=2,则block中每个卷积的实际膨胀率=2* (1, 2, 4)=(2,4,8)。
3.4.3.4 训练策略
- 采用变化的学习率,学习率衰减策略如下(其中,power设置为0.9):
( 1 − i t e r m a x _ i t e r ) p o w e r (1 - \frac{iter}{max\_iter})^{power} (1−max_iteriter)power
- 裁剪。在训练和测试期间,在PASCAL VOC 2012数据集上采用的裁剪尺寸为513,以保证更大的膨胀率有效。
- Batch Normalization。先在增强数据集上output stride = 16(输入图像与输出特征大小的比例),batch size=16,BN参数衰减为0.9997,训练30k个iter。之后在官方PASCAL VOC 2012的trainval集上冻结BN参数, output stride = 8,batch size=8,训练30k个iter。
- 采用上采样真值计算Loss。DeepLabv1/v2中都是下采样的真值来计算loss,这样会让细节标记产生损失,本模型使用上采样最后的输出结果计算。
- 数据随机处理。在训练阶段,对输入的图像进行随机缩放(缩放率在0.5-2.0之间),并随机执行左右翻转。
3.4.3.5 效果
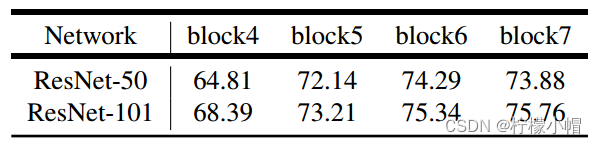
-
ResNet-50和ResNet-101结构比较,更多的级联采样能获得 更高的性能
-
各种优化测略效果实验
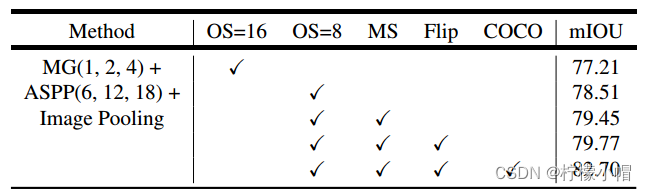
其中,MG表示Multi-grid,ASPP 表示Atrous spatial pyramid pooling ,OS表示output stride ,MS表示Multiscale inputs during test ,Flip表示镜像增强,COCO表示MS-COCO 预训练模型。 -
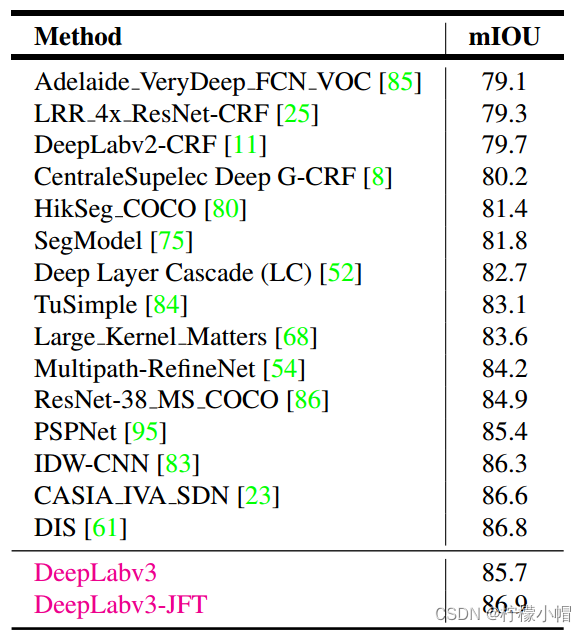
其它模型对比(PASCAL VOC 2012 测试集)
-
分割效果展示

3.4.4 DeepLab v3+
3.4.4.1 深度可分离卷积
采用深度可分离卷积,大幅度降低参数数量。
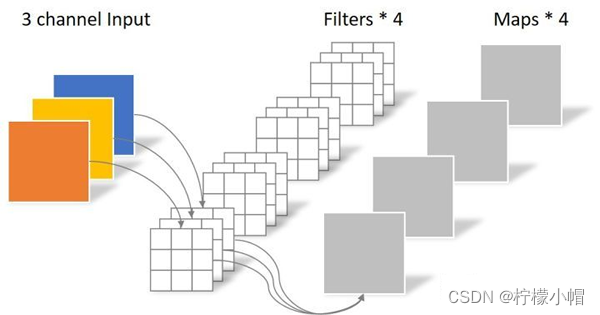
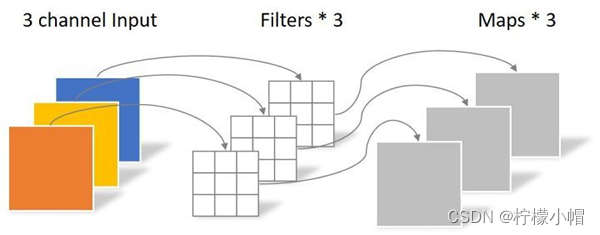
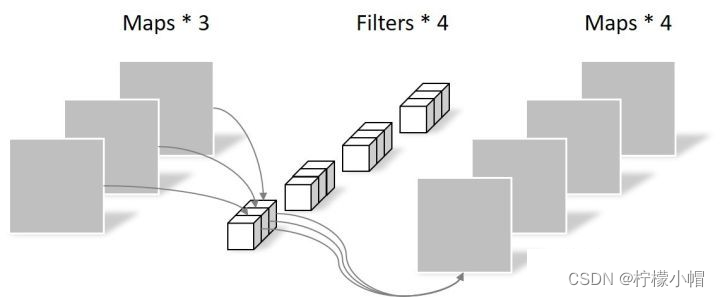
深度可分离卷积分为两步:第一步逐通道卷积(参数数量3 × 3 × 3 = 27),第二步逐点卷积(参数数量1 × 1 × 3 × 4 = 12),输出4个特征图,共39个参数。
3.4.4.2 网络结构
-
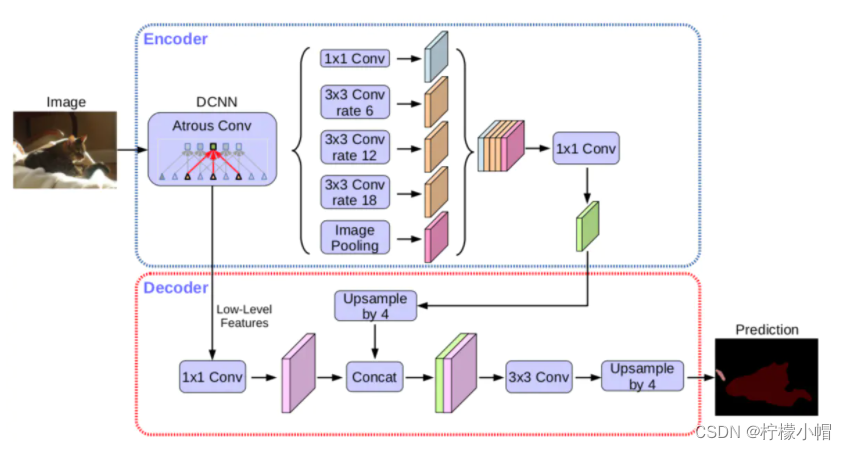
Encoder:同DeepLabv3。
-
Decoder:先把encoder的结果上采样4倍,然后与resnet中下采样前的Conv2特征进行concat融合,再进行3*3卷积,最后上采样4倍得到输出结果。
-
融合低层次信息前,先进行1*1卷积,目的是减少通道数,进行降维。
-
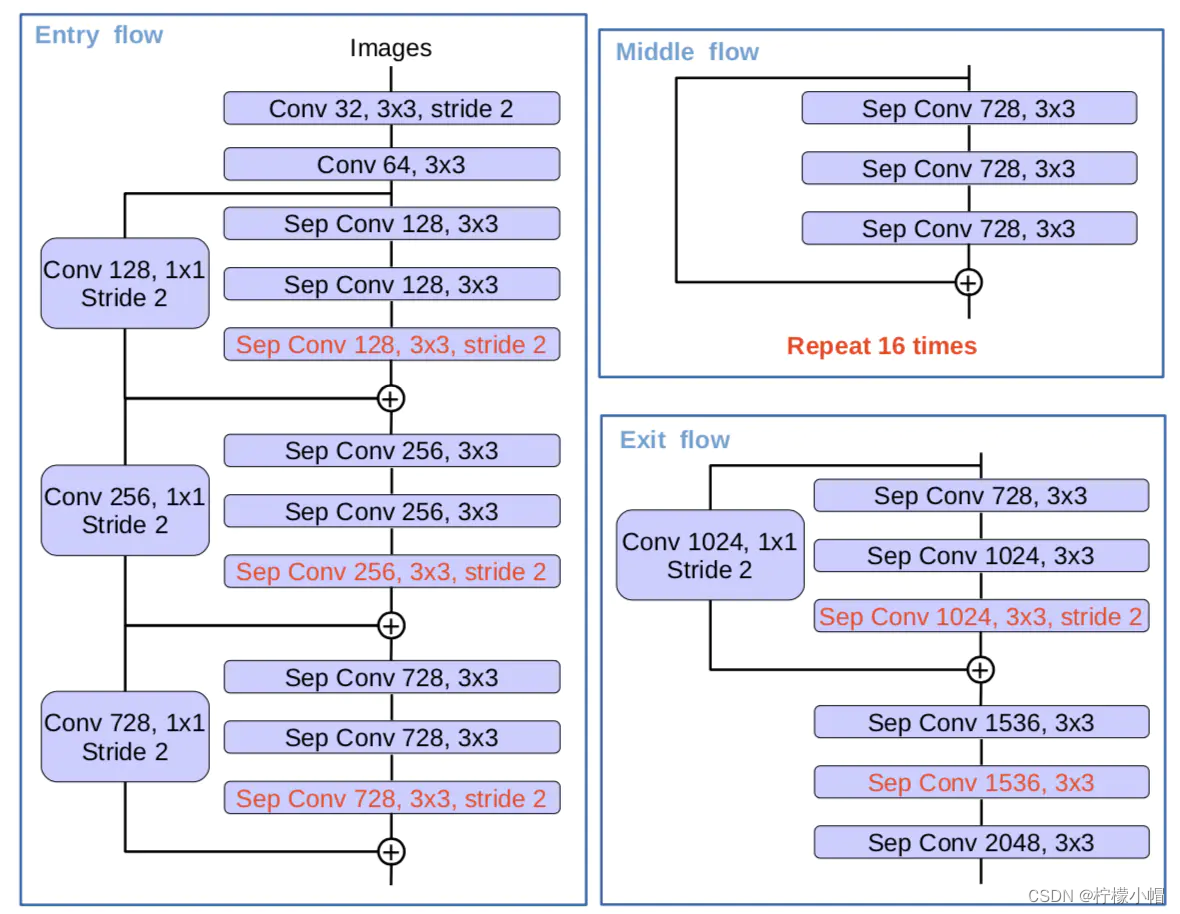
主干网部分:采用更深的Xception网络,所有max pooling结构为stride=2的深度可卷积代替;每个3*3的depthwise卷积都跟BN和Relu。改进后的主干网结构如下:
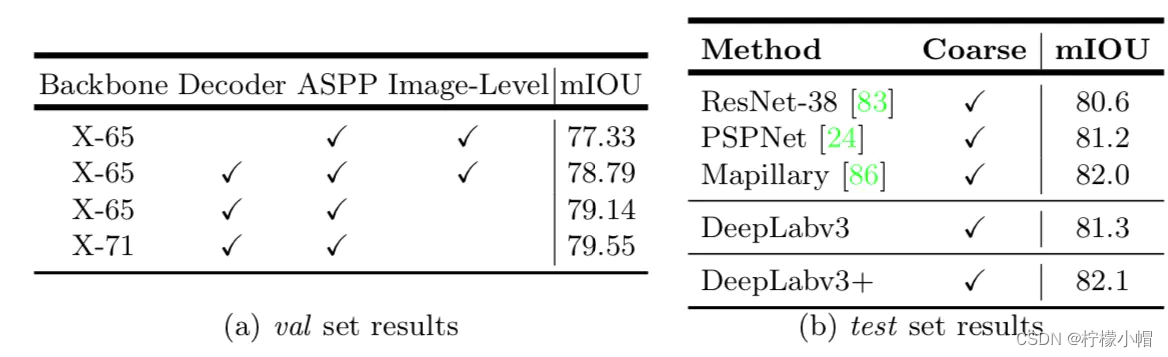
3.4.4.3 结果
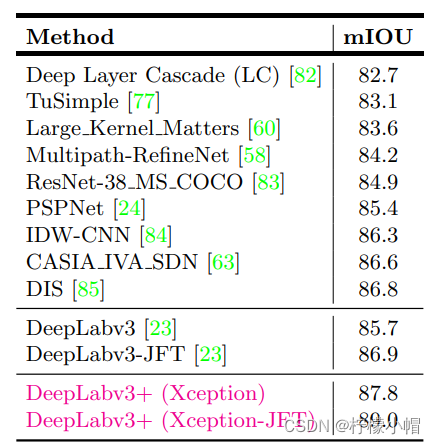
- 与其它模型的对比
- 在Cityspaces数据集上实验结果如下:
- 分割效果展示(最后一行是失败的分割)

3.5 其它模型
4. 数据集
4.1 VOC2012
Pascal VOC 2012:有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割。
4.2 MSCOCO
是一个新的图像识别、分割和图像语义数据集,是一个大规模的图像识别、分割、标注数据集。它可以用于多种竞赛,与本领域最相关的是检测部分,因为其一部分是致力于解决分割问题的。该竞赛包含了超过80个物体类别。
4.3 Cityscapes
50 个城市的城市场景语义理解数据集,适用于汽车自动驾驶的训练数据集,包括19种都市街道场景:road、side-walk、building、wal、fence、pole、traficlight、trafic sign、vegetation、terain、sky、person、rider、car、truck、bus、train、motorcycle 和 bicycle。该数据库中用于训练和校验的精细标注的图片数量为3475,同时也包含了 2 万张粗糙的标记图片。
4.4 Pascal Context
有 400 多类的室内和室外场景。
4.5 Stanford Background Dataset
至少有一个前景物体的一组户外场景。
5. 图像分割标注工具
labelme
-
安装
pip3 install labelme -
运行
labelme -
运行界面

6. 代码实现
(见专栏 -> 全栈资料包 -> 资源包/03_dl/DeepLab3_plus.zip)
7. 附录:术语表
| 英文简称 | 英文全称 | 中文名称 |
|---|---|---|
| Semantic Segmentation | 语义分割 | |
| Instance Segmentation | 实例分割 | |
| Panoptic Segmentation | 全景分割 | |
| ASPP | Astrous Spatial Pyramid Pooling | 空洞金字塔池化 |
| FOV | Field of View | 视野 |
| CRF | Fully-connected Conditional Random Field | 全连接条件随机场 |
| DSC | Depthwise Separable Convolution | 深度可分离卷积 |