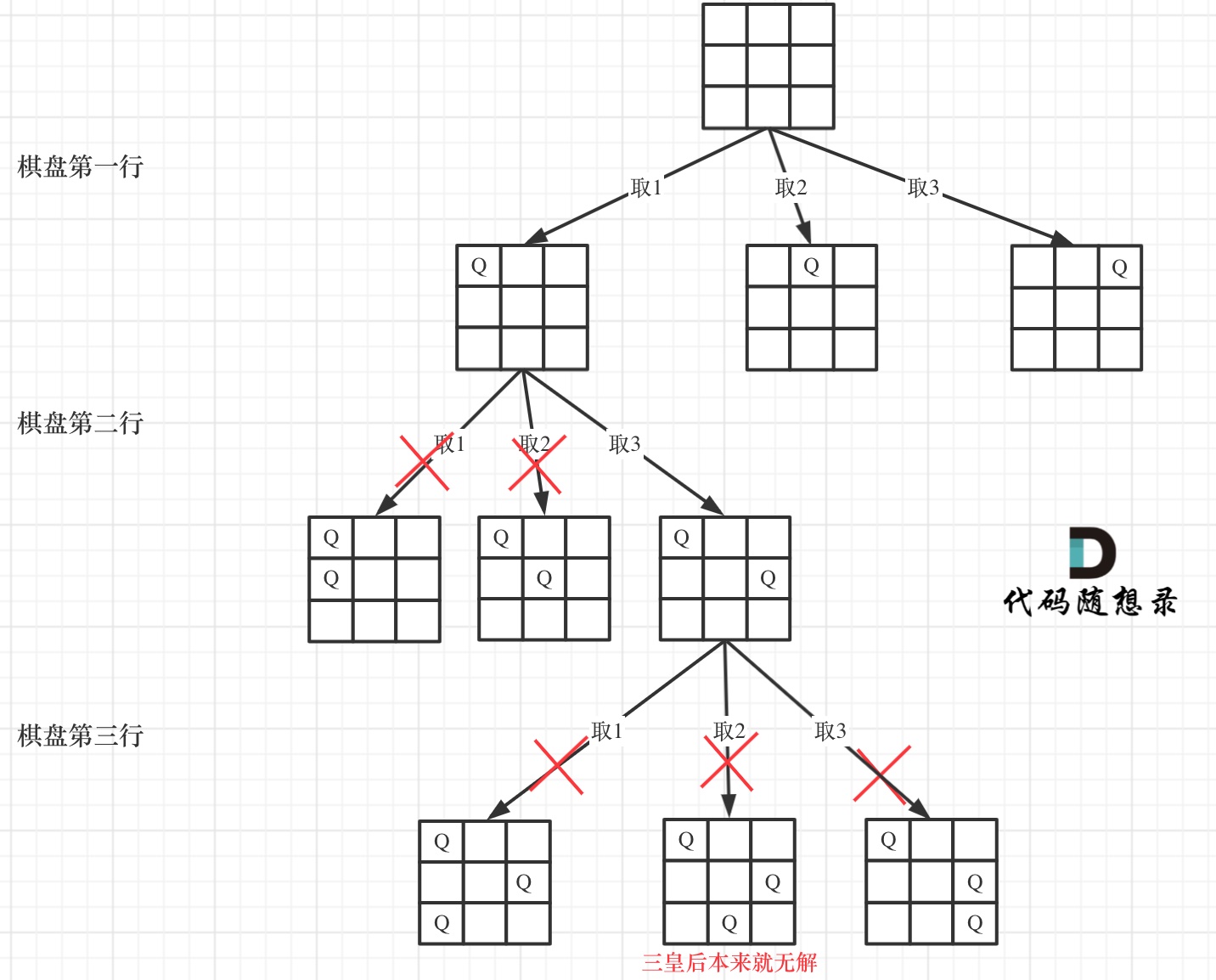
Logistic 回归是线性回归中一个很重要的部分。
Logistic 函数:
\[\sigma(x) = \frac {L} {1 + \exp(-k(x - x_0))}
\]
其中:
- \(L\) 表示最大值
- \(x_0\) 表示对称中心
- \(k\) 表示倾斜度

一般来说,都将 \(L\) 设为 \(1\),而 \(k\) 和 \(x_0\) 在参数中控制。
认为特征只有一个,那么自然:
\[p(y = 1 | x) = \sigma(\omega_0 + \omega_1 x) = \frac 1 {1 + \exp(\omega_0 + \omega_1 x)}
\]
认为 \(\vec x\) 是特征向量,并且是增广向量,也就是:
\[\vec x = \begin{bmatrix}
x_0 & x_1 & \ldots & x_c & 1
\end{bmatrix}
\]
认为参数向量也是增广的:
\[\omega = \begin{bmatrix}
\omega_0 \\
\omega_1 \\
\vdots \\
\omega_c \\
1
\end{bmatrix}
\]
那么:
\[p(y = 1 | \vec x) = \sigma(\vec x \omega) = \frac 1 { 1 + \exp(\vec x \omega)}
\]
对于多组数据,\(X = \begin{bmatrix} \vec x_0 \\ \vec x_1 \\ \ldots \\ \vec x_m \end{bmatrix}\):
\[p(\vec y = 1 | X) = \sigma(X \omega)
\]
注意最终得到是一个向量,\(\sigma\) 函数作用于向量中的每个单独的元素。
利用交叉熵作为损失函数:
\[R(\omega) = - \frac 1 m \sum_{n = 1}^m \left(y_n \log \hat y_n + \left(1 - y_n \right)\log \left(1 - \hat y _n \right) \right)
\]
其中 \(\hat y\) 表示预测分类,而 \(y\) 表示实际分类。
由于 \(\sigma'(x) = \sigma(x)(1 - \sigma(x))\),自然的可以推出其偏导数:
\[
\begin{aligned}
\frac \delta {\delta \omega} R(\omega)
&= - \frac 1m \sum \left( y_n \frac {\hat y_n (1 - \hat y_n)}{\hat y_n} x_n + (1 - y_n) \frac {- \hat y_n (1 - \hat y_n)}{1 - \hat y_n} x_n \right) \\
&= - \frac 1m \sum \left( y_n - \hat y_n \right) x_n \\
\end{aligned}
\]
写成向量形式也就是:
\[- \frac 1 m (\hat y - y) \cdot x
\]
于是利用梯度下降算法:
\[\omega = \omega - \frac \alpha m X {\Large (}\sigma(X \omega) - y{\Large )}
\]
代码和梯度下降函数十分相似。
Feature Mapping
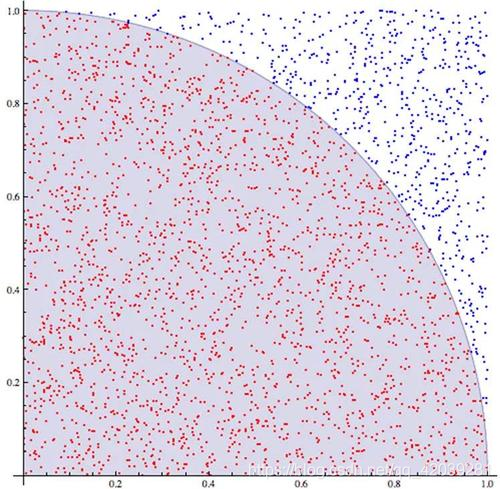
合理的利用线性回归可以解决很多复杂的问题。

大概率我们需要一个类似于圆的东西才可以拟合。
考虑到在高中我们学过:
\[C: Ax^2 + B y^2 + C x + D y + F =0
\]
可以表示一个圆,那么我们就可以利用重映射:
\[(x, y) \to \begin{bmatrix} 1 & x & y & xy & x^2 & y^2 \end{bmatrix}
\]
的方式将特征向量进行一点点简单的变换,那么自然就变成了对于多个参数的线性回归问题,一种可能的拟合是:

当然,我们也可以更复杂的利用这些参数,例如 \(x^3\),\(\sqrt x\),\(\frac 1 x\) 之类的参数,这取决于我们想要如何去拟合。
正则化参数
和平方损失函数的正则化方式一模一样,见 机器学习笔记(1): 梯度下降算法
Softmax Regression
其实就是多分类的 Logistic 回归:
\[p(y = c | \vec x) = {\rm softmax}(\vec x W) = \frac {\exp(\vec x W_c)}{\sum_{k = 1}^C \exp(\vec W_k)}
\]
其中 \(C\) 表示分类数,而 \(W = \begin{bmatrix} \omega_1 & \omega_2 & \ldots & \omega_C \end{bmatrix}\),其中 \(\omega_i\) 就表示某一个 Logistic 函数的参数。
由于其实就是多个 Logistic 函数,所以其偏导数和参数学习过程非常相似:
\[W = W - \frac \alpha m X \left( \sigma(X W) - Y \right)
\]
值得注意的是,对于每一个 \(\omega_i\) 减去同一个 \(\theta\) 结果不会改变,意味着一般都需要正则化。

![[UE 虚幻引擎] DTLoadFbx 运行时加载FBX本地模型插件说明](https://dt.cq.cn/wp-content/uploads/2024/05/image-1.png)