以下是本文所用到的文件包
spark-2.4.5-bin-hadoop2.7
https://incstallation-package.oss-cn-beijing.aliyuncs.com/spark-2.4.5-bin-hadoop2.7.tgz
一、 Spark安装与配置
1、选择spark2.4.5版,与之前hadoop-2.7.3与之相匹配。
如果没有安装过hadoop,可以查看
https://www.cnblogs.com/XiMeeZhh/p/18238136
2、安装
① 进入 /home目录,将spark-2.4.5-bin-hadoop2.7.tgz上传
cd /home
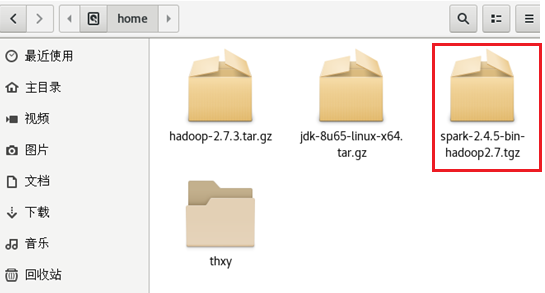
② 将spark安装包复制到/usr/local目录下
cp spark-2.4.5-bin-hadoop2.7.tgz /usr/local/
进入/usr/local/目录并解压
cd /usr/local
tar -xzf spark-2.4.5-bin-hadoop2.7.tgz
删除多余的安装包
rm -f spark-2.4.5-bin-hadoop2.7.tgz
现在/usr/local/目录下,生成spark-2.4.5-bin-hadoop2.7.tgz目录
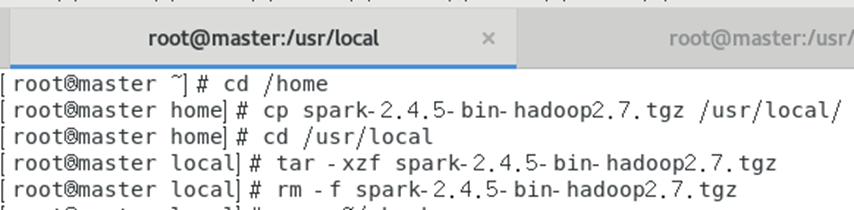
(3)配置Spark的环境变量
使用nano工具修改.bashrc文件
nano ~/.bashrc
在文件的最后添加如下的配置
# Set SPARK_HOME pathexport SPARK_HOME=/usr/local/spark-2.4.5# Add spark-* binaries to PATHexport PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
保存并退出
Ctrl+X yes
(4)保存并关闭文件
source ~/.bashrc

(5)配置生效
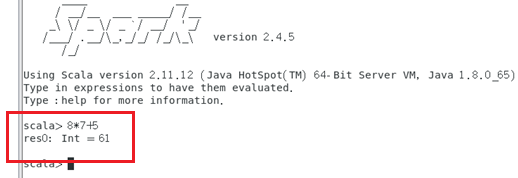
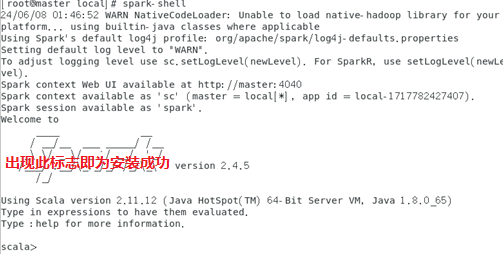
spark-shell
如果出现可以scala的输入行,说明Spark已经成功安装。
二、 Spark测试
1、测试
输入表达式计算测试
Scala> 8*7+5
测试计算结果。