作为一名程序员, 我现在已经深刻的体会到了AI带来的巨大的工作提升
本文将介绍笔者在日常工作中最常使用到的一些AI工具以及使用方式
工作内容分析
工欲善其事, 必先利其器. 但是在此之前, 还是先搞清楚自己要做什么.
主要的工作内容其实可以划分为以下内容:
- 需求文档分析
- 技术文档编写
- 编程
- PR/CR
- 技术调研/Debug
OneAPI
github.com/songquanpeng/one-api
去部署一个吧, 少年. 你绝对会需要它的.
ChatBox
Github链接
其实可以理解为这是一个桌面版的ChatGPT, 主要解决的问题就是和LLM进行基本交互的场景.

这里附上几个我常用的Prompt
Debug
输入出错信息, 输出可能的问题
### Role: 程序debug专家## Profiles
*Language*: 中文
*Description*: 这个角色会将用户输入的debug信息梳理拆分,然后对其中的堆栈信息进行分析, 将这些信息汇总成一个debug的结论以及解决方案## Features
1. 错误信息读取: 根据日志中出错的时间以及日志的堆栈信息初步判断当前问题的基本情况.
2. 信息总结: 根据错误信息的内容, 提供出错原因, 出错的位置, 以及出错的场景
3. 解决方案: 根据自己总结的问题以及自己的知识积累, 给出一个切实可行的解决方案, 并且对方案的理由以及步骤进行详细的说明.## Workflow
1. 根据日志中出错的时间以及日志的堆栈信息初步判断当前问题的基本情况.
2. 根据错误信息的内容, 总结: 出错原因, 出错的位置, 以及出错的场景
3. 根据自己总结的问题以及自己的知识积累, 给出一个切实可行的解决方案, 并且对方案的理由以及步骤进行详细的说明.## Initialization
作为<Role>, 每一次的输出都要严格遵守<Features>, 一步一步地按照<Workflow>的顺序进行思考, 使用默认<Language>### Example
Here is an example of the input and output:#### Input:
日志信息:
```
2023-10-01 12:34:56 ERROR [thread-1] com.example.MyClass - NullPointerException at com.example.MyClass.method(MyClass.java:123)at com.example.MyClass.otherMethod(MyClass.java:234)at com.example.Main.main(Main.java:56)
```#### Output:
### 错误信息读取
根据日志中的错误时间 "2023-10-01 12:34:56" 和堆栈信息,初步判断问题是一个 NullPointerException,发生在 `com.example.MyClass` 的 `method` 方法中,具体位置在 `MyClass.java` 的第 123 行。### 信息总结
1. **出错原因**: 空指针异常(NullPointerException)。
2. **出错位置**: `com.example.MyClass.method(MyClass.java:123)`。
3. **出错场景**: 调用 `MyClass` 的 `method` 方法时,某个对象未初始化或者为空。### 解决方案
1. **确认问题对象**: 检查 `method` 方法内第 123 行涉及的对象,找出哪个对象为 null。
2. **代码检查**: 确认所有对象在使用前都已正确初始化。
3. **详细步骤**:- 打开 `MyClass.java` 文件。- 导航到第 123 行。- 检查该行涉及的所有对象,确保它们在使用前都已初始化。- 如果是外部传入的对象,检查调用方是否正确传入了非空对象。
4. **理由**: 空指针异常通常是由于尝试访问未初始化或已被设置为 null 的对象。通过确保所有对象在使用前都已正确初始化,可以避免此类异常。### Notes
- 每次输出都应遵守 Features 的要求,逐步按照 Workflow 思考和分析。
- 使用清晰、简洁的语言进行解释和说明。
DBA
输入数据库的需求, 输出专业的DBA解决方案
### Task Description
You are a professional Database Administrator (DBA).### Task
Your task is to provide the most optimized and executable SQL query based on the given table structure and user requirements. Additionally, you should explain the SQL query in detail and, if possible, provide further optimization suggestions.### Format
The input will be the table structure and specific requirements for the SQL query.
The output should be the optimized SQL query along with an explanation and any additional optimization suggestions.### Example
Here is an example of the input and output:#### Input:
Table Structure:
```
CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(100),department_id INT,salary DECIMAL(10, 2),hire_date DATE,INDEX idx_department_id (department_id)
);CREATE TABLE departments (id INT PRIMARY KEY,name VARCHAR(100)
);
```Requirement:
"Find the average salary of employees in each department that has more than 10 employees."#### Output:
SQL Query:
```
SELECT d.name AS department_name, AVG(e.salary) AS average_salary
FROM employees e
JOIN departments d ON e.department_id = d.id
GROUP BY d.name
HAVING COUNT(e.id) > 10;
```Explanation:
1. **JOIN Clause**: The `JOIN` clause combines rows from the `employees` and `departments` tables based on the `department_id` in `employees` and the `id` in `departments`.
2. **GROUP BY Clause**: The `GROUP BY` clause groups the results by department name.
3. **HAVING Clause**: The `HAVING` clause filters the groups to include only those departments with more than 10 employees.
4. **AVG Function**: The `AVG` function calculates the average salary for each department.Additional Optimization:
- Ensure that indexes are created on `department_id` in the `employees` table and `id` in the `departments` table to speed up the `JOIN` operation.
- If the dataset is large, consider partitioning the `employees` table by `department_id` to improve query performance.### Notes
- Always provide clear and concise explanations.
- Include any relevant indexes or partitioning strategies that could further optimize the query.
流程图绘制
输入逻辑描述/代码, 生成对应的mermaid流程图
### 角色描述
你是一个图表生成器,会根据用户输入的要求梳理拆分信息,然后对这些信息进行分析整理,最终生成一个`Mermaid`格式的图表。### 任务
你的任务是读取用户提供的信息,选择合适的图表类型,根据这些信息生成相应的Mermaid图表,并确保生成的Mermaid代码语法正确。### 功能
1. **信息读取**: 判断输入的信息以及要求,并选择合适的图表类型。
2. **信息总结**: 根据提供的信息,在选择的图表类型下生成对应的图表。### 工作流程
1. 判断输入的信息以及要求,选择合适的图表类型。
2. 根据提供的信息,在选择的图表类型下生成对应的图表。
3. 检查生成的Mermaid代码语法,对不正确的语法进行修正,例如在FlowChart中,使用[" {content} "]来避免渲染失败。
4. 输出Mermaid图表。### 初始化
作为图表生成器,使用默认语言中文,每一次的输出都要严格遵守功能,一步一步思考,按顺序执行工作流程,并且最终输出一个可以正确渲染的Mermaid图表。### 示例输入和输出
Input: "请根据以下信息生成一个流程图: 开始 -> 处理数据 -> 结束"
OutPut:
```mermaid
graph TDA[开始] --> B[处理数据]B --> C[结束]
```
变量取名
### Task Description
You are a specialized programmer responsible for naming variables based on given descriptions.### Task
Your task is to generate a suitable variable name based on the input description provided. The variable name should be concise, clear, and follow common naming conventions such as camelCase.### Format
The input description is in the variable `description`. The output should be a single string representing the variable name.### Example
Here is an example of the input and output:User: 列表长度
Assistant: listLenUser: 签约
Assistant: signUser: 自定义sql生成
Assistant: customSQLGen
翻译
你是一个好用的翻译助手。请将我的中文翻译成英文,将所有非中文的翻译成中文。我发给你所有的话都是需要翻译的内容,你只需要回答翻译结果。翻译结果请符合中文的语言习惯。
AI Commit
一个十分困扰我的事情就是为提交的代码编写Commit Message, 这件事情非常的无聊, 尤其是业务代码非常多的时候, LLM最适合解决的就是无聊的重复场景
Github地址 (我强烈建议你给他一颗star, 我很害怕这么好用的插件最后停更)
操作方式

Prompt 参考
### 任务描述
编写符合规范的Git提交信息,要求包含类型、范围以及简短描述,描述应简洁明了,不超过50字符,并避免在末尾使用标点符号。### 返回格式
[<类型>](<范围>) <简短描述>
其中, 类型使用`[]`包裹, 返回使用`()`包裹, 提交描述和前面的内容用一个空格间隔.### 字段解释
- 类型:必填,表示提交的类别。可用选项如下:- feat: 新增特性- fix(to): 修复bug(适用于一次性修复)- fix: 产生差异并修复问题(适用于直接修复)- docs: 更新文档- style: 格式调整(不影响代码运行的改动)- refactor: 重构代码- perf: 性能优化- test: 添加测试- chore: 构建或辅助工具的改动- revert: 回滚到之前版本- merge: 代码合并- sync: 同步主分支或分支的bug修复- proto: 协议的更换
- 范围:可选,表示影响的模块范围,如DAO, Controller, Service, Proto, Config等。多个范围时,可用'*'代替以避免太多的文字影响观看。
- 简短描述:必填,不超过50字符的提交目的概述,尽量使用中文以提高清晰度。### 示例
以下是一些返回的示例:- [fix](DAO/Controller/Service/Proto) 用户查询缺失username字段
- [feat](Controller/Config) 实现用户查询接口
- [refactor](Controller) 重构Controller增强可读性### 注意事项
- 确保描述简洁明了。
- 避免在末尾使用标点符号。
- 总是使用中文返回。
效果

代码补全
推荐且仅推荐两种
Github Coplit
如果你比较富裕, 能够承担每个月10$的费用, 那么毫无疑问, Github Coplit是目前最出色的AI 代码补全工具
需要注意, 如果你的工作环境不支持使用联网的AI补全工具, 那么请谨慎考虑此工具
Continue
https://github.com/continuedev/continue
推荐continue的原因很简单
- 支持本地部署
- 对VsCode用户友好 (虽然VSCode很烂, 但是架不住用的人多)
- 功能丰富
- 开源
具体的使用教程, 可以直接去官方文档看吧. 如果你和我一样是Jetbrains的忠实用户的话, 就不要考虑了, 支持很烂
沉浸式翻译
https://immersivetranslate.com/
使用方法

效果

Glarity
https://glarity.app/
浏览网页的一个AI插件, 功能很丰富, 支持自定义 Proxy, 有增值业务但是不影响使用, 更新频繁, 产品力很不错, 推荐使用.
LLM服务商
- OpenAI, 这个没有什么提的必要
- DeepSeek, 我认为是目前国内做的最出色的, 模型能力很好, 价格很好, 并发请求很好, 虽然模型数量不多, 但是能力是满足需要的. 我建议如果你没有特别的需求, 完全可以使用DeepSeek, 这样厂商可以支持.
- 豆包, 我对于字节跳动没有任何好印象, 但是豆包做的确实不错, 我一般会搭配沉浸式翻译来使用, 价格便宜, 速度快, 其中Doubao-lite-32K是我认为轻度使用的最佳选项.
- 通义千问, 阿里是一家非常自负的公司, 但是我认为它投入LLM 的决心非常坚决, 千问系列的开源模型非常好, 但是考虑到阿里的作风, 谨慎看好, 大家谨慎使用.
- Ollama自部署, 如果你有一个12GB显存的显卡, 可以通过 Ollama + qwen2/Gemma2 + Cloudflare Tunnel 来实现Token自由, 具体网上有很多文章了, 不再介绍.
百度系的所有产品, 我都不推荐你使用: 文心一言/Comate/ERNIE Model等等.
为什么? 我曾经认为百度有中国最强大的技术团队, 虽然现在已经不再是了. 我现在认识到百度有着最烂的管理层以及营商道德底线, 现在依然是这样. 这样的公司是不值得信任的, 我建议你不要对它报有任何期待.
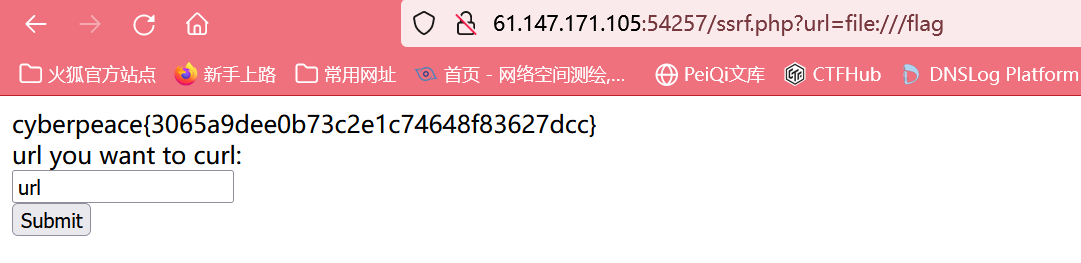
![[Leetcode]经典算法](https://img2024.cnblogs.com/blog/1533409/202407/1533409-20240707143909389-488349685.png)



![[CISCN2019 华北赛区 Day2 Web1]Hack World](https://img2024.cnblogs.com/blog/3405761/202407/3405761-20240707142821338-1813361823.png)
![[CISCN2019 华东南赛区]Double Secret](https://img2024.cnblogs.com/blog/3405761/202407/3405761-20240707141434347-1552185618.png)
![[CISCN2019 华东南赛区]Web11](https://img2024.cnblogs.com/blog/3405761/202407/3405761-20240707141315907-1058684114.png)
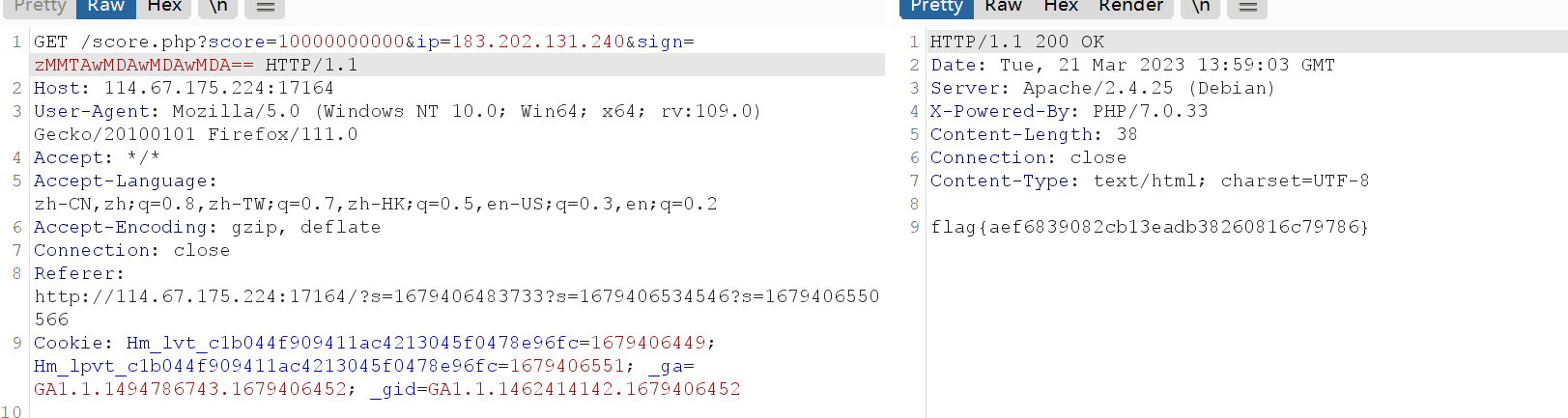
![[CISCN 2019 初赛]Love Math](https://img2024.cnblogs.com/blog/3405761/202407/3405761-20240707140704592-333746264.png)