- 前言
- 入门基本指令篇章
- man帮助手册
- 字符集设置
- cd
- ls
- date
- mkdir
- touch
- -d
- -m
- 修改主机名
- rm
- shred
- rename重命名
- mv移动
- tar打包与压缩
- 打包但是不压缩
- 打包且压缩
- 更新包文件
- 解压对应的包
- zip压缩文件命令
- cat查看
- 显示行号
- 交互写入(追加)
- 显示空行
- more和less
- head和tail
- head
- tail (能够实时监测内容)
- -F
- -f
- tac
- wc
- du
- -s
- -h
- find
- -exec
- -ok
- -mtime
- grep
- xargs -i(神器)
- 其他参数
- stat
- history
- history的工作流程
- 其他指令
- vim
- write写入
- 命令行模式搜索字符
- 取消搜索的高亮
- 替换内容
- 单行替换(替换一次)
- 单行替换(替换所有)
- 全文匹配替换(每行替换一次)
- 全文替换(全部搜索符合的都替换)
- 可视化快(进行列操作)
- 粘贴模式
- 设置和取消行号
- 复制、粘贴
- 删除和剪切
- 撤销
- 恢复
- 回到整个文档开头段
- 回到整个文档末尾段
- 回到行首
- 回到行尾
- 定位到第几行
- 命令行模式光标移动
- .swp文件
- 环境变量(个性化自定义设置)
- env 和 set
- PS1
- 临时生效
- 永久生效
- 用户bash损坏修复
- 用户管理篇章
- useradd
- passwd
- usermod
- userdel
- id
- 用户相关的配置文件
- 组管理
- groupadd
- groupmod
- groupdel
- whoami/who/w/last/lastlog
- sudo
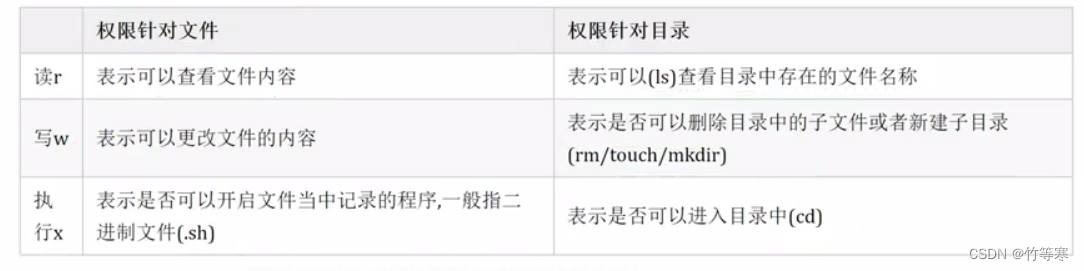
- 文件权限篇章
- 权限了解
- chmod
- 文件权限的数字表示法
- chown
- chgrp
- ln
- suid
- sgid
- sbit
- 系统服务篇章
- ssh服务
- network服务
- 配置网络服务
- 服务管理
- systemctl
- systemctl
- 总结
- service
- chkconfig
- systemctl
- systemctl
- scp文件传输服务
- ntp时间服务
- 同步时间
- 更改时区
- 定时任务
- 基本设置
- 黑白名单限制
- 进程管理篇章
- 孤儿进程
- 僵尸进程
- ps
- top
- lsof
- 找回文件之练习题
- kill
- pkill
- 后台运行命令
- 三剑客篇章
- 通配符
- find找文件与通配符
- 特殊符号
- cd路径相关
- 引号相关
- 重定向
- 命令执行
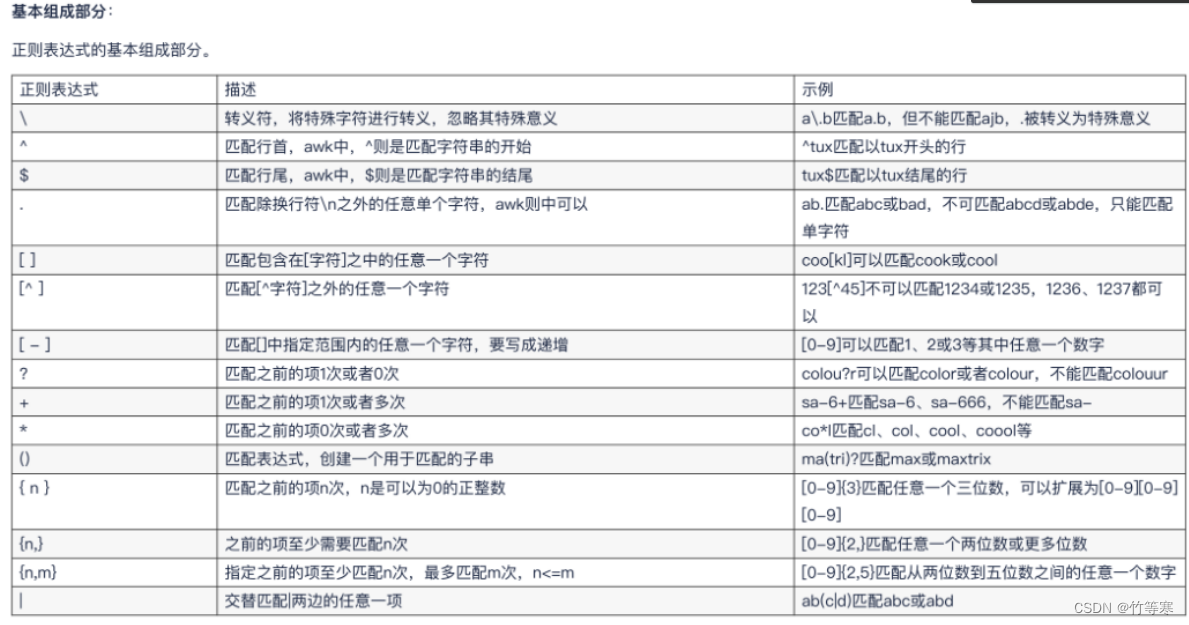
- 正则表达式
- 基本正则表达式
- 扩展正则表达式
- 注意点
- grep
- ( ) 括号、分组符。很好用!!!
- 分组与向后引用
- sed
- 参数
- 命令
- 增
- 删
- 查
- 改
- 注意
- 其他命令
- 多次编辑-e
- 写入文件w命令
- ;分号
- awk
- 动作
- NR内置变量
- NF内置变量
- 其他变量
- BEGIN 和 END
- 参数
- 动作
- 通配符
- 系统资源篇章
- 软件包篇章
- 磁盘篇章
前言
本文章仅仅是我个人学习过程中,觉得会在安全领域用的比较多的命令,也有一些本散修在Linux入门学习中的一些命令与总结心得。
道友们可参考一二我的修炼心得,切勿无脑修炼,适合自己的才是最好。
入门基本指令篇章
man帮助手册
我们可以使用命令 -h 或者命令 --help的方式查看使用文档,但是除了这种还有一种全面的手册,就是man 命令查看方式。
man 命令
比如:
man ls

其他命令都尝试查看,man手册是解释比较全面的。
字符集设置
很多shell脚本里都有这么一个语句如下
LC_ALL=C
这个变量赋值的动作,是等于还原linux系统的字符集
因为我们系统本身是支持多语言的
德文
英文
中文
每一个语言都有其特有的语言,字符,计算机为了统一字符,生成了编码表
比如你平时喜欢让linux支持中文,如果你的系统编码是中文,很可能导致你的正则出错,因此要还原系统的编码
LANG='zh_CN.UTF-8'
执行一个还原本地所有编码信息的变量
LC_ALL=C
- LC_ALL是表示设置全局变量,所以shell脚本里为了脚本不出错就会经常先设置这个
- 设置全局通用用法是输入如下指令:
export LC_ALL=C - 如果要还原就输入如下指令即可:(就是让他变回空即可)
export LC_ALL= - 要查看你是否设置成功,可以直接使用如下两个指令查看
第一个: locale第二个: 一般我们会使用$LANG变量来设置linux的字符集,一般设置为我们所在的地区,如zh_CN.UTF-8 直接echo $LANG 也可以看到你设置了哪个字符集
cd
cd ~ #当前用户的家目录
cd - #回到上次你所在的目录,比如有时候我从home目录中操作完了,然后去到/etc/目录下,然后又想回到home目录的话就要重新输入路径,这样很麻烦,那么我们就可以使用cd -,然后回到上次访问的目录
cd .. #回到上一层目录
ls
ll #能看到属性,并且以列形式查看
ls #一行一行显示文件和文件夹
ls -l == ll #-l参数加在ls等于llls/ll -a # -a参数表示查看所有文件,隐藏文件也能看到ll -d 目录名 # 只看目录的属性ls -i #显示文件的i节点号,相当于文件的身份id
date
[root@localhost ~]# date '+%F %T'
2024-06-28 14:39:39
[root@localhost ~]# date '+%F&&%T'
2024-06-28&&14:40:36
mkdir
递归创建
mkdir -p /xxx/xxx/xxx
创建单个目录,mkdir即可
touch
创建多个文件
touch 1 2 3 4
用空格隔开即可创建多个文件
可以通过批量创建 touch a{1..100}.log #会以a1.log a2.log ... 以此类推进行,同时还可以{a..z} {A..Z}
-d
-d参数可以指定时间 比如 touch -d '2024-01-01' 他的最近改动时间就会以你的时间进行创建出来
一般你想要修改时间基本使用这个就行了。
-m
-m参数,改变档案的修改时间记录,这个和-d一起使用的时候,会将文件的最近访问时间也一起修改成当前时间。
以下是实践出来的例子

修改主机名
查看主机名指令:hostname
临时修改主机名:hostname xxx
永久修改主机名:hostnamectl set-hostname xxx
rm
rm删除动作
-r 递归删除 (要删除目录的时候必须要用到)
-f 强制删除
-i 删除的时候进行提示 (因为我们alias中就已经将rm == rm -i , 所以我们使用删除rm都是自带-i参数,除非你自己改过)
shred
粉碎文件,导致文件无法恢复或者说难以通过数据恢复技术进行恢复shred file #就是粉碎一个文件,过程是将该文件输入一些二进制数据,但是该文件还在的,只是内容无法恢复回来了而已。
rename重命名
rename 源字符 替换字符 文件名
# 源字符就是在你给出的文件名的这个文件,进行找到源字符,然后使用替换字符进行替换,这样就是一个重命名过程。这个和mv进行重命名操作有点不同,rename就是直接的为重命名而生,rename可以挑选文件名中某个字符进行重命名,而mv是你给的名字就是直接覆盖源文件名。
mv移动
mv 源 目的
比如:
mv a.txt /etc/a.txt #这个就是移动过去就叫a.txt
或者
mv a.txt /etc/b.txt #这个相当于重命名,其实mv移动的时候就是相当于一个复制+重命名的操作mv a.txt /etc #这样也可以,就是把a.txt移动到etc目录下
tar打包与压缩
tar在压缩和打包过程中是可以直接将文件夹直接压缩的,不会像rm或者其他命令一样需要加一个r递归参数(zip命令压缩文件夹就需要)
tar命令
-f 必须要加的参数且加在最后,后面要跟打包的名字 tar -cvf 打包名 要打包的一些文件-c 创建包
-v 显示打包过程
-t 查看一下包中有什么文件
-u 往你包中添加文件,就是更新的意思-z 压缩包,这个是.gz格式,还有其他压缩格式
-j 压缩为.bz2格式
-J 压缩为.xz格式记住一点:f参数一定要放在所有参数后面,因为要接打包名字
打包但是不压缩
tar -cf 包名.tar 要打包的文件
打包且压缩
tar -czf 包名.tar.gz 要打包的文件
更新包文件
tar -uf 包名.tar[.gz] 要添加进去的文件
解压对应的包
解压.gz包:tar -xzf 包名
解压.bz2包:tar -xjf 包名
解压.xz包:tar -xJf 包名
以上均没有添加-v参数,但是奉劝一句,建议都加上,例子不加是因为怕混淆,加上-v既装逼又能够详细的知道解压了哪些文件出来。
zip压缩文件命令
压缩文件(普通压缩)
zip 压缩包名.zip 文件1 文件2 。。。
压缩文件夹
zip -r 压缩包名.zip 文件夹
解压缩
unzip 压缩包 #解压到当前文件夹unzip 压缩包 -d 指定解压位置 #解压到指定文件夹
cat查看
显示行号
cat -n 文件名 #查看出来的文件内容显示行号
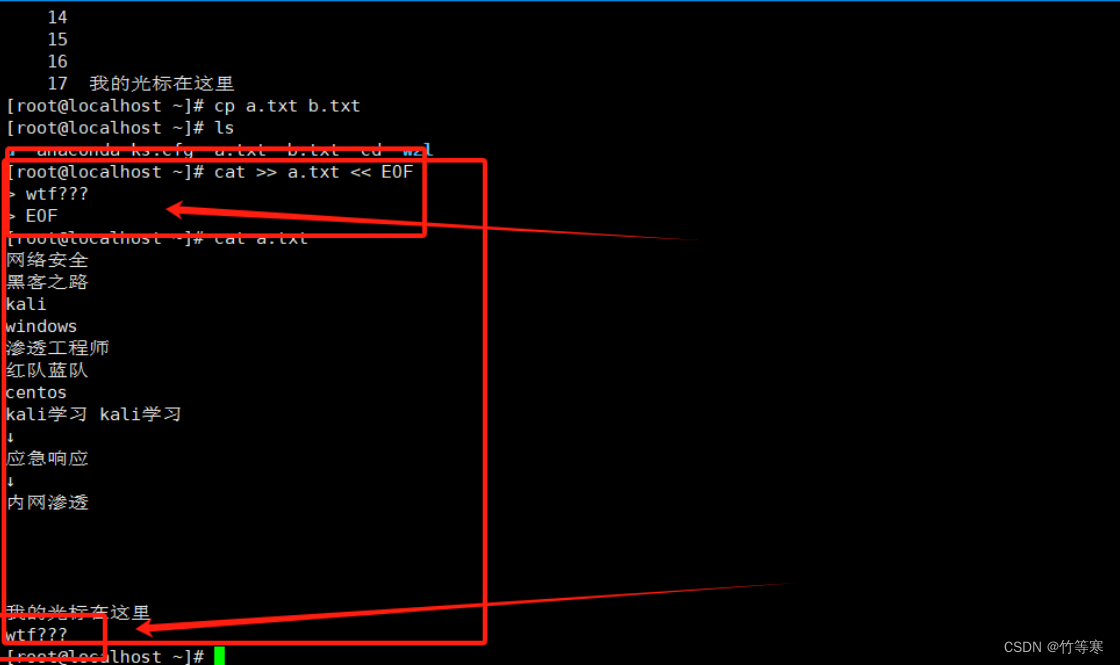
交互写入(追加)
cat >> 文件名 << EOF
这个可以进入一个交互式输入模式,用了两个>> 和<<,那就代表是追加模式,所以我们进入交互模式后输入的东西,一直到你输入EOF表示结束,然后内容就会被追加进去。
显示空行
(目前不知道谁能和它组合一起使用)
cat -b 文件名

more和less
more和cat都是一次性读取文件内容到内存中,对于大文件来说十分消耗资源。
less就是一行一行的读取,一点点的加载。
more和less的效果是一样的,只是底层加载不一样。
more是你读取完之后直接退出,less是要按q按键才能退出。
head和tail
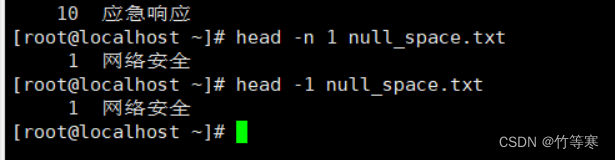
head
理解:head是想看文件头几行,tail是你新加入了文件内容后,你想看新加入的内容就使用tail
head -行数 文件名
或者
head -n 行数 文件名 #这个两个一样
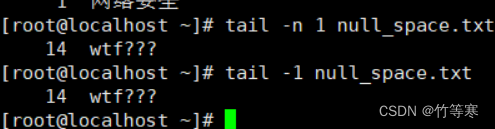
tail (能够实时监测内容)
同理
tail -行数 文件名
或者
tail -n 行数 文件名 #这个两个一样
-F
实时监测内容参数是-F
同时他还能检测还问创建的文件,这个就像是一个蜜罐一样,有人碰了一个文件,被创建出来了那就中圈套了。而-f却不可以,-f只能监测已经被创建出来的文件。
tail -F 文件名 #目前测试过好像不能加 -n参数

保存后即可就显示过来了(注意我源数据本身就有标行号,加进去后就没有行号,所以我这里是没有加-n参数的哈)
- 同时他还能完成-f的动作,实时监测程序追加进去的内容,比如追踪log日志文件。个人感觉直接用-F就行了。
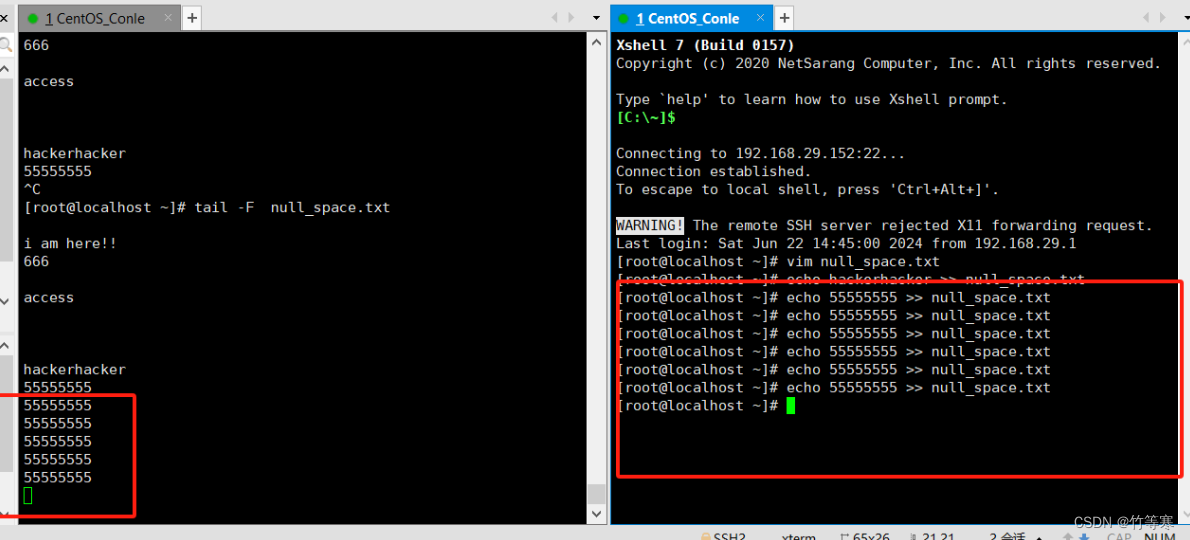
- 可以检测未存在的文件
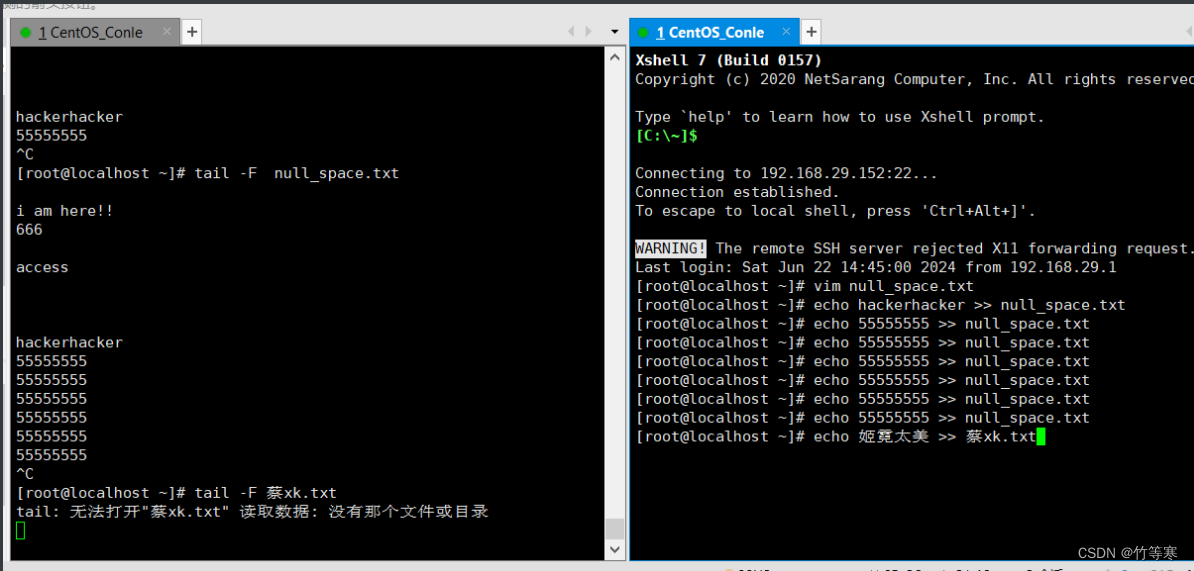
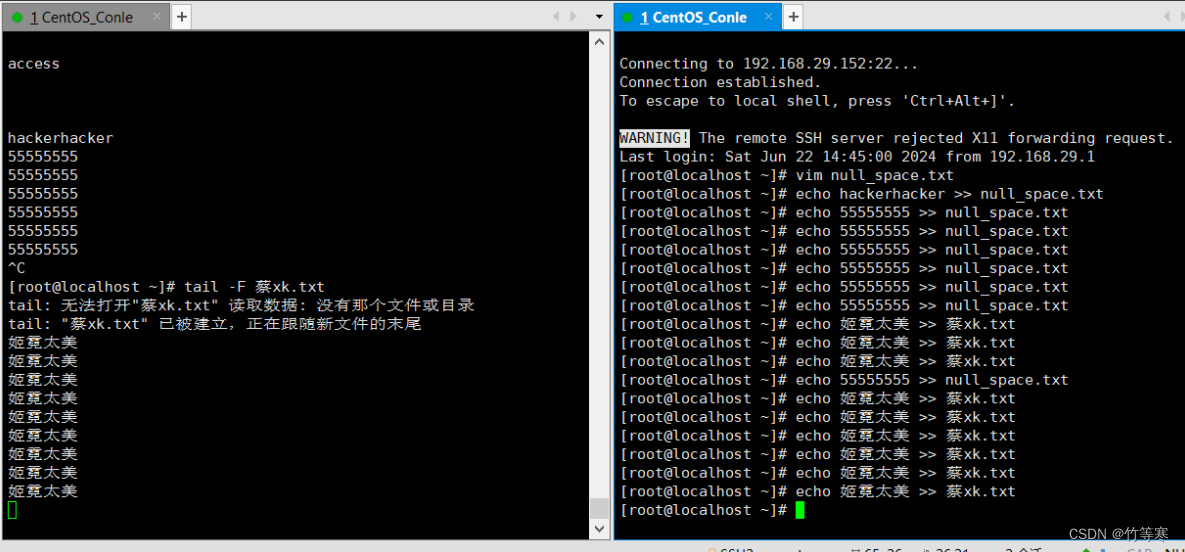
-f
只能监测已经被创建出来的文件,而-F能检测还未被创建出来的文件。
这个是程序往文件追加的时候能够显示的追踪,
比如我们echo >>追加内容就会在-f参数跟踪后显示出来,一般输入追踪log日志的比较多,-F可能协同办公用的比较多,因为大家都要保存
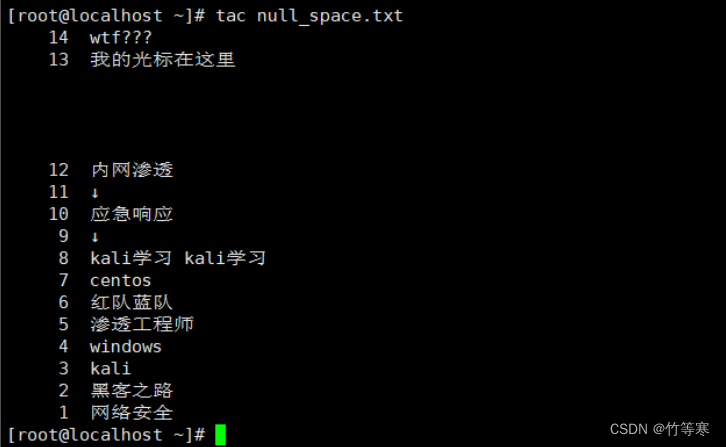
tac
文件内容倒过来读取
wc
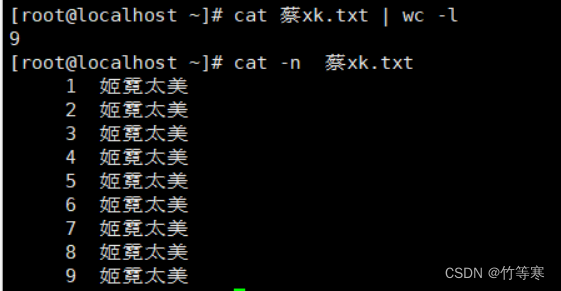
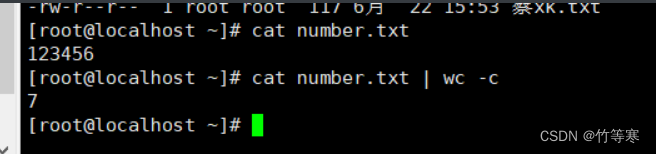
统计行数与字符数
-l 统计行数-c 统计字符数
统计行数
统计字符
du
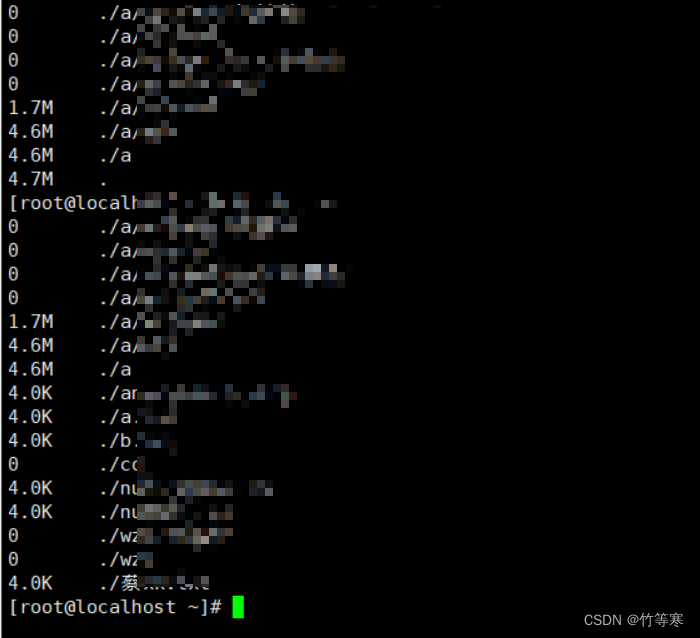
主要是用于计算文件夹大小的,du同时能够计算文件大小只是一个理所应当的功能
使用du命令一般都会将两个参数同时使用-sh,除非你要递归统计当前目录下所有文件夹分别占多大空间的时候就需要去掉s参数
下面对两个参数进行讲解
显示指定文件夹(默认当前pwd目录)或指定文件名大小
会对文件夹进行递归统计,比如从最低下的./文件夹所有文件大小的一个统计,慢慢往上./a 在往上./a/wzl文件夹一直递归
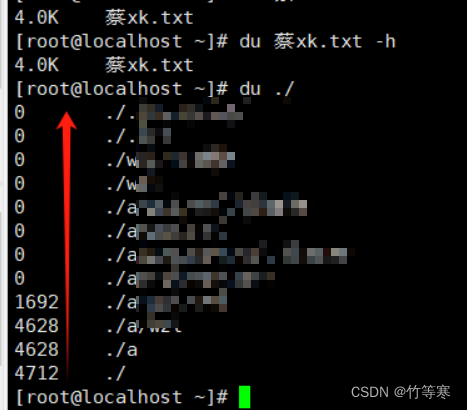
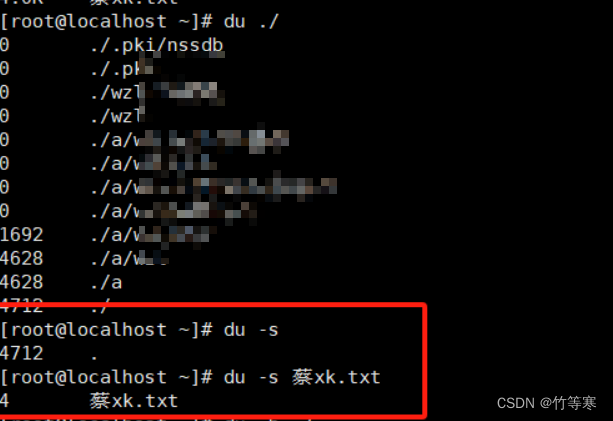
-s
只统计你给定的目录或文件夹的总大小,不会给你将所在目录所有文件夹都递归统计一遍出来
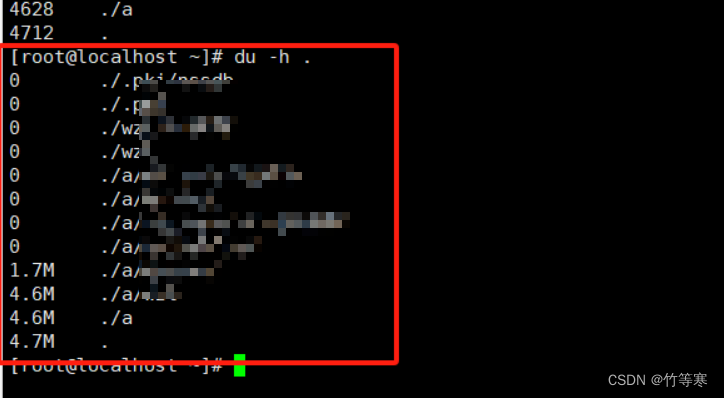
-h
统计出来的单位以m为单位
find
-tyep f 表示搜索的类型是文本类型
-type d 表示搜索的类型是文件夹类型
-type l 表示搜索的类型是软连接类型-iname 忽略文件名的大小写
-a:and 必须满足两个条件才显示
-o:or 只要满足一个条件就显示UNIX/Linux文件系统每个文件都有三种时间戳:
访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。
修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间
变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。-size 文件大小单元b —— 块(512字节)c —— 字节w —— 字(2字节)k —— 千字节M —— 兆字节G —— 吉字节其中比如 +10k 表示大于10kb的文件 -就是小于 不加符号就是等于常用查找格式:find (搜索目录位置) [-type f 搜索的类型] (-name) '文件名,可以进行模糊匹配,使用*进行模糊匹配'
例子:
-
查找 /home/ 下所有以.txt或.pdf结尾的文件
find /home/ -name "*.txt" -o -name "*.pdf" -
查找 /home/ 下所有以a开头和以.txt结尾的文件
find /home/ -name "*.txt" -a -name "a*" -
搜索最近七天内被访问过的所有文件
find /etc/ -type f -atime -7 -
搜索大于10KB的文件
find /etc/ -type f -size +10k #小于的话就把+换成-
-exec
我们find命令查找出来文件无非是将其批量操作,所以find命令提供了这些可对你查找出来的文件进行批量操作
find / -name '*.log' -exec rm -f {} \;
切记切记:\; 在尾部一定要加,固定语法,下面的-ok也是一样的哈
-ok
这个同-exec的作用,但是他在你使用rm 的时候会自动带上 rm -i参数,而-exec在你使用rm的时候不会带上-i参数,所以交互的时候可能会欠佳,除非你确定了你匹配的文件是要删除的了。
find / -name '*.log' -ok rm -f {} \; #这里相当于后面执行的rm -f -i 也就是说删除的时候会带上提示
当然exec和ok参数不仅仅能够执行rm参数而已,还可以执行其他命令,这里只是做一个提醒,rm的时候使用ok参数会带上 -i参数,当然其他指令可能也会有类似的操作。
-mtime
根据给出的时间进行查找,mtime是根据天数为单位进行查找
-
-mtime +1
表示find一天前的文件 1天前到今天都查 ,2 就是一天前到今天的文件都查
-
-mtime -1
表示find一天内的文件,2就是两天内的,这很明显了
-
-mtime 1
表示查找前1天的,仅仅是那天的文件,2就是前2天的那一天的文件
grep
后面三剑客会经常用到grep
-n 匹配出来的内容显示行号
-i 关键字匹配忽略大小写 # grep -i '关键字' 文件名
-o 显示出你筛选出来的结果,而不是grep出来的那一行数据。(这里就是为了契合正则表达式的参数)
-v 将你筛选的结果取反 (这里就是和正则表达式使用的时候取反筛选内容搭配的)
-
grep '关键字' 文件1 文件2 文件3 文件4 ...
-
grep -n '关键字' 文件名 #表示查找出你要匹配的内容然后-n表示显示找出来的内容在你文件中的行号
-
grep -n '关键字' ./* #查看当前文件夹中所有文件是否包含你要查找的关键字,但是记住grep无法查看文件夹的,只能去匹配文本文件
xargs -i(神器)
理解:xargs -i 能够将你传输过来的内容一个一个的进行传入到{}中,然后你直接使用{}进一步的执行你所要执行的命令。(用于批量处理十分方便)
#该命令能够将你过滤出来的内容进行进一步的处理#比如:
#该指令就是通过find指令找文件后,将查找到的文件 传到xargs的{}内,-i 参数要加,然后执行命令grep过滤{}传过来的文件中是否含有内容hacker,有的话直接打印出来
[root@localhost ~]# find ./ -type f -name '*.*' | xargs -i grep -n 'hacker' {}
27: new char!! hello hacker#该指令就是在grep 中多了一个-l参数,就是过滤出含有hacker的文件后,不是打印那一行内容,而是打印包含该内容的文件。
[root@localhost ~]# find ./ -type f -name '*.*' | xargs -i grep -l 'hacker' {}
./null_space.txt再举个例子:批量重命名文件
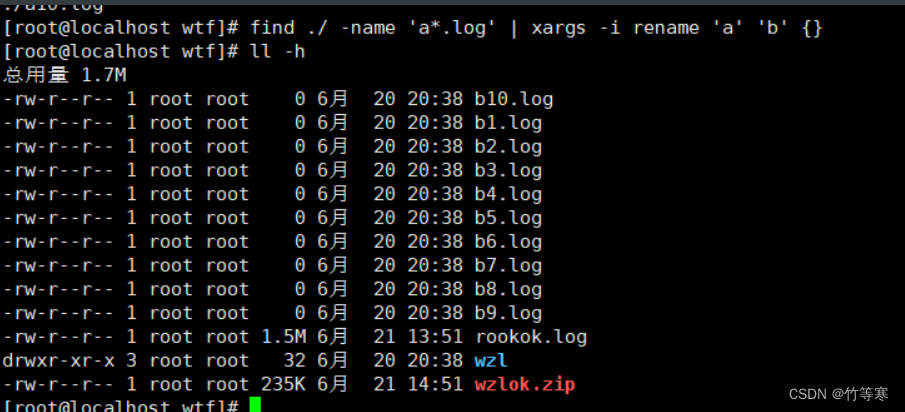
我要将所有的a*.log重命名为b*.log

find ./ -name 'a*.log' #测试是否匹配成功找到对应文件find ./ -name 'a*.log' | xargs -i rename 'a' 'b' {}
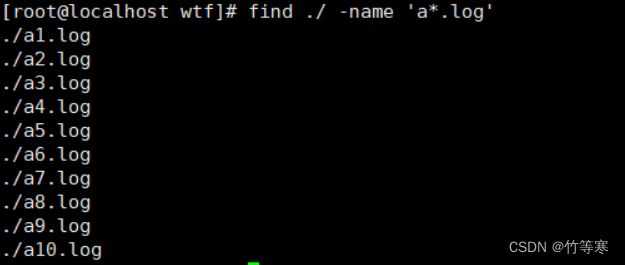
成功批量重命名
其他参数
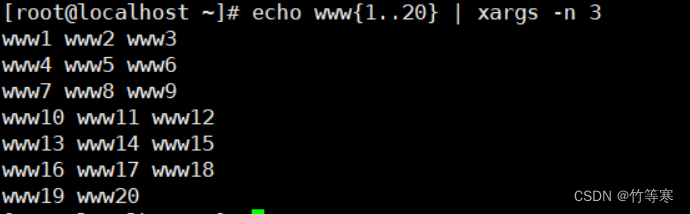
-n #表示限制每一行输出两个echo www{1..20} | xargs -n 3
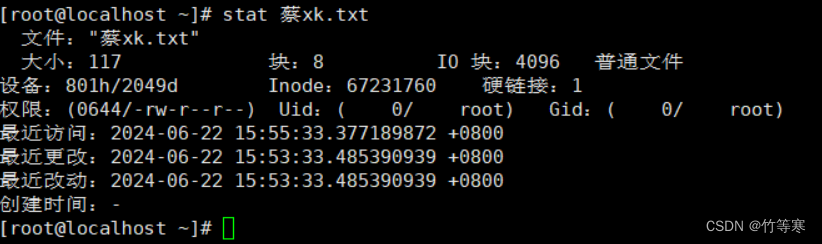
stat
可以列出文件和文件夹属性
提前提醒:modify文件内容变化会导致文件属性也改变,因为你修改了文件内容,文件属性各方面都会变!!!!
最近访问==access:最后一次读取的时间,读取命令可以是->cat / more / less / grep 等等最近改动==change:最后一次修改文件属性的时间,这些命令可以是->chmod / chown / mv 等等最近更改==modify:最后一次内容修改的时间。(只要文件内容被修改了就会更改时间)
注意:modify文件内容变化会导致文件属性也改变,因为你修改了文件内容,文件属性各方面都会变!!!!
注意下面的顺序是最近范文、最近更改、最近改动,我上面解释的顺序是访问、改动、更改,因为中文和英文版的顺序不一样
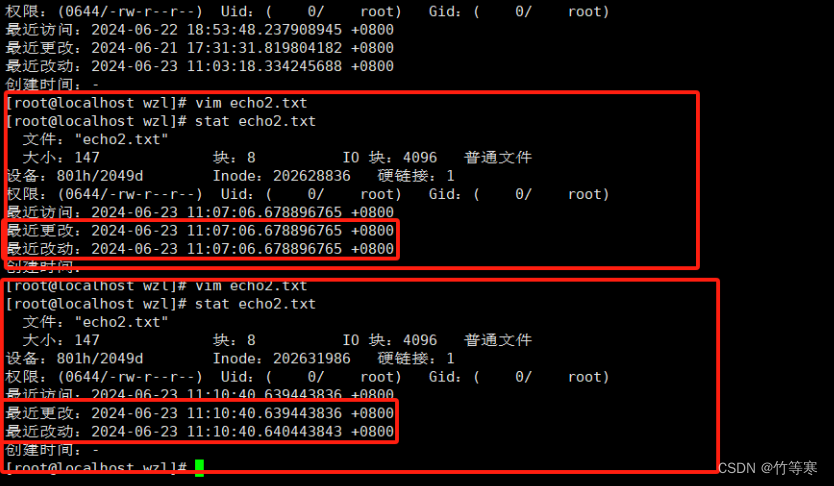
下面是文件内容修改后导致文件属性也发生变化的例子,可以看到每次修改文件内容都会导致最近改动时间也发生变化。
history
history的工作流程
首先history命令:显示的是你当前的历史指令,这些都是临时存储cat /home/用户名/.bash_history
这个文件记录的是你这个用户做的一些历史指令,如果不做任何动作,你的history历史指令是不会直接存储进去.bash_history的exit退出登录后,你的临时存储才会将历史指令存储进去(追加进去)
其他指令
history -c #清空历史指令history -W #写入.bash_history文件中,这里-w是将你的临时存储的历史指令将其文件内容覆盖掉history -r ~/.bash_history#恢复历史指令!1000 #快速查看历史指令的id,比如这个就是查看第1000条历史指令是执行了什么指令
说明:我们不小心history -c 清空了后,我们还是能够恢复回来的,history -r ~/.bash_history 就是通过该命令,即通过恢复.bash_history文件下的文件内容进行恢复的。
tips:
作为一个黑客,那么想要做到滴水不漏,可能他做的就是清空历史指令动作history -c #清空临时存储的历史指令,这样登录出去后我们之前的历史指令就不会存储进去了
history -w 或者 > .bash_history #同时还可以对其进行情况文件信息,这样做到万无一失,更加恶心的就是不断的对.bash_history文件进行内容覆盖,让其历史指令的难以数据恢回来。(> .bash_history就是写入一个空字符串进去,那不就是清空了。)总之你要抹除痕迹,那就是先清空当前临时存储的历史指令,这样才不会在你登录出去的时候又记录进去.bash_history文件中。vim
write写入
:w #表示保存不退出:w /opt/temp.txt #表示你该文件另存为/opt目录下的temp.txt文件中
注意:
:x! #表示强制写入且退出,知道即可,平时使用w q !三个已经够用了
随机记录一些vim中很容易忘记的命令
命令行模式搜索字符
命令
直接 / 或者 : -> /
下面采用 :/字符


取消搜索的高亮
:noh
替换内容
单行替换(替换一次)
单行替换需要你把光标定位到对应的行进行替换才行,而且替换一次而已。
如果进入:命令之前光标所在的行没有你要替换的字符就无法替换,根据你当前光标的行内容进行替换的。
:s/原字符/替换字符/
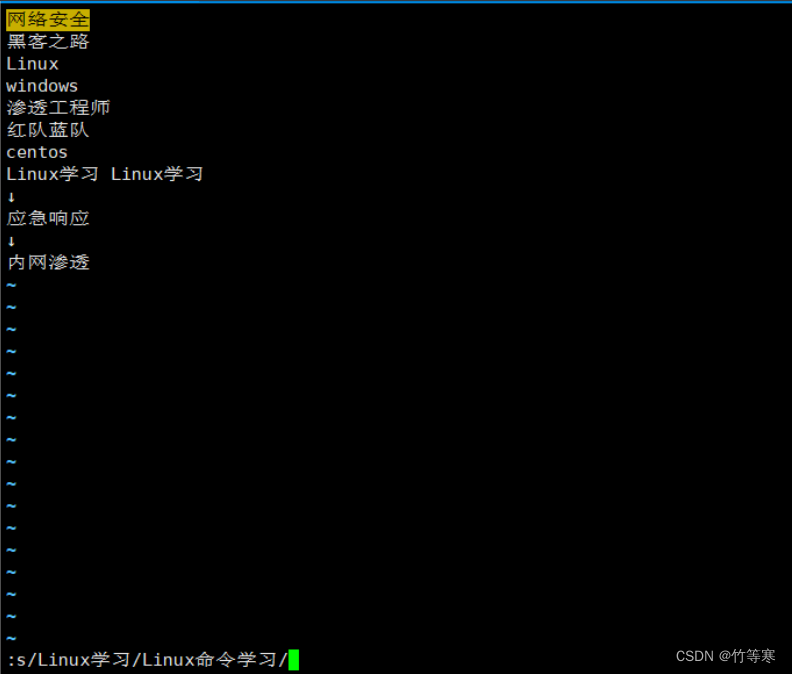
这个是光标不在那一行导致没有匹配成功的例子

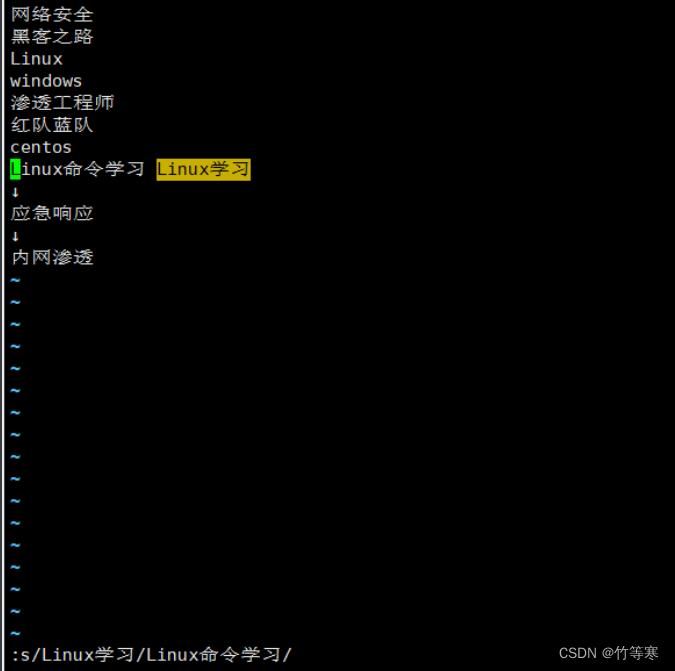
单行替换(替换所有)
只需要在最后多加一个g即可
:s/原字符/替换字符/g
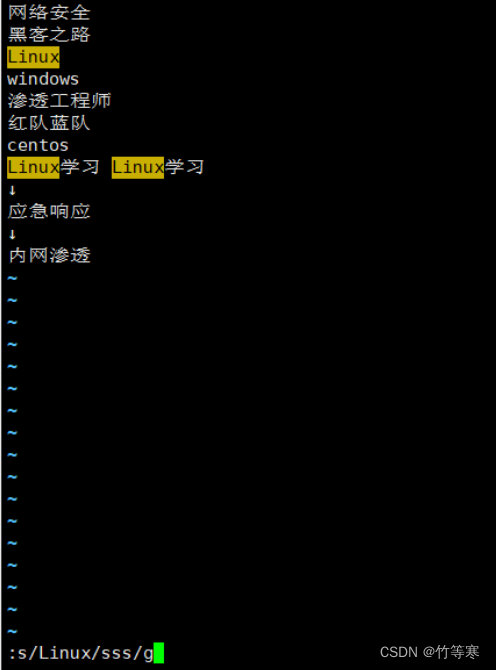
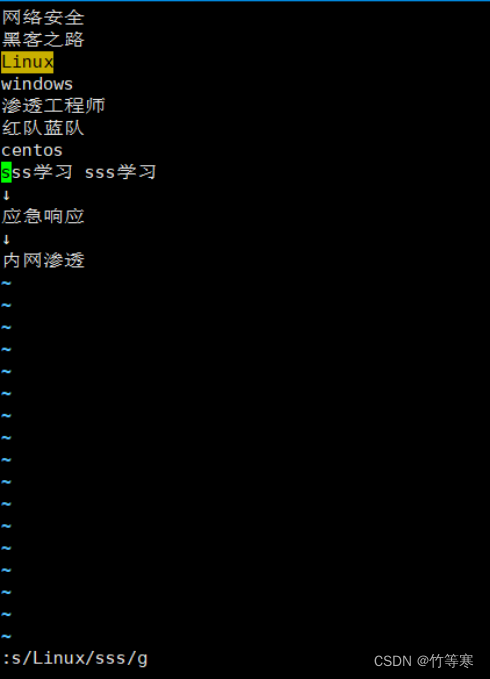
全文匹配替换(每行替换一次)
逐行查看,从第一行开始匹配到第一个就替换,接着到第二行中匹配到第一个就替换,接着第三行以此类推
:%s/原字符/替换字符/
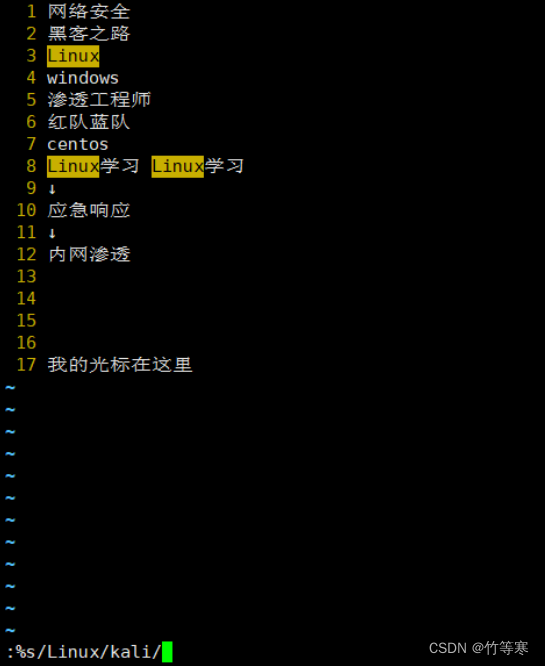
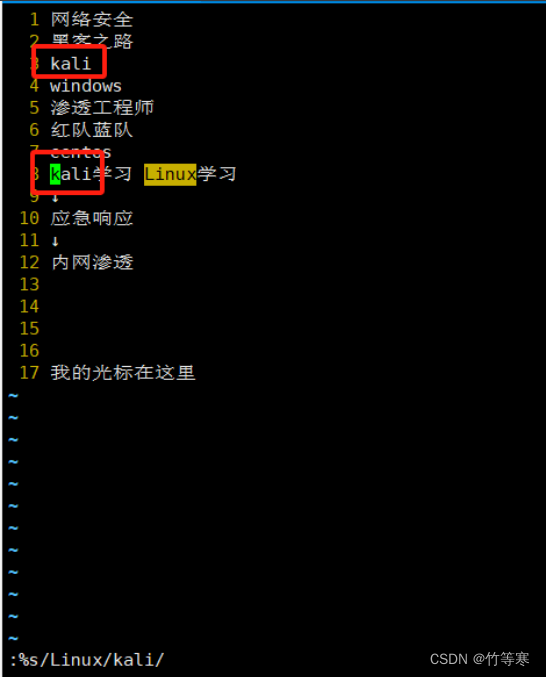
全文替换(全部搜索符合的都替换)
%s/原字符/替换字符/g
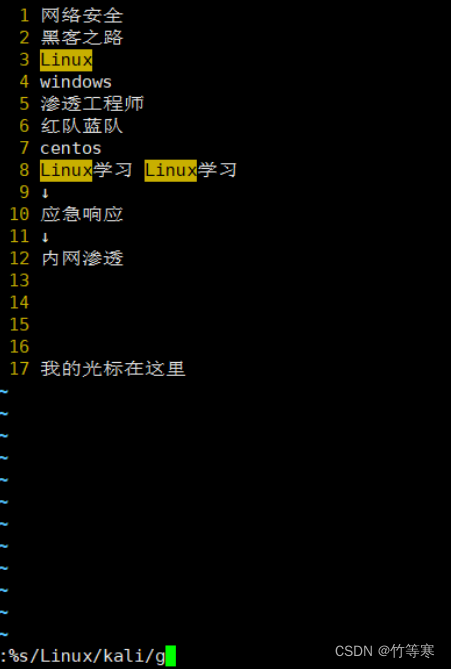
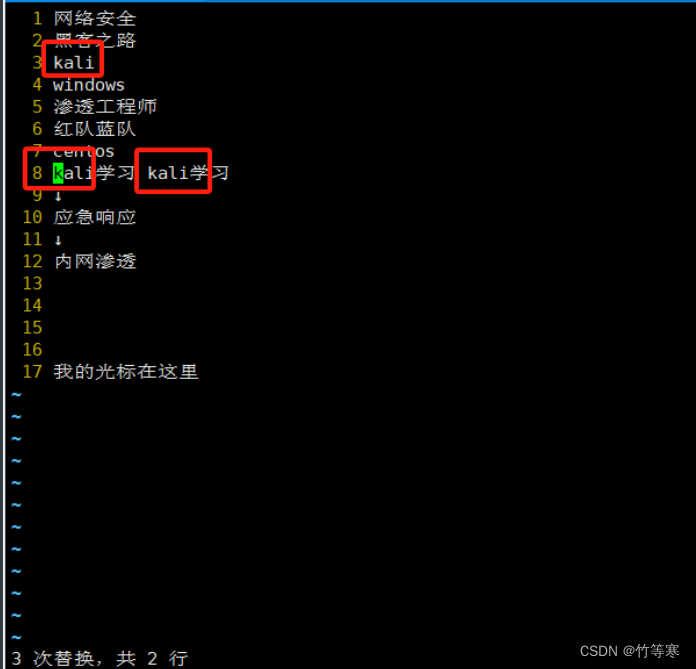
可视化快(进行列操作)
该功能是为了能够让你选择多个地方同步操作,一般是用于操作同一列上的数据,然后能够同时修改这一列的数据第一步:选择你光标位置第二步:ctrl + v进入可视化快比如我想同时操作这一列的12数字改为34
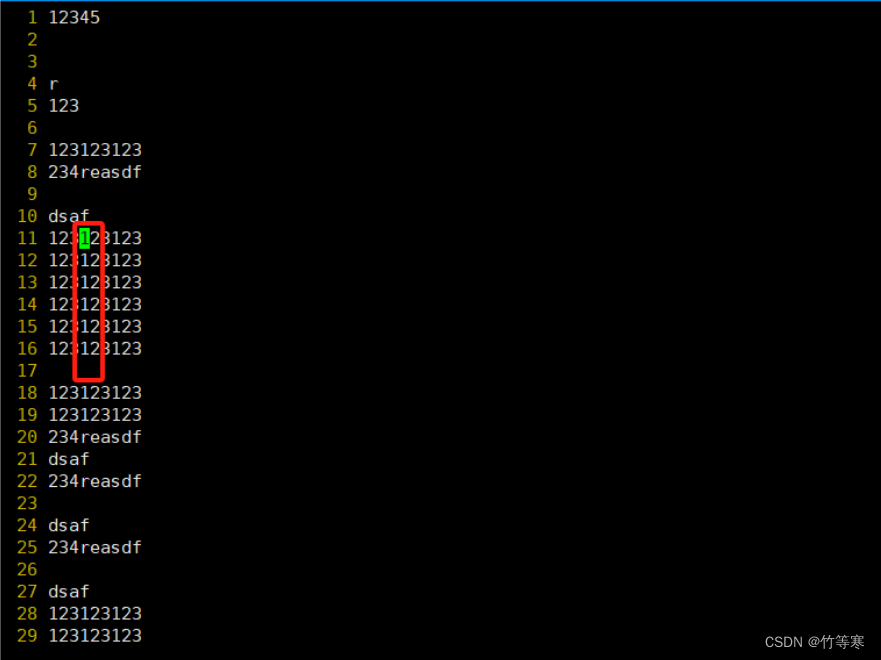
步骤都是一样的,进入可视化快后直接移动光标即可,光标移动的地方都是被标记选中
这样就是选中了你的这一列
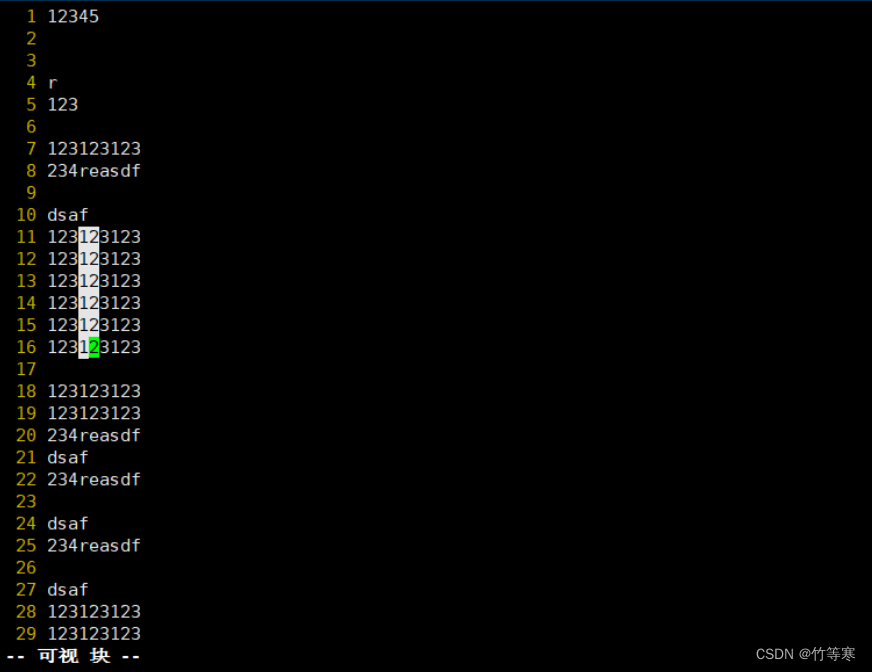
然后选好后只能进行一个命令行下的操作
按下 d 就是删除按下 y 就是复制
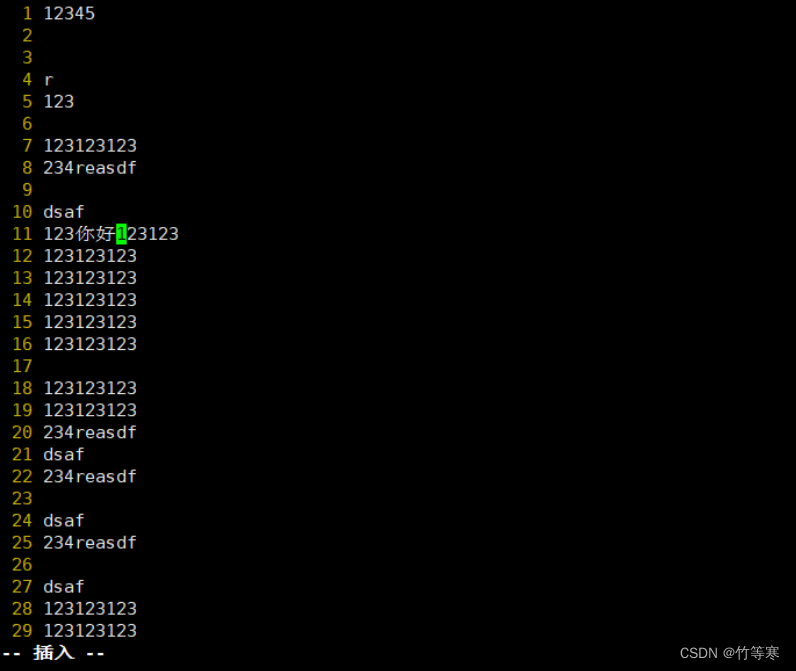
如果你要进入编辑模式
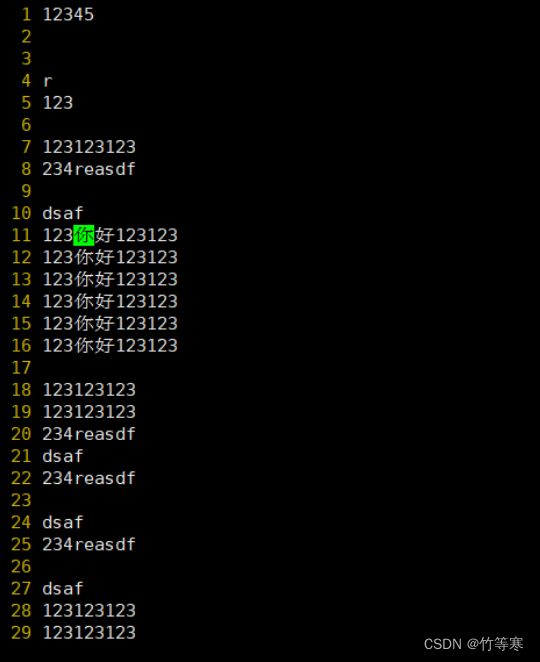
选好后按下大写的I编辑好后按两下esc键退出,就能够自动帮你批量修改好你刚刚可视化选中的内容了。这里进入编辑是只能看到编辑了一行,退出后才能看到你选中的都被修改了
然后按两下esc直接就帮你批量修改好了
粘贴模式
因为有时候如果不进入粘贴模式进行粘贴你复制好的内容的话,可能会出现一些错误。
如果是中英文的一些字符的话直接粘贴就还好,如果是你要粘贴一些配置信息,带格式的那种,最好是先进入粘贴模式再粘贴进去。
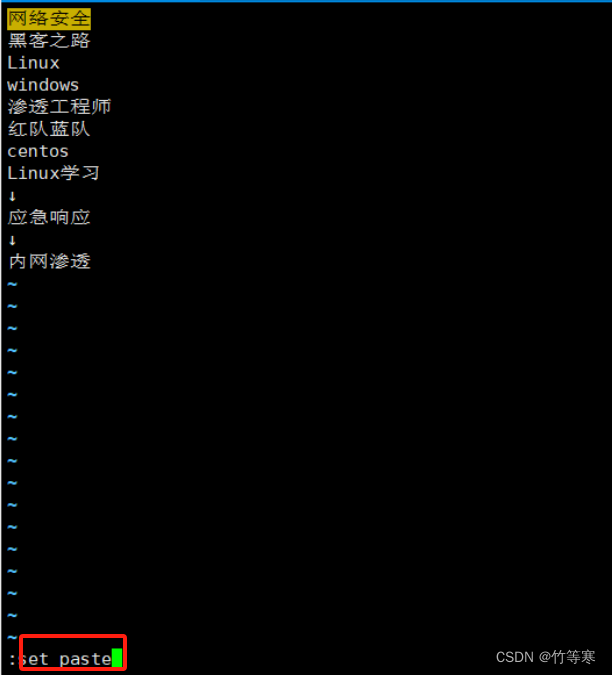
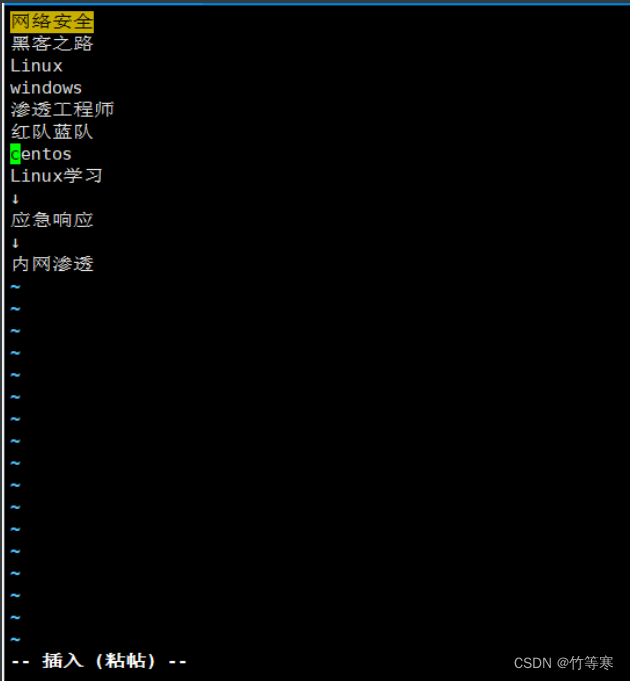
命令
:set paste
然后当你进入写模式的时候就会显示为paste模式
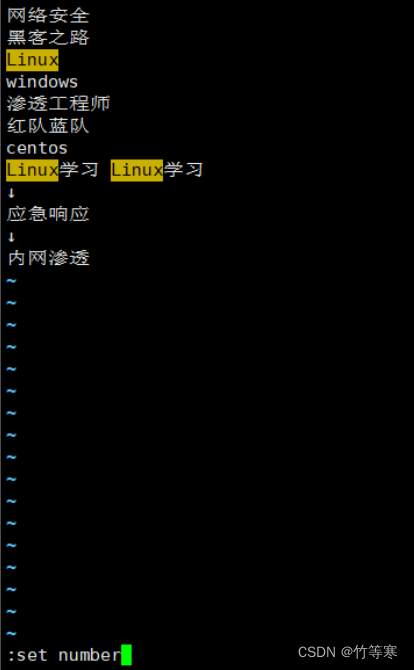
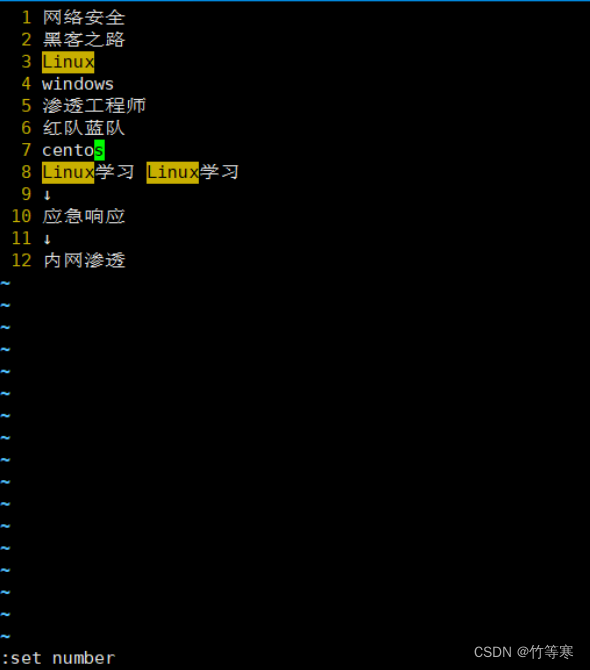
设置和取消行号
进入vim后看不到行号很烦恼?
不妨试试
:set nu
或者
:set number
取消行号就是
set nonu
或者
set nonumber
复制、粘贴
都是在命令模式下进行的
复制
yy # 复制一行
复制多行
复制那几行取决于你光标所在位置(包含光标行)
3yy == 复制你光标所在的地方三行
粘贴
命令行中比如你yy复制好了一行,那么命令行中直接使用p就能够粘贴了
删除和剪切
删除光标所在字符
x
单行操作
dd 表示剪切,如果不粘贴那就是删除了
D 删除光标所位置的当前行的往后内容,注意不是删除当前行所有,而是光标所在位置的往后的内容,并且在当前行
多行操作
先按下你要删除或者剪切的行数,都是在你光标当前位置进行操作的。3dd 表示剪切光标所在位置的三行内容3D 表示删除光标所在位置的往后的内容的三行内容,注意光标前面的内容不进行删除,是从光标往后的内容开始删除
当前光标删除到末尾
光标位置定好后,直接命令模式中输入:dG
这样即可从光标位置直接删除后面所有文本内容。
撤销
u
恢复
ctrl + r
回到整个文档开头段
gg
回到整个文档末尾段
G
回到行首
0
回到行尾
$
定位到第几行
第一种方法:
进入命令模式后,冒号+行数即可跳转: 20 == 跳到20行
第二种方法:(比较装逼的方法)
先按你要跳转的行号 , 然后按下G,这里要大写,所以我一般都是shift + g或者先按你要跳转的行号 , 然后按下gg也能实现同样的跳转装逼是因为你没有显示任何东西就直接给你跳转到你要的行号了。
命令行模式光标移动
hjkl
h = ←
j = ↓
k = ↑
l = →
.swp文件
该文件的出现是因为你编辑文件的过程中异常退出或者多人同时编辑了该文件的时候就会发生。
那么我们一般vim这个.swp文件的时候,我们就会进入一个选项模式,直接根据需求恢复还是删掉即可。一般来说如果要恢复的话会有。
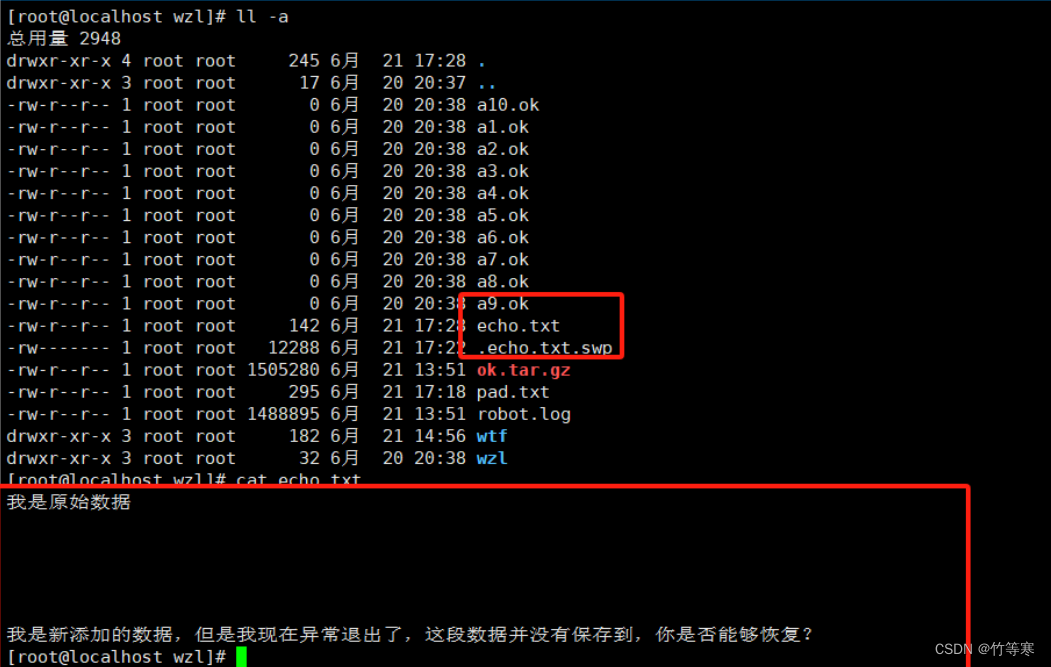
下面演示一个我复制回话后,编辑一个文件不保存退出的情况,我回到原会话中就会发现出现该文件
现在存在echo.txt文件如下
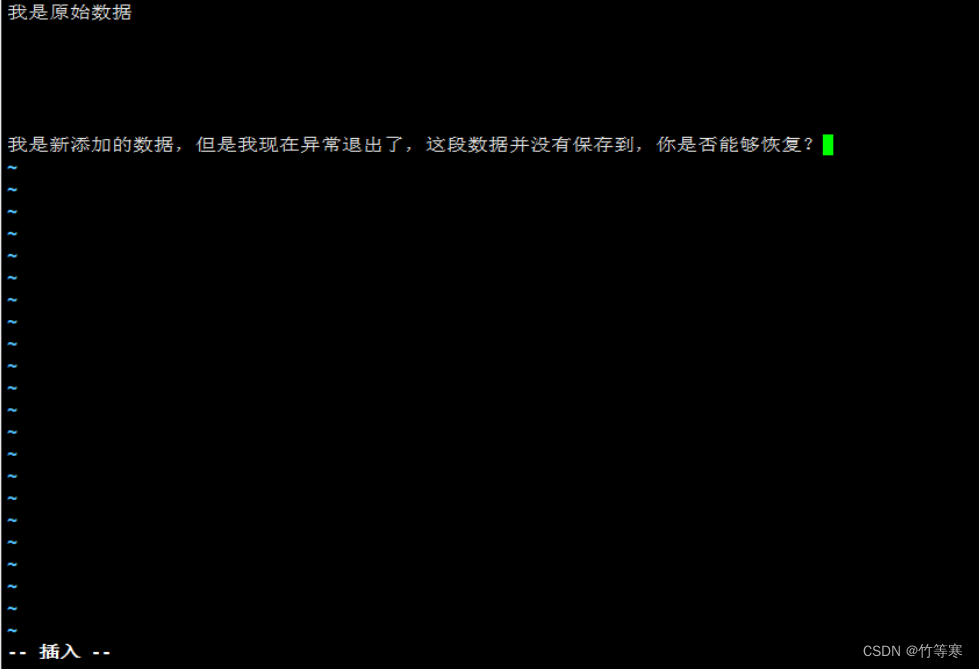
如果你不要这个刚刚编辑添加好的内容的话直接删掉.swp文件即可
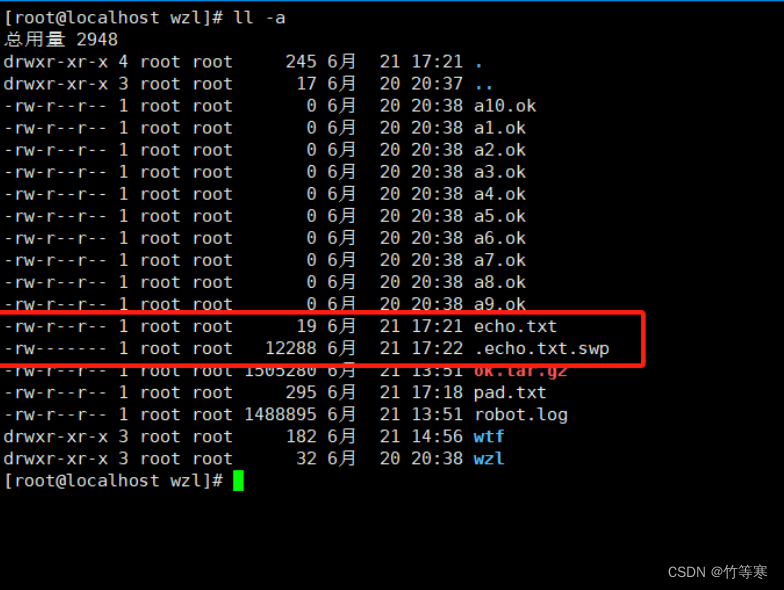
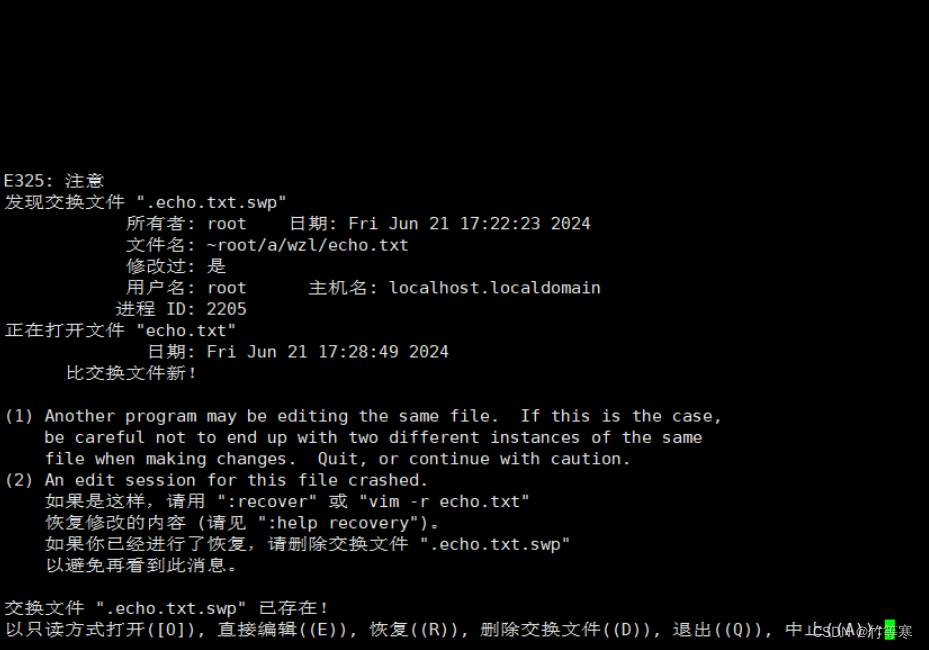
但是我们真的是不小心断开连接了,需要对文件内容进行恢复,我们vim echo.txt就会出现提示。
我们就直接vim echo.txt吧,不要vim那个.swp,那文件是给内存看的,不是给我们看的。

只读模式o(不管大小写的哈)直接编辑e恢复r删除交换.swp文件d退出q中止a
我们现在需要恢复之前编辑的内容就直接r
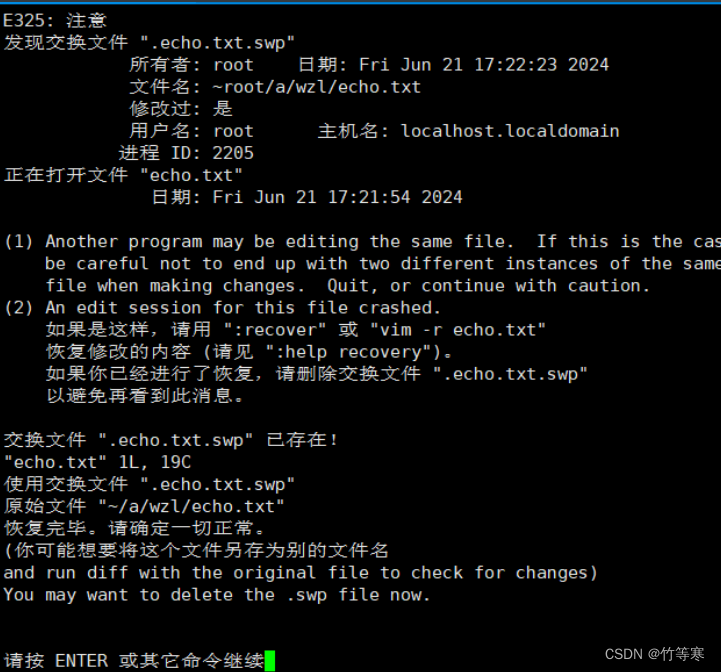
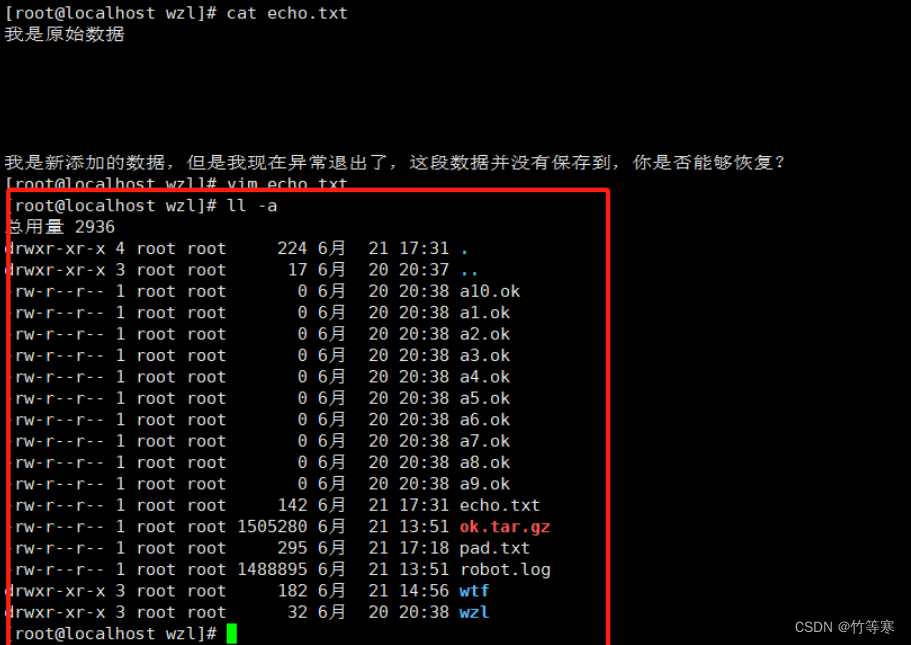
然后回车就能够看到恢复成功了
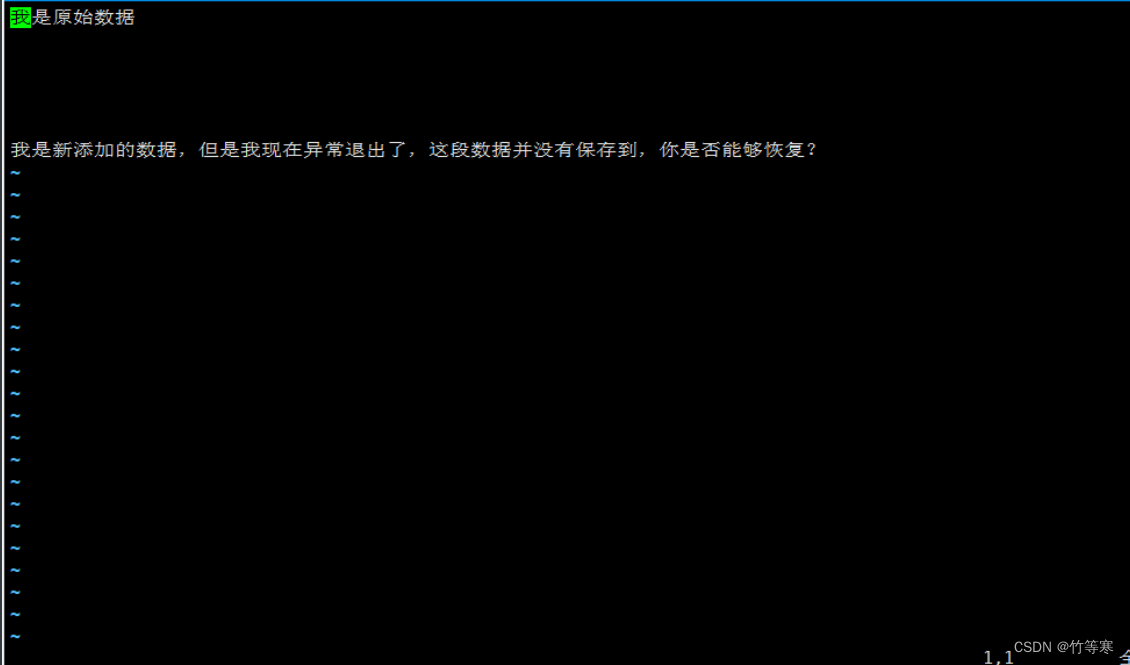
现在来看的话我们已经恢复成功了,只是我们的交换文件还存在,还是要手动给他删掉
如果不删掉的话再次vim echo.txt的时候还是回出现提示,因为那个文件不会自动删除
这里有两种方法,
-
一种是你手动rm删除.swp文件
-
第二种是你再次vim echo.txt的时候,提供了命令d让你去删除
d删除后,发现已经删掉了该文件,注意,前提是你已经恢复好了二次进入后再d命令删掉,否则你想要恢复但是还没恢复好久d掉了那就神也救不了你。

环境变量(个性化自定义设置)
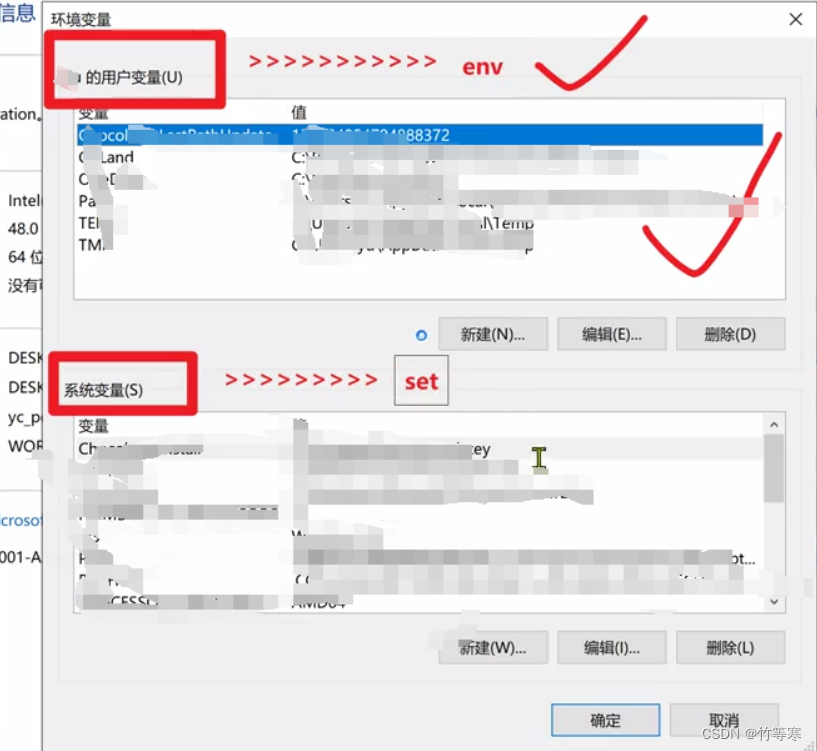
env 和 set
env #相当于windows中的用户变量set #相当于windows中的系统变量
PS1
PS1变量可用参数
\d 日期,格式为weekdat month date
\H 完整的主机名称
\h 仅取主机的第一个名字
\t 显示时间为24小时格式,如:HH:MM:SS
\T 显示时间为12小时格式
\A 显示时间为24小时格式:HH:MM
\u 当前用户的账号名称
\v bash版本信息
\w 完整的工作目录名称。家目录会以~代替
\W 利用basename取得工作目录名称,所以只会列出最后一个目录
# 下达的第几个命令
$ 提示字符,如果是root,提示符为:#,普通用户则为:$
! 命令行动态统计历史命令次数
临时生效
[root@localhost a]# set | grep PS1
PS1='[\u@\h \W]\$ 'PS1是控制命令变量提示符
\u显示用户名
\h显示主机名
\W显示根目录
\w显示pwd当前目录
\t显示当前时间由于它是一个变量,所以我们可以直接在命令行中直接对其进行修改
PS1='[\u@\h \w \t]\$ '这种方法只是临时生效,当你重启后系统就会重新加载环境变量,然后你设置的东西就会失效。
永久生效
直接修改配置文件
/etc/profile #这个是针对全局的,系统的,那么想要修改他肯定只有root用户才可以修改。用户的home/.bash_profile #这个是针对某个用户生效的。我们对这两个文件进行修改即可永久生效了那么比如说我们要修改用户下的.bash_profile
[wzl01@localhost ~]$ ls -a
. .. .bash_history .bash_logout .bash_profile .bashrc .viminfo
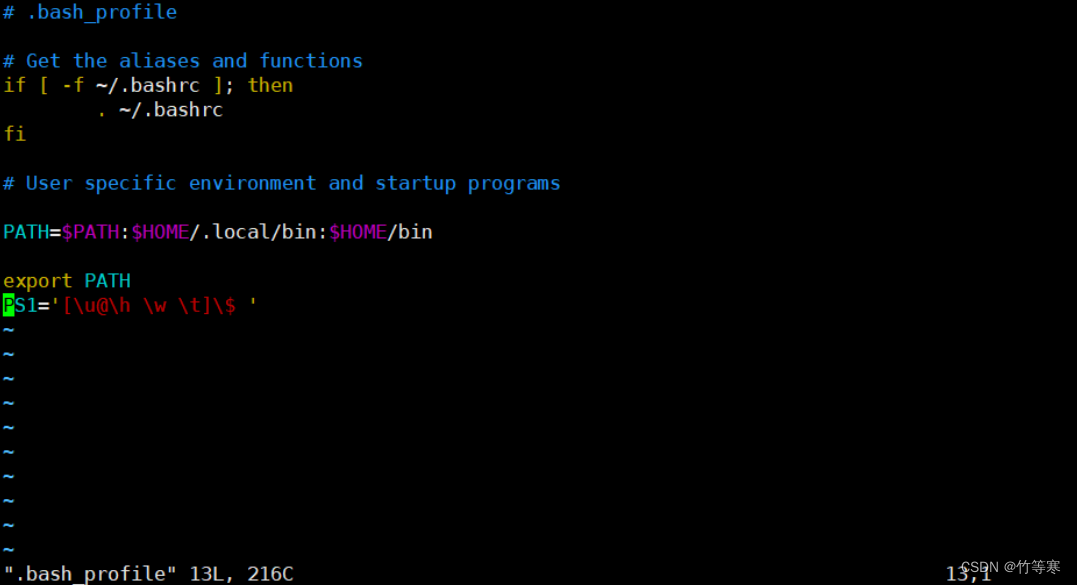
[wzl01@localhost ~]$ cat .bash_profile
# .bash_profile# Get the aliases and functions
if [ -f ~/.bashrc ]; then. ~/.bashrc
fi# User specific environment and startup programsPATH=$PATH:$HOME/.local/bin:$HOME/binexport PATH
那么我们现在修改一下这个配置文件,在最后面加上PS1='[\u@\h \w \t]\$ '即可
然后使用指令
source .bash_profile #让配置文件生效即可

用户bash损坏修复
当出现用户的bash变成了:
-bash-4.2$
这种情况下,用户输入pwd,大概率会回显tmp目录,因为你家没有了,那你.bash_profile也没了这种情况十有八九是该用户的家目录没有了,被掏家了
假设该用户叫做admin,
那么我们只需要将模版文件复制过来即可。
cp -r /etc/skel/ /home/admin/
# -r参数 递归复制目录及其子目录内的所有内容
也就是说我们要同时创建/home/admin才能将其admin恢复回来,那么我们cp -r其实就是顺便帮忙把目录也创建出来了。
用户管理篇章
useradd
useradd 用户名 #添加用户-u #设置用户的id
比如我设置1234为新用户的id
useradd -u 1234 用户名 -s #指定用户登录进来后所使用的shell解释器,
解释:这里的解释器就是你在cat /etc/passwd出来后,每一行最后那个,比如能够登录进来的就是 /bin/bash,不能登陆进来的解释器就是/sbin/nologin
比如我设置一个不能登陆的用户wtf(已实验过确实不能登陆进去)
ueradd -s /sbin/nologin wtf -g #注意该参数是设置用户的主组
useradd -g 组名/组id 用户名 #在创建用户的使用就把该用户添加到某个组里面作为该用户的主组-G #注意该参数是设置有用户的附加组,因为用户在不设置组的时候默认用自己的用户名创建一个组然后作为自己的主组
useradd -G 组名/组id 用户名

细节:useradd创建的用户的id号默认是从1000开始的,然后id号递增
passwd
passwd 用户名 #回车后就能修改该用户名的密码了
超级用户的UID是0
-
查看该用户是否可登录状态
cat /etc/passwd后, 如果对应用户后面是sbin/nologin表示无法登录。 如果是bin/bash的话就是可以使用ssh进行登录的。
用户可以属于多个组,默认主组是你创建该用户的时候相应的用该用户名创建一个组,然后这就是你的主组。
用户可以加入多个组。
usermod
usermod -L user //L表示lock , 锁定,禁用帐号,帐号无法登录 /etc/shadow第二栏为!开头 user表示你查到的用户名
usermod -g 组名/组id 用户名 //-g小写g表示改的时候用户的主组
usermod -G 组名/组id 用户名 //-G大写的G表示改的是用户的附属组,注意这里是直接修改你的附属组,也就是说你原本的附属组会被覆盖
usermod -a -G 组名/组id 用户名 //这里多了个-a表示追加附属组,因为你直接用-G就会覆盖以前的附属组,所以-a可以追加
userdel
userdel user //删除user用户
userdel -r user // 将删除user用户,并且将/home目录下的user目录一并删除,有些人入侵完成删除自己用户的时候,可能忘记了加-r,那么在/home目录下是有它用户名的文件夹的,也就是存有相关信息。
id
id 用户名 / 直接id命令
发现:whoami 指令可以等于 id -un ,以后获取用户名又多了一条指令
查询用户的id和用户组-u #查询uid
-g #查询组id
-un #显示用户名 == whoami
-gn #显示组名[root@localhost ~]# id
uid=0(root) gid=0(root) 组=0(root)
[root@localhost ~]# id -u wzl01
1000
[root@localhost ~]# id -un wzl01
wzl01
[root@localhost ~]# id -un
root
[root@localhost ~]# id -gn
root
[root@localhost ~]# id -gn wzl01
wzl666
[root@localhost ~]# id -g
0
解释/etc/passwd文件内容:
密码都是x加密,不会直接显示出来。
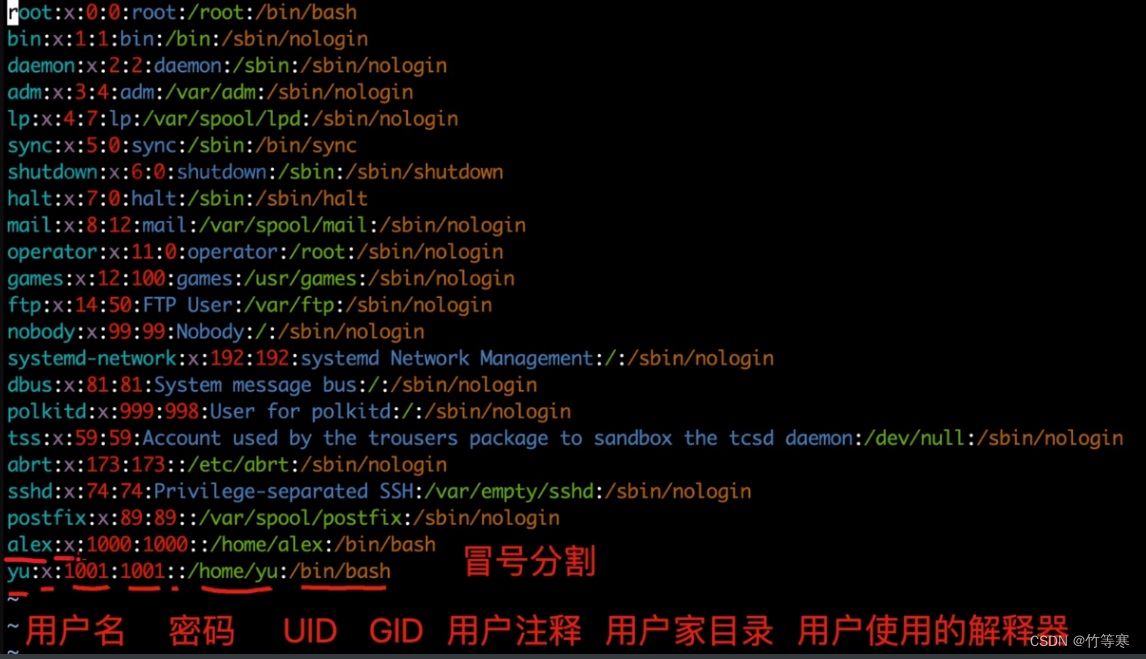
用户相关的配置文件
useradd命令执行后,以下文件都会发生变化:
/etc/passwd 用户信息
/etc/shadow 用户密码信息
/etc/group 用户组信息
/etc/gshadow 用户组密码信息(一般公司中用户和组数量很大的时候就会用到这个组密码)
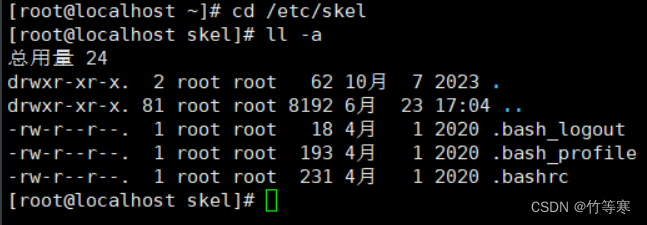
/etc/skel
skel是skeleton的缩写,表示骨骼框架的意思,那么就是说当你useradd执行创建一个用户的时候,一般都会有一个home目录,那么home目录系统帮你创建完成后,里面的一些比如.bash_history之类的文件模板就是从这个文件拷贝过去的。
下面是/etc/skel目录下的模板文件:
组管理
groupadd
groupadd 组名 #添加组 这个组默认是从组的id1000开始递增-g
groupadd -g 1111 组名 #设置组id,注意这里是在添加的过程中直接指定组id,当然我们添加完成后也是可以通过groupmod -g来进行id修改的
groupmod
-g
groupmod -g 6666 src #这样就是将组名为src的id改成6666-n修改组名
groupmod -n des src #这样就是把src组名改成des名
groupdel
groupdel 组名 #删除组
whoami/who/w/last/lastlog
whoami #打印当前用户名
[root@localhost ~]# whoami
rootwho #显示已登录的用户信息
[root@localhost ~]# who
root pts/0 2024-06-23 10:28 (192.168.29.1)w #显示系统登录用户信息,以及负载信息
[root@localhost ~]# w16:39:01 up 6:10, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.29.1 10:28 5.00s 0.66s 0.00s wlast #显示近期登录的终端有哪些
last -5 #表示显示最近登录的5条信息
[root@localhost ~]# last
wtf pts/1 192.168.29.1 Sun Jun 23 15:40 - 15:40 (00:00)
wtf pts/1 192.168.29.1 Sun Jun 23 15:39 - 15:39 (00:00)
wzl01 pts/1 192.168.29.1 Sun Jun 23 15:21 - 15:39 (00:17)
....
....
....
reboot system boot 3.10.0-1127.el7. Sun Oct 8 00:03 - 11:54 (29+11:51)
wtmp begins Sun Oct 8 00:03:00 2023lastlog #显示关于所有用户的登录记录
[root@localhost ~]# lastlog
用户名 端口 来自 最后登陆时间
root pts/0 日 6月 23 15:20:40 +0800 2024
bin **从未登录过**
wzl01 pts/1 192.168.29.1 日 6月 23 15:21:28 +0800 2024
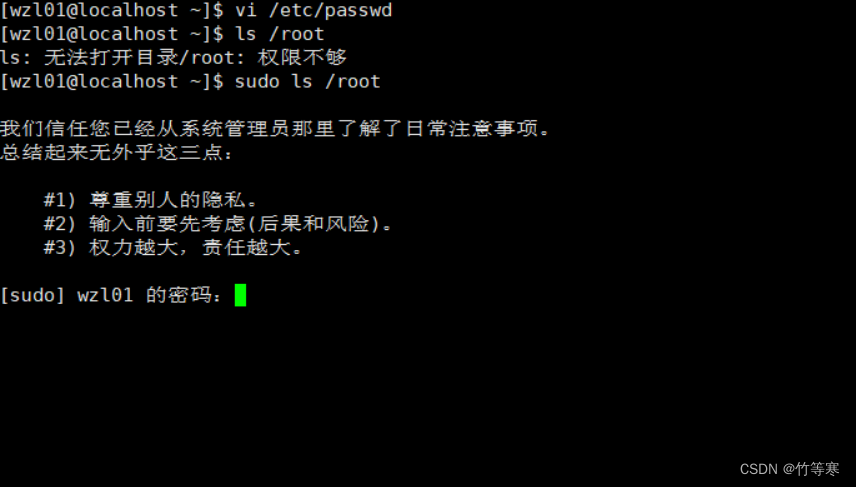
wtf pts/1 192.168.29.1 日 6月 23 15:40:00 +0800 2024sudo
举一个例子即可:普通用户想要执行管理员权限的指令需要用sudo,
但是我们不想要输入root的密码,因为他不是随便给人的,
那么我们就可以请求他去执行一下:visudo,这个命令
然后去到大概100行左右,加上我的用户名,然后给权限,这样我sudo,输入自己账号密码就行了,不用输入root的密码!就可以直接用了

这里我输入自己的密码就可以查看root下的目录了
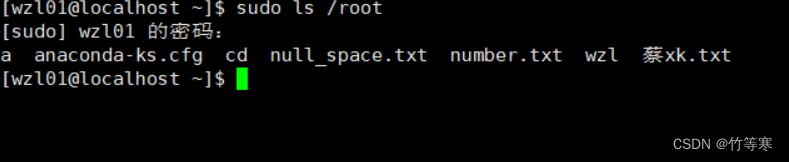
文件权限篇章
如何查看文件属性
ll
stat 文件名
权限了解
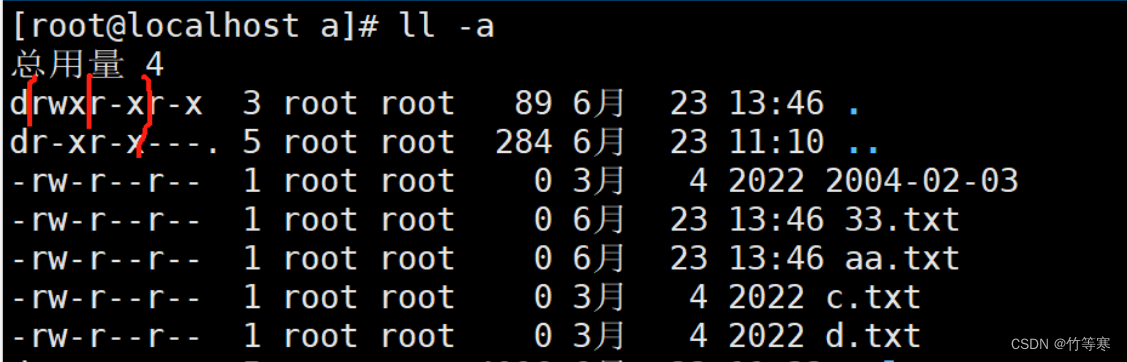
文件属性 d - l 属主user 属组group 属其他other
三个常见的文件类型:
d 文件夹
- 普通文本
l 软链接
记住属谁的英文后面修改权限的时候就很容易了。
all=a user=u group=g other=o
还有一个all,别忘了。
d rwx r-x r-x 3 root root
第一个d表示这个是一个目录,如果是-那就表示是一个文本文件rwx
这里表示是属主的权限,比如这里后面显示root root那就是代表属主和属组都是root。
那么rwx就是root这个属组拥有读写和执行权限r-x
这里表示属组权限,那么我们刚刚说到属组还是root,
那么我们的root组中,对该文件有读和执行权限,没有写权限r-x
最后一个是other,其他人的权限,只有读和执行,同样没有写权限
疑问和细节:为什么属主我自己登上去还要搞能不能执行能不能读取这些??我本人不应该默认读写执行都可以吗?
答:不是的,有时候需要自己去划分权限,比如该文件就是为了防止被乱改,那我就需要禁用写权限。
chmod
了解了上面的权限分类后,使用chmod就得心应手了
chmod是修改这个文件所属于那个属主和属组是否有权限
例子:drwxr-xr-x 3 root root 89 6月 23 13:46 .
chmod a+r file #表示对file文件进行权限修改为all所有用户和组都可以进行+r,即加了一个读权限chmod u-r file #表示对文件修改,让属主没有r读权限,-表示去掉,所以-r就是去掉读权限
注意u这里是rootchmod g+w file #表示修改该文件权限,让属组有对文件进行写权限操作,+w就是加一个w写权限
住恶意g这里是root组,主要看文件属于的属主和属组是谁,u和g都是针对这两个进行修改的哈。chmod o-w file #这里表示对其他用户和组进行-掉w写的权限,让其他的用户和不属于该用户组的都没有写权限。还可以进行多个权限加减,只需要用逗号分隔即可
chmod u+r,u+w,o-x file 还可以直接等于
chmod u=rwx file如果要给某个权限位设置为空,即设置为---,可以给空字符
chmod o='' file
疑问:root root 属主和属组我们怎么修改呢?
答:我们还有另外一个指令chown,很明显的名字了change改变own文件拥有者,即文件是属于谁的和哪个组的,这个是chown命令修改的,而chmod只是针对于文件拥有者进行权限修改还有对非文件拥有者进行权限修改,而不是修改文件在水户口本下的。
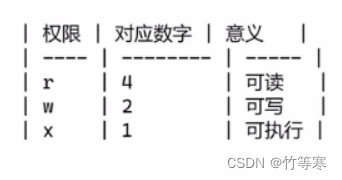
文件权限的数字表示法
比如
chmod 777 file #就是将u g o 三个的读写执行权限都给了,因为 4 + 2 + 1 = 7
chown
chown 用户名 file
注意:要修改目录内容,必须要对目录有x可执行权限,这样才能cd进去,并且touch或者其他修改目录内容的命令。
chgrp
该操作只能root操作,因为涉及到安全问题,不可能你所属于a组,你就想把你这个文件改到b组吧?
chgrp 组名 file
ln
创建软连接
不带-s参数的是硬链接
-s参数是创建软链接
ln -s 源文件 链接存放路径/链接存放的路径+名字 Linux会自动区分,因为没找到目录名字的时候会当作链接名字命名该链接
比如ln -s /etc/okok.sh /usr/bin/ok.sh
suid
chmod u+s file
suid:因为有一些执行的指令需要普通用户临时申请一下root权限去执行一下指令,比如ping或者find等等,这些本身都是只有root才能去执行的指令,那我们就可以打上suid标志,然后普通用户也能够执行该指令和文件了。
-rwx------ file
当我执行chmod 4000 file 或者 chmod u+s file的时候就会变成下面权限
-rws------ file-rw------- file
当我执行chmod 4000 file 或者 chmod u+s file的时候就会变成下面权限
-rwS------ file总结;
suid权限八进制表示是4000,那么同理可以和其他权限组合起来用,比如4777
当文件本身对属主有x执行权限的时候,添加suid权限的时候x会变成s
当文件本身对属性没有x执行权限的时候,添加suid权限的时候就会变成S
sgid
chmod g+s dir
---rws--- nb nb dir这是一个目录
这里g属组中有s,表示sgid,然后属主和属组是nb
意思是我们该目录在root进入后,在此目录进行创建文件的时候,就会以nb属组创建出来的文件而不是root也就是说目录下谁进来创建文件,那么这些文件和文件夹都会继承为nb属组,而不是他们所属的组
好处:能够限制在该目录中所有文件都属于nb组
sbit
chmod o+t dir
粘滞位
------rwt nb nb dir这是一个目录
t表示sbit,
如果一个目录chmod 777 dir后,那么无论谁进来该目录创建文件后,不同的用户都能够对其对方的文件进行删除或者甚至可能可以修改(不确定是否有的Linux可以修改),这就很危险了,因为可以删除对方文件。
那么在该目录下,就应该需要加一个粘滞位chmod o+t dir ,比如tmp目录就有t粘滞位。那么假设真的有这么一个目录share 拥有777权限,甚至还在根目录下,没有在某个目录中包含,所以他无论谁进来创建的文件,那么其他人都可以对他创建的文件进行删除,就需要加一个粘滞位了。
当然我们想要在根目录下创建这么一个目录是不太可能的,除非你是root用户才可以。所以这也就是为什么粘滞位已经快无人问津了,基本用户都是在自己家目录下进行文件的创建和修改,家目录肯定是属于自己的而不是777权限谁都可以进来,所以安全性就有了。
系统服务篇章
理解systemctl如何管理服务的,如果看不懂先看后面的服务解释。
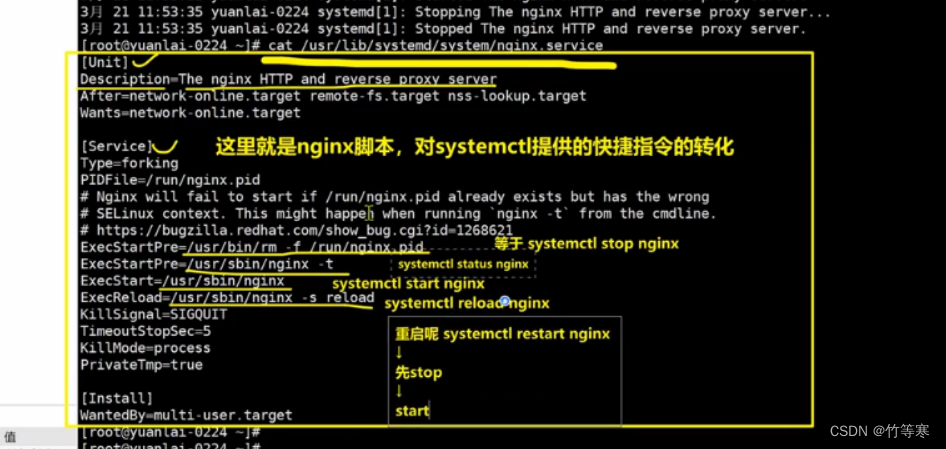
如果我们平时使用的软件其实都是需要去到对应的脚本目录下进行运行起来,
当我们不用该软件的时候,需要停下来的时候,其实是使用kill 他的pid号来进行停止,
但是我们的systemctl管理服务的这个指令就完成了我们的任务,
比如nginx下就有一个nginx.service文件,里面写着就是我们怎么去关闭软件,
本质上都是找到pid然后进行kill,开启的时候同理,都是找到对应的文件脚本启动。也就是说我们systemctl start nginx就能够完成我们上面那一步去到脚本目录下执行快多了,
同理停下程序只需要:systemctl stop nginx即可停掉。
ssh服务
systemctl start sshd #启动ssh服务
systemctl stop sshd #关闭ssh服务
systemctl restart sshd #重启ssh服务
systemctl status sshd #查看ssh服务状态
network服务
systemctl start network #启动网络功能
systemctl stop network #关闭网络功能
systemctl restart network #重启网络功能systemctl status network #查看网络服务状态
配置网络服务
Centos系统
进入配置网卡目录
cd /etc/sysconfig/network-scripts/
找到对应的网卡文件
[root@localhost network-scripts]# ls | grep ens
ifcfg-ens33#注意ifcfg-ens33是你ifconfig查看网卡信息的时候,你那个使用的网卡名字叫做ens33那就是编辑这个。文件名和ifconfig显示网卡信息是对应的,所以你可以通过这个方式来查看。
编辑该文件
vim ifcfg-ens33#设置的是dhcp模式 ,重要的信息我加上注释解释一下
TYPE="Ethernet" #网卡类型,以太网
BOOTPROTO="dhcp" # boot启动协议proto是dhcp,这里可以改成static静态
DEFROUTE="yes"
NAME="ens33" #这个就是你ifconfig显示出来的网卡名字
DEVICE="ens33"
ONBOOT="yes"#设置的是static模式
TYPE="Ethernet"
BOOTPROTO="static"
IPADDR="xxx.xxx.xxx.xxx"
GATEWAY="xxx.xxx.xxx.xxx"
NETMASK="255.255.255.0" #通常掩码都是这个,根据你实际情况修改
DNS1='' #根据你要的对你说服务器,自己设置即可
DNS2=''
DEFROUTE="yes"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
重启网络服务
systemctl restart network
服务管理
注意区分:
在CentOS 7及以后版本中,虽然 systemctl 是主要的服务管理工具,但为了兼容性,仍然保留了 service 命令,并且 service 命令在这些版本中通常会调用 systemctl 来执行相应的操作。因此,即使在systemd系统中,也可以使用 service 命令进行基本的服务管理。
systemctl
在centos6和7的系统版本中,为了方便理解,可以暂时理解为:systemctl = service + chkconfig
对这些服务,进行管理
- 启动
- 停止
- 重启
- 重新加载
- 开机自启(持久化)
- 禁止开机自启
- 查询是否持久化(是否开机自启)
centos7,用这个命令,同时对服务进行启停管理,以及开机自启
systemctl start/stop/restart/reload/enable/disable/is-enabled 服务名使用语法:systemctl [OPTIONS...] COMMAND [UNIT...] 参数:unit 是要配置的服务名称。command 选项字如下: unit(单元,服务,指的是如sshd,network,nginx,这样的服务名(unit))这几个指令,就替代了旧版的service 服务名 start/stop/等等
start:启动指定的 unit。
stop:关闭指定的 unit。
restart:重启指定 unit。
reload:重载指定 unit。
status:查看指定 unit 当前运行状态。
is-enabled :查看是否设置了开机自启。替代了旧版的chkconfig 服务名 on/off
enable:系统开机时自动启动指定 unit,前提是配置文件中有相关配置。 设置开机自启
disable:开机时不自动运行指定 unit。 禁用开机自启参数:unit 是要配置的服务名称。
systemctl
-
查看所有服务
systemctl list-unit-files #这是查看所有服务 systemctl list-unit-files | grep enabled #意思是过滤开机自启的服务 -
列出系统中,所有的内置服务,名字,和状态
systemctl list-units --type service --all 运行中 挂掉的 都帮你全列出来,一般服务名字都是以 .service结尾 -
只列出,active运行中的服务
systemctl list-units --type service可以利用该命令,搜索出,系统内置服务名的完整名称,才可以去管理
其实也可以:systemctl list-unit-files | grep ssh,这样也可以过滤出来。一样的,只是下面的会告诉你哪些是runing哪些是dead了。
下面加上 --all 是包括未激活的单元。
systemctl list-units --type service --all |grep ssh ↓↓↓sshd-keygen.service loaded inactive dead OpenSSH Server Key Generationsshd.service loaded active running OpenSSH server daemonsystemctl is-enabled sshd.service #然后你才可以根据以上命令查找出来的完整服务将其开机自启关掉。 ↓↓↓ enabled

systemctl list-unit-file 和 systemctl list-units 的区别
-
systemctl list-unit-files
用途: 列出所有单元文件及其启用状态。
输出: 显示系统上所有的单元文件,包括服务(service)、挂载点(mount)、设备(device)等的文件名及其启用状态(如 enabled, disabled, static 等)。
-
systemctl list-units
用途: 列出当前加载的单元及其状态。
输出: 显示当前加载的单元,包括正在运行的、失败的和其他状态的单元。默认情况下,只显示活动(active)的单元。
总结
systemctl list-units | grep 服务名 #这个就能够完成你查找服务名的操作了,grep能够进行模糊查找
service
service命令用于对系统服务进行管理,比如启动(start)、停止(stop)、重启(restart)、重新加载配置(reload)、查看状态(status)等。
# service mysqld 指令 #打印指定服务mysqld的命令行使用帮助。# service mysqld start #启动mysqld# service mysqld stop #停止mysqld# service mysqld restart #重启mysqld (先停止,再运行 ,进程会断开,id会变化)# service mysqld reload # 当你修改了mysqld程序的配置文件,需要重新加载该配置文件,而不重启
chkconfig
备注
在centos7中,service启停服务的命令和 chkconfig命令,都被统一整合为了systemctl
并且你依然可以使用旧的命令,系统会自动的转变为systemctl去执行。
做了向下兼容的操作,新命令,兼容旧命令。
说人话:哪个能用用哪个,他会有以下提示给你的
注:该输出结果只显示 SysV 服务,并不包含
原生 systemd 服务。SysV 配置数据
可能被原生 systemd 配置覆盖。要列出 systemd 服务,请执行 'systemctl list-unit-files'。
查看在具体 target 启用的服务请执行
'systemctl list-dependencies [target]'。
chkconfig: 指定服务是否开机启动
sshd 远程连接服务
network 提供网络的服务设置开机自启提供了一个维护/etc/rc[0~6] d 文件夹的命令行工具,它减轻了系统直接管理这些文件夹中的符号连接的负担。chkconfig主要包括5个原始功能:为系统管理增加新的服务、为系统管理移除服务、列出单签服务的启动信息、改变服务的启动信息和检查特殊服务的启动状态。当单独运行chkconfig命令而不加任何参数时,他将显示服务的使用信息。[root@localhost www]# chkconfig --list #查看系统程序列表[root@localhost www]# chkconfig httpd on #将httpd加入开机启动[root@localhost www]# chkconfig httpd off #关闭httpd开机启动
scp文件传输服务
scp语法
无论你使用scp服务进行传过去还是拉取文件,都需要输入对方的密码
#把文件发给root@192.168.1.1,回车后需要输入他的密码
scp /etc/passwd root@192.168.1.1:/opt #传输文件夹到对方目录中 -r 参数
scp -r /var/log root@192.168.1.1:/opt#把文件拉取到自己本地目录中
scp root@192.168.1.1:/etc/passwd /opt#把文件夹拉取到本地目录中 -r 参数
scp -r root@192.168.1.1:/var/log /opt/
ntp时间服务
同步时间
如果没有ntpdate那就安装一下,yum install ntpdate -y
1.找到时间服务器地址,强制更新即可
[root@yuanlai-0224 ~]# ntpdate -u ntp.aliyun.com[root@yuanlai-0224 ~]# ntpdate -u ntp.aliyun.com
21 Mar 12:31:11 ntpdate[19892]: step time server 203.107.6.88 offset 106194278.720730 sec[root@yuanlai-0224 ~]# timedatectl statusLocal time: 一 2022-03-21 12:31:32 CSTUniversal time: 一 2022-03-21 04:31:32 UTCRTC time: 四 2018-11-08 02:06:54Time zone: Asia/Shanghai (CST, +0800)NTP enabled: no
NTP synchronized: noRTC in local TZ: noDST active: n/a
更改时区
修改时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
查看系统中有哪些时区文件
ls /usr/share/zoneinfo/
ll /usr/share/zoneinfo/Asia/Shanghai
定时任务
基本设置
crontab提供最小分钟级别的任务,想完成秒级别的任务,得通过编程语言自己写。
每个用户对应的定时任务文件存储在:
/var/spool/cron/root的定时任务文件名在该目录下就叫root
/var/spool/cron/root
-
列出当前用户有哪些计划任务
crontab -l -
编辑当前用户的计划任务
crontab -e -
删除当前用户的计划任务
crontab -r
定时任务难点就是理解他设置时间的格式,但是无他,唯手熟尔!
分 时 日 月 周
每分或者每时或者。。。那就用 */ ,
每30分 */30 * * * *
每15天 * * */15 * *时间段,那就用-,
每小时15-20分 * 15-20 * * *
每个月的1-5日 * * 1-5 * *指定某几天某几分钟,那就用,逗号
每个月的1,6,20天 * * 1,6,20 * *
每天的1,5,19小时 * 1,5,19 * * *
无他,唯手熟尔,再看完下面你就理解定时任务怎么写了!
学习定时任务,最简单的,就是直接通过案例,掌握其语法
* * * * *
分 时 日 月 周 命令的绝对路径从左 向右,依次去写,不要跳级问题1:每月1、10、22 日的4:45 重启network 服务
45 4 1,10,22 * * /usr/bin/systemctl restart network问题2:每周六、周日的下午1:10 重启network 服务
10 13 * * 6,7 /usr/bin/systemctl restart network问题3:每天18:00 至23:00 之间每隔30 分钟重启network 服务
*/30 18-23 * * * /usr/bin/systemctl restart network问题4:每隔两天的上午8点到11点的第3和第15分钟执行一次重启
* * * * *
分 时 日 月 周 命令的绝对路径
3,15 8-11 */2 * * 问题5 :每天凌晨整点重启nginx服务。
* * * * *
分 时 日 月 周 命令的绝对路径
0 0 * * * /usr/bin/systemctl restart nginx问题6:每周4的凌晨2点15分执行命令
15 2 * * 4 问题7:工作日的工作时间内的每小时整点执行脚本。
工作日 1-5
工时 9-18
* * * * *
分 时 日 月 周 命令的绝对路径
0 9-18 * * 1-5如果定时任务的时间,没法整除,定时任务就没有意义了,得通过其他手段,自主控制定时任务频率。
crontab提供最小分钟级别的任务,想完成秒级别的任务,得通过编程语言自己写。问题10:每1分钟向文件里写入一句话"超哥666",且实时监测文件内容变化。
* * * * * /usr/bin/echo "好快乐啊" >> /tmp/t1.txt问题11:每天凌晨2点30,执行ntpdate命令同步ntp.aliyun.com,且不输出任何信息,把命令结果,重定向到黑洞文件
/dev/null
备注:定时任务的命令执行,会产生日志
30 2 * * * /usr/sbin/ntpdate -u ntp.aliyun.com &> /dev/null
黑白名单限制
白名单高于黑名单,也就是说,白名单上的用户,即使在黑名单中被禁了也可以使用crontab -e进行定时任务编辑
/etc/cron.deny 黑名单文件 (将系统中,所有uid大于1000的用户,全部写入黑名单)
/etc/cron.allow 白名单 ,优先级高于黑名单#可能默认没有该文件,没有就创建出来即可
定时任务,默认存放的路径
[root@yuchao-linux01 ~]# ls /var/spool/cron/
jerry01 root
定时任务,服务端的运行日志,可以用于给运维,进行故障排查
/var/log/cron
最后,定时任务,crontab会在系统中,生成大量的邮件日志,会占用磁盘,因此我们都会关闭邮件服务即可
[root@yuchao-linux01 ~]# find / -type f -name 'post*.service'
/usr/lib/systemd/system/postfix.servicesystemctl服务管理命令
[root@yuchao-linux01 ~]# systemctl list-units |grep post
postfix.service loaded active running Postfix Mail Transport Agentsystemctl status postfixsystemctl stop postfix禁止开机自启
systemctl disable postfix
进程管理篇章
linux系统启动产生1号进程
孤儿进程
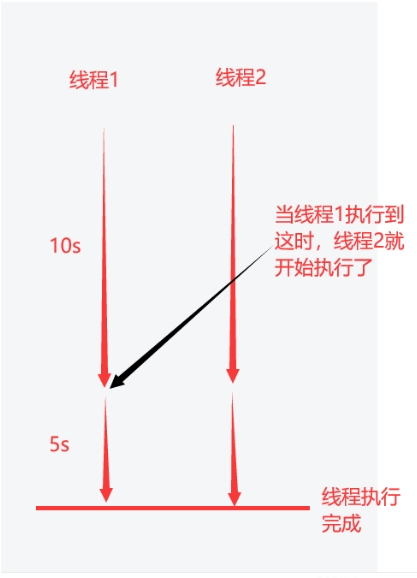
子进程的父进程挂掉后,子进程没有父进程了,那么就会将该子进程给到1号进程,然后这个就叫做孤儿进程,1号进程过一段时间会对该孤儿进程进行资源回收。换句话说就是孤儿进程的ppid就是1号进程。孤儿进程释放后,释放执行的相关文件,数据,以及释放进程id号(系统id号是有固定的数量)。
僵尸进程
僵尸进程就是子进程挂掉了,但是父进程没有被通知到,他还以为子进程还在运行着,那么父进程就会一直拿着子进程的一些资源和其他数据,就不会释放,那么这就是一个僵尸进程了。
ps
ps -ef == ps aux
linux风格的组合参数,一般都是携带短横线
ps -ef unix操作系统下,查看进程,用如下不带短横线的参数选项
ps aux
ps两种风格,分别是unix和liunx风格,但是作用都是一样的
# UNIX风格,没有短横线
a # 显示所有终端、所有用户执行的进程
u # 以用户显示出进程详细信息
x # 显示操作系统所有进程信息
f # 显示进程树形结构
o # 格式化显示进程信息,指定如pid
k # 对进程属性排序,如k %mem ,正序排序 ,k -%mem 逆序
--sort,再进行排序,如 --sort %mem 根据内存使用率显示linux标准参数用法
-e # 显示所有进程
-f # 显示进程详细,pid,udi,进程名
-p # 指定pid,显示其信息,如 ps -fp 2609
-C # 指定进程的名字查看,如sshd.service
-U # 指定用户名,查看用户进程信息 ps -fU yuchao01ps -fp 22 #用p参数的话建议配合f参数,因为你看的不就是详细信息吗,只用p的话只有端口号,而且参数顺序是fp。
top
P:以CPU的使用资源降序排序显示,默认
M:以内存的使用资源降序排序显示
N:以pid降序排序显示
T:由进程使用的时间累计排序显示
k:给某一个pid一个信号。可以用来杀死进程
r:给某个pid重新定制一个nice值(即优先级)
q:退出top(用ctrl+c也可以退出top)。
1:数字1,可以查看CPU核心的个数及详细信息
lsof
有的系统没有安装该命令,需要安装lsof工具。比如:yum install lsof -y
这个是list open file 的意思
所以是列出进程运行起来后已经打开了的文件,很有用的一个命令,对于网络安全应急响应过程中。
-
-p #指定PID,查看该进程使用打开了哪些文件
比如我想找到nginx打开了哪些日志文件,那么我就可以通过这种方式查看: ps -ef | grep nginx #先筛选出nginx的进程号 lsof -p 进程号 | grep log -
-u #查看某个用户打开了哪些文件
lsof -u 用户名
找回文件之练习题
nginx已经启动了,日志一直记录着黑客删除了日志文件
rm -f /var/log/nginx/access.log #删除日志文件黑客不够细节,忘记了日志文件能够恢复,nginx还运行着,你应该如何恢复日志文件呢?
答:
ps -ef | nginx #找到nginx的pid号,假设为1234ls /proc/1234/fd/* #根据正在运行的进程号找到proc进程文件,里面的fd文件夹里面所有的文件就是正在运行的文件数据,也就是说我们的access.log日志文件也无非就是从这些文件内容中拷贝过去的。 比如某个 /fd/5的内容就是日志文件,这里数据数据就是输入进access.log文件中的。kill
kill
-15 #正常的发送kill信号,如果关不掉就关不掉进程了,可能就要用-9
-9 #强制杀死
-1 #重新加载reload进程,比如你修改了配置文件,只需要kill -1 pid即可,省掉了重新启动服务动作。
pkill
根据进程名字批量杀进程
pkill ping #批量杀死进程ping这个应急响应的时候可能会有大作用,比如shell脚本名字都是一个名,加上他可能是守护进程,杀不完,除了用三剑客语法进程批量杀出之外还可以进行pkill进行批量删除。
后台运行命令
jobs #查看后台进程列表,后台进程列表顺序号从1开始。ctrl + z #暂停进程,进程放到后台列表中,比如ping是前台一直进行的,我们可以ctrl + z进行暂停。bg #把进程放入后台运行,不是暂停哦~ 一般是你暂停后,jobs的id号,bg id这样子放入后台fg #将后台任务放在前台运行,比如ping,不管你ctrl + z还是bg放在后台了,都可以通过fg放到前台来运行或者继续运行。

三剑客篇章
三剑客大名如下:
- sed
- grep
- awk
通配符
在命令行中,我们想要输入什么就得到什么,即不会被转义成某个命令的话就使用''单引号,
而双引号,如果你输入了某些指令或者符号就会当作命令给你执行
以下是两种不同输出信息区别:
[root@localhost ~]# echo '123$(pwd)'
123$(pwd)
[root@localhost ~]# echo "123$(pwd)"
123/root
| 字符 | 说明 | 示例 |
|---|---|---|
| * | 匹配任意字符数。 您可以在字符串中使用星号 (*****)。 | ls /opt/my*.txt |
| ? | 在特定位置中匹配单个字母。 | ls /opt/myfis?.txt |
| [ ] | 匹配方括号中的字符。[abd],[a-z] | ls /opt/myfirs[a-z].txt |
| ! | 在方括号中排除字符 [!abcd] [!a-z] | ls myfirs[!a-g].txt |
| - | 匹配一个范围内的字符。 记住以升序指定字符(A 到 Z,而不是 Z 到 A)。 | [a-z] 小写的a一直到z的序列 [A-Z] [0-9a-zA-Z] |
| ^ | 同感叹号、在方括号中排除字符,用法和感叹号一样 | ls [^a-c]yfirst.txt |
find找文件与通配符
- 关于文件名的搜索
搜索/etc下所有包含hosts相关字符的文件
find /etc -name '*hosts*'搜索/etc下的以ifcfg开头的文件(网卡配置文件)
ifcfg*
find /etc -name 'ifcfg*'只查找以数字结尾的网卡配置文件(ifcfg开头的)
find /etc -name 'ifcfg*[0-9]'找到系统中的第一块到第四块磁盘,注意磁盘的语法命名
/dev/sda sdb sdd sdc sde sdf
/dev/sda1
/dev/sda2
/dev/sda3ls /dev/sd[abcd]找找sdb硬盘有几个分区,请考虑到* ? [] 通配符
-这个不对,不严谨
ls /dev/sdb*
等于找到
/dev/sdb
ls /dev/sdb1
ls /dev/sdb2
ls /dev/sdb3
-正确的写法
[0-9]
ls /tmp/dev/sdb[0-9]
-还有写法吗?
问号
ls /tmp/dev/sdb?
练习二
测试数据源准备
[yuchao-linux01 root ~/test_shell]$touch {a..h}.log
[yuchao-linux01 root ~/test_shell]$touch {1..10}.txt
[yuchao-linux01 root ~/test_shell]$ls
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt a.log b.log c.log d.log e.log f.log g.log h.log
[yuchao-linux01 root ~/test_shell]$找出a到e的log文件
ls [a-e].log找出除了3到5的txt文件
ls [!3-5].txt
ls [^3-5].txt找出除了2,5,8,9的txt文件
两个写法
ls [!2589].txt
ls [!2,5,8,9].txt尖角号一样和感叹号
[242-yuchao-class01 root ~]#ls [^2,5,8,9].txt
1.txt 3.txt 4.txt 6.txt 7.txt
[242-yuchao-class01 root ~]#ls [^2589].txt
1.txt 3.txt 4.txt 6.txt 7.txt找出除了a,e,f的log文件
ls [!aef].log
ls [^aef].log
ls [^a,e,f].log
特殊符号
比起通配符来说,linux的特殊符号更加杂乱无章,但是一个专业的linux hacker
孰能生巧,这些都不是问题
cd路径相关
| 符号 | 作用 |
|---|---|
| ~ | 当前登录用户的家目录,对目录操作的命令,cd ,ls,touch,mkdir,find,cat |
| - | 上一次工作路径,仅仅是在shell命令行里的作用 |
| . | 当前工作路径,表示当前文件夹本身;或表示隐藏文件 .yuchao.linux |
| .. | 上一级目录 |
引号相关
引号意义,为什么要用引号
- 在于区分一个字符串的边界
- 因为linux识别,命令,参数,文件对象,中间是以空格区分的
- echo 'hello world'
'' 单引号、所见即所得,引号里的所有内容,原样输出
[242-yuchao-class01 root ~]#echo 'hello&*('
hello&*(
[242-yuchao-class01 root ~]#echo 'hello!!*('
hello!!*(
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo 'hello!!*($(pwd)'
hello!!*($(pwd)
"" 双引号、可以解析变量、及引用、linux命令
[242-yuchao-class01 root ~]#echo 'hello!!*($(pwd)' "现在时间是$(date)"
hello!!*($(pwd) 现在时间是Mon Apr 11 11:04:53 CST 2022
[242-yuchao-class01 root ~]#echo "现在时间是 $(date '+%F %T')"
现在时间是 2022-04-11 11:08:26
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo '现在时间是 $(date '+%F %T')'
现在时间是 $(date +%F %T)[242-yuchao-class01 root ~]#name='吴彦祖'
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo "别人都喊我${name}"
别人都喊我吴彦祖
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo '别人都喊我${name}'
别人都喊我${name}
```反引号、可以解析命令`
输出一段话
当前时间是:时间格式化
引号嵌套
[242-yuchao-class01 root ~]#echo "当前时间是:`date '+%F %T'`"
当前时间是:2022-04-11 11:11:23
作用同上
$(linux命令)
无引号,一般我们都省略了双引号去写linux命令,但是会有歧义,比如空格,建议写引号
重定向
数据流代号
0 stdin 数据输入,如键盘的输入,如文件数据的导入
1 stdout ,cat /etc/passwd
2 stderr , cat /etc/passwdddddddddddddddddddddd
2>&1 stderr重定向
把stderr当做stdout进行处理
[242-yuchao-class01 root ~]#ls /opt/ttttttttt > /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
2>&1 stderr追加重定向
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
命令执行
-
command1 && command2 #command1成功后执行command2
编译安装软件 make && make install 例子,多个 && 多个命令成功后,向后执行 #ls && cd /opt && pwd -
|| 符 #只有前面命令失败、才执行后面命令
# 用户创建 判断用户已经存在了,就删掉用户 useradd wenjie || userdel -f wenjie -
分号,执行多个linux命令
[242-yuchao-class01 root /opt]#cd /opt ; pwd ;cd ~; /opt -
\ # 转义特殊字符,还原字符原本含义
需要和双引号结合使用 [242-yuchao-class01 root ~]#touch "\$name的文件" [242-yuchao-class01 root ~]# [242-yuchao-class01 root ~]#ls $name的文件 -
$() # 执行小括号里的命令
[242-yuchao-class01 root ~]#echo "opt下的内容是$(ls /opt)" opt下的内容是mm8888888.sh M.sh myfirst.txt -
`` # 反引号,和$()作用一样
[242-yuchao-class01 root ~]#echo "opt下的内容是`ls /opt`" opt下的内容是mm8888888.sh M.sh myfirst.txt 创建一个log文件,以当前时间命名 文件名是 "nginx_日期.log"当你进行引号嵌套时,请你这样用, 最外层用双引号,内层用单引号 touch "nginx_`date '+%F#%T'`.log" -
| # 管道符
管道符,是命令二多次加工处理找出某进程 ps -ef|grep 进程名 -
{} # 生成序列
生成英文字母序列,数字序列,用于文件拷贝的文件名简写
正则表达式
使用正则表达式的时候尽量使用单引号,因为双引号一般是用于你要执行某些命令或者要打印某些变量的时候要用的。
- 通配符和正则的区别
从语法上:只有awk grep sed才能识别正则表达式,其他的都是通配符 比如其他linux命令的操作其实都是通配符的概念记住一个点就是:正则就是在引号里面的,通配符可以不在引号里面的, 比如:ls [a-z].log 这个就是通配符,可能你已经忘掉了。
Linux下普通命令无法使用正则表达式的,只能使用linux下的三个命令,结合正则表达式处理。
- sed
- grep
- awk
基本正则表达式
BRE对应元字符有
^ $ . [ ] *
扩展正则表达式
ERE在在BRE基础上,增加了
( ) { } ? + | 等元字符
其实用的比较多的扩展正则式( ),因为我们使用这个可以进行多次匹配,() () \1 \2,就是对应的第几个括号内匹配好的正则,能够重复使用。
grep使用扩展正则的参数是-E
sed使用扩展正则的参数是-r
注意点
首先,不匹配换行这事,是因为 . 的作用
.* 是重复前面这个字符0次或N次
- 例如关于多行数据
i love you
i hate you love.*hate 这样的正则是不可用的,拿不到的数据的
-
转义符: \
-
空白行
^$
grep
grep有些参数就是为了正则而生的
-v #取反,使用正则匹配到的结果取反
-o #只看你筛选到的那一个字符,而不是直接打印出整行
-E #扩展正则表达式就要用这个 ,如果你忘记了哪个是扩展正则表达式符号,那就每一个都适用正则表达式就行了。
-w #选项默认匹配一个单词。
( ) 括号、分组符。很好用!!!
语法
() 作用是将一个或者多个字符捆绑在一起,当做一个整体进行处理1.可以用括号,把正则括起来,以及系统最多支持9个括号小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体括号内的数据,可以向后引用,其实就是\1代表你第一个括号写的内容或者正则表达式,\1省去了再次重复()内的内容或者正则表达式而已
() () () () \1 \2 \3 \4 括号()内的内容可以被后面的"\n"正则引用,n为数字,表示引用第几个括号的内容\1:表示从左侧起,第一个括号中的模式所匹配到的字符
\2:从左侧起,第二个括号中的模式所匹配到的字符
测试数据
测试数据
[root@yuchao-tx-server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
I am glad to see you, god,you are a good god!
要求仅仅匹配出glad和good
分组的第一个用法,将数据,正则当做一个整体处理
grep -E 'glad|good' god.log括号用法
grep -E 'g(la|oo)d' god.log
g.........d
分组与向后引用
-
向后引用用法, 在grep中不容易体现
-
但是用在sed中就非常牛掰了
语法
()
分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容\n
引用前面()里的内容,例如(abc)\1 表示匹配abcabc
测试数据
[root@yuchao-tx-server test]# cat lovers.log
I like my lover.
I love my lover.
He likes his lovers.
He love his lovers.
提取love出现2次的行
[242-yuchao-class01 root ~]#grep -E '^.*(love).*\1.*' lovers.txt -o
I love my lover.
He love his lovers.
sed
sed默认是一行一行,处理文件中每一行的数据
工作里用的最多的还是指定数字行号,或者完整字符精确匹配,不容易出错,
而正则或是其他模糊匹配,很容易改错,了解即可。
参数
-n 取消默认的 sed 软件的输出,常与 sed 命令的 p 连用
-e 说白了-e就是实现多次编辑,-e告诉sed你编辑完后可以第二次使用-e参数继续编辑你第一轮搞好的数据,一行命令语句可以执行多条 sed 命令
-f 选项后面可以接 sed 脚本的文件名
-r 使用正则拓展表达式,默认情况 sed 只识别基本正则表达式
-i 直接修改文件内容,而不是输出终端, 如果不使用-i 选项 sed 软件只是修改在 内存中的数据,并不影响磁盘上的文件
命令
个人比较常用的命令
a 追加,在指定行后添加一行或多行文本
p 打印模式空间的内容,通常 p 会与选项-n 一起使用
d 删除指定的行
i 插入,在指定的行前添加一行或多行文本
s 取代,s#old#new#g==>这里 g 是 s 命令的替代标志,注意和 g 命令区分。g命令是全局替换,而不加g参数的话就是每一行的第一个匹配成功的就替换。同时s命令不仅仅可以使用#进行分割,还能使用@或者/,用#是因为好区分,不容易混淆。
c 直接替换指定的行,语法是:c命令后面接要替换的数据 sed '1 c data' file.txt其他命令
D 删除模式空间的部分内容,直到遇到换行符\n 结束操作,与多行模式相关
h 把模式空间的内容复制到保持空间
H 把模式空间的内容追加到保持空间
g 把保持空间的内容复制到模式空间
G 把保持空间的内容追加到模式空间
x 交换模式空间和保持空间的内容
l 打印不可见的字符
n 清空模式空间,并读取下一行数据并追加到模式空间
N 不清空模式空间,并读取下一行数据并追加到模式空间
P(大写) 打印模式空间的内容,直到遇到换行符\你结束操作
q 退出 sed
r 从指定文件读取数据
w 另存,把模式空间的内容保存到文件中
y 根据对应位置转换字符
:label 定义一个标签
t 如果前面的命令执行成功,那么就跳转到 t 指定的标签处,继续往下执行后 续命令,否则,仍然继续正常的执行流程
对sed软件的一些理解:
命令模式是在引号中使用的,参数就是正常的加参数一样即可。
sed主要是用于搜索内容和进行文本替换的,因为是一个软件,所以能够用于进行shell脚本的编写。
格式:sed '行号 命令(可以多个)' file
这个行号可以是一个范围,下面就是一个行范围语法↓↓↓↓↓↓↓
关于sed处理文件行范围语法
| sed命令语法 | 作用 |
|---|---|
| 3 | 操作第三行 |
| 3,6 | 操作3~6行,包括3和6行 |
| 3,+5 | 操作3到3+5(8)行,包括3,8行 |
| 1~2 | 步长为2,操作1,3,5,7..行 |
| 3,$ | 对3到末尾行操作,包括3行 |
| /yuchao/ | 对匹配字符yuchao的该行操作 |
| /yuchao/,/chaoge/ | 对匹配字符yuchao到chaoge之间的行操作 |
| /yuchao/,$ | 对匹配字符yuchao到结尾的行操作 |
| /yuchao/,+2 | '/yuchao/,+2p',打印匹配到yuchao的行,包括其后2行 |
| /yuchao/ {!d} # 这里!表示取反的意思,其他命令能用的话也是一个道理 | 找到yuchao行,然后不删除他,删除除了yuchao的行 |
| 备注:使用//,里面匹配的内容可以是正则表达式,所以sed功能非常强大 |
---shell
下面介绍增删查改,但是不管是增删查改,里面处理文件行范围或者方式都是通用的,只不过使用的参数和命令不一样罢辽。
增
增加数据的命令有:a 和 i
在第二行进行添加数据(没有要求修改文件那就不用 -i 参数)
sed '2 i 添 加 的 内 容 ' file.txt #这里添加的内容可以是有空格的,因为你命令i后面接的本来就是文本内容注意:添加多行的话,直接输入\n即输入了回车换行
删
sed不指定行号的话,默认匹配所有行,执行d删除命令
sed 'd' file.txt
删除第二行数据
sed '2 d' file.txt
删除第二行到第五行数据
sed '2,5 d' file.txt
删除第二行和往下的两行
sed '2,+2 d' file.txt
只保留第一和第二行
sed '3,$ d' file.txt
只保留奇数行
sed '1~2 d' file.txt #从1行开始,步长为2,那么就是1 3 5 7 9,保留偶数行那就是2~2
根据正则匹配删除对应的行数据
sed '/正则表达式/ d' file.txt
删除两个正则表达式之间的行数据
sed '/正则1/,/正则2/ d' file.txt
删除指定的两个正则表达式匹配成功的行数据(注意,两个正则式不一样的,只要两个其中一个匹配都要删除)
sed '/正则1/;/正则2/ d' file.txt
删除以.结尾的行
sed '/\.$/ d' file.txt
查
查的话就是找出来然后打印出来,那么就要用到p命令
根据正则表达式找到对应的行,然后打印出来(仅打印你找到的行即可)
需要用到 -n 参数和 p 命令
sed -n '/正则表达式/ p' file.txt
忽略大小写匹配正则表达式,然后打印出来
sed -n '/正则/ I p' file.txtsed -n '/正则/ Ip' file.txtsed -n '/正则/Ip' file.txt以上三个都是一样的结果,因为这里参数用的比较多,就在这里作为一个例子,命令和参数其实都可以进行堆叠在一起使用
改
行替换:替换第二行数据为xxx OK
sed '2 c xxx OK' file.txt
字符替换:将每一行第一处匹配的字符替换,将www替换为xxx
(以下三种方式都是可以,但是用#居多)
sed 's#www#xxx#' file.txtsed 's@www@xxx@' file.txtsed 's/www/xxx/' file.txt
字符替换:全局匹配的字符,将所有www替换为xxx
(g为全局替换)
sed 's#www#xxx# g' == sed 's#www#xxx#g'
指定最后一行($) 字符www替换为hacker
-
第一个匹配成功的替换
sed '$ s#www#hacker#' file.txt -
所有匹配成功的都替换
sed '$ s#www#hacker#g' file.txt
指定数据中,根据字符替换提取出welcome字符
echo 'I am teacher yuchao,welcome my linux course'
echo 'I am teacher yuchao,welcome my linux course' | sed -r 's#.*,(.*)\sm.*#\1#g'
\s表示单个空格
分组取出ip
使用命令ip a,用sed将其ip提取出来
ip a | sed -rn 's#^.*inet\s([0-9]{,3}.[0-9]{,3}.[0-9]{,3}.[0-9]{,3})/[0-9]{,2}\sbrd.*#\1#g p'

注意
如果要使用shell脚本变量的话记得使用双引号,不要忘记了单引号是你给啥就输出啥,还有用正则的时候使用单引号s###替换字符中,你在##之间是可以直接写正则表达式的,然后如果你不是使用替换字符命令的话就需要使用//字符中间才能够写正则表达式进行操作。
其他命令
多次编辑-e
找出http和linux的行
sed -e '/http/p' -e '/linux/p' -n t1.log
解释:
sed -e '/http/p' 是在打印所有文本的过程中,如果找到匹配的数据后将那个数据再打印一份,
第一次出来的数据,同时还使用了p命令存储了一次匹配的数据,给到下一次匹配的话还是完整的数据,
那么这样的话我们第二次-e后面那个就能够继续使用正则匹配继续匹配,然后还是使用p命令进行存储
然后接着-n参数就能够将两次p命令存储的匹配出来的数据进行一次性打印了。
写入文件w命令
sed '/正则/ w 要写入的文件路径' file.txt
比如:
匹配http的正则表达式,然后写入/etc/ok.ok文件中
sed -n '/http/ w /etc/ok.ok' file.txt #注意:这里使用-n意思是不打印出来文件中的内容,最好习惯性的加上该参数,因为以后要处理的文件数据量会十分大,-n参数不会影响操作,只是一个打印和不打印的区别而已。
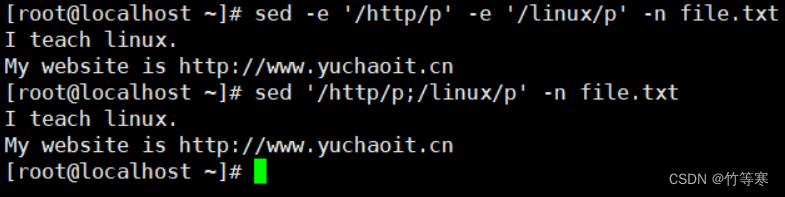
;分号
分号也用于执行多条命令,这里和-e能够实现一样的效果
比如:我要同时提取出http和linux相关的行。
-e参数写法
sed -e '/http/p' -e '/liunx/p' -n file.txt分号写法
sed '/http/p;/linux/p' -n file.txt
awk
对行操作、对列操作
-
如何分割数据,
-
如何输出数据,指定第一行,到第三行
语法:
awk 参数 '模式 {动作}' test.txt模式可以理解为是一种判断,那么就是可以用&& || ,就是说可以是一个判断比如NR判断行号,或者是正则匹配。
模式是这样指定正则的:awk '/正则/{print $0}'
测试数据生成指令:
echo www{01..50} | xargs -n 5 > test.txt #xargs -n参数是排版,每一行只打印5列,然后输入文件中即可
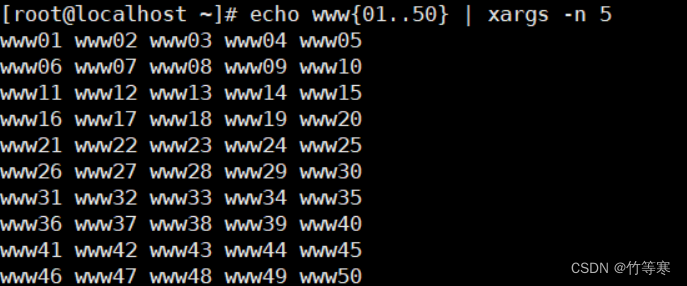
动作
| awk变量符号 | 作用 | 名称翻译 |
|---|---|---|
| NR | 行记录、行数据、awk处理的第几行 | umber of record |
| NF | 字段的数量,表示这一行数据分了几列, | Number of filed, |
| $1 | 第一个字段的数据、$2、$3以此类推 |
$0表示打印所有列数
awk '{print $0}' test.txt
打印每一行数据的第一列数据
awk '{print $1}' test.txt
打印每一行数据的第二列数据
awk '{print $2}' test.txt
打印每一行的第一和第三列
awk '{print $1,$3}' test.txt
NR内置变量
NR内置行变量
直接打印这个内置变量,表示取当前行的号码
NR == number of record 行记录,你也可以记住row表示行,我个人觉得这样好记一点
NR>= 大于等于行
NR<= 小于等于
NR>=N && NR<=M 从N行到M行
|| 或的用法
开头显示行号
awk '{print NR,$0}' test.txt
结尾显示行号
awk '{print $0,NR}' test.txt
打印第二行的所有字段数据(同理可以打印其他行的数据)
awk 'NR==2 {print $0}' test.txt
打印第一行到第三行的所有字段
awk 'NR>=1&&NR<=3 {print $0}' test.txt
NF内置变量
NF内置列变量
直接写NF变量表示每一行字段的总数
number of field (字段的数量) 等于列的总数
请注意理解:NF表示每一行的列数,那么我们NF打印的就是每一行的列数,那么加个$的话就是$NF,那不就是变成了每一行的最后一列了吗!!!!!!!!!!!
在所有数据后面加上每一行的列数
awk '{print $0,NF}' test.txt

仅仅打印最后一列的数据
awk '{print $NF}' test.txt那么同理输出倒数第2列
awk '{print $(NF-1)}' test.txt
打印第二列到第五列的数据
awk '{print $2,$3,$4,$5}' test.txt
NR 和 NF 结合一下就可以美化输出了。
-
输出全部数据的同时,输出每一行分别有多少列和同时输出行号
awk '{print $0,NF,NR}' test.txt[root@localhost ~] awk '{print $0,NF,NR}' test.txt www01 www02 www03 www04 www05 5 1 www06 www07 www08 www09 www10 5 2 www11 www12 www13 www14 www15 5 3 www16 www17 www18 www19 www20 5 4 www21 www22 www23 www24 www25 5 5 www26 www27 www28 www29 www30 5 6 www31 www32 www33 www34 www35 5 7 www36 www37 www38 www39 www40 5 8 www41 www42 www43 www44 www45 5 9 www46 www47 www48 www49 www50 5 10
其他变量
下面两个变量都是可以通过-v参数进行修改的
RS ##行分隔符,默认行分隔符是\n换行符,你可以通过-v参数修改,awk -v RS=' '进行修改,比如修改成空格为行分割符,那就碰到空格为一行
ORS ##输出行分隔符,默认输出的行分隔符是\n,这个对我们将输出美化来说很重要,下面用一个例子进行举例说明
FS ##列分隔符,默认列分隔符是空格,你可以通过-v参数修改,awk -v FS=':'进行修改,比如修改成:列分割符,那就是碰到:为一列
OFS ##输出列分隔符,默认是空格,这个也是对我们输出美化很重要。
注意:修改列分割符一般不这么使用,我们一般是使用-F参数,比如:awk -F ':' ... 这样就是修改了列分隔符为:
-
RS
测试数据为:
[root@localhost ~]# echo 111@@222@@333@@444@@555 > RS.txt [root@localhost ~]# cat RS.txt 111@@222@@333@@444@@555第一种美化数据,因为ORS默认就是\n为行分割符号:
awk -v RS='@@' '{print $0}' RS.txt当然你也可以多此一举加一个: -v ORS='\n' awk -v RS='@@' -v ORS='\n' '{print $0}' RS.txt第二中美化数据,自己指定ORS行分割符号:
awk -v RS='@@' -v ORS='---------' '{print $0}' RS.txt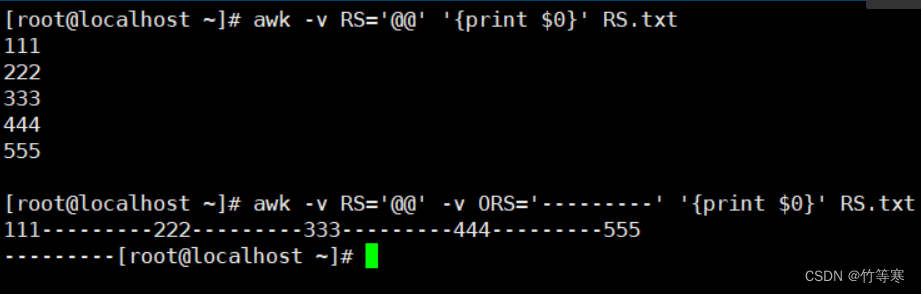
-
ORS
测试数据为:
[root@localhost ~]# cat ORS.txt 111 222 333 444 555将行分隔符换成@@
awk -v ORS='@@' '{print $0}' ORS.txt[root@localhost ~]# awk -v ORS='@@' '{print $0}' ORS.txt 111@@222@@333@@444@@555@@总结:
一般来说,如果你仅仅要修改为换行符为\n,那么直接使用RS进行切割开即可,因为ORS默认就是\n,
而你要使用ORS进行修改的通常是希望数据不以\n进行分割的。 -
OFS
测试数据为:
这个故意设置分隔符号为@@,我们下面进行变量设置的时候理解的更加到位
[root@localhost ~]# cat OFS.txt 111@@222@@333@@444@@555下面指令是一样的,只不过是直接使用了-F参数[root@localhost ~]# awk -F @@ -v OFS=':' '{print $1,$2}' OFS.txt 111:222目标是将@@分隔符修改为冒号 :
[root@localhost ~]# awk -v OFS=':' -v FS='@@' '{print $1,$2}' OFS.txt 111:222总结:
不要忘记了FS默认列分隔符是空格,所以我们这里测试数据就是故意用@@作为分隔符,
所以我们就需要特地的修改FS变量为@@,这样才能取到对应的列出来,
然后我们通过OFS修改输出的列分隔符号即可。
BEGIN 和 END
一道题就能理解了
无非就是
BEGIN就是开头
END就是结尾
就是在开头和结尾加上你要加的东西即可,然后格式的话只不过是位置和多了BEGIN或者END而已
head -5 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinawk -v FS=':' 'BEGIN{print "用户名","uid","gid","家目录","登录解释器" } NR<=5{print $1,$3,$4,$6,$7} END{print "awk_over~"}' /etc/passwd | column -tcolumn -t是美化输出的

参数
-v 修改awk内置变量RS 设置哪个为你的数据行分隔符ORS 修改要输出的行分隔符FS 设置哪个为你的数据列分隔符OFS 修改要输出的列分隔符
-F 修改列分隔符
系统资源篇章
正在努力完善中...
软件包篇章
正在努力完善中...
磁盘篇章
正在努力完善中...