https://zhuanlan.zhihu.com/p/585749690
全网最全EdgeMesh Q&A手册

转载请注明出处
本人信息如下,有任何问题请联系我:
github链接:Poorunga - Overview
邮箱:2744323@qq.com
前言
重要的事情1说三遍:定位问题前先看edgemesh-agent日志!定位问题前先看edgemesh-agent日志!定位问题前先看edgemesh-agent日志!
服务访问不通原因有很多,大部分都记录在这篇日志里,先用kubectl logs或者docker logs看看edgemesh-agent容器的日志。自己定位的时候你得看,请别人帮忙定位的时候,你也得先把日志发给别人看。
重要的事情2说三遍:定位问题前先自检!定位问题前先自检!定位问题前先自检!否则你可能将白白浪费你的时间。如何自检请仔细阅读:
1.前置准备:快速上手 | EdgeMesh | 前置准备
2.启用边缘Kube-Endpoint API:边缘 Kube-API 端点 | EdgeMesh | 快速上手
自检时请一条条仔仔细细的过,确保没问题。
最后,如果你觉得这篇文章对你有帮助,同时你觉得EdgeMesh是一个有意思的项目,希望你能给EdgeMesh仓库点上一个小星星:
定位模型
EdgeMesh的定位思路具有下面一个重要模型:
发起访问的podA->edgemesh-agent(跟podA在同一个节点)->edgemesh-agent(跟podB在同一个节点)->被访问的podB
画图所示就是:
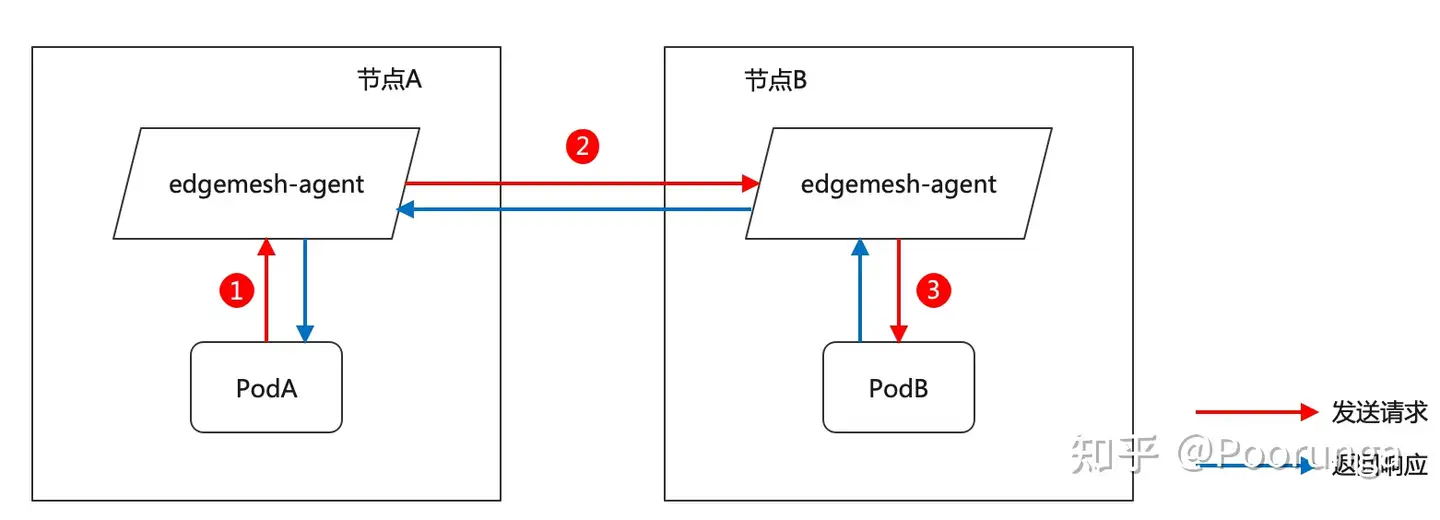
举个例子,podA是订单微服务的后端,另外还有个数据库服务,podB是数据库服务的后端实例。实际情况中微服务为了做高可用,可能会部署多个后端,也即可能存在podA-0,podA-1,podA-2,podB也是一样,为了简化我们的问题,我们还是抽象出上面的定位模型。
大部分问题都可以归纳为以下几种:
圆圈1:podA侧的流量没被edgemesh-agent(左)拦截到,比如问题三、问题十三、问题十四
圆圈2:edgemesh-agent(左)发现不到edgemesh-agent(右),更甚的是edgemesh-agent(右)根本没部署,比如问题六、问题十六
圆圈3:一般不会出问题
问题一:Failed to watch xxx: failed to list xxx: no kind xxx ; Reflector ListAndWatch xxx (total time 10003ms)
- 如果cloudcore是二进制部署的,请你再仔细按照前言说的自检一下。
- 如果cloudcore是容器化部署的,也先仔细按照前言说的自检(注意如果容器部署的话,cloudcore的配置是一个k8s configmap)。然后再检查cloudcore的clusterrole是不是跟 cloudcore clusterrole配置文件 里的一致(特别是namespaces和networking.istio.io这两项配置)。有些用kubesphere的用户,使用了kubesphere内置的kubeedge,其中kubeedge的yaml文件都是上古老版本了,得更新一下。
问题二:calico、flannel无法在边缘节点启动
这个问题和edgemesh没半毛钱关系。你想知道到底是为啥,可以阅读材料:边缘 Kube-API 端点 | EdgeMesh | 背景 。
跑在边缘节点的容器,是没法通过访问kubernetes这个服务的clusterIP(10.96.0.1)访问到kube-apiserver的,看下方的iptables规则,对clusterIP(10.96.0.1:443)的访问最终会DNAT到192.168.0.229:6443,192.168.0.229是部署kube-apiserver的节点的IP,你边缘节点所处的网络和它在不同的子网里,所以访问不到。
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 307d$ iptables -t nat -nvL | grep kubernetes:https | grep 10.96.0.10 0 KUBE-MARK-MASQ tcp -- * * !10.244.0.0/16 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:4430 0 KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- * * 0.0.0.0/0 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
$ iptables -t nat -nvL | grep kubernetes:https | grep DNAT0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/kubernetes:https */ tcp to:192.168.0.229:6443如果你不知道什么是iptables规则,关键字 Linux iptables、netfilter原理和四表五链。如果你不知道处于不同网络的含义,关键字计算机网络、NAT、cidr,查关键字自己学吧。
不过通过修改配置,对接到edgecore的边缘kube api endpoint后,像kube-proxy,flannel等组件就能跑起来了,不过flannel、calico、cilium等常见的CNI插件,不支持跨子网的pod流量转发,也即云边不能通。
问题三:curl、telnet、nc卡住; No route to host
1.大多数原因都是因为kube-proxy根链插在了edgemesh根链的前面
要搞懂这个问题你得对 Linux iptables、netfilter原理和四表五链 有基本的了解,然后再阅读:混合代理 | EdgeMesh | 原理。kube-proxy和edgemesh都具有流量代理功能,目前两者的原理都是通过iptables去拦截应用发出的流量,再做代理/转发。
此问题一般发生在kube-proxy和edgemesh共存的云节点上,如果有不明白,请看问题十。
临时规避方式如下:
a. 先卸载edgemesh
b.清理iptables规则
$ iptables -F
$ iptables -X
$ iptables -t nat -F
$ iptables -t nat -X
$ systemctl restart dockerc. 更新或新建一个k8s service,这是为了触发kube-proxy重建自己的链
d.重新部署edgemesh,这一步确保了edgemesh根链插入到kube-proxy根链前面
你想问为啥不让edgemesh-agent代码每隔一段时间检查一下链的顺序,如果有误就插入到kube-proxy链前面?我觉得可以,等有时间就去优化一下。当然,我也非常欢迎你能贡献代码。
2.少数原因是因为iptables的版本不对,低版本的DNAT规则长得很怪异,也不能正常拦截流量,原因不明。可以看看edgemesh创建的iptables正常长成什么样子(在边缘节点上),如下:
$ iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 14272 packets, 1310K bytes)pkts bytes target prot opt in out source destination 3 184 KUBE-PORTALS-CONTAINER all -- * * 0.0.0.0/0 0.0.0.0/0 /* handle ClusterIPs; NOTE: this must be before the NodePort rules */3 184 KUBE-NODEPORT-CONTAINER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL /* handle service NodePorts; NOTE: this must be the last rule in the chain */Chain INPUT (policy ACCEPT 14278 packets, 1311K bytes)pkts bytes target prot opt in out source destination Chain POSTROUTING (policy ACCEPT 394K packets, 105M bytes)pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 394K packets, 105M bytes)pkts bytes target prot opt in out source destination 48 3769 KUBE-PORTALS-HOST all -- * * 0.0.0.0/0 0.0.0.0/0 /* handle ClusterIPs; NOTE: this must be before the NodePort rules */7 445 KUBE-NODEPORT-HOST all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL /* handle service NodePorts; NOTE: this must be the last rule in the chain */Chain EDGEMESH-NODEPORT-CONTAINER (0 references)pkts bytes target prot opt in out source destination Chain KUBE-PORTALS-CONTAINER (1 references)pkts bytes target prot opt in out source destination 0 0 DNAT udp -- * * 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns */ udp dpt:53 to:169.254.96.16:413230 0 DNAT tcp -- * * 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns-tcp */ tcp dpt:53 to:169.254.96.16:408770 0 DNAT tcp -- * * 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:metrics */ tcp dpt:9153 to:169.254.96.16:400410 0 DNAT tcp -- * * 0.0.0.0/0 10.96.0.1 /* default/kubernetes:https */ tcp dpt:443 to:169.254.96.16:42665Chain KUBE-PORTALS-HOST (1 references)pkts bytes target prot opt in out source destination 0 0 DNAT udp -- * * 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns */ udp dpt:53 to:169.254.96.16:413230 0 DNAT tcp -- * * 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns-tcp */ tcp dpt:53 to:169.254.96.16:408770 0 DNAT tcp -- * * 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:metrics */ tcp dpt:9153 to:169.254.96.16:400410 0 DNAT tcp -- * * 0.0.0.0/0 10.96.0.1 /* default/kubernetes:https */ tcp dpt:443 to:169.254.96.16:42665Chain KUBE-NODEPORT-CONTAINER (1 references)pkts bytes target prot opt in out source destination Chain KUBE-NODEPORT-HOST (1 references)pkts bytes target prot opt in out source destination对于edgemesh <= v1.11,链的名字是EDGEMESH- 开头的,edgemesh >=v1.12,链的名字是KUBE-开头的。
问题四:env MY_NODE_NAME not exist; /etc/edgemesh/edgemesh-agent.yaml not exists
首先这是因为edgemesh-agent版本存在差异,如下:
EdgeMesh <= v1.11
1.需要部署edgemesh-server和edgemesh-agent两个组件
2.配置文件在/etc/kubeedge/config/edgemesh-agent.yaml下,环境变量叫 MY_NODE_NAMEEdgeMesh >= v1.12 (包括latest)
1.只需要部署edgemesh-agent
2.配置文件在/etc/edgemesh/config/edgemesh-agent.yaml下,环境变量叫 NODE_NAME重点来了:如果你使用kubeedge/edgemesh-agent:latest镜像还遇到这个问题,那是因为有些机器的docker去拉kubeedge/edgemesh-agent:latest镜像老是拉到旧的,原因不明。 但kubeedge/edgemesh-agent:latest镜像我最近是更新过的,下图可证:
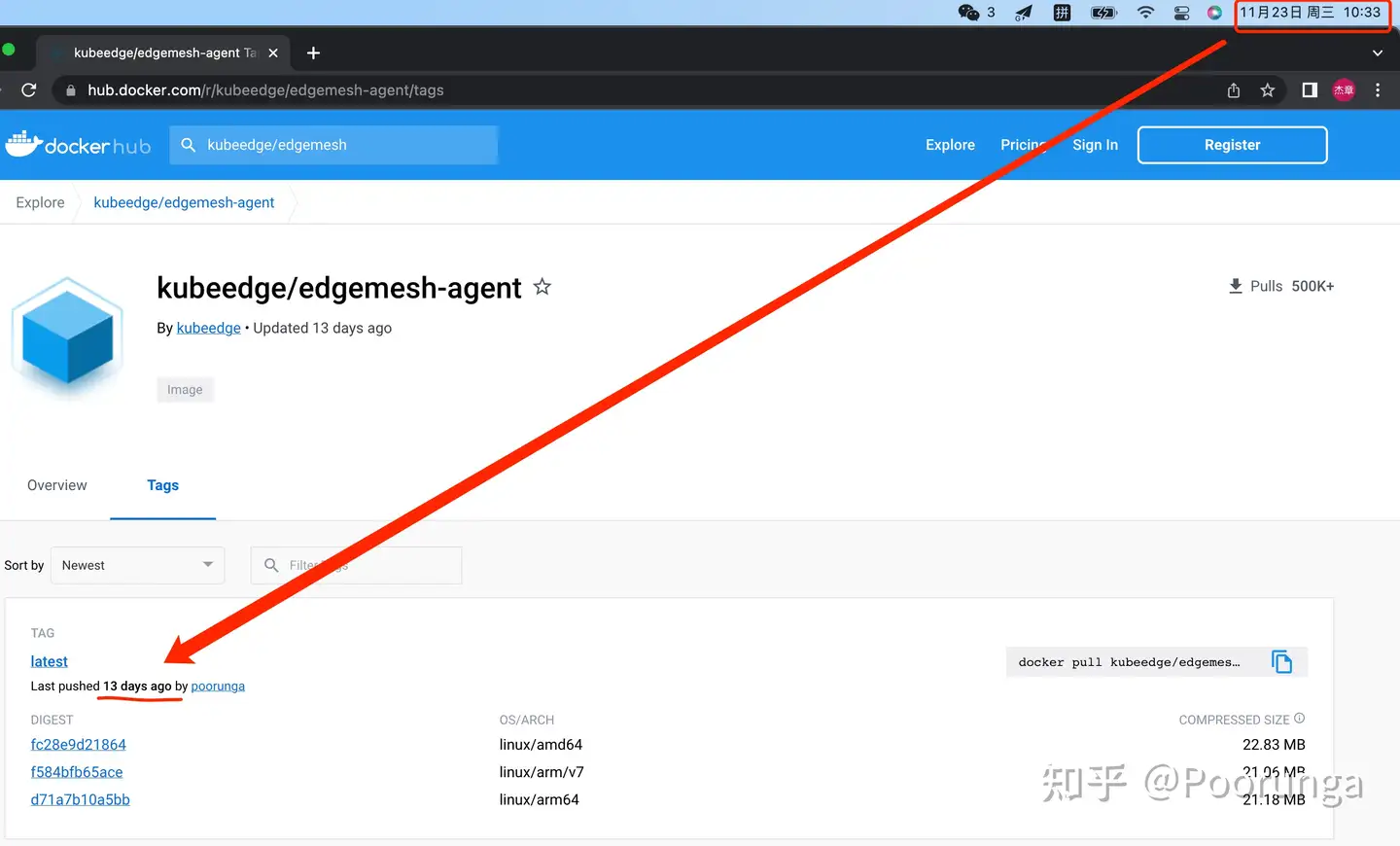
真不怪我啊,而且每次edgemesh仓库有commit合入main分支就会打latest镜像并push,你得看看自己的docker出啥问题了。
解决方法就是别用latest镜像,通过指定镜像版本和helm版本部署edgemesh:
1.如果选用的EdgeMesh版本 >= v1.12.0
$ helm install edgemesh --namespace kubeedge \
--set agent.image=kubeedge/edgemesh-agent:v1.12.0 \
--set agent.relayNodes[0].nodeName=k8s-node1,agent.relayNodes[0].advertiseAddress="{119.8.211.54,2.2.2.2}" \
https://raw.githubusercontent.com/kubeedge/edgemesh/release-1.12/build/helm/edgemesh.tgz2.如果选用的EdgeMesh版本 <= v1.11.0
$ helm install edgemesh \
--set agent.image=kubeedge/edgemesh-agent:v1.11.0 \
--set server.image=kubeedge/edgemesh-server:v1.11.0 \
--set server.nodeName=k8s-node1 \
--set server.advertiseAddress="{119.8.211.54}" \
https://raw.githubusercontent.com/kubeedge/edgemesh/release-1.11/build/helm/edgemesh.tgz问题五:bad address xxx; Could not resolve host xxx
这是一个域名解析(DNS request)问题。
首先你要搞清楚是在云上节点(kubelet节点)还是边缘节点(edgecore节点)遇到这个问题。如果你是在云上节点(kubelet节点)遇到这个问题,那和edgemesh没有半毛钱关系,因为云上节点的域名解析是coredns或kube-dns负责的,不过你可以看看有没有可能是问题六导致的。
如果在边缘节点上遇到这个问题,那么定位思路如下:
- 先用clusterIP访问,测试连通性。比如有个mysql服务的域名是 my-mysql.default 对应的 clusterIP是10.96.0.25,那就(用curl或telnet或nc,反正别用ping)访问10.96.0.25看看能不能通,能通证明连通性没问题,至少家保住了!
2. 看发起访问的pod内的/etc/resolv.conf内容,有没有 nameserver 169.254.96.16。
/etc/resolv.conf是用来配置主机(或容器内)的域名解析服务器的文件,不懂的话自己搜一下去学。 169.254.96.16是edgemesh监听的网桥IP,其中 169.254.96.16:53 是edgemesh的域名解析模块监听的socket。如果/etc/resolv.conf内容里没有nameserver 169.254.96.16,那域名解析请求肯定发不到edgemesh的域名解析模块里。
注意:请别手动修改pod内的/etc/resolv.conf,因为pod重建后记录就消失了;当然,也别往你宿主机的/etc/resolv.conf写入nameserver 169.254.96.16,因为如果edgemesh-agent不在你宿主机上运行的话,这条nameserver会影响到你宿主机的域名解析。如果你非得改/etc/resolv.conf,你必须非常了解 /etc/resolv.conf 的原理,同时你得清晰的知道自己为什么这么干。
那为什么你的pod里的/etc/resolv.conf不对呢?
a.重点来了,这里有一个k8s 知识点,就是关于pod的DNS策略,请看 Pod 的 DNS 策略。
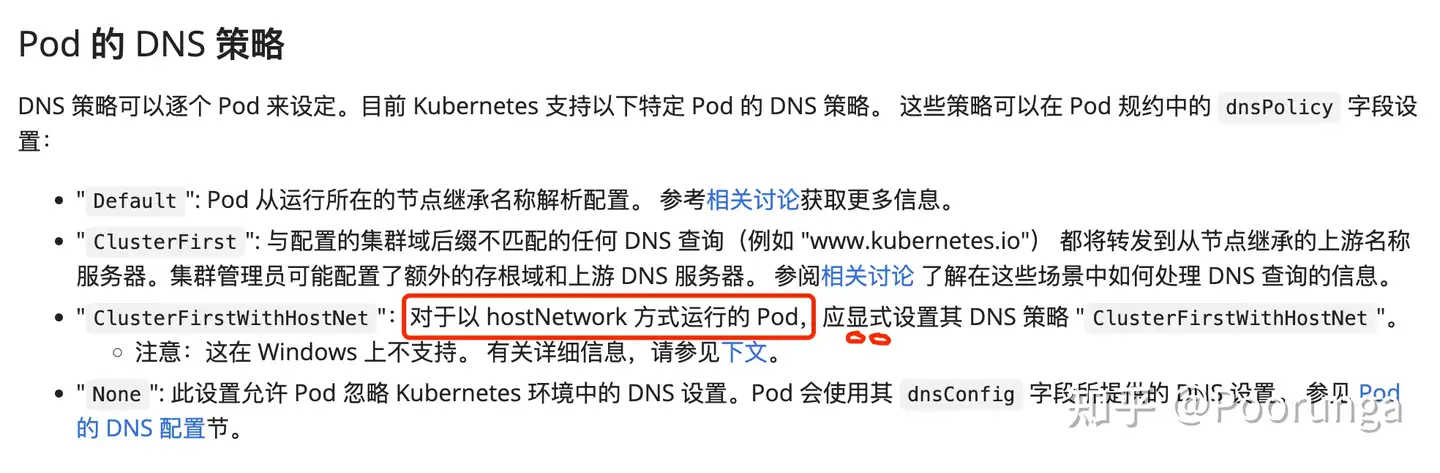
简单的说就是,如果你的pod是hostNetwork: true(也即主机网络启动的),那你得配置 dnsPolicy: ClusterFirstWithHostNet,然后重启你的pod。
b.如果你的pod是容器网络的(不是主机网络那就是容器网络了),但是/etc/resolv.conf的内容还是不对,请你给我再去自检一遍。自检完后,如果edgecore的配置修改了,记得重启你的pod,那样/etc/resolv.conf才能生效。
3. 如果上述的 1 和 2 都没问题,那你可以先去宿主机上测试一下其他域名通不通:
$ nslookup kubernetes.default.svc.cluster.local 169.254.96.16
Server: 169.254.96.16
Address: 169.254.96.16#53Name: kubernetes.default.svc.cluster.local
Address: 10.96.0.1然后再自己创建一个test服务测一下通不通:
$ nslookup test-svc.default.svc.cluster.local 169.254.96.16
Server: 169.254.96.16
Address: 169.254.96.16#53Name: test-svc.default.svc.cluster.local
Address: 10.109.140.60nslookup是域名解析工具,不懂自学;中间是服务的域名;最后是域名解析服务器的IP(169.254.96.16:53代表edgemesh的域名解析服务模块监听的socket)
重点来了,如果nslookup测试后都是通的,那么我认为edgemesh的域名解析没任何问题,那为啥还是解析不了域名呢?
可能是 KubeEdge issue 3445 导致。因为edgemesh用于域名解析的元数据来自于edgecore的metaserver,metaserver发送了service 的DELETE事件,edgemesh拿到这个事件后,就把这个service的元数据从内存中删除了,导致域名解析的时候查不到元数据。
根据issue里的指导,临时规避方式如下:
a. 删除service
b. kubectl delete objectsync --all
c. 重启cloudcore、edgecore,重新部署edgemesh
d. 重新创建service问题六:装edgemesh后,云上节点域名解析失效了
装edgemesh前云上的域名解析好好的,装edgemesh后,云上的域名解析失败了。
首先,云上的域名解析服务是coredns或kube-dns做的(在kube-system命名空间下,clusterIP通常是10.96.0.10)。这是k8s自己的域名解析服务,云上所有pod的集群域名解析都由他们完成。k8s自己的域名解析服务也是一个k8s service,和你自己创建的service没任何区别。
你部署了edgemesh,那默认来说edgemesh就会拦截所有的k8s service,包括k8s自己的域名解析服务。那么为什么edgemesh拦截后,就不通了呢?
请再复习一下定位模型,这大概率是因为coredns-pod所处的节点,它没部署edgemesh-agent,导致发起端的edgemesh-agent找不到对端,所以流量送不过去。这个情况是非常经常出现的,因为coredns一般会部署在k8s master节点上,而master节点一般都有污点,会驱逐其他pod,进而导致edgemesh-agent部署不上去。这种情况可以通过去除节点污点,使edgemesh-agent部署上去解决。
还有一种规避方法,就是不让edgemesh去代理k8s自己的域名解析服务:
先阅读一下:混合代理 | EdgeMesh | 服务过滤,总结就是:
$ kubectl -n kube-system label services coredns service.edgemesh.kubeedge.io/service-proxy-name=""
或
$ kubectl -n kube-system label services kube-dns service.edgemesh.kubeedge.io/service-proxy-name=""问题七:宿主机上不能解析集群域名
集群域名格式:service-name.namespace.svc.cluster.local 在pod内访问域名时,后缀 svc.cluster.local 是可逐个省略的,比如mysql.default.svc.cluster、mysql.default.svc 和 mysql.default
外部域名格式: www.baidu.com, www.jd.com 等等
首先,没人说过宿主机上能解析集群域名啊!不信你试试在云上k8s节点的宿主机上,用nslookup解析集群域名试试。
pod内能解析域名,是因为:
- 云上节点,当kubelet启动一个pod时,会往pod的/etc/resolv.conf写入coredns或kube-dns的clusterIP,比如:
$ cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local openstacklocal
options ndots:52.边缘节点,当edgecore(需要配置过clusterDNS)启动一个pod时,会往pod的/etc/resolv.conf写入 nameserver 169.254.96.16(169.254.96.16:53就是edgemesh的域名解析模块监听的socket)
kubelet和edgecore会往pod的/etc/resolv.conf写入什么内容,也取决于pod是否是主机网络,以及pod的dnsPolicy,请看 问题五的2.a 学习一下。
如果你非得在宿主机上访问集群域名,那你就把域名解析服务器的ip手动写入到宿主机上的/etc/resolv.conf。 云上是coredns或kube-dns的clusterIP,如10.96.0.10;边缘是edgemesh的网桥IP 169.254.96.16
问题八:Get xxx:10350/containerLogs xxx timeout
你这是想在云上节点通过 kubectl logs 命令看处于边缘节点的pod的日志对吧?还是想在云上节点通过 kubectl exec 命令登录边缘节点的pod?
和edgemesh没半毛钱关系,请移步:KubeEdge启用logs与exec功能
问题九:can't open node port for xxx bind: address already in use
一般出现在kube-proxy和edgemesh共存的云节点上(可以共存,没说不能共存)。另外,这个报错并不会影响你使用edgemesh。
kube-proxy和edgemesh都会去代理k8s 的 services,对于nodePort类型的services,kube-proxy和edgemesh都会处理它,并会去主机上启动一个监听的端口。比如一个service的type是NodePort,nodePort地址是30001,那么kube-proxy和edgemesh都会尝试去主机上启动并监听30001端口。
读到这你应该明白了,其实就是kube-proxy优先处理了这个NodePort Service,并监听在主机某个端口。然后edgemesh也想去处理这个service,也想在主机监听同一个端口,所以就bind: address already in use。
如果你看这个日志很烦,可以这么规避,请阅读:混合代理 | EdgeMesh | 服务过滤 ,把服务过滤掉。
如果这个服务你就是希望它被edgemesh代理(可能你想跨云边去访问这个服务),请给服务打上http://service.kubernetes.io/service-proxy-name 标签,使此服务不被kube-proxy代理。
还有不明白,请看问题十
问题十:在edgemesh和kube-proxy共存的节点,服务会被谁给代理?
请先阅读:混合代理 | EdgeMesh ,作为扩展知识,还建议你学习一下Linux iptables、netfilter原理和四表五链。
所以,在edgemesh和kube-proxy共存的节点上,一个k8s service会被谁代理,得看发出的流量优先被谁给拦截了(即谁的根链在前,谁就更先拦截)。可以结合 问题二、三 再细品一下。
此外,一个k8s service:
- 不想让edgemesh代理的话,请给服务打上
http://service.edgemesh.kubeedge.io/service-proxy-name标签 - 不想让kube-proxy代理的话,请给服务打上
service.kubernetes.io/service-proxy-name标签
问题十一:怎么调试edgemesh代码
建议使用Goland IDE,同时升级Goland到2022.02后的版本,这个版本会自带ssh功能,你可以ssh到你的服务器上去调试代码。
调试方法很多,举例一个我的调试方法:
- 搞一个服务器,比如服务器A,把服务器A纳管成k8s的节点或者边缘节点
- 在你的k8s集群部署edgemesh,这时候edgemesh-agent会部署到服务器A上
- 通过给节点(服务器A)添加污点,把服务器A上的edgemesh-agent的pod驱逐掉
- 在服务器A下载edgemesh源代码,然后用Goland IDE连接上去,确保能远程编译、运行和调试
- 准备edgemesh需要的环境变量和配置文件,如NODE_NAME、edgemesh-agent.yaml等等(后续运行的时候缺什么就补什么)
- 通过Goland IDE 的ssh功能连接服务器A上的edgemesh代码,这时候对edgemesh的编译、运行和调试都是发生服务器A上的
还有另一个方式,就是直接进k8s pod去调试,不过需要给Goland IDE安装插件,请阅读 什么是 Nocalhost? | Nocalhost。需要你自己花点时间琢磨一下,我以前用这个插件调试过kube-proxy的pod,能成功。
问题十二:应用处于同一个边缘网络里,却无法互相访问
首先edgemesh目前只支持通过service的clusterIP互访,暂不支持podIP互访;其次这个问题得分edgemesh版本讨论。
- 对于edgemesh <= v1.11的版本
需要部署edgemesh-server和edgemesh-agent。edgemesh-server一般部署在数据中心(具有公网IP,服务器资性能较好),用来协助其他edgemesh-agent在建立连接的时候交换公网信息与协助打洞;后续在打洞失败的时候也会作为中继节点来转发流量。想了解这些信息,可以搜关键字:内网穿透、UDP打洞、STUN/TURN和Libp2p。
edgemesh-agent在启动的时候,会尝试和edgemesh-server建立连接,如果多次尝试后仍无法建立连接,那么edgemesh-agent就会挂掉/重启并重新执行上述过程。此外,edgemesh-agent还会通过调用edgecore的边缘Kube API Endpoint功能去将自己的peer ID信息,写入到一个名为edgemeshaddrsecret的configmap里面(kubeedge命名空间下),重点就在于edgecore的边缘Kube API Endpoint功能需要edgecore和cloudcore是连通的,才能执行资源的Update、Add和Delete。
总结就是:如果edgemesh-agent连接不上edgemesh-server,或者edgecore与cloudcore断连,那么edgemesh-agent无法正常工作,所以应用就无法互访。
2.对于edgemesh>=1.12版本
在架构上不再需要部署edgemesh-server了,内网穿透和中继的能力移植到了edgemesh-agent里面。如果某个节点或者某些节点具有公网IP,你可以让部署在这些节点上的edgemesh-agent成为中继。
edgemesh-agent在启动的时候,会多次尝试连接那些被配置成中继节点的relayNodes(我们也称之为bootstrap节点)。对比小于1.12版本的差异是,现在即使连接不上bootstrap节点,edgemesh-agent也不会挂掉,紧接着它会通过多播(组播)的方式发送mDNS协议的数据包,在同一个VLAN网络里发现其他edgemesh-agent并记录peer ID。
这边需要满足几个条件:
a. mDNS协议本身是基于UDP协议的,你需要确保你的网络放通了UDP数据包的传输
b. 由于mDNS是多播(组播)协议,因此要求你的节点在同一个网段里面;节点也必须也得在同一个VLAN里面,不同VLAN之间是隔离广播域的
c. edgemesh-agent的tunnel模块监听在20006,确保安全组/防火墙对20006端口放开
d. 所有节点应该具备内网IP(10.0.0.0/8、172.16.0.0/12、192.168.0.0/16),否则mDNS的数据包会被丢弃,导致不能互相发现
满足上述的条件后,edgemesh就能协助同一个边缘网络里应用的互访了;如果不满足上述条件,你就必须配置relayNodes来走中继的方式去通信。relayNodes设置方式详细材料请阅读:KubeEdge EdgeMesh 高可用架构详解 。
问题十三:访问服务时出现 Connection reset by peer
先复习一下定位模型,再确定发起访问节点上的 edgemesh-agent 容器是否存在、是否处于正常运行中。
使用 kubectl logs 或者 docker logs 查看发起访问节点上的edgemesh-agent容器的日志,看看报什么错。遇到的错误一般都记录在此文档里,找找一定有。
问题十四:进行服务访问的时候,edgemesh-agent没任何日志
先复习一下定位模型,再确定发起访问节点上的 edgemesh-agent(左)容器是否存在、是否处于正常运行中。
如果正常,那一般由问题三导致。
问题十五:ping不通服务的ClusterIP
服务的clusterIP就是不能ping的!
你先自学一下 ping 这个东西是干什么的,ping一般可以测试主机间的连通性和往返时延,它的原理是往目的主机发送一个ICMP报文,目的主机接收并处理此ICMP报文,然后回复响应给发起端。
你自己的服务,比如mysql-service,clusterIP是10.96.0.25,监听在3306,这样一个只服务在 10.96.0.25:3306的mysql服务,凭什么能处理ICMP报文?
问题十六:failed to find any peer in table; failed to connect to an endpoint
此答复适用于EdgeMesh>v1.12。先复习一下定位模型,确定被访问节点上的edgemesh-agent(右)容器是否存在、是否处于正常运行中。
这个情况是非常经常出现的,因为master节点一般都有污点,会驱逐其他pod,进而导致edgemesh-agent部署不上去。这种情况可以通过去除节点污点,使edgemesh-agent部署上去解决。
如果访问节点和被访问节点的edgemesh-agent都正常启动了,但是还报这个错误,可能是因为访问节点和被访问节点没有互相发现导致,请这样排查:
- 首先每个节点上的edgemesh-agent都具有peer ID,比如
我有两个节点:k8s-master和ke-edge2
k8s-master节点上的edgemesh-agent的peer ID是:12D3KooWB5qVCMrMNLpBDfMu6o4dy6ci2UqDVsFVomcd2PfYVzfW
ke-edge2 节点上的edgemesh-agent的peer ID是:12D3KooWSD4f5fZb5c9PQ6FPVd8Em4eKX3mRezcyqXSHUyomoy8S注意:
a. peer ID是根据节点名称哈希出来的,相同的节点名称会哈希出相同的peer ID
b. 另外,节点名称不是服务器名称,是k8s node name,请用kubectl get nodes查看2.如果访问节点和被访问节点处于同一个局域网内,请看问题十二。同一个局域网内edgemesh-agent互相发现对方时的日志是 [MDNS] Discovery found peer: <被访问端peer ID: [被访问端IP列表(可能会包含中继节点IP)]>
3.如果访问节点和被访问节点跨子网,这时候你应该看看relayNodes设置的正不正确,为什么中继节点没办法协助两个节点交换peer信息。详细材料请阅读:KubeEdge EdgeMesh 高可用架构详解。跨子网的edgemesh-agent互相发现对方时的日志是 [DHT] Discovery found peer: <被访问端peer ID: [被访问端IP列表(可能会包含中继节点IP)]>

如果还有不明白,可以根据问题十八,画出组网图来分析。
问题十七:Couldn't find an endpoint for service; missing endpoints
这个问题是因为你的服务不存在后端pod实例,可能是后端应用实例没启动。
假如你有一个deployment应用叫mysql,同时还创建了它的service叫mysql-svc:
1.使用kubectl get deploy mysql,看看pod是不是都running起来了
2.使用kubectl get endpoints mysql-svc,看看ENDPOINTS是不是有数据。
如果上述都正常,可能是 KubeEdge issue 3445 导致。根据issue里的指导,临时规避方式如下:
a. 删除service
b. kubectl delete objectsync --all
c. 重启cloudcore、edgecore,重新部署edgemesh
d. 重新创建service问题十八:如何画组网图分析问题
当你读完问题十二或者问题十六后,你还是不清楚为啥失败,这时候可以画一下组网图来分析,以EdgeMesh >= v1.12.0为例。
概念解释
| 关键信息 | 解释 | 示例 |
|---|---|---|
| 节点名 | nodeName;通过kubectl get node获取,注意不是节点的hostname | k8s-node1 |
| 节点IP | 节点的IP地址 | 192.168.1.151(内网IP) 或 113.13.28.141(公网IP) |
| 节点peerid | 通过nodeName哈希出来的加密串,用来标识唯一的节点 | QmYyQSo1c1Ym7orWxLYvCrM2EmxFTANf8wXmmE7DWjhx5N |
备注:怎么查看某节点上运行的edgemesh-agent的peerid呢?在edgemesh-agent运行后会有日志,大概前10行附近有形如:I'm /ip4/198.51.100.0/tcp/20006/p2p/QmYyQSo1c1Ym7orWxLYvCrM2EmxFTANf8wXmmE7DWjhx5N 的日志
组网图示例
1.k8s-master和k8s-node1是云上节点,处于同一个局域网,且k8s-master具有公网IP可以作为中继节点
2.ke-edge1和ke-edge2是边缘节点,分别处于不同的局域网,且能够连上k8s-master的公网IP 121.32.11.34
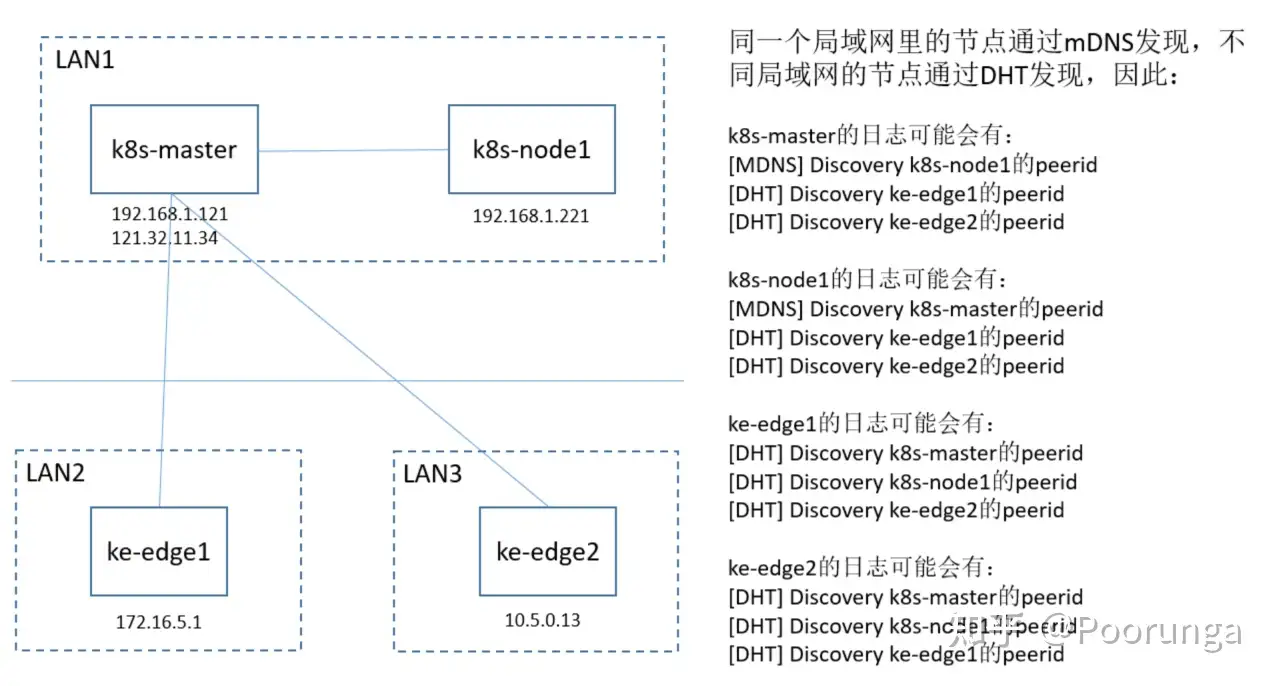
想象一个场景:如果你ke-edge2想要连接k8s-node1,但是却发现failed to find any peer in table的错误日志,你得排查一下:
- k8s-node1是否正常运行了edgemesh-agent
- ke-edge2有没有类似 [DHT] Discovery k8s-node1的peerid 的日志
- k8s-master是中继节点,你的relayNodes配置对了吗


第五个问题,测试都没问题,但是边无法访问云,报错telnet: bad address 'tcp-echo-cloud-svc.cloudzone',主节点执行nslookup kubernetes.default.svc.cluster.local 169.254.96.16 报错 connection timed out; no servers could be reached
不知道怎么定位了


一样的情况,请问问题解决了吗

edgemesh网络代理组件导致,容器间无法访问,时而能,时而又不能,这咋用,目前没法用于商业环境啊

问下这个问题有后续进展吗?云端容器访问边端有时可以,有时不可以

如果有bug或者使用问题,可以在github提issue或在社区例会讨论

小白一枚,edgemesh安装后,云端显示edge-agent pod运行正常,边缘端看不到edgemesh相关镜像启动(按照我目前对kubeedge的认知似乎不应该这样),请问这是正常的吗?

请问EdgeMesh能用于手机端之间的p2p通信吗?
KubeEdge issue 3445 导致, 这个问题有点繁琐,解决起来,能否下个版本可以解决掉bug
kubeedge的新版本应该是修复了,KubeEdge issue 3445里面也有一个PR修复

问题五怎么解决啊, pod里面没有EdgeMesh 的DNS解析