用两种解法解面试题:出现频率最高的 100 个词
用两种解法解面试题:出现频率最高的 100 个词题目描述
假如有一个 1G 大小的文件,文件里每一行是一个词,每个词的大小不超过 16 bytes,要求返回出现频率最高的 100 个词。内存限制是 10M。
解法1
由于内存限制,所以我们没有办法一次性把大文件里面的所有内容一次性读取到内存中去。
对此我们可以采用分治的策略来实现,把一个大文件分解成多个小文件,保证每个文件的大小小于 10 M,进而直接将单个小文件读取到内存中进行处理。
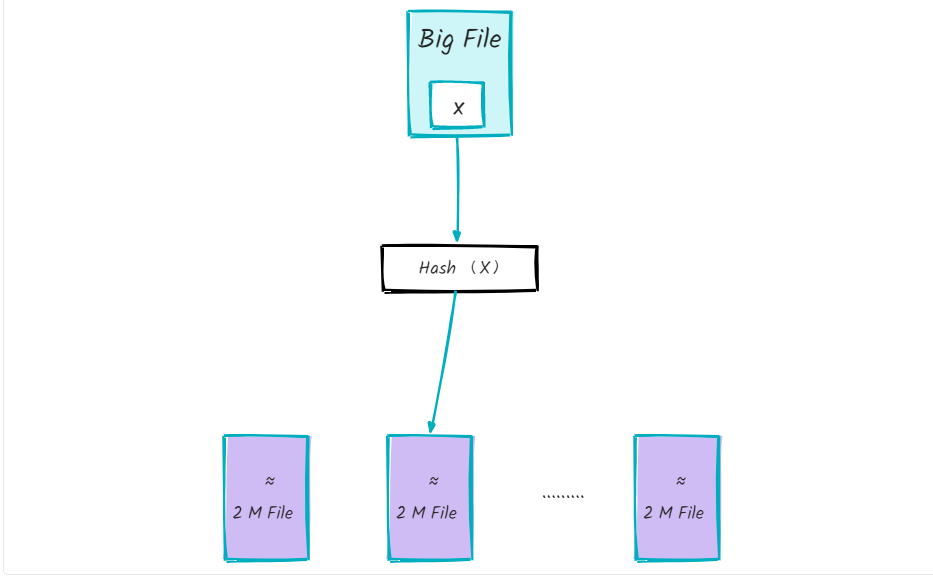
第一步,首先遍历一遍大文件,对遍历到的每个词 x ,执行 hash(x)% 500,将结果为 i 的词存放到文件 f(i)中,遍历结束之后,可以得到 500 个小文件,每个小文件的大小为 2 M 左右;
第二步,接着统计每个小文件中出现频率最高的 100 个词。可以用 HashMap 来实现,其中 key 为词,value 为该次出现的频率。(示意代码)
BufferedReader br = new BufferedReader(new FileReader(fin)); String line = null; while ((line = br.readLine()) != null) {if(map.containsKey(line)){map.put(line,map.get(x) + 1)}else{map.put(line,1);} }br.close();
对于遍历到的词 x,如果在 map 中不存在,则执行 map.put(x,1)。
若存在,则执行 map.put(x,map.get(x) + 1),将该词出现的次数 + 1。
第三步,在第二步中找出了每个文件出现频率最高的 100 个词之后,通过维护一个小顶堆来找出所有小文件中出现频率最高的 100 个词。
具体方法是,遍历第一个文件,把第一个文件中出现频率最高的 100 个词构建成一个小顶堆。
如果第一个文件中词的个数小于 100,可以继续遍历第二个文件,直到构建好有 100 个结点的小顶堆为止。
继续遍历其他小文件,如果遍历到的词的出现次数大于堆顶词的出现次数,可以用新遍历道的词替换堆顶的词,然后重新调整这个堆位小顶堆。
当遍历完所有小文件后,这个小顶堆中的词就是出现频率最高的 100 个词。
总结
总结一下,这个解法的主要思路如下:采用分治的思想,进行哈希取余使用 HashMap 统计每个小文件单词出现的次数使用小顶堆,遍历步骤 2 中的小文件,找到词频 top 100 的单词。
很容易就会发现一个问题,如果第二步中,如果这个 1 G 的大文件中有某个词的频率太高,可能导致小文件大小超过 10 M,这种情况该怎么处理呢?
在此疑问上,我们提出了第二种解法。
解法2
第一步:使用多路归并排序堆大文件进行排序,这样的话,相同的单词一定是紧挨着的。
多路归并排序对大文件排序的步骤如下:将文件按照顺序切分成大小不超过 2 M 的小文件,总共 500 个小文件使用 10 MB 内存分别对 500 个小文件中的单词进行排序使用一个大小为 500 的堆,对 500 个小文件进行多路排序,然后将结果写到一个大文件中。
其中第三步,对 500 个小文件进行多路排序的思路如下:初始化一个最小堆,大小就是有序小文件的个数 500。堆中的每个节点存放每个有序小文件对应的输入流。按照每个有序文件中的下一行数据对所有文件输入流进行排序,单词小的输入文件流放在堆顶。拿出堆顶的输入流,并且将下一行数据写入到最终排序的文件中,如果拿出来的输入流还有数据的话,那么就将这个输入流再次添加到栈中。否则说明该文件输入流中没有数据了,那么可以关闭这个流。循环这个过程,直到所有文件输入流中没有数据为止。
第二步:初始化一个 100 个节点的小顶堆,用于保存 100 个出现频率最高的单词。遍历整个文件,一个单词一个单词地从文件中读取出来,并且进行计数。等到遍历的单词和上一个单词不同的话,那么上一个单词及其频率如果大于堆顶的词的频率,那么放在堆中。否则不放。
最终,小顶堆就是出现频率前 100 的单词了。
小结
解法 2 相对于解法 1,其更加严谨,如果某个词词频过高或者整个文件都是同一个单词的话,解法 1 不适用。