1. 应用程序(Application)
通过下面的代码设置应用程序名称,设置后再UI中可以看到相应的名称。
//1.设置Application的名称
val conf = new SparkConf()
conf.setAppName("WordCount")
conf.setMaster("local")
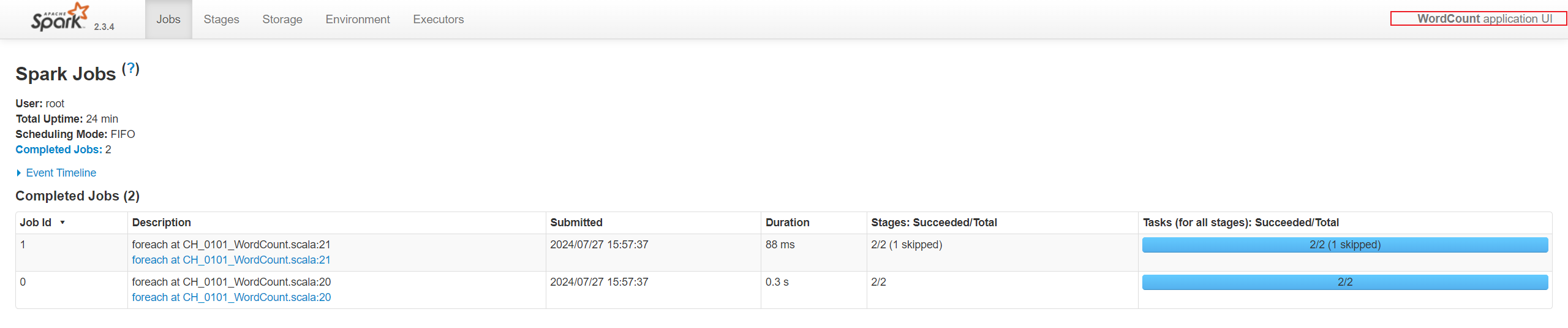
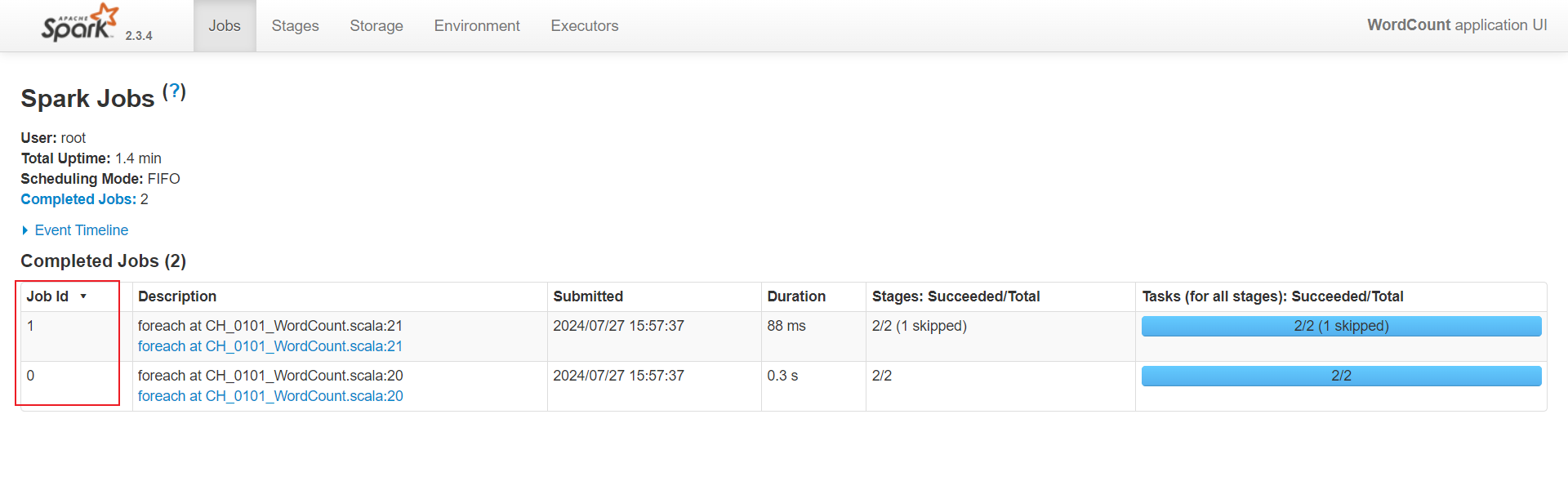
2. Job
Job由scala的执行算子生成,每个执行的算子会调起runjob,从而生成一个job。
res.foreach(println)
value.foreach(println)
3. Stage
Stage表是任务执行的阶段,以聚合类算子为分界点划分stage,聚合类的算子需要经过shuffle的过程,也就是需要从其他的结点拉取数据,因此shuffle前的stage是的操作是可以在同一个节点完成。
val res = dataSets.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)val value = res.map(x => {(x._2, 1)}).reduceByKey((ordVal: Int, newVal: Int) => {ordVal + newVal
})
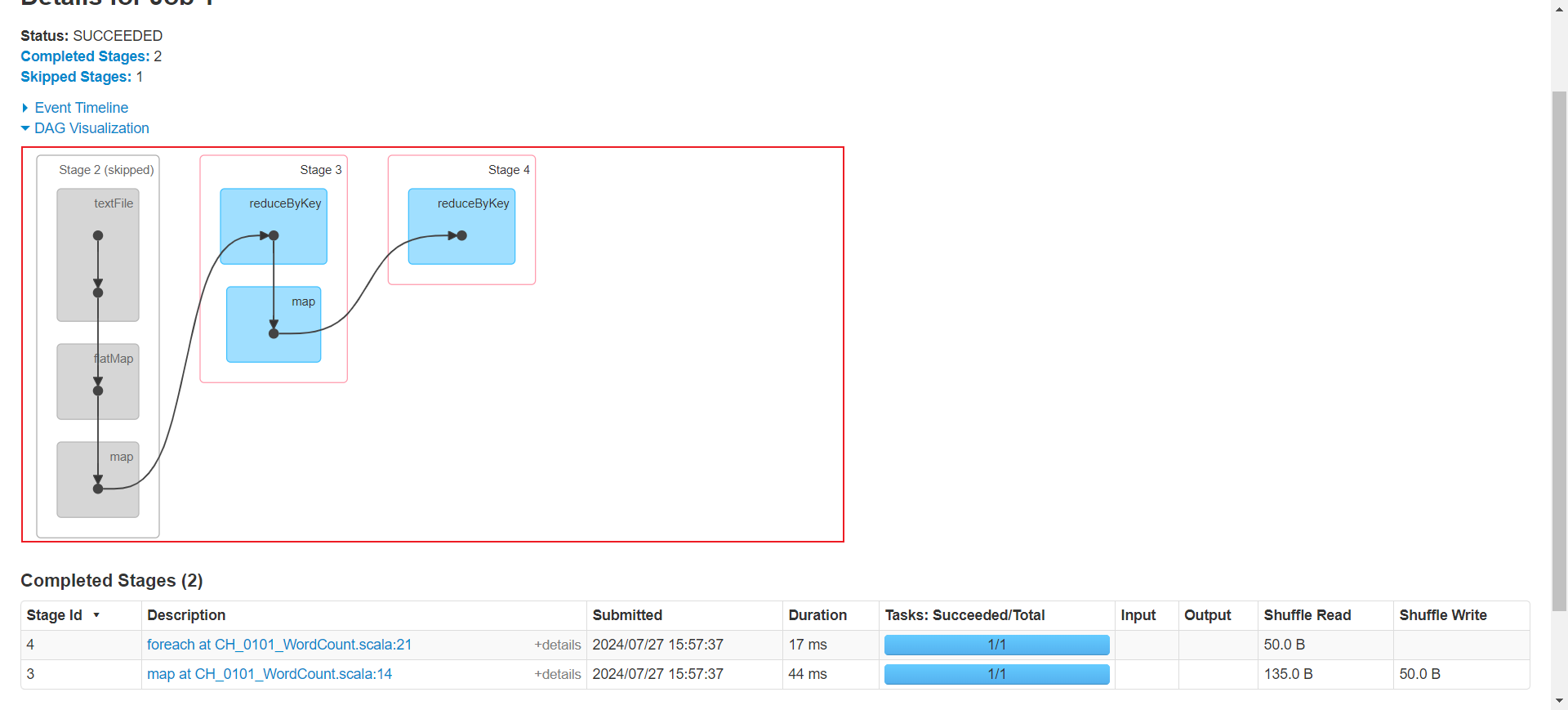
4.各自的关系
一个Application可以生成多个Job,每个Job由执行算子生成。一个Job以shuffle类算子为分界点,将job划分成不同的阶段(Stage)。每个stage有多个task执行。



![电影《抓娃娃》迅雷/百度云下载[超清版BT种子][MP4/2.89GB]分享](https://img2024.cnblogs.com/blog/3470799/202407/3470799-20240727152843370-1156660089.jpg)


![[题解]P2672 [NOIP2015 普及组] 推销员](https://img2024.cnblogs.com/blog/3322276/202407/3322276-20240727141059046-1857752070.png)