基于 AnythingLLM 及 Ollama 构建本地知识库
- RAG
- Ollama
- AnythingLLM
1. 什么是 RAG
RAG(Retrieval Augmented Generation)检索增强生成,是 2023 年最火热的 LLM 应用系统架构,它的作用简单来说就是通过检索获取相关的知识并将其融入 Prompt,让大模型能够参考相应的知识从而给出合理回答。
现在的大模型在企业应用中存在着很多挑战,首先第一点就是大模型的世界知识是完全来自于模型预训练中提供的数据,是有限的,那么企业本身的业务知识与产品知识,这些大模型都是不知道的。如果通过微调等方式去给大模型补充这些知识,成本高且可控性低,大部分场景是不适合的。以及大模型有比较严重的幻觉问题,也就是大模型在不熟悉的领域会提供不正确的答案,那在企业应用的场合里很多都是严肃的场景,对于这方面的接受程度是比较低的。
所以出现了 RAG。RAG 给大模型提供了一个外部的知识库,这个知识库可以是文档的集合也可以是网站或者是其他结构化非结构化的知识库,当用户提出问题的时候,通过 Embedding 向量化处理和关键字查询等各种检索方式,把相关内容从知识库中拉出来,并通过优先级重排等操作再提供给 LLM,LLM 就会根据检索出来的知识和用户的问题,做针对性的回答。
这个就好像给大模型一个企业私域知识的字典,大模型可以根据用户的问题一边查字典一边根据字典当中的说明进行回答。
给出一个 RAG 的运作流程图。
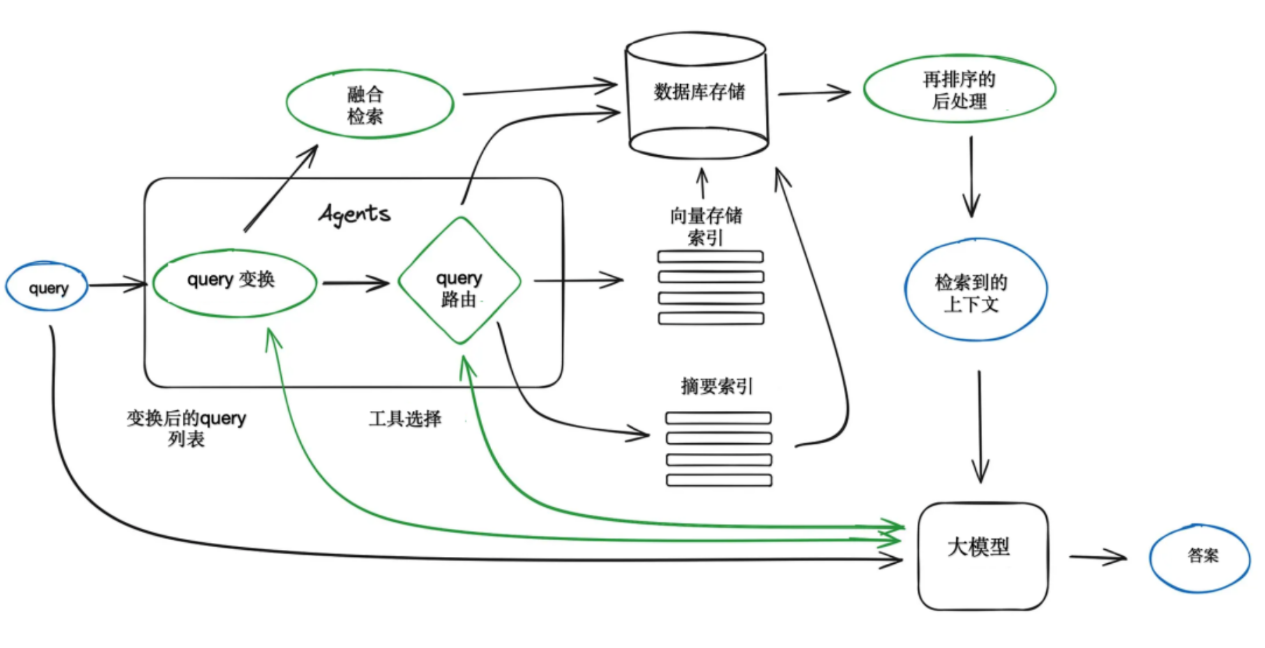
这种方式一方面给大模型提供了补充企业内部知识的一个途径,另外通过这些外部知识的约束,也可以大大降低大模型的幻觉问题,特别适合去做一些企业相关的问答产品,从给内部人员使用 AI 的业务助手,到给一些 C 端用户使用的 AI 客服或 AI 营销产品等。
RAG 现在已经成为了 AI 企业应用当中最容易落地的一种方式,各种方案与产品层出不穷。但是要想把 RAG 真的做好也不是一件易事,比如如何去组织知识、如何提高检索质量等,都会对 RAG 最后呈现的效果起到至关重要的作用。
所以从关于 RAG 的解释上就可以推断出,RAG 与 LLM 相结合其实就可以构建出一个私有的、本地知识库,这也是现在构建知识库的主要手段。
使用 Ollama 和 AnythongLLM 的组合就是很常见的一种构建知识库的手段。
2. 什么是 Ollama

Ollama 是一个免费的开源项目,是一个专为在本地机器上便捷部署和运行 LLM 而设计的开源工具,可在本地运行各种开源 LLM,它让用户无需深入了解复杂的底层技术,就能轻松地加载、运行和交互各种LLM模型。
Ollama 最初是被设计为本地(主要是开发)运行LLM的工具,当然现在也可以在服务器(面向用户并发提供服务)上使用,并且兼容 OpenAI 接口,可以作为 OpenAI 的私有化部署方案。
Ollama 的特点:
- 本地部署:不依赖云端服务,用户可以在自己的设备上运行模型,保护数据隐私。
- 多操作系统支持:无论是 Mac、Linux 还是 Window,都能很方便安装使用。
- 多模型支持:Ollama 支持多种流行的 LLM 模型,如 Llama、Falcon 等,包括最近 Meta 公司新开源的大模型 llama3.1 405B 也已经更新,用户可以根据自己的需求选择不同的模型,一键运行。
- 易于使用:提供了直观的命令行界面,操作简单,上手容易。
- 可扩展性:支持自定义配置,用户可以根据自己的硬件环境和模型需求进行优化。
- 开源:代码完全开放,用户可以自由查看、修改和分发(虽然没有很多人会去修改)
3. 什么是 AnythingLLM
从上面的描述与说明中可以知道,对于企业来说幻觉是阻碍大模型应用的严重缺陷性问题,以及除了幻觉,通用大模型无法满足企业实际业务需求,涉及到知识局限性、信息安全等问题,企业不能将私域数据上传到第三方平台训练。
而 AnythingLLM 就是为解决这个问题而生的框架。它能在本地轻松构建基于 LLM 的 AI 应用,集成 RAG、向量数据库和强大的 Agent 功能,是高效、可定制、开源的企业级文档聊天机器人解决方案,能够将任何文档、网页链接、音视频文件甚至只是一段文字,转化为 LLM 可以理解的上下文信息,并在聊天过程中作为参考。还可以自由选择不同的 LLM 或向量数据库,并进行多用户管理和权限设置。

主要功能:
- 多用户管理和权限控制: 让团队协作更轻松,每个人都能安全地使用 LLM。
- AI Agent 加持: 内置强大的 AI Agent,可以执行网页浏览、代码运行等复杂任务,自动化程度更高。
- 可嵌入聊天窗口: 轻松集成到您的网站或应用中,为用户提供 AI 驱动的对话体验。
- 广泛的文件格式支持: 支持 PDF、TXT、DOCX 等多种文档类型,满足不同场景需求。
- 向量数据库管理: 提供简单易用的界面来管理向量数据库中的文档,方便知识管理。
- 灵活的对话模式: 支持聊天和查询两种对话模式,满足不同场景需求。
- 信息来源追踪: 聊天过程中会提供引用的文档内容,方便追溯信息来源,增强结果可信度。
- 多种部署方式: 支持 100% 云部署,也支持本地部署,满足不同用户的需求。
- 自定义 LLM 模型: 可以使用您自己的 LLM 模型,定制化程度更高,满足个性化需求。
- 高效处理大型文档: 相较于其他文档聊天机器人解决方案,AnythingLLM 在处理大型文档时效率更高,成本更低,最多可节省 90% 的成本。
- 开发者友好: 提供全套开发者 API,方便自定义集成,扩展性更强。
4. 基于 AnythingLLM 及 Ollama 构建本地知识库
介绍完 Ollama 与 AnythingLLM,接下来就可以利用这两个东西来建立本地知识库了。
4.1. 安装 Ollama
- 下载Ollama:https://ollama.com/download
- 安装,启动命令行窗口输入命令加载模型。命令可以通过点击官网 Models 后,搜索并选择所需要的模型后查看。

- 选择模型后,拷贝对应的命令。
Ollama 也支持加载运行 GGUF 格式的大模型,这个自行查看官网。
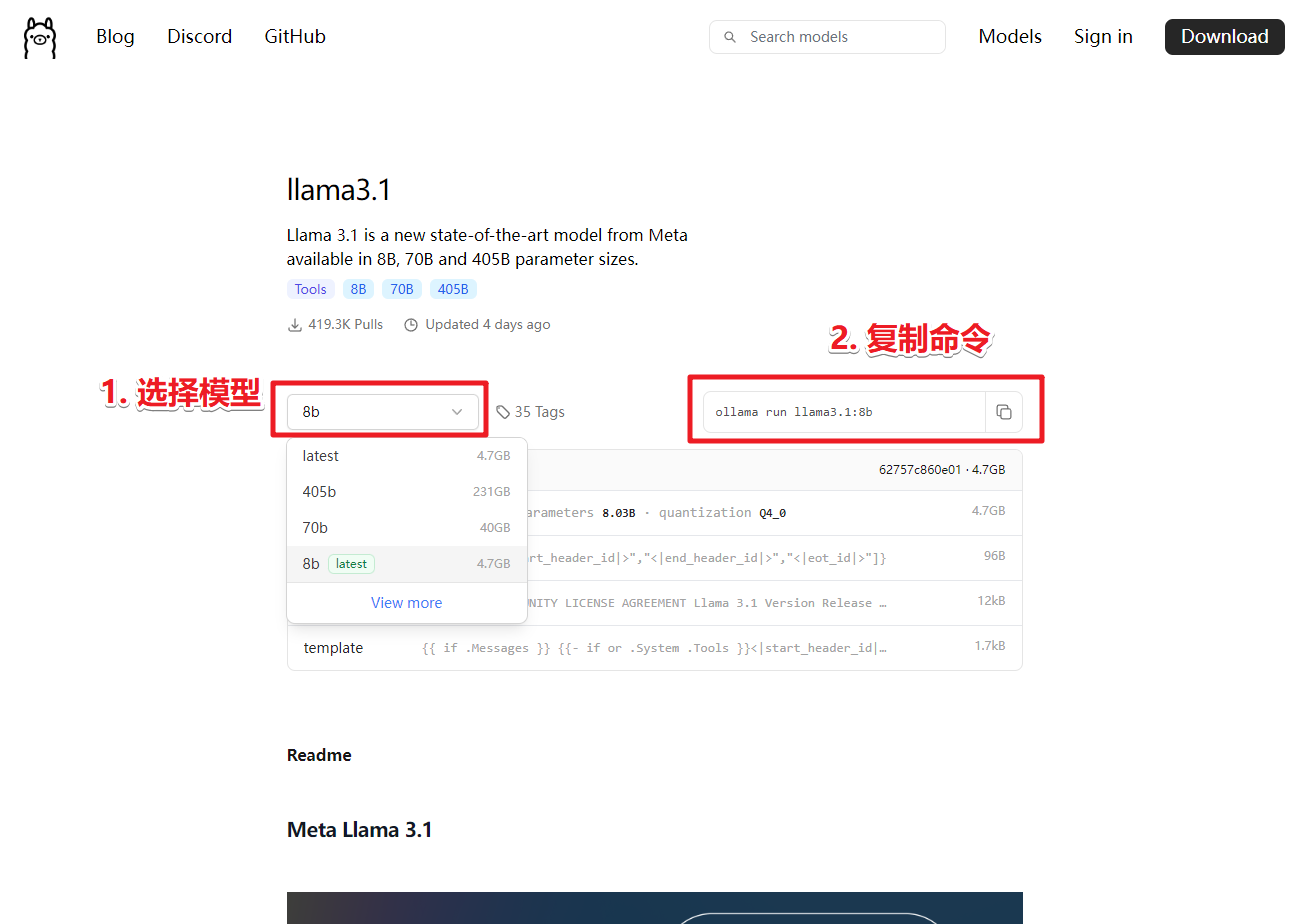
- 启动命令行窗口,拷贝命令并运行,若是第一次运行,Ollama 会自动下载模型并启动模型。如本机上已安装了的模型。
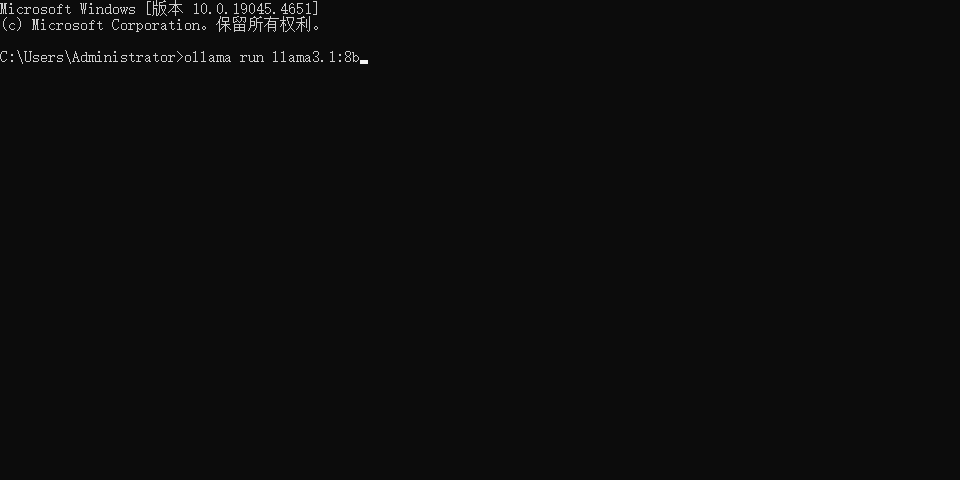
- 至此,Ollama安装完毕。
4.2. 安装 Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的操作系统的机器上,从而实现虚拟化。
在 Windows 下一般直接安装 Docker Desktop,这需要 Windows 开启 Hyper-V 虚拟化功能。
Docker Desktop 的下载地址是:https://www.docker.com/products/docker-desktop
下载后直接双击安装即可,Docker的安装过程非常简单,没有什么参数需要设置,一路next即可,不多做赘述。
4.3. 安装 AnythingLLM
AnythingLLM 有多种安装方式,首先是可以在 Docker 上安装。通过搜索 AnythingLLM 镜像并 pull 后 run 运行,但是需要使用一些科学的手段才能搜索并使用安装。
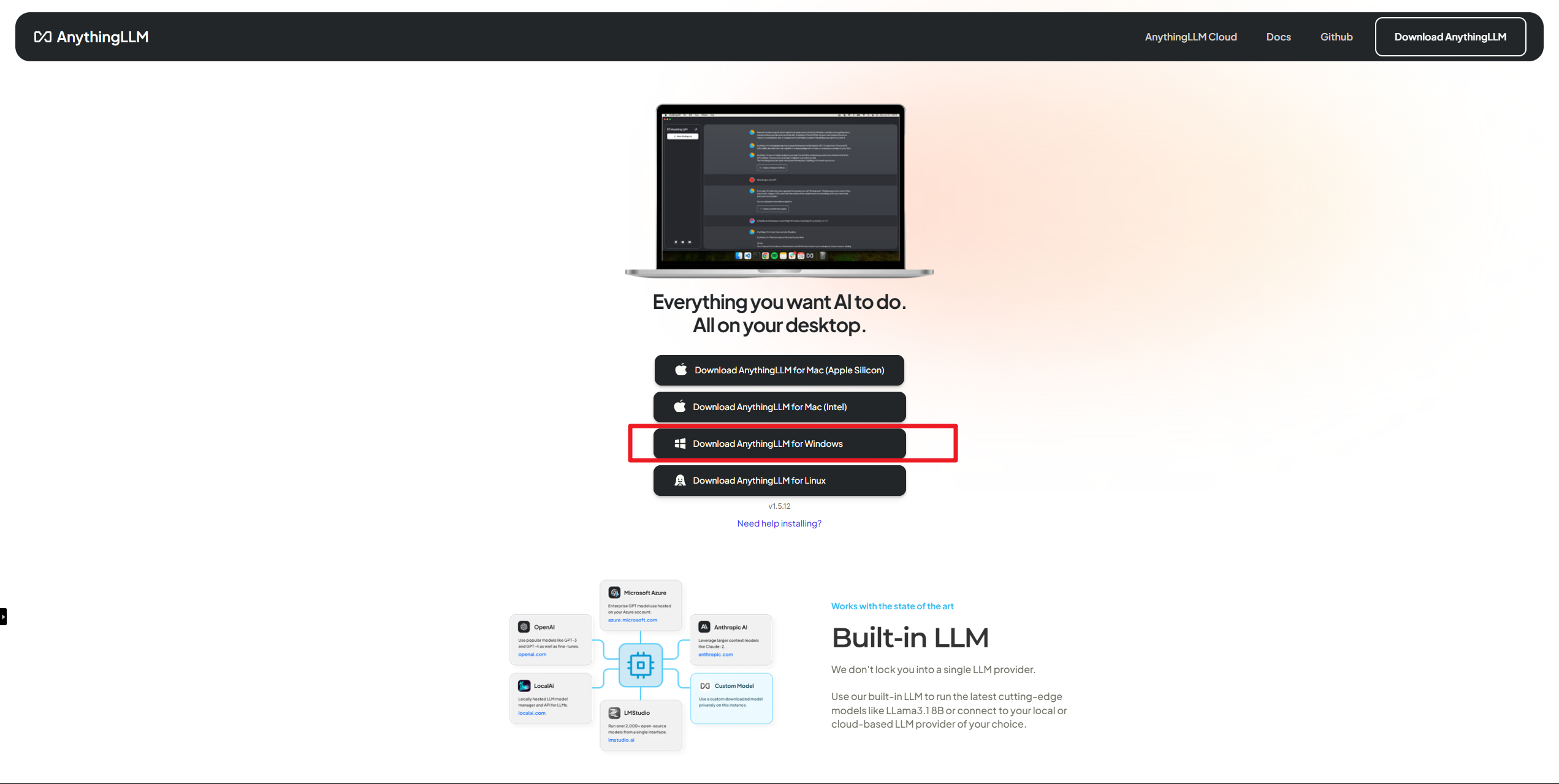
第二种方式是直接下载地址:https://useanything.com/download 进行安装。
4.4. 配置 AnythingLLM,搭建本地知识库
安装完成之后,点击按钮 Get started 进入设置向导界面。
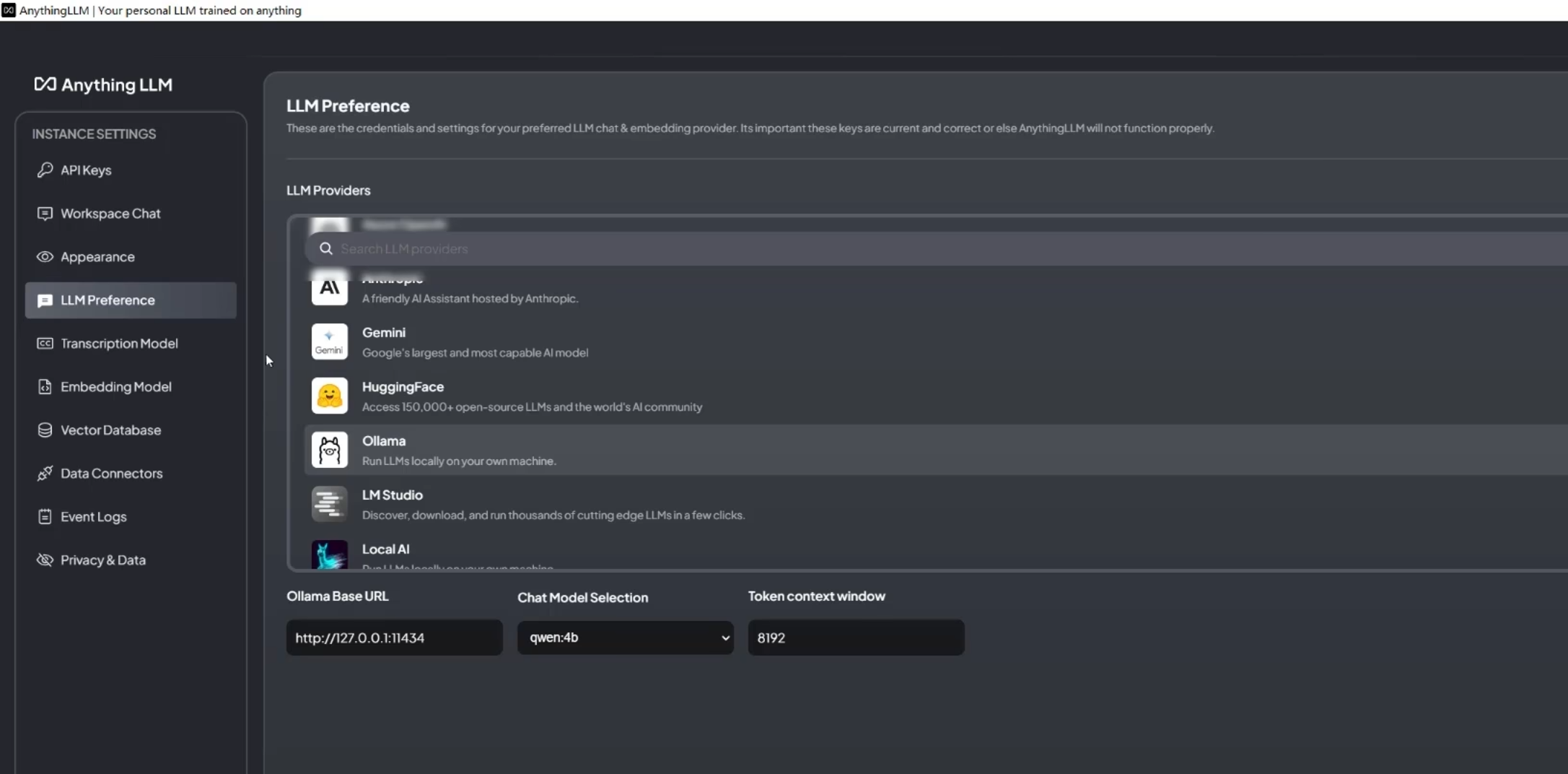
选择大模型,在这里我们选择刚刚安装好的 Ollama,然后设置参数:
- 指定 Ollama Base URL 为 http://host.docker.internal:11434
- 指定 Chat Model Selection 为 llama3.1:8b
- 指定 Token context window 为 4096 (这里的 token 数量视情况而定,一般来说越大会越准确但解析等待时间越长)
当然 AnythingLLM 也支持使用闭源模型的API。
-
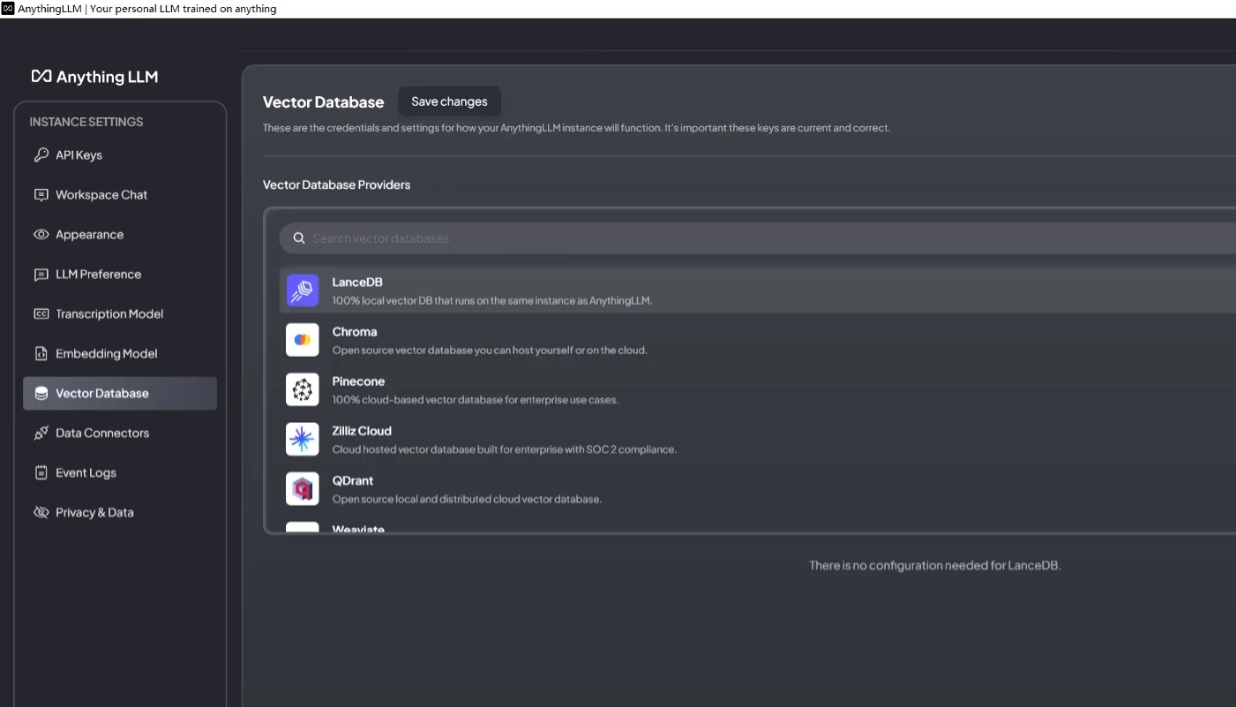
Embedding Preference(嵌入模型)的选择,选择默认的 AnythingLLM Embedder 就好。
-
向量数据库 Vector Database Connection,选择默认的 LanceDB
-
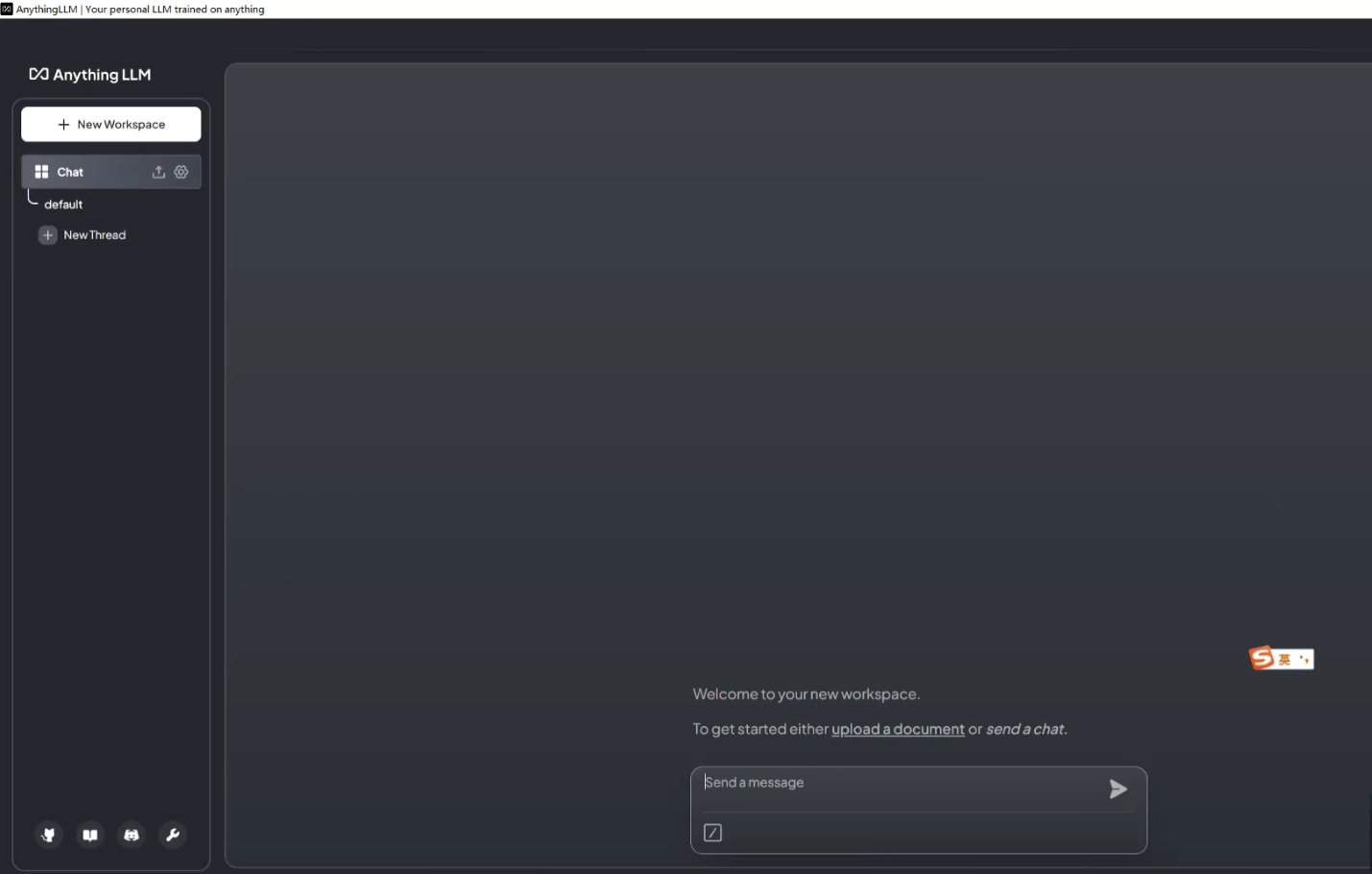
确认相关信息之后,制定工作空间名称,下一步,就会得到如下界面
-
这个时候就可以上传文档,并将文档移入工作区,作为本地知识库
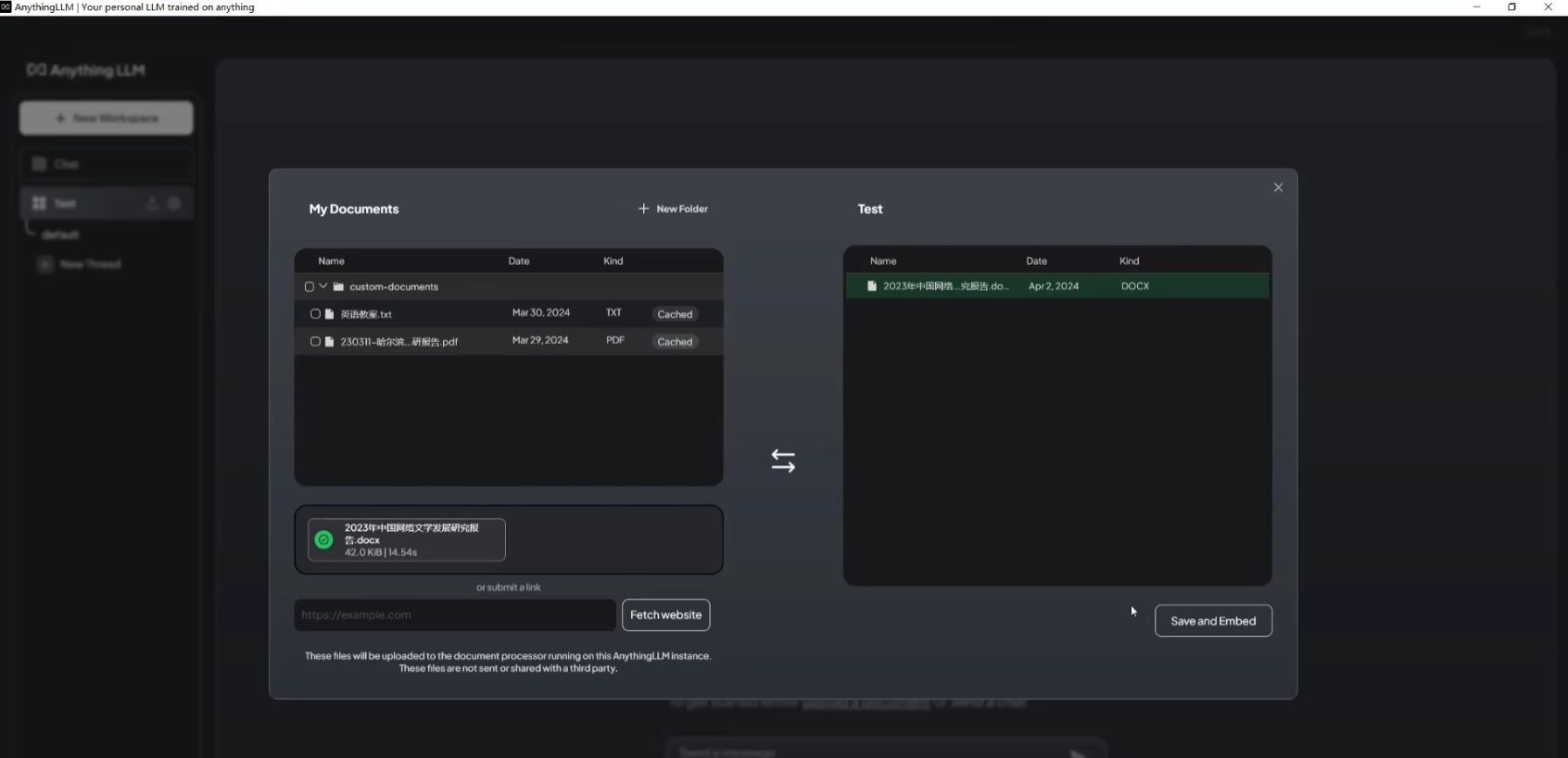
-
这个时候就可以进行问答测试了,如下图。第一次未上传本地文件提问时,LLM 并没有给出答案,在上传了本地文件作为知识库后,再次提出相同问题,LLM 根据知识库内容给出了相应的回答。
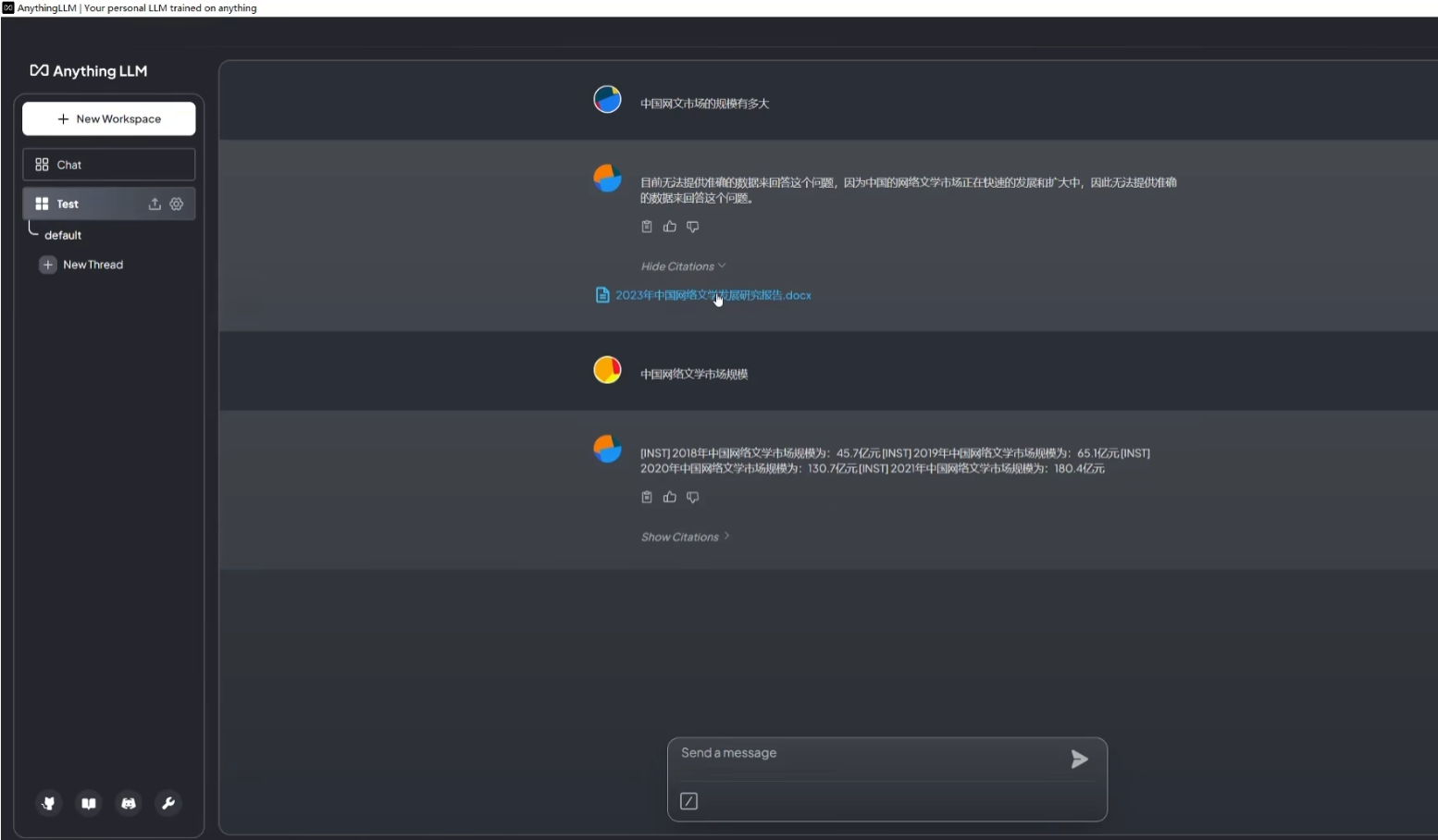
4.5. 知识库管理
当然这些是最简单的本地知识库搭建,除此之外 AnythingLLM 还提供了灵活的配置供给管理,可以设置例如语料分割参数、修改 Chat mode、修改 Embedding chunk 的大小(用于设置向量模型处理资料的颗粒度)等等。
另外值得说明一下的是,一般来说,参数更大的模型处理能力以及回答的内容效果会更好,举个例子,在之前用 Ollama 下载的 llama3.1:8b 模型与 llama3.1:70b 模型相比,肯定是 llama3.1:70b 的效果更好。
扩展:在大模型中,b 指的是 10 亿的参数量,8b就是 80 亿的参数,70b 就是 700 亿的参数。
当前最新开源的 Meta 的 llama3.1:405b 就意味着有 4050 亿的参数量,是当前最大最强的开源大模型(在基准测试中 llama3.1 在大多数方面都强过了 GPT4O)
当然参数越多所需要的算力就越大,需要的性能也就越高,在本地部署就需要根据自身的设备条件进行适合的选择。
参考资料:
- 一文读懂:大模型RAG(检索增强生成):https://zhuanlan.zhihu.com/p/675509396
- 基于 AnythingLLM 及 Ollama 构建本地知识库:https://www.bilibili.com/read/cv34813632/
- 一文了解:打造垂域的大模型应用:https://www.zhihu.com/tardis/bd/art/640493296?source_id=1001
- qdrant对常用的向量数据库的测试报告:https://qdrant.tech/benchmarks/
- Ollama 本地运行大模型(LLM)完全指南:https://mp.weixin.qq.com/s/rKfxEWSppYGtGT3teXujBw