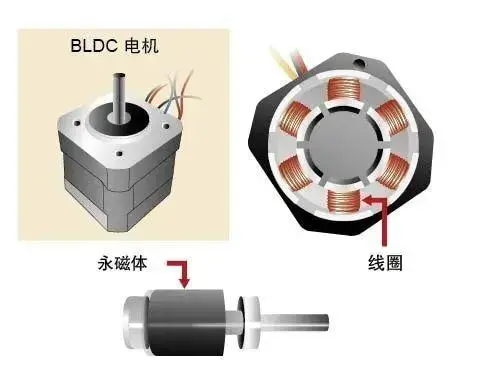
通过模型划分进行分布式训练
https://siboehm.com/articles/22/pipeline-parallel-training
流水线并行性使得训练不适合单个GPU内存的大型模型成为可能。示例:Hugginface的BLOOM模型是一个175B参数的Transformer模型。将权重存储为bfloat16需要350GB,但他们用来训练BLOOM的GPU“只有”80GB的内存,训练需要的内存比加载模型权重多得多。因此,他们的最终训练分布在384个GPU上。这可以通过将模型的不同层分配给不同的GPU来实现,这一过程称为模型分区。模型分区的实现过于天真,导致GPU使用率低。将首先讨论管道并行性的简单实现及其一些问题。然后,将讨论GPipe和PipeDream,这两种最新的算法可以缓解管道并行性方面的一些问题。
这是关于大规模深度学习模型分布式训练系列的第二部分。第一部分涵盖了数据并行训练。
朴素模型并行性
朴素模型并行是实现流水线并行训练最直接的方法。将模型拆分为多个部分,并将每个部分分配给GPU。然后,对小批量进行定期训练,在分割模型的边界处插入通信步骤。
以这个4层顺序模型为例:
output=L4(L3(L2(L1(input))))
将计算分配给两个GPU,如下所示:
- GPU1计算: 中间表示=L2(L1(输入))
- GPU2计算: 输出=L4(L3(中间表示))
为了完成正向传递,在GPU1上计算迭代,并将得到的张量传递给GPU2。GPU2然后计算模型的输出并开始反向传递。对于反向传递,将梯度从GPU2发送到GPU1。然后,GPU1根据其发送的梯度完成反向传递。这样,模型并行训练产生的输出和梯度与单节点训练相同。因为发送不会修改任何比特,所以与数据并行训练不同,朴素模型并行训练的比特等于顺序训练。这使得调试变得容易得多。
下面说明了朴素模型的并行性。GPU1执行前向传递并缓存激活(红色)。然后,它使用MPI将L2的输出发送到下一个GPU GPU2。GPU2完成前向传递,使用目标值计算损耗,并开始后向传递。GPU2完成后,梯度w.r.t.L2的输出被发送到GPU1,GPU1完成后向传递过程。只使用节点到节点通信(MPI.Send和MPI.Recv),不需要任何集体通信原语(因此没有MPI.AllReduce,就像数据并行一样)。

通过观察图,可以观察到朴素模型并行性的一些低效之处。
GPU使用率低:在任何给定时间,只有一个GPU繁忙,而另一个GPU空闲。如果增加更多的GPU,每个GPU只会很忙

时间(忽略通信开销)。低使用率表明,可以通过将有用的工作分配给当前空闲的GPU来加速训练。
没有通信和计算的交织:当通过网络发送中间输出(FWD)和梯度(BWD)时,没有GPU在做任何事情。当讨论数据并行性时,已经看到了交织计算和通信如何带来巨大的好处。
高内存需求:GPU1保存整个小批量缓存的所有活动,直到最后。如果批处理大小较大,则可能会产生内存问题。将讨论如何结合数据和流水线并行来解决这个问题,但还有其他方法可以减少内存需求。
现在来看看如何减轻朴素模型并行性的低效。首先是GPipe算法,与朴素模型并行算法相比,它的GPU使用率要高得多。
GPipe算法:将小批分割成微批次
GPipe通过将每个小批量拆分为更小、大小相等的小批量来提高效率。然后,可以独立计算每个微批的正向和反向通过。只要没有批量规范。通过计算微批上的归一化统计数据,可以使用批规范和GPipe,这通常有效,但不再等同于顺序训练。如果把每个微批的梯度加起来,就能得到整个批的梯度。因为,就像数据并行训练一样,求和的梯度是每个项的梯度之和。这个过程称为梯度积累。由于每一层只存在于一个GPU上,因此可以在本地执行微批梯度的求和,而无需任何通信。
考虑一个在4个GPU上划分的模型。对于简单的管道并行性,生成的计划如下:
|
时间戳 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
GPU3 |
|
|
|
FWD |
BWD |
|
|
|
|
GPU2 |
|
|
FWD |
|
|
BWD |
|
|
|
GPU1 |
|
FWD |
|
|
|
|
BWD |
|
|
GPU0 |
FWD |
|
|
|
|
|
|
BWD |
如前所述,在任何给定时间点,只有一个GPU繁忙。此外,这些时间步中的每一个都需要相当长的时间,因为GPU必须为整个小批量运行前向传递。
使用GPipe,现在将小批量拆分为小批量,比如4个。
|
时间戳 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
GPU3 |
|
|
|
F1 |
F2 |
F3 |
F4 |
B4 |
B3 |
B2 |
B1 |
|
|
|
|
GPU2 |
|
|
F1 |
F2 |
F3 |
F4 |
|
|
B4 |
B3 |
B2 |
B1 |
|
|
|
GPU1 |
|
F1 |
F2 |
F3 |
F4 |
|
|
|
|
B4 |
B3 |
B2 |
B1 |
|
|
GPU0 |
F1 |
F2 |
F3 |
F4 |
|
|
|
|
|
|
B4 |
B3 |
B2 |
B1 |
这里F1表示使用当前GPU上存储的层分区执行微批1的前向传递。重要的是,GPipe调度中的每个时间步,都将短于朴素模型并行调度中的每一个时间步,因为使用GPipe,GPU一次只能处理四分之一的小批量。然而,将小批量拆分为更小的小批量会增加开销,部分原因是需要总共启动更多的内核。如果层很小,微批处理很小,GPU内的并行性,可能没有足够的机会导致CUDA内核的高使用率。
总的来说,GPipe及其微批处理,比简单的流水线并行性,有了很大的改进,因为现在不止一个GPU同时在做有用的工作。来看看GPipe仍然存在的一些低效问题,以及如何解决这些问题:通信和计算的交织、管道泡沫和内存需求。
GPipe:计算与通信的交织
不幸的是,如果每个GPU的前向和后向传递需要相同的时间,则没有太多机会交织通信和计算。这可以在上表中看到,因为在前一个GPU完成处理同一个微批之前,每个GPU都无法开始处理给定的微批。如果所有阶段花费相同的时间,那么仍然会得到不同的通信和计算时间。
最初介绍GPipe的论文没有涵盖这一点,但一种选择是将每个小批量分成两半。然后,可以将前半部分的通信与后半部分的计算交织在一起。在实践中是否有意义,将取决于内核和网络时序。
以下是GPipe交错版本的草图:

箭头显示了第一个微批前半部分的依赖关系。
让继续讨论GPipe的主要低效之处,即管道气泡的大小。
GPipe:管道气泡
气泡是管道中没有做任何有用工作的地方。它们是由操作之间的依赖关系引起的。例如,在GPU3执行F1并发送结果之前,GPU4无法执行F1。

浪费在气泡上的时间分数,取决于管道深度n和微批数量m:

因此,为了使气泡分数变小,有必要增加小批量的尺寸,从而增加微批量的数量m。由单个微批和4个微批组成的批次一些示例计算:大的微批大小需要仔细的学习率缩放。参见LARS和LAMB等学习率调度器。并且将增加缓存活动的内存需求,将在下一步讨论。
GPipe:内存需求
增加批处理大小会线性增加缓存激活的内存需求。有关NN训练的内存需求的更详细分析,参阅关于数据并行性的文章的附录。在GPipe中,需要缓存每个微批从转发到相应的反向的活动。以GPU0为例,从时间步0到时间步13,微批1的激活都保存在内存中。

以降低内存需求。在梯度检查点中,不是缓存计算梯度所需的所有激活,而是在向后传递过程中,动态重新计算激活。这降低了内存需求,但增加了计算成本。
让假设所有层的大小大致相同。缓存活动的内存需求为

对于每个GPU。为了解释这个公式:对于每一层,需要缓存它的输入。假设层宽度为常数,则单个缓存输入的大小为

。相反,可以执行梯度检查点,只缓存层边界上的输入(即缓存从上一个GPU发送给张量)。这将每个GPU的峰值内存需求降低到

为什么?

是缓存边界激活所需的空间。当对给定的微批执行反向传递时,需要重新实现计算该微批梯度所需的激活。这需要每个GPU上的

层的

空间。
下图显示了具有梯度检查点的GPipe的内存需求。它显示了反向过程中的两个GPU。GPU3重新计算了微批3的激活,而GPU4重新计算了小批2的激活。在GPU边界,整个批处理的激活从正向缓存到反向缓存。

接下来,将介绍PipeDream,这是一种用于流水线并行训练的不同算法。PipeDream为提供了另一种减少微批训练内存需求的选择,这与梯度检查点正交。
PipeDream算法:交错不同微批的前进和后退过程
一旦最后一个流水线阶段完成了相应的前向传递,PipeDream就会开始对微批进行后向传递。可以在执行相应的后向传递后立即丢弃第m个微批的缓存激活。使用PipeDream,这种后向传递比GPipe更早发生,从而减少了内存需求。
下面是PipeDream调度的图表,有4个GPU和8个微批。图取自威震天LM论文。严格来说,这个调度叫做PipeDream Flush 1F1B,稍后会解释。蓝色框是正向传球,用它们的微批id编号,而反向传球是绿色的。

考虑一下内存需求。对于GPipe和PipeDream,缓存激活的内存需求可以形式化为(不带梯度检查点)。

根据上述PipeDream调度,在飞行中最多有相同数量的微批次。如果为微批次执行了>1次前向传球,但尚未完成所有后向传播,则微批次正在飞行中。因为管道很深。
与GPipe相比,在GPipe中,所有微批处理都在调度的某个时间点运行,导致缓存激活的内存需求更高。使用上面的例子,使用PipeDream,最多有4个微批次在飞行,而使用GPipe,则有8个微批次。由于在这个例子中每批有8个小批次,GPipe将在开始第一个BWD过程之前,首先计算所有微批次的FWD过程。参阅上面的GPipe表作为参考,但该表假设每批有4个小批次。将缓存激活的内存需求加倍。
就气泡分数而言,PipeDream和GPipe之间没有区别。气泡是之前对微批处理的操作之间固有依赖性的结果,PipeDream不会改变这一点。从视觉上看,看看上面的PipeDream图,如果向左移动蓝色前进传球,向右移动绿色后退传球,会得到GPipe。这就解释了为什么气泡分数是相同的。
PipeDream调度有很多变化,不能说已经摸索过了。上述调度称为1F1B,因为在稳定状态下,每个节点都在执行正向和反向传递之间交替。上述调度仍然是顺序一致的。
在最初的PipeDream论文以及威震天LM论文中,还有更多的变体。通过避免管道冲洗,冲洗管道意味着在所有当前计划的操作完成之前,不安排任何新的操作。一旦管道被冲洗,就知道梯度(在微批次上累积)是顺序一致的。然后执行优化器步骤。在每批加工结束时,可以通过降低气泡分数来提高效率。然而,这意味着该算法不再具有顺序一致性,这可能会损害收敛速度。较慢的收敛将迫使进行更长时间的训练,因此非顺序一致的PipeDream调度可能实际上对减少训练时间和成本没有帮助。不确定PipeDream的非顺序一致版本的使用范围有多广。
简要看看实现流水线并行所需的网络通信量。GPipe和PipeDream的分析结果相同。
管道并行性:通信量
为简单起见,让假设一个只有密集层的模型,所有层的维度都是相等的N。在正向传递过程中,每个GPU将发送和接收大小为

的数据。反向传递也是如此,使总通信量达到

浮点数。-1项来自初始GPU不必接收,最后一个GPU不必发送任何东西。
将其与数据并行性进行比较,在数据并行性中,每个GPU都必须对其所有层的梯度进行AllReduce。在密集模型示例中,使用Ring-AllReduce,每个GPU需要大致传输

。根据模型的配置和训练设置,数据并行可能需要更多的通信。可以很好地交织数据并行通信,而流水线并行是不可能的。
到目前为止,已经研究了实现流水线并行的三种方法:朴素模型并行、GPipe和PipeDream。接下来,将展示如何将流水线并行性与数据并行性相结合,允许在不耗尽内存的情况下使用更大的批处理大小。
结合数据和流水线并行性
数据和流水线并行性是正交的,可以同时使用,只要批大小足够大,可以产生敏感的微批大小。
为了实现流水线并行性,每个GPU都需要与下一个流水线级(FWD期间),以及上一个流水线阶段(BWD期间)进行通信。
为了实现数据并行性,每个GPU都需要与分配了相同模型层的所有其他GPU进行通信。在管道冲洗后,需要AllReduce所有层复制之间的梯度。可以将AllReduce与最终微批的反向传递交织在一起,以减少训练时间,就像在常规数据并行训练中一样。
在实践中,管道和数据并行的正交通信是使用MPI通信器实现的。这些形成了所有GPU的子组,只允许在子组内执行集体通信。任何给定的GPU-X都将是两个通信器的一部分,一个包含与GPU-X保持相同层片的所有GPU(数据并行性),另一个包含保持GPU-X模型复制的其他层片的GPU(流水线并行性)。参见下图:

为给定的GPU池组合不同程度的数据和流水线并行性,需要一个模块化的软件架构。
流水线并行性:GPipe的实现
与数据并行性相反,流水线并行性不需要集体通信,因此工人之间也不需要显式同步。微软的DeepSpeed库使用了一种软件设计,其中每个GPU都包含一个工人,按照调度处理指令。DeepSpeed工人模型很有吸引力,因为调度是静态的。这意味着每个工人的日程安排是在工人启动时计算的,然后对每个小批量重复执行,不需要在培训期间工人之间就日程安排进行沟通。PyTorch的Pipeline设计完全不同,它使用队列在工作人员之间进行通信,工作人员将任务转发给彼此。
对于ShallowSpeed库中的GPipe实现,遵循了worker模型。
在开始处理小批量之前,首先将当前梯度归零。一旦小批量处理完成,就会通过优化器步骤更新权重。
def minibatch_steps(self):
yield [ZeroGrad()]
# 第一阶段:首先,对所有小批量进行FWD
for microbatch_id in range(self.num_micro_batches):
yield self.steps_FWD_microbatch(microbatch_id)
# 在这个位置,所有的微粒都在飞行中
#内存需求最高
# 第二阶段:然后,对所有微批次进行BWD
for microbatch_id in reversed(range(self.num_micro_batches)):
yield from self.steps_BWD_microbatch(microbatch_id)
# 更新权重是处理任何批次的最后一步
yield [OptimizerStep()]
调度的步骤是作为Python生成器实现的。来看看推进微批处理所需的步骤:
def steps_FWD_microbatch(self, microbatch_id):
cmds = []
if self.is_first_stage:
# 第一流水线阶段从磁盘加载数据
cmds.append(LoadMicroBatchInput(microbatch_id=microbatch_id))
else:
# 所有其他阶段都从前一个管道阶段接收激活
cmds.append(RecvActivations())
cmds.append(Forward(microbatch_id=microbatch_id))
if not self.is_last_stage:
# 除最后一个管道级外,所有管道级都将其输出发送到下一级
cmds.append(SendActivations())
return cmds
将微批id传递给需要存储到激活缓存中的所有操作。这是因为,对于某些微批-X,需要能够在微批-X BWD过程中检索微批-X FWD期间缓存的活动。
最后,让看看单个微批的反向传递步骤:
def steps_BWD_microbatch(self, microbatch_id):
cmds = []
if self.is_last_stage:
# 最后一个管道阶段从磁盘加载数据
cmds.append(LoadMicroBatchTarget(microbatch_id=microbatch_id))
else:
# 所有其他阶段都等待从上一阶段获得梯度
cmds.append(RecvOutputGrad())
# 第一个微批次是经过反向传递的持久批次
if self.is_first_microbatch(microbatch_id):
# 在BWD的最后一个微批次中,交错反向传播和AllReduce
cmds.append(BackwardGradAllReduce(microbatch_id=microbatch_id))
else:
cmds.append(BackwardGradAcc(microbatch_id=microbatch_id))
if not self.is_first_stage:
# 除最后一个管道阶段外,所有管道阶段都将其输入等级发送到前一阶段
cmds.append(SendInputGrad())
yield cmds
结论和总结
以上就是对管道并行性的介绍。流水线并行是一种通过在GPU上划分模型的层来训练不适合单个GPU内存的大型模型的方法。在正向传递(发送激活)和反向传递(发送梯度)期间,在模型分区之间执行GPU到GPU的通信。看到了朴素模型并行性如何因GPU使用率低而受到影响。GPipe可以缓解这种情况,它将小批量拆分为更小的小批量,使多个GPU在任何给定时间都处于忙碌状态。看到了PipeDream,另一种流水线并行算法,通过更早地开始反向传递,实现了比GPipe更小的内存占用。流水线并行性可以与数据并行性相结合,以进一步减少每个worker的内存需求。
为了更好地了解管道并行性,请查看GPipe和PipeDream论文。PipeDream论文还解释了他们在GPU之间公平划分任意模型的分析策略。《威震天LM》是另一本好书。它讨论了如何有效地结合数据并行性、PipeDream和张量并行性,同时保持序列一致性。
为ShallowSpeed从头开始在CPU上实现了GPipe并行训练。试图使代码尽可能可读,可以随意使用。
参考文献链接
https://siboehm.com/articles/22/pipeline-parallel-training
![[vue3] Vue3 自定义指令及原理探索](https://fox-blog-image-1312870245.cos.ap-guangzhou.myqcloud.com/202408010206704.png)

![Zotero怎样才能形成[2-6]这样的引用](https://img2024.cnblogs.com/blog/3493107/202408/3493107-20240801004817066-284980520.png)