腾牛网抓取(单页)
创建时间:2024-08-05
一、完整代码
import requests
from lxml import etree
url = 'https://www.qqtn.com/wm/meinvtp_1.html'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
res = requests.get(url, headers=header)
# data = res.content.decode('gbk') # 手动设置
res.encoding = res.apparent_encoding # 自动获取解码格式
data = res.text
tree = etree.HTML(data)
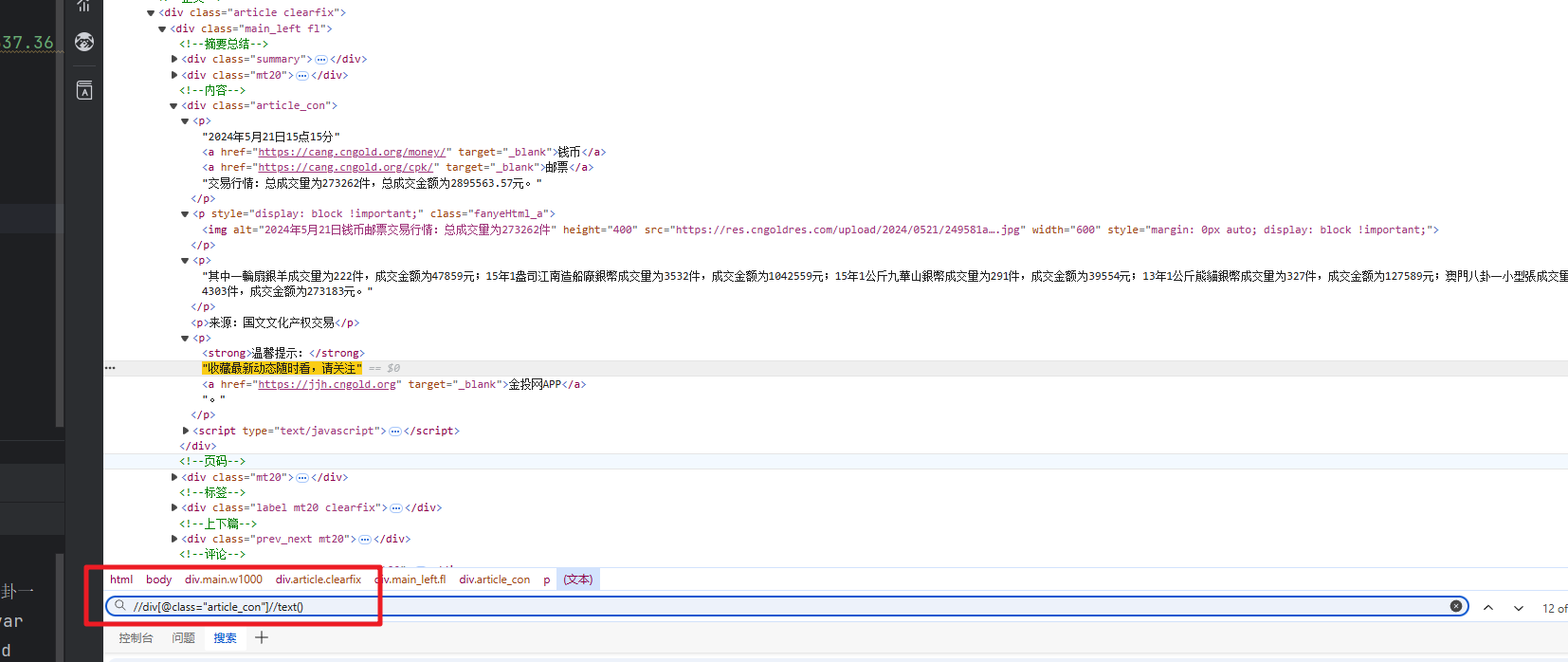
url_list = tree.xpath('//ul[@class="g-gxlist-imgbox"]//img/@src')
url_title = tree.xpath('//ul[@class="g-gxlist-imgbox"]//a/@title')
for url, title in zip(url_list, url_title):print(f'下载{title}中-------')with open(f'./tnw/{title}.png', 'wb') as f:f.write(requests.get(url).content)
1.1 效果
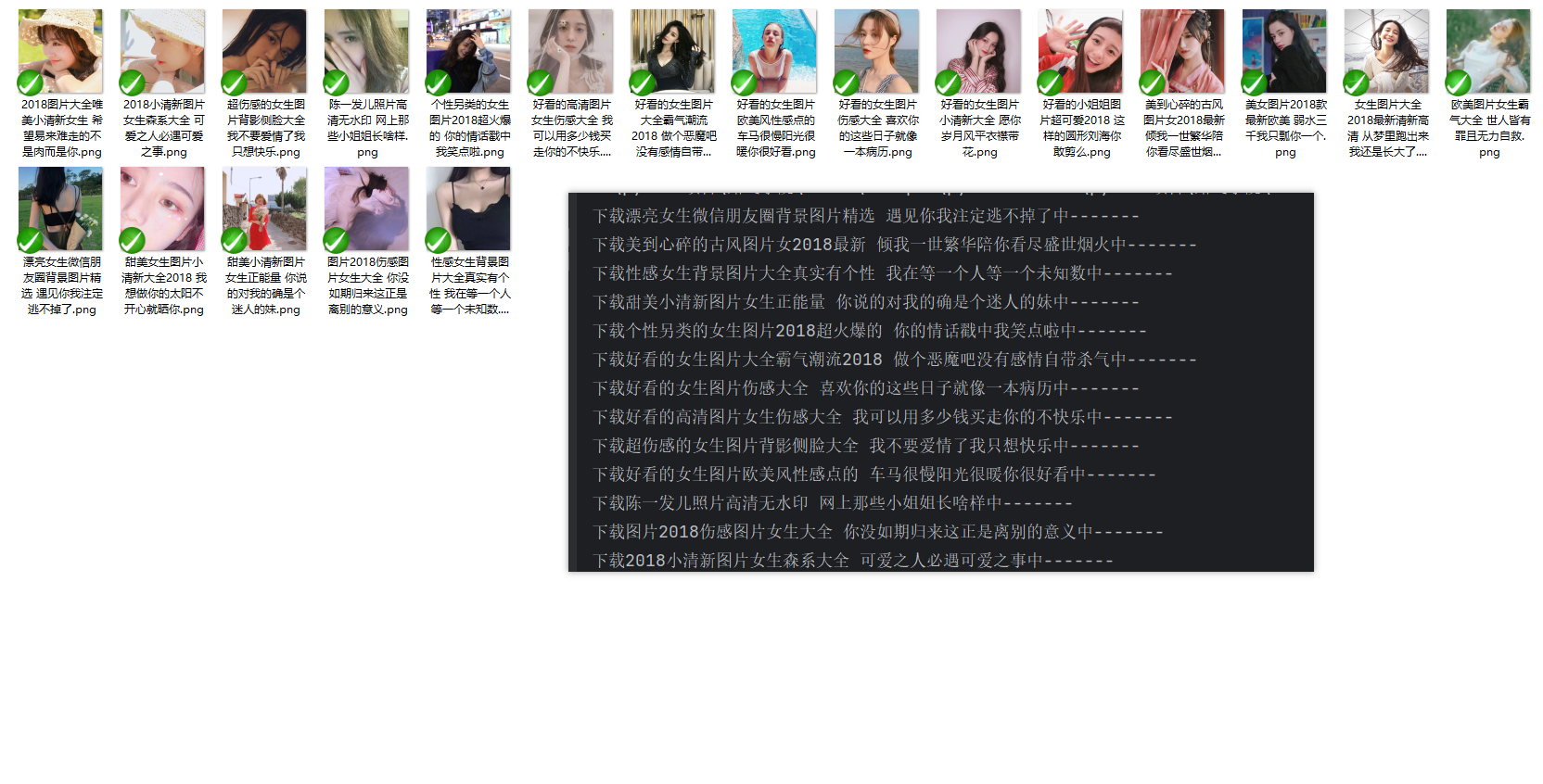
二、知识点
2.1 xpath解析 中间节点省略

2.2 使用zip遍历
zip(*iterables, strict=False) zip对象产生长度为n的元组,其中n是作为位置参数传递给zip()的可迭代对象的数量。每个元组中的第i个元素来自zip()的第i个可迭代参数。这种情况一直持续到最短的论证被用尽为止。如果strict为真,并且其中一个参数先于其他参数用尽,则引发ValueError.