参考:
https://docs.amd.com/r/zh-CN/pg210-25g-ethernet/%E7%AE%80%E4%BB%8B?tocId=59kIPN67Q57xorWh9w6GTA
10GbE以太网MAC和PHY - 者旨於陽 - 博客园 (cnblogs.com)
什么是CML电平-CSDN博客
10G Ethernet PCS/PMA v6.0 Product Guide (PG068) • 查看器 • AMD 技术信息门户网站常识小记:
万兆以太网,即10G以太网;
MAC-(XGMII)-XGXS-(XAUI)-XGXS+PCS-(XSBI)-PMA+PMD-Fiber Optics
MII是CMOS33电平的SDR传输模式;
RGMII是CMOS33电平的DDR传输模式;
8086-8080-89c51等使用的是ttl电平,大约是5v;(1:5,0:0)由于跳变的范围太大,需要的时间太长,导致压摆率(差分放大器的电平转换速率)很低;这个阶段使用三极管控制电平的反转;
CMOS电平标准,使用CMOS反转,有3.3也有5v,(1:3.3,0:0)这个范围同样太大了,在500MHZ时钟以上,这个反转速率依旧难以满足要求了;
把电压降低以提高反转速率是场景的手段(CMOS18等),但是抗干扰能力也变弱了;
HSTL:高速传输逻辑电平标准。
XGMII:10 千兆 媒体无关接口;
涉及72根线:
1:RXC 32:RXD 4:RX CTRL
1:TXC 32:TXD 4:TX CTRL
太多的线导致等长困难,SKEW过大;FPGA的板上连接可能是由核心板和背板组成的,这么多高速信号是无法正常连接的;
随着技术进步,一切都有了改善;
XGMII——XAUI:10G 附属 接口
XAUI是4lane串行接口,其对数据接口进行串化以完成传输;
[7:0]:1lane
...
[31:24]:4lane
XAUI将XGMII优化到只需要二十根线,而且因为采用了高速收发对,走线可以走的更长,节约了硬件的开发成本。
XGXS:将XGMII与XAUI互相转换;为了方便使用XGMII协议的转换方法;

目前的FPGA:不使用PHY芯片,自己利用GT(或其他高速收发对)收取数据,并且编写RTL逻辑解析代码。
GTX的速率可以满足10G需求:
表1 RocketIO(早期GT叫做火箭IO)的种类和对应的速率
|
种类 |
MGT |
GTP |
GTX |
GTH |
GTZ |
GTY |
|---|---|---|---|---|---|---|
|
最高速率(Gbps/s) |
6.5 |
6.63.753.2 |
12.5 6.66.5 |
16.31613.1 11 |
28.05 |
32.75 30.5 |
FPGA+GT通过CML电平连接SFP+即可实现10G信号的收发。
当然,需要光模块负责其中的模数转换。
XGMII接口MODEL框图
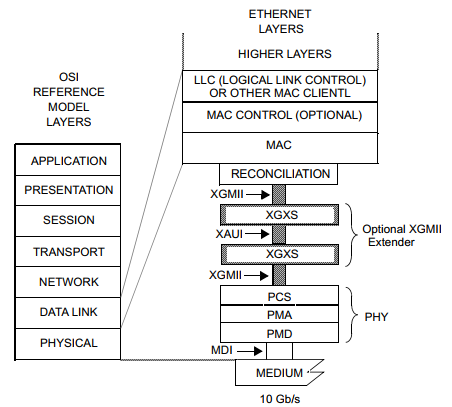
本子句定义了CSMA/CD媒体访问控制器和各种PHYs之间的调节子层(RS)和10千兆媒体独立接口(XGMII)的逻辑和电气特性。图46-1显示了RS和XGMII与ISO/IEC(IEEE)OSI参考模型之间的关系。
PHY = PCS + PMA
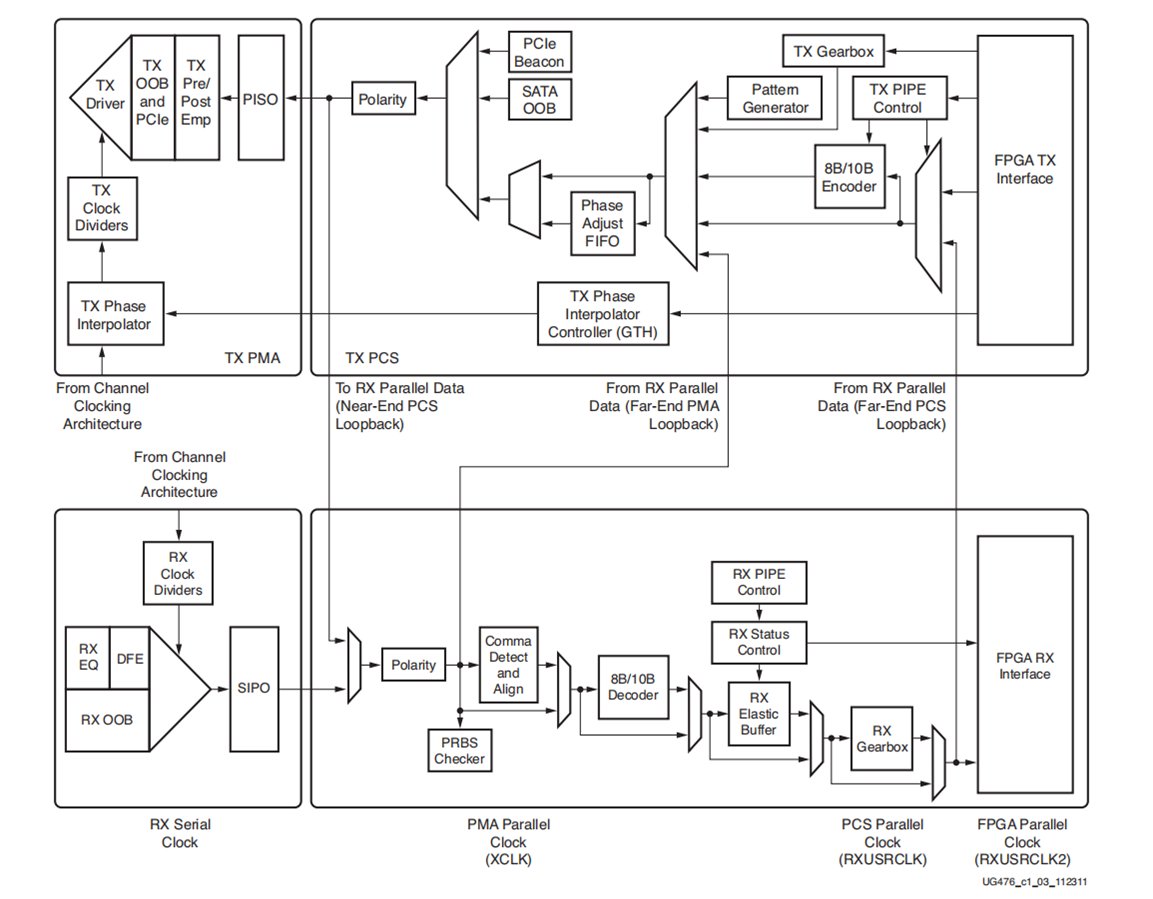
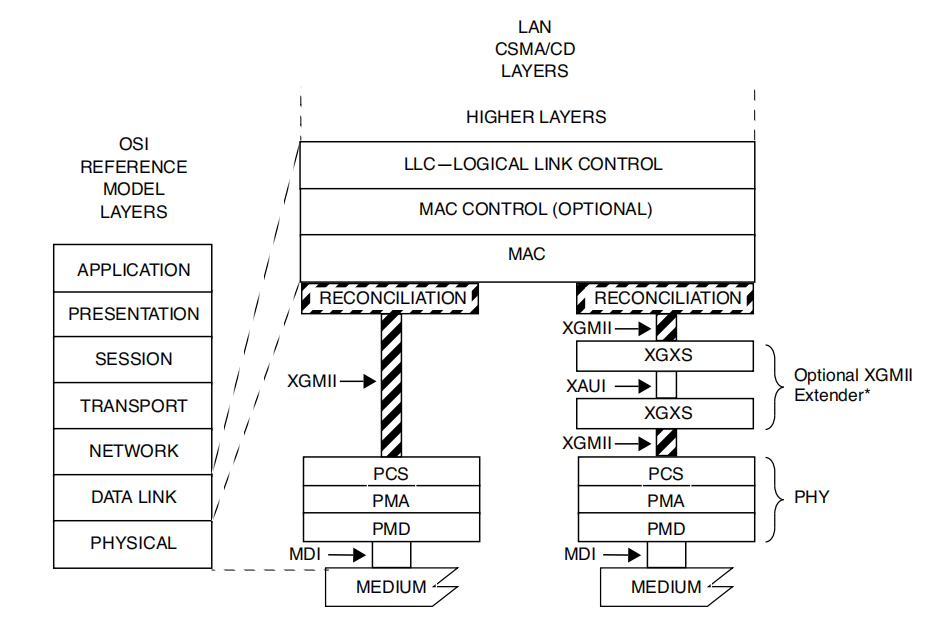
实现XGMII的方法:
1.直接使用GT收发器搭建PCS+PMA;
2.使用IP核;
XILINX 10G以太网IP核本质就是使用10G以太网协议对GT收发器进行封装。
相当于直接实现了上图的MAC之前的部分。
千兆以太网的前导码+SFD:EthernetⅡ报文格式
7{8‘h55}+8’hd5;+()+CRC
万兆以太网:802.3
前导码+界定符
在MAC字段中,将千兆以太网中的长度中增加了LCC(目的符地址等)
万兆网协议字段
GT收发器无法停止,其的所谓空闲状态也需要发送数据,只是制式需要调整。
以下是万兆网协议下的一些字符。
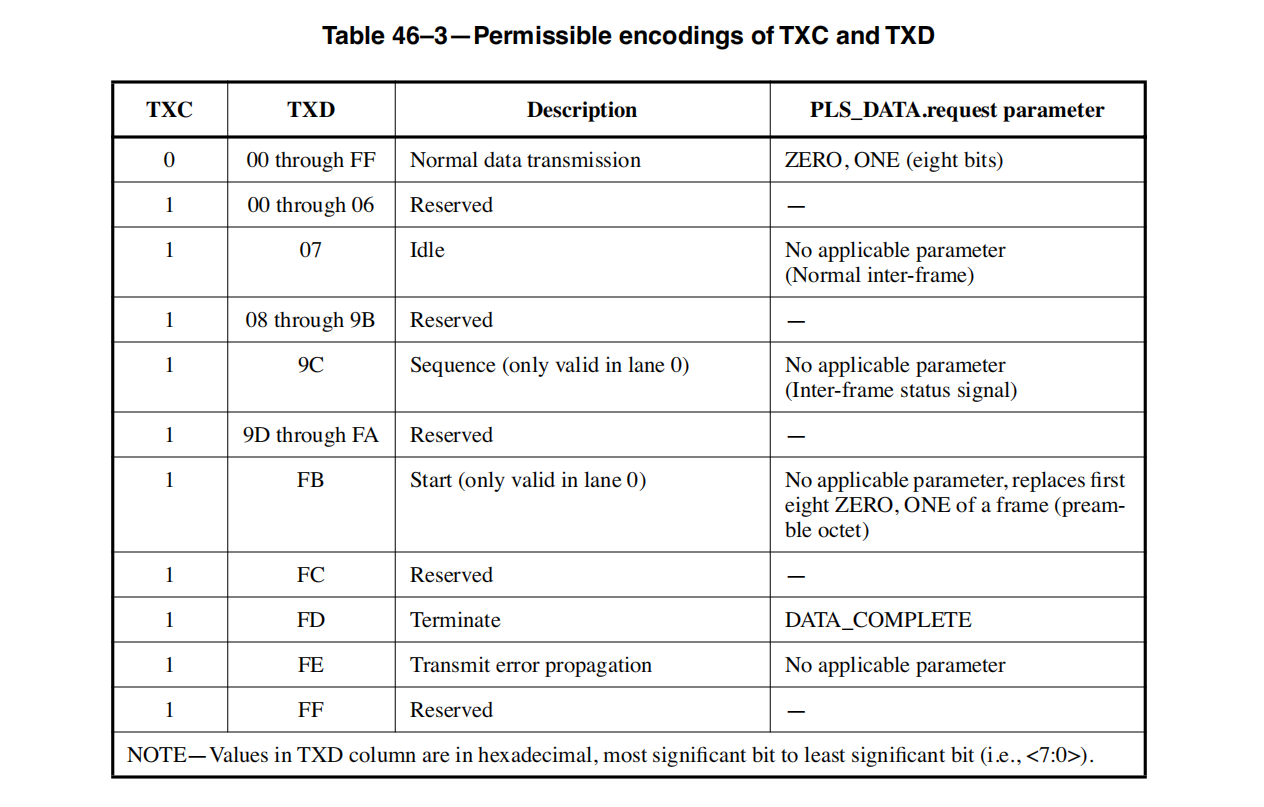
空闲字符:
task tx_stimulus_send_idle;begintx_stimulus_send_column(32'h07070707,4'b1111);endendtask // tx_stimulus_send_idle
万兆网IP核
PCS+PMA 核负责了PHY的部分;
但是完整版需要收费,这里选择手写MAC;
搬运:
10GbE以太网MAC和PHY - 者旨於陽 - 博客园 (cnblogs.com)
10GbE以太网遵循IEEE 802.3ae规范,其物理传输介质只支持光纤。
10GbE以太网主要分为串行的10GBase-S/L/E-R/W与并行(4路并行WDM波分复用)的10GBase-LX4两类。
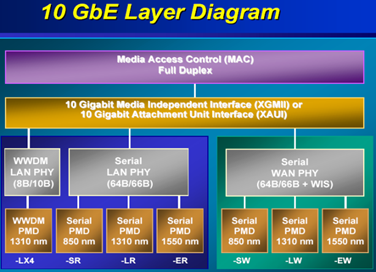
10GBase-S/L/E-R/W中,S/L/E表示波长,S表示850nm短波,L表示1310nm长波,E表示1550nm超长波,不同波长有效传输距离不一样;
R/W表示PHY类型,R表示LAN PHY,即局域网物理层,码率为10.3125Gb/s,W表示WAN PHY,即广域网物理层,码率为9.95328Gb/s。
串行10GBase-R/W使用64B/66B编码,而并行10GBase-LX4沿用千兆以太网的8B/10B编码。通过64B/66B编码,10Gb/s会变成10.3125Gb/s,所以10GBase-R的码率为10.3125Gb/s。但是10GBase-W要与SONET/SDH无缝兼容,所以在10GBase-W的物理层增加了WIS(WAN Interface Sublayer)子层,其主要功能是将10GbE LAN应用中的Idle码去掉,使速率降到9.95328Gb/s,与SDH VC-4-64c和STS-192c兼容。
IP核参数
位宽选择 156.25MHZ,32位宽;64位宽时钟频率太高了!
此IP核(BASE-R)仅实现通信功能;
KR则实现了自协商、校验等功能。
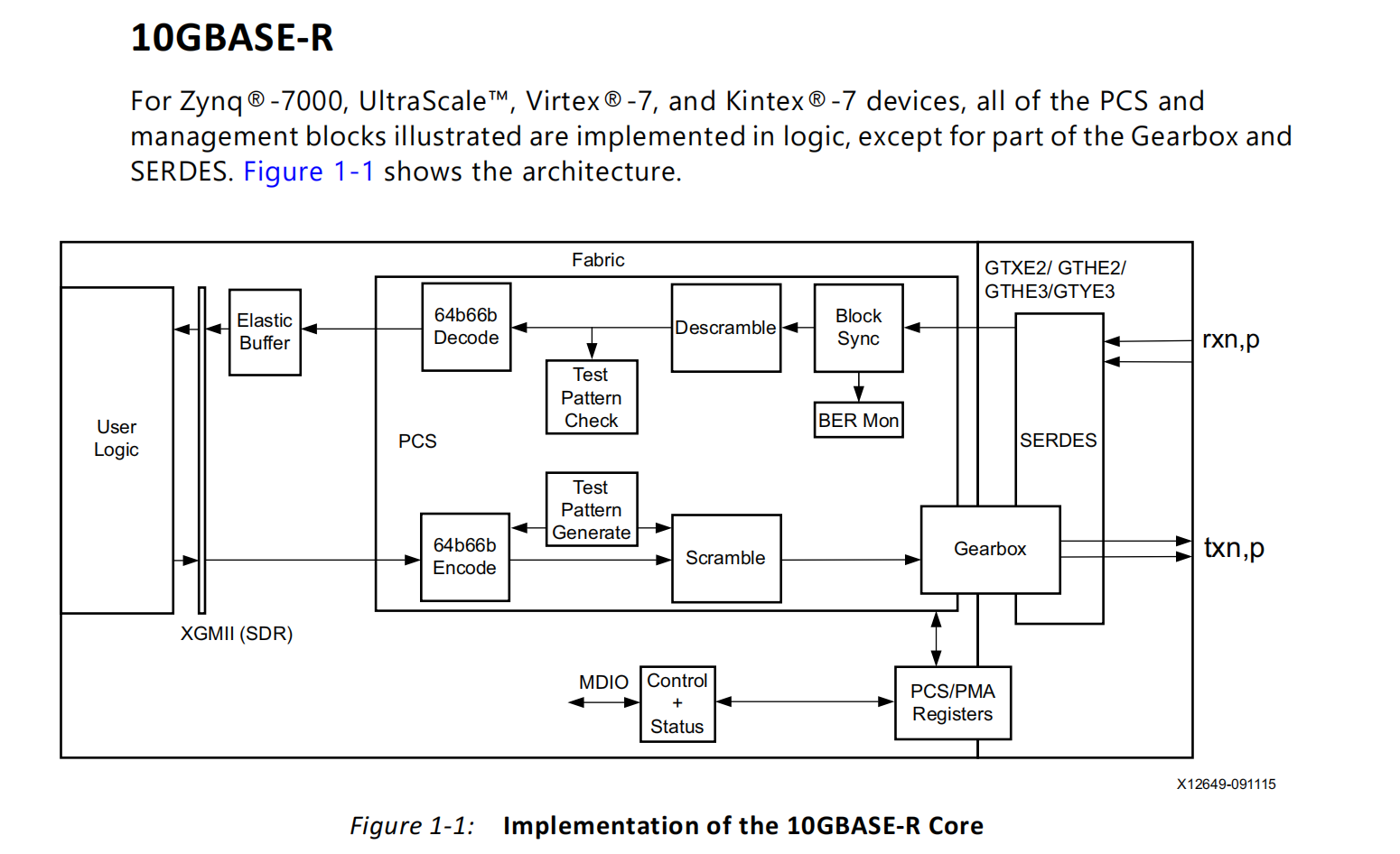 同步-解扰-解码+对齐
同步-解扰-解码+对齐
延迟
这些测量仅适用于核心;它们不包括通过收发器的延迟。通过收发器的延迟可以从相关的用户指南中获得。
这些数字的误差范围为33个UI(一个32位的XGMII单词)。
传输路径延迟
从发射端XGMII的输入端口xgmii_txd[31:0]测量(直到该数据出现在gt_txd[31:0]),
7系列设备的XGMII接口配置的延迟为14个周期。
对于超尺度设备,这是312.5 MHz传输时钟的8个周期。
接收路径延迟
接收路径延迟是可变的,并且主要取决于接收弹性缓冲区的填充级别。
当选择64位数据路径时,
核心的MAC(或客户端)端有一个64位数据路径加上8个实现XGMII接口的控制位。
表2-1定义了信号,这些信号都同步到156.25 MHz时钟源;
相关的时钟端口依赖于家族和核心排列。
它被设计为连接到FPGA中的用户逻辑,
或者通过在您自己的顶级设计中使用选择IO™技术双数据速率(DDR)寄存器,(ODDR)
以提供一个外部的32位DDR XGMII,在IEEE Std 802.3的第46条中定义。TX时钟源和RX时钟源的定义见表3-1。
(这里的描述意味着,选择64位的时候,需要使用ODDR输出以太网的输出时钟)
再用这个时钟来处理RXD这些信号。
ODDR #(.SRTYPE("ASYNC"),.DDR_CLK_EDGE("SAME_EDGE")) rx_clk_ddr(.Q(xgmii_rx_clk),.D1(1'b0),.D2(1'b1), .C(coreclk),.CE(1'b1),.R(1'b0),.S(1'b0));
SFP+相关配置
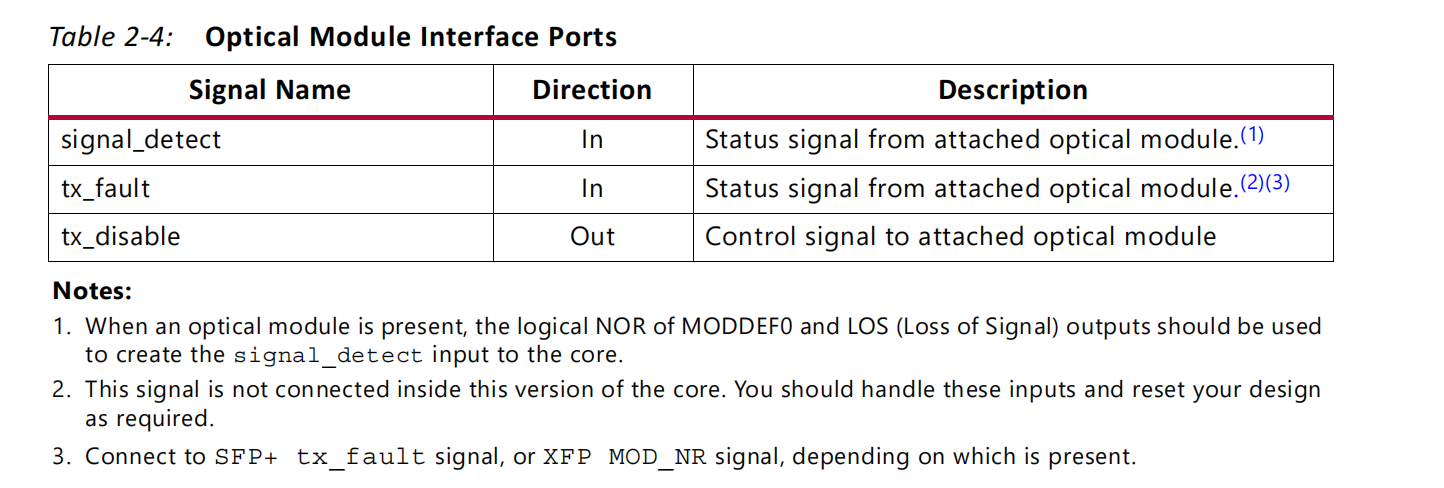
备注:
1.当一个光模块存在时,应使用MODDEF0和LOS(信号丢失)输出的逻辑NOR来创建到核心的信号检测输入。
2.这个信号没有连接到这个版本的核心内部。您应该处理这些输入,并根据需要重置设计。
3.连接到SFP+ tx_fault信号,或XFP MOD_NR信号,具体取决于存在哪个信号。
IP核引脚
选择64bit模式的时候不能像直接封装GT收发器一样使用USERCLK2作为用户时钟;而是应该使用coreclk;
这是因为其的输出的过程中添置了一些事物以后,在64bit下CORECLK只有USERCLK2的1/2;(但是DDR模式输出数据)
在官方的例子中使用了ODDR输出CORECLK。
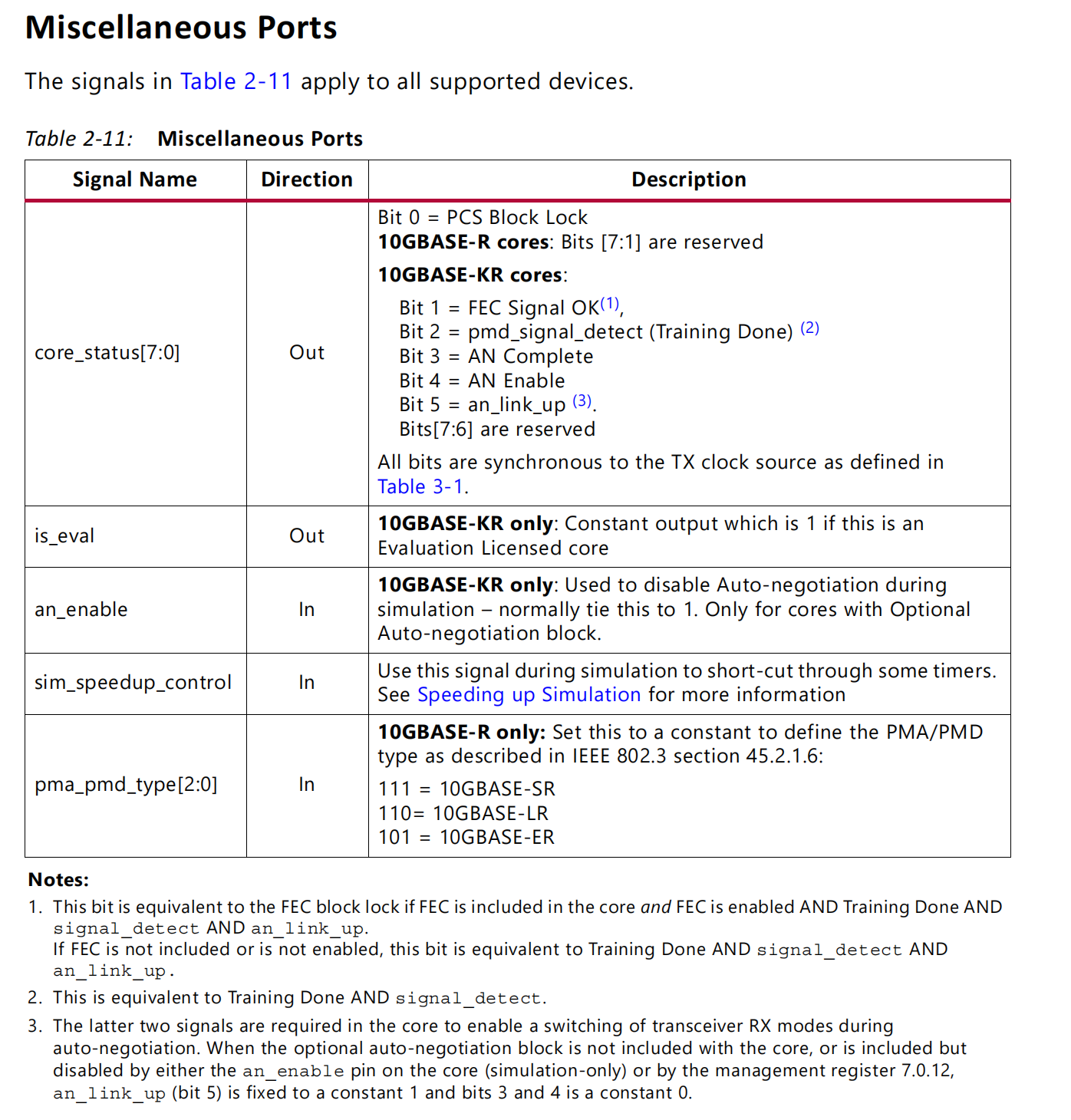
PCS BLOCK LOCK:同步完成;
其余的状态R版本没有提供。
pma_pmd_type[2:0]
In 10GBASE-R only: Set this to a constant to define the PMA/PMD type as described in IEEE 802.3 section 45.2.1.6:
111 = 10GBASE-SR(其实选其他的也没有影响)短距离
110= 10GBASE-LR 长距离
101 = 10GBASE-ER 超长距离(苛刻环境,采矿,水下)


名词解释
MAC
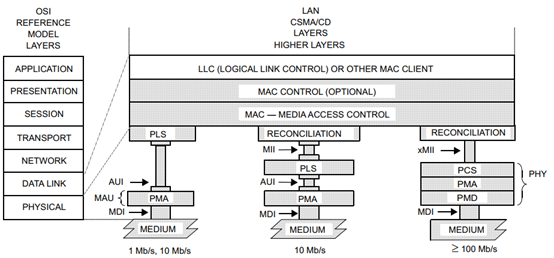
数据链路层包括LLC子层、MAC Control子层(可选)、MAC子层和RS子层。MAC层主要负责控制与连接物理层的物理介质。在发送数据时,MAC协议事先判断是否可以发送数据,如果可以发送,将给数据添加一些控制信息,最终将数据以及控制信息以规定的格式发送到物理层;在接收数据时,MAC协议首先判断输入的信息是否发生传输错误,如果没有错误,则去掉控制信息发送至LLC层。
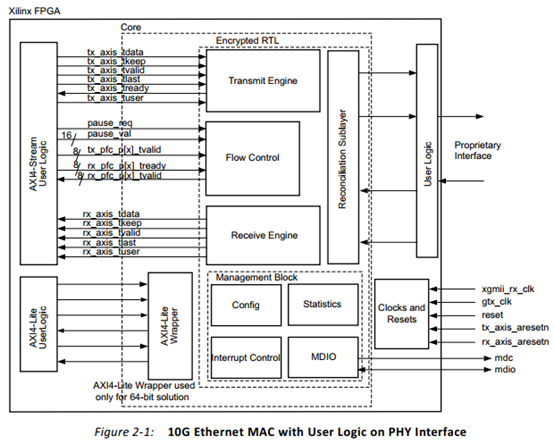
上图是10GE MAC的内部实现框图,主要包括Transmit Engine、Receive Engine、Flow Control、RS、管理模块和时钟&复位模块。其中Transmit Engine和Receive Engine主要是两个FIFO缓冲区,用来缓存发送和接收的数据。Flow Control指流控制,因为实际通信过程中,双方的处理速度不一致,这样可能出现MAC接收缓冲区满的情况,如果此时继续接收报文,则接收到的报文会被直接丢弃,Flow Control就是针对这种情况,当接收缓冲区报文达到阈值时,发送PAUSE帧或者PFC帧,告知对端MAC停止发送报文。Statistics模块则进行报文统计。
以太网帧
标准数据帧

802.1Q数据帧

MAC Control
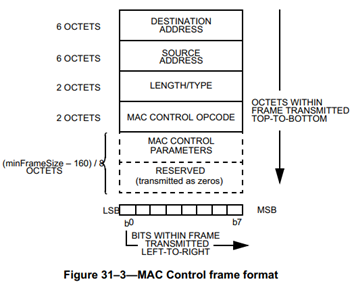
MAC Control帧格式如上图,其中,目的MAC是一个特定的地址,Type字段为0x8808,MAC Control Opcode决定了MAC Control帧的类型。
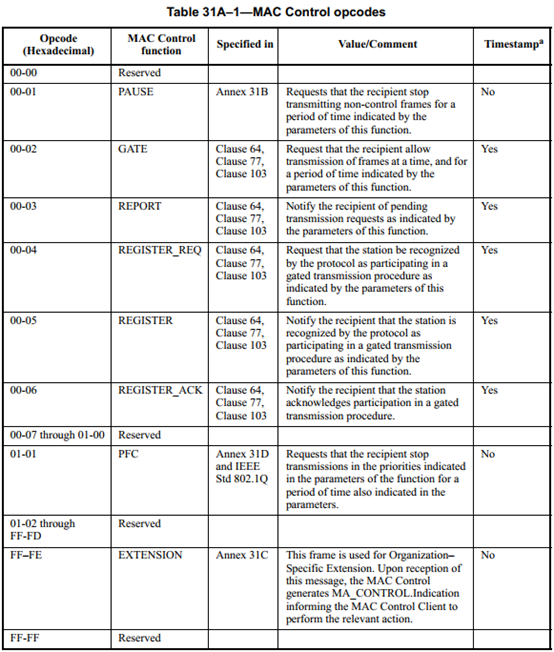
PAUSE帧和PFC帧是MAC层Flow Control的基础。
PAUSE帧的目的MAC固定为01-80-C2-00-00-01,它的作用是当接收FIFO达到阈值时,告诉对端MAC停止发送报文。PAUSE帧的参数表示停止发送报文的时间间隙,当对端MAC接收到PAUSE帧之后,会在时间间隙结束之后继续发送报文;如果在时间间隙结束之前接收到参数为0的PAUSE帧,则表示可以立即发送报文。
PFC(Priority-based Flow Control)帧则是根据802.1Q VLAN TAG的COS值,依据优先级进行流控。PFC帧的目的MAC也是01-80-C2-00-00-01。
RS
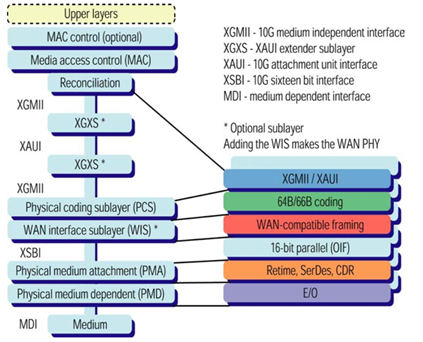
协调子层主要是使不同物理介质对MAC子层透明,即把各种MII接口的数据,以统一的方式和MAC层传输。
MII
MII接口是MAC和PHY之间的接口,有MII/RMII/SMII/SSMII/GMII/SGMII/XGMII等,由MII接口转换而来的以太网背板接口有XAUI/10G-KR4等。
XGMII
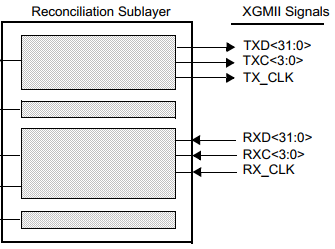
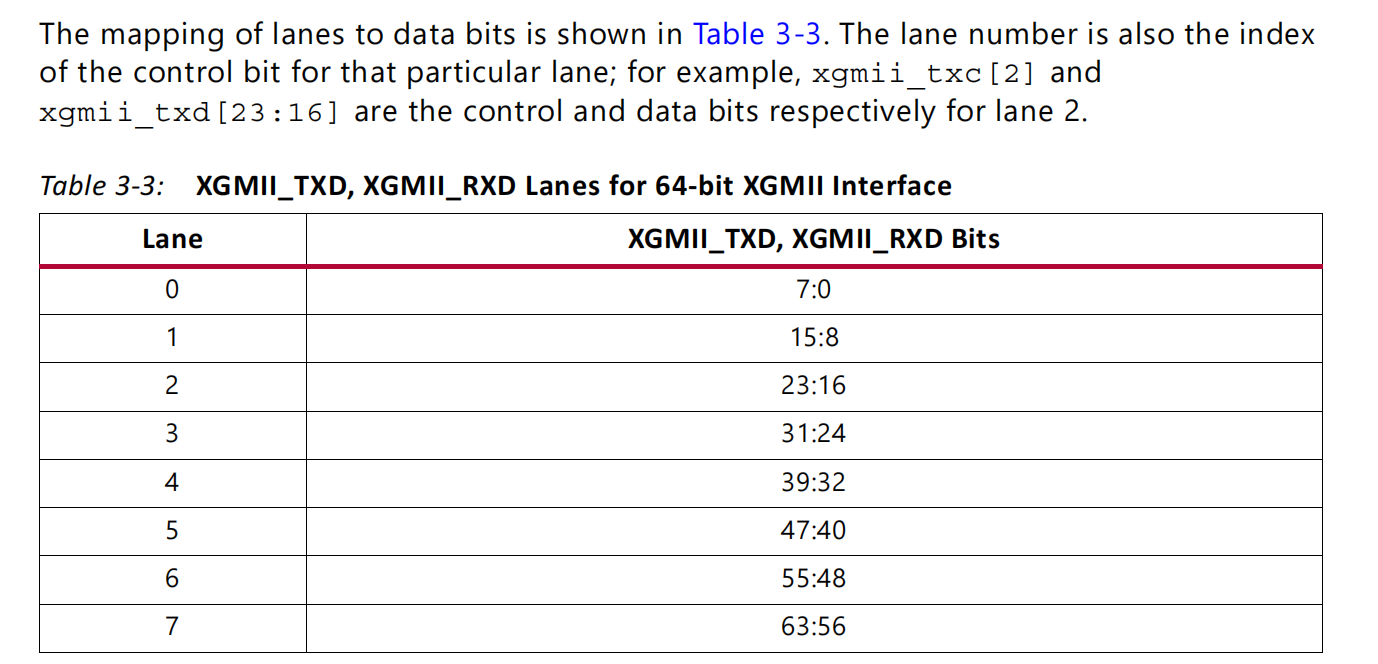
XGMII总线(IEEE 802.3 Clause 46)有发送和接收两个相互独立的通道,每个通道有一根参考时钟信号、4根数据同步信号(每个同步信号控制1个Lane的数据同步)、32根数据传输信号(分为4个Lane),一共74根信号线。
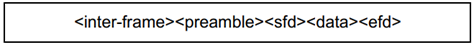
XGMII码流格式如上图,由帧间隙(IFG)、帧前导码(Preamble)、帧开始定界符(SFD)、帧数据(DATA)和帧结束定界符(EFD)构成。
帧间隙从Terminate控制符开始,到Start控制符结束,帧间隙过程中传输Idle控制帧。帧间隙的时长以字节为单位,帧间隙最小值根据双方MAC实现确定,10GBASE-R应用场景,最小帧间隙(IPG)为5个字节。(千兆网下是12个周期)
帧前导码是7个连续的0xAA。
帧开始定界符必须通过XGMII Lane 0传输,一个字节0xAB。(此处与下表中的Start控制符不一致,待商榷)
帧结束定界符,可以出现在XGMII的任意Lane,其值不详。
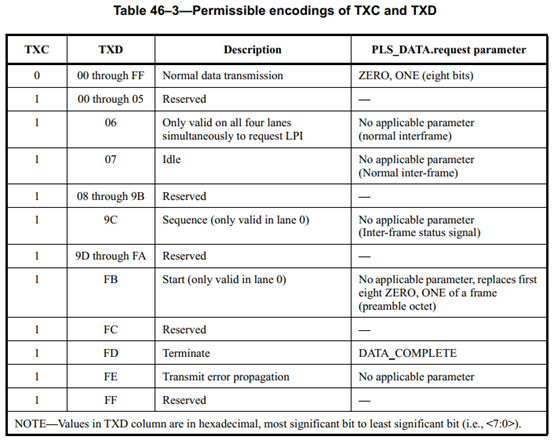
TXC为低电平时,表示传输数据帧;TXC为高电平时,表示传输控制帧。
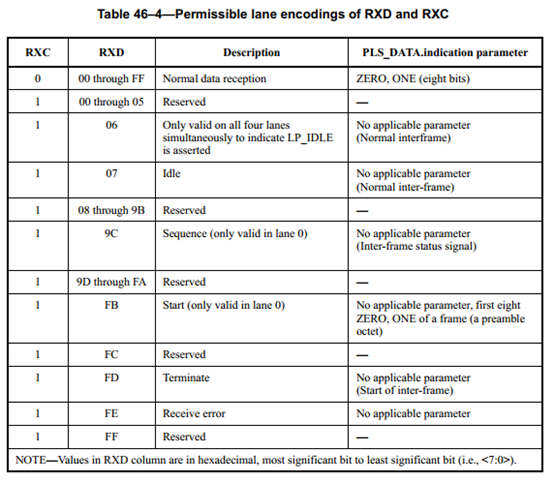
RXC为低电平时,表示传输数据帧;RXC为高电平时,表示传输控制帧。
控制通道和数据通道存在着映射关系
发送通道:S所处的位置有多个位置,C需要做映照。


XGXS & XAUI
XGXS包括位于RS侧的DTE XGXS和PHY侧的PHY XGXS两部分。XGXS子层(IEEE 802.3 Clause 47)的出现有两个原因:
1) XGMII接口是并行接口,一共有74根信号线,XGXS将XGMII接口转为XAUI接口,串行化(4 Lane共16根信号线);
2) XGMII接口总线的布线长度小于7cm,无法支持二层以太网交换机跨板(通过背板)通信,经过XGXS转换的XAUI接口则支持最长50cm的布线长度;

发送方向,XGXS接收XGMII的数据,将XGMII数据帧和控制帧转换成XAUI码流(code-groups),编码之后传输。接收方向,首先解码XAUI码流,补偿时钟和相位,转换成XGMII数据帧和控制帧,然后传输。
PHY
PHY层包括PCS子层、PMA子层和PMD子层。
PCS
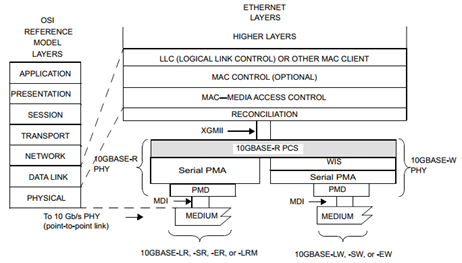
PCS层面向的业务接口是XGMII, XGMII是所有10Gb/s PHY针对RS层或者XGXS层提供的统一接口。
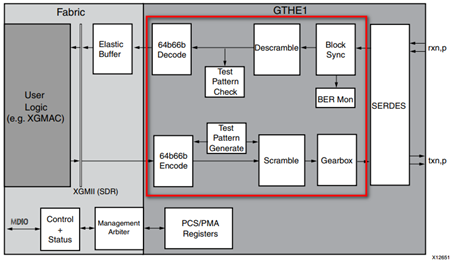
上图是一个典型的10GBase-R PHY的IP核内部结构体,红色框图部分是PCS实现。其中,64B/66B Encode/Decode负责编解码、Test Pattern Generate/Test Pattern Check负责发送和校验测试报文(PHY硬件自检)、Scramble/Descramble负责加解扰、Gearbox(变速箱)和Block Sync负责速率匹配和时钟、相位补偿、字对齐等功能、BER Mon(Bit Error Rate Monitor)负责监控误码率。
加解扰技术是一种调制技术,其原理是将扰码与原始信号相乘,从而得到新的信号,与原始信号相比,新信号在时间和频率上被打散。(不加扰根本发不对)
PCS层发送方向和接收方向都可以工作在正常模式(Normal mode)和测试模式(Test-Pattern mode)。当处于测试模式时,Test Pattern Generate/Check使能。
PCS层Gearbox模块负责将发送方向的数据分组成16位一组的数据单元,通过XSBI接口发送给PMA层。
编解码的目的有两个:
1)避免物理传输介质上出现连续的1或者0,如64B/66B编码将64位数据编码成66位数据在传输介质上传输,从而降低信噪比;
2)区分出数据和命令。
此外,PCS层还负责PHY自协商,PHY自协商可以自动匹配工作模式、工作速率等。
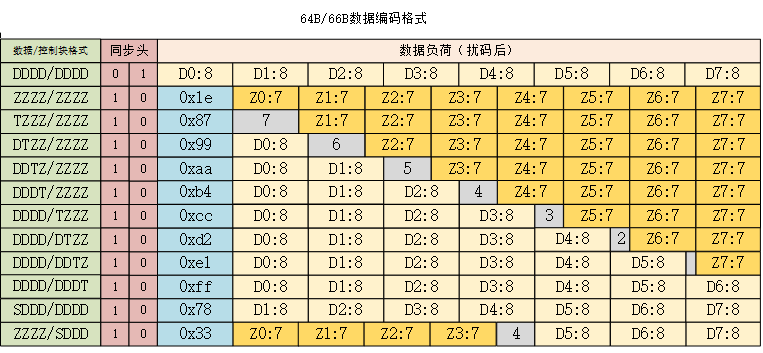
64B/66B
10GBase-R的PCS层使用64B/66B编码(IEEE802.3 Clause 49),支持数据帧和控制帧,同时拥有健全的错误检测机制。
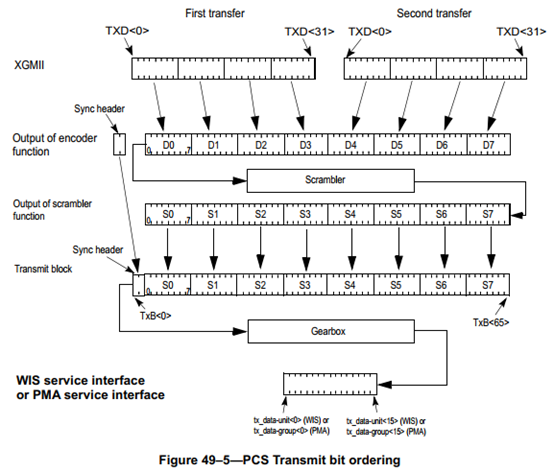
发送方向,PCS从XGMII接收两组32位数据,一共64位数据。然后添加2位同步头(根据XGMII的TXC信号决定),01表示数据帧,10表示控制帧。同步头不通过Scrambler模块加扰码,因为如果同步头被改变,就无法区分数据帧和控制帧,也无法进行帧定界。
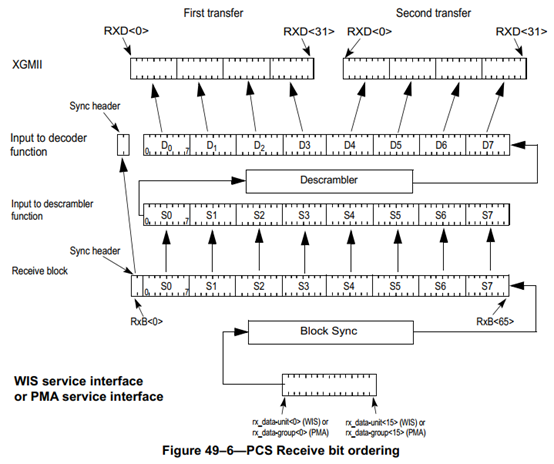
在接收方向,PCS从接收到的66位数据块中提取出同步头,负载部分进行解扰码和64B/66B解码,然后把解码出来的数据通过XGMII接口发送给XGXS层或者RS层。
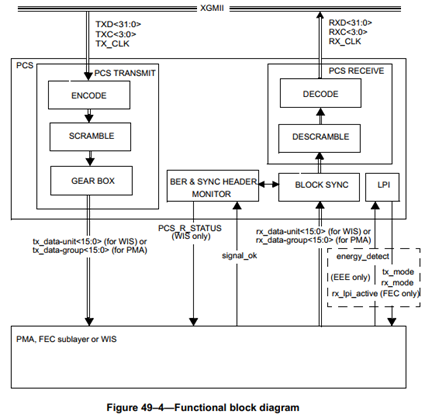
PCS层无论是对接RS层还是XGXS层,都是通过XGMII接口。XGMII接口在发送和接收方向都有32根数据线,通过TXC[3:0]和RXC[3:0]进行数据同步,每个TXC/RXC信号控制8根数据线。
64B/66B编码中,数据帧和控制帧除了同步头之外的负载部分,均包含8个字节。对于数据帧而言,负载各字节命名为D0~D7。控制帧负载的8个字节,除了Ordered Set(/O/)字符、Start(/S/)字符和Terminate(/T/)字符之外,命名为C0~C7。Ordered Set字符只能由XGMII的第一个Lane发送,因此命名为O0或者O4;Start字符同样只能由XGMII的第一个Lane发送,因此命名为S0或者S4;Terminate字符则可以出现在任意字节,因此命名为T0~T7。
对于控制帧而言,进行64B/66B之后,除同步头之外的负载部分第一个字节称为Block Type域,用来区分控制帧类型。对于包含Start字符或者Terminate字符的控制帧,Block Type域指示了它的类型。其他控制字符被编码为7位的控制码(Control Code)或者4位的O码(Ordered Set Code)。
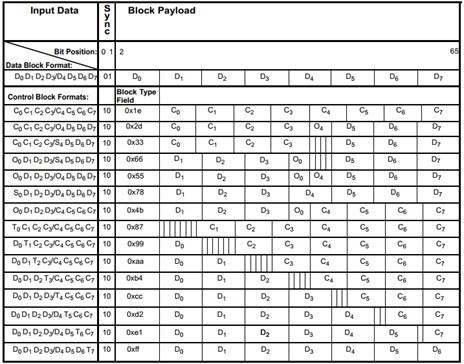
Control Codes
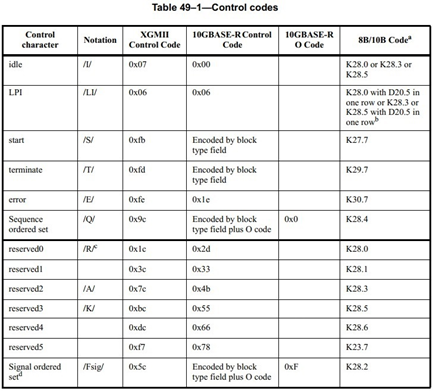
Idle(/I/)
从XGMII接收到Idle控制字符(0x07)时,PCS会根据当前数据传输忙或者闲,动态地插入或者删除Idle字符,从而调整时钟频率。/I/字符的插入和删除需要4个一组,/I/字符只能出现在/I/或者/O/之后。数据接收过程中,不能插入/I/字符。删除/I/时,紧跟着/T/的四个/I/不能被删除。
LPI(/LI/)
/LI/字符的插入和删除原则同/I/字符。
Start(/S/)
Start字符表示开始发送报文。
Terminate(/T/)
Terminate字符表示发送报文结束。
Ordered Set(/O/)
/O/字符表示开始发送Ordered Set,有两种类型的Ordered Sets——Sequence Ordered Set和Signal Ordered Set(保留扩展用)。其中,/O/出现在XGMII的第一个Lane中,/Q/紧跟着/O/出现。
Ordered Sets用来发送控制和状态信息,如Remote Fault和Local Fault。Ordered Sets包含一个控制字符,紧跟着3个数据字符。10GBASE-R应用场景只有一种Ordered Set类型,即Sequence Ordered Set,它的控制字符简写为/Q/。
Error(/E/)
当从XGMII接收到/E/字符,或者接收到无效控制帧时,/E/被发送。/E/可以使PCS层或者XGXS层接收到错误信息。
一个66位数据块怎么确认是否为有效数据块呢?当出现以下情况是,被判定为无效数据块:
1) 同步头不是01或者10;
2) 如果为控制帧,Block Type域为无效类型;
3) 如果为控制帧,控制码为无效控制码;
4) 任何无效Ordered Set Code(4位),包括0xF;
5) 64位负载各字符顺序错乱;
PMA
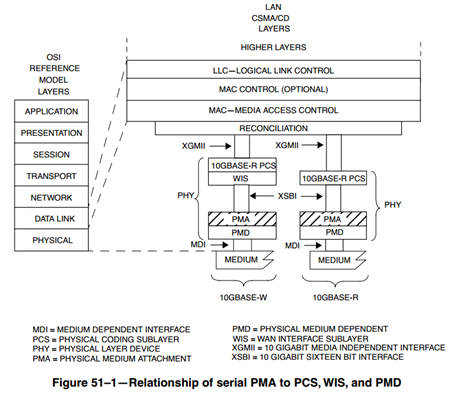
如图所示,10GBASE-R应用场景中,PMA子层介于PCS编码子层和PMD子层之间,它与PCS编码子层之间使用XSBI总线接口。

PMA主要包括TX Serializer、RX Deserializer、PLL和CDR几部分。其中CDR负责从接收的数据中恢复出时钟信号,并通过PLL输出发送数据时钟。发送方向,Tx Serializer负责将并行数据转换成串行数据。接收方向,Rx Deserializer负责将接收的串行数据转换成并行数据。
在PMA的实现中,针对发送通道可以配置预加重值和VOD值。预加重是噪声整形技术在模拟信号处理中的应用,其原理是在信号发送之前,先对模拟信号的高频分量进行适当提升;在收到信号之后,再对信号进行逆处理,即去加重,对高频分量进行适当衰减。预加重与去加重技术可以降低信号在传输过程中的高频损耗,也可以使噪声的频谱发生变化,这就是模拟降噪的原理。在接收方向,使用失调消除技术(offset cancellation)进行降噪。
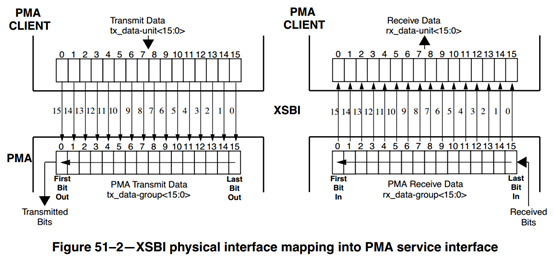
接收方向
接收方向,PMA层从PMD层接收数据,然后发送到PCS层:
1) 从接收PMD的串行数据中恢复时钟,并将时钟信号传送到PCS编码层;
2) 将10Gb/s串行数据并行化,变成16bit并行数据,速率为644.53Mbps,通过XSBI(10G Sixteen Bit Interface)接口,发送到PCS编码层;
3) 提供链路状况信息;
发送方向
发送方向,PMA层从PCS层接收数据,然后发送到PMD层:
1) 提供时钟信号给PCS层;
2) 从PCS编码层接收16bit并行数据进行串行化,变成10Gb/s串行数据发送到PMD层;
PMD
10GBASE-R应用场景中,PMD子层负责光电信号转换,即光模块。

自协商
目前只有千兆PHY才支持自协商模式,如10/100/1000M自适应PHY。
PHY自协商是通过快速连接脉冲(Fast Link Pulse)信号实现,简称FLP。自协商的双方通过FLP来交互数据。
在具备自协商能力的端口没有Link的情况下,端口一直发送FLP,在FLP中包含着自己的连接能力信息,包括支持的速率能力、双工能力、流控能力等。这个连接能力是从自协商能力寄存器中得到的(Auto-Negotiation Advertisement Register ,PHY标准寄存器地址4 )。FLP依靠脉冲位置编码携带数据,一个FLP突发包含33个脉冲位置。17个奇数位置脉冲为时钟脉冲,时钟脉冲总是存在的;16个偶数位置脉冲用来表示数据:此位置有脉冲表示1,此位置没有脉冲表示0。这样1个FPL的突发就可以传输16bit的数据。自协商交互数据就这样通过物理线路被传输。
如果两端都支持自协商,则都会接收到对方的FLP,并且把FLP中的信息解码出来。得到对方的连接能力。并且把对端的自协商能力值记录在自协商对端能力寄存器中(Auto-Negotiation Link Partner Ability Register , PHY标准寄存器地址5 )。同时把状态寄存器(PHY标准寄存器地址1)的自协商完成bit(bit5)置成1。在自协商未完成的情况下,这个bit一直为0。然后各自根据自己和对方的最大连接能力,选择最好的连接方式Link。比如,如果双方都即支持10M也支持100M,则速率按照100M连接;双方都即支持全双工也支持半双工,则按照全双工连接。一定连接建立后,FLP就停止发送。直到链路中断,或者得到自协商Restart命令时,才会再次发送FLP。
Error and Fault Handling
数据帧接收过程中,通常是/S/ + /D/ … /D/ + /T/序列,如果在/C/控制字符出现在/S/和/T/之间,那么RS层应该告知MAC层发生了FrameCheckError。如果/S/出现在除了lane 0之外的lane上,RS层也会感知到错误。
数据帧发送过程中,PHY必须仔细校验保证数据不被篡改,因为一旦对端发现接收到的数据被篡改,就会发送Error控制字符。
Link Fault Signaling
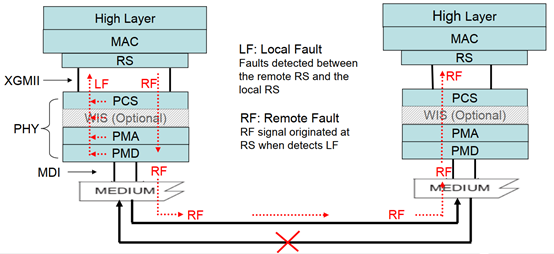
关于Link Fault Signaling,参考IEEE 802.3ae Clause46.3.4章节。
首先要区分两个概念,PHY层Link Up和LLC层Link Up,前者是物理链路的连接状态,后者是逻辑链路的连接状态。通常,此处,Link Fault指的是PHY层的链路连接状态。
PHY层的链路状态指Local RS层和Remote RS层之间的链路状态。
PHY层的各子层都需要具备检测链路错误的能力,检测链路错误主要分为两个方面:
1) 检测I/O信号;
2) 传输数据/控制帧解析,包括:
CODEC Synchronization;
Lane Alignment,如/S/只能出现在Lane 0等;
Link Status Report Recognized;

Link Status Message是一个四字节的Ordered Sets,其中Lane 0是Sequence控制字符,剩下的3个是数据部分。Local Fault帧的Sequence控制字符是0x9C,Remote Fault帧的Sequence控制字符是0x00。
任何一方,在接收过程中检测到链路错误,都会产生Local Fault, Local Fault帧会在接收方向透传PHY各子层,直到RS层。
RS层负责处理Local Fault帧,同时发送Remote Fault帧给对端RS层(只有RS层可以残生Remote Fault帧)。Remote Fault帧在RS层之间透传。RS层之所有会发送Remote Fault帧给对端,是假设只有接收链路发生链路错误,发送链路没有问题。
当RS层在128个时钟周期内接收到4个以上Local Fault帧时,它会通知本机MAC停止发送数据,并连续发送Remote Fault帧给对端RS层。当RS层在128个时钟周期内,连续接收到4个Remote Fault帧时,才会认为发送链路出现问题,它会通知本机MAC停止发送数据,并在发送链路上连续发送Idle帧。
在128个时钟周期内,没有接收到Local Fault帧或者Remote Fault帧,则表示链路状态正常。



![[Spring]Bean生命周期](https://img2024.cnblogs.com/blog/1533409/202408/1533409-20240812210152873-1325758865.png)