Multiple View Geometry Transformers for 3D Human Pose Estimation
link
时间:CVPR2024
机构:University of Toronto && Southeast University && Microsoft Research Asia
TL;DR
提出一种基于Transformer端到端3D Human Pose Estimation方法MVGFormer,核心模块是geometry与appearance模块。前者是无参可微的,泛化更友好;后者是可学习的,对提高精度更友好。效果SOTA。
Method
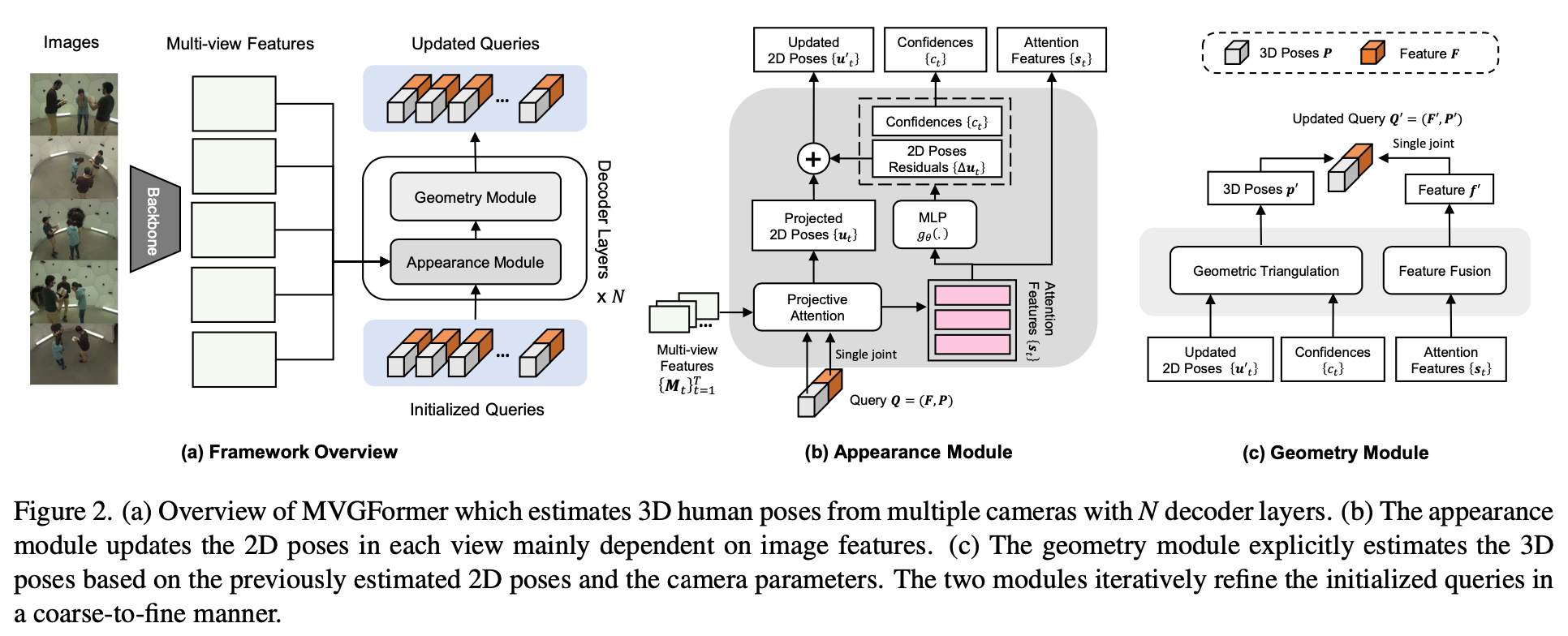
Query
Query 𝑸 = (𝑭, 𝑷)两部分构成,其中,appearance项\(F_k ∈ R_{J×L}\),geometry项\(P_k ∈ R_{J×3}\)。
Decoder
Appearance Module
输入:多目features、Query
输出:
- Attention Features:3D Poses投影到多目局部特征进行attention
- 2D Poses:上一轮3D Poses投影2D pose作为anchor,使用attention features预测residual。两者叠加。
- Condidence:2D Pose点的置信度
Geometry Module
核心操作就是可微的三角化
输入:Appearance Module的输出
输出:𝑭, 𝑷
下图是在Appearance项上增加一个MLP预测instance的score,从而过滤掉一些低质量的query减少计算量。
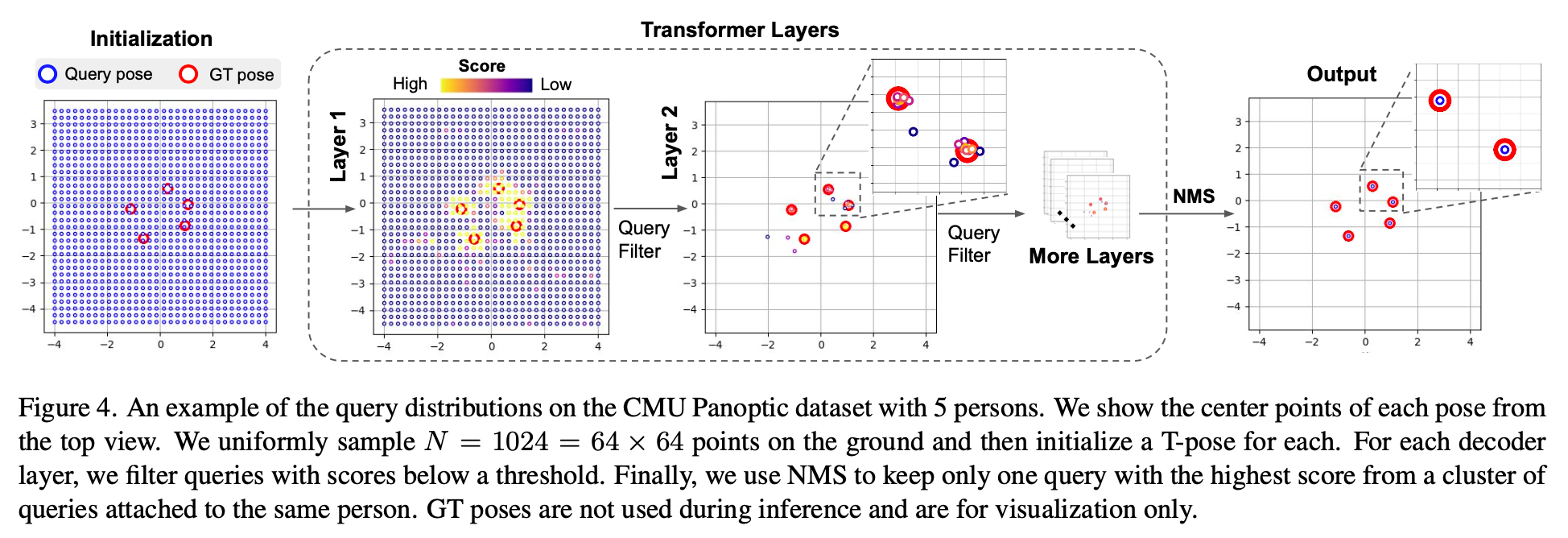
Loss
通过距离来匹配GT与Pred之间的Match关系,从而计算2D与3D误差的Loss。
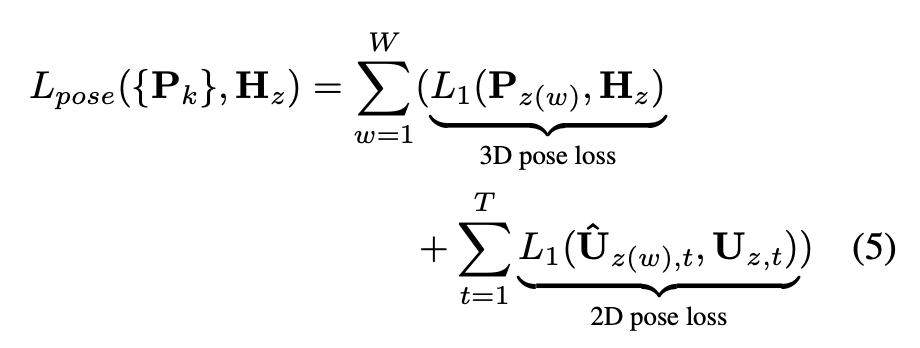
实验代码:https://github.com/XunshanMan/MVGFormer/tree/master
效果可视化:https://github.com/XunshanMan/MVGFormer/blob/master/figures/cmu_demo.gif
Experiment
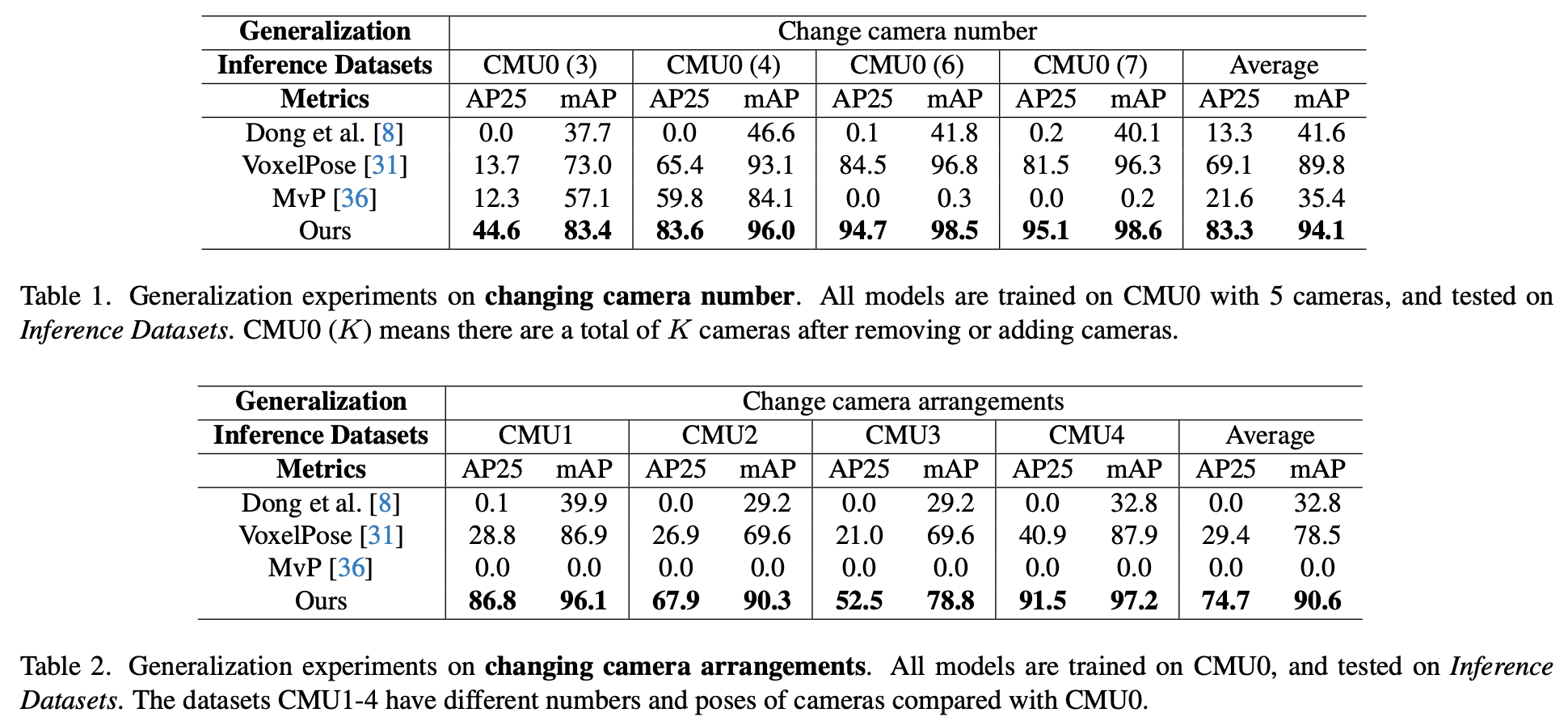
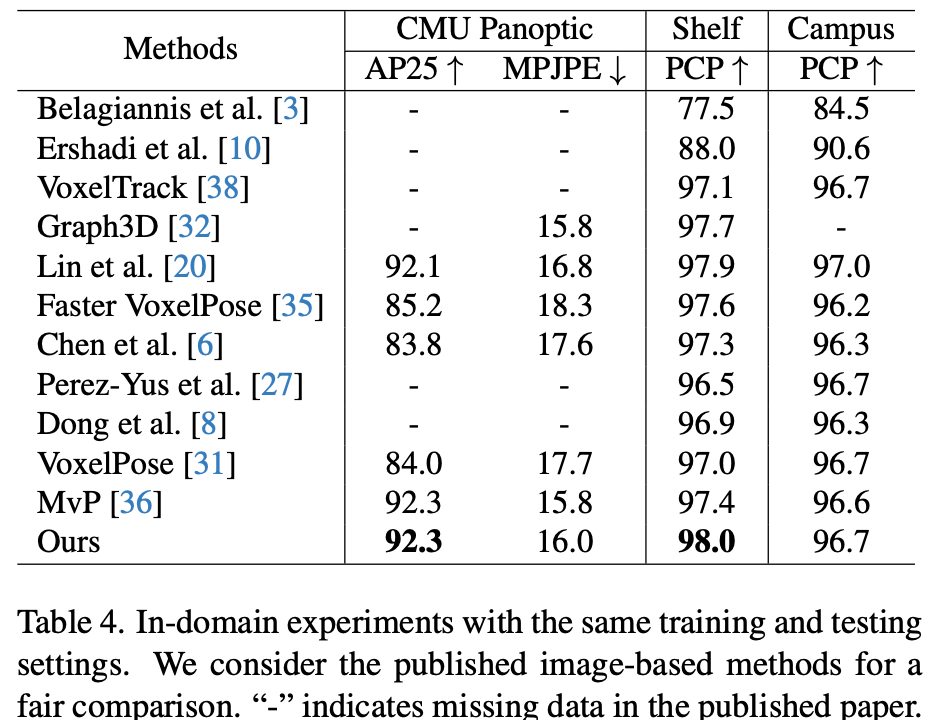
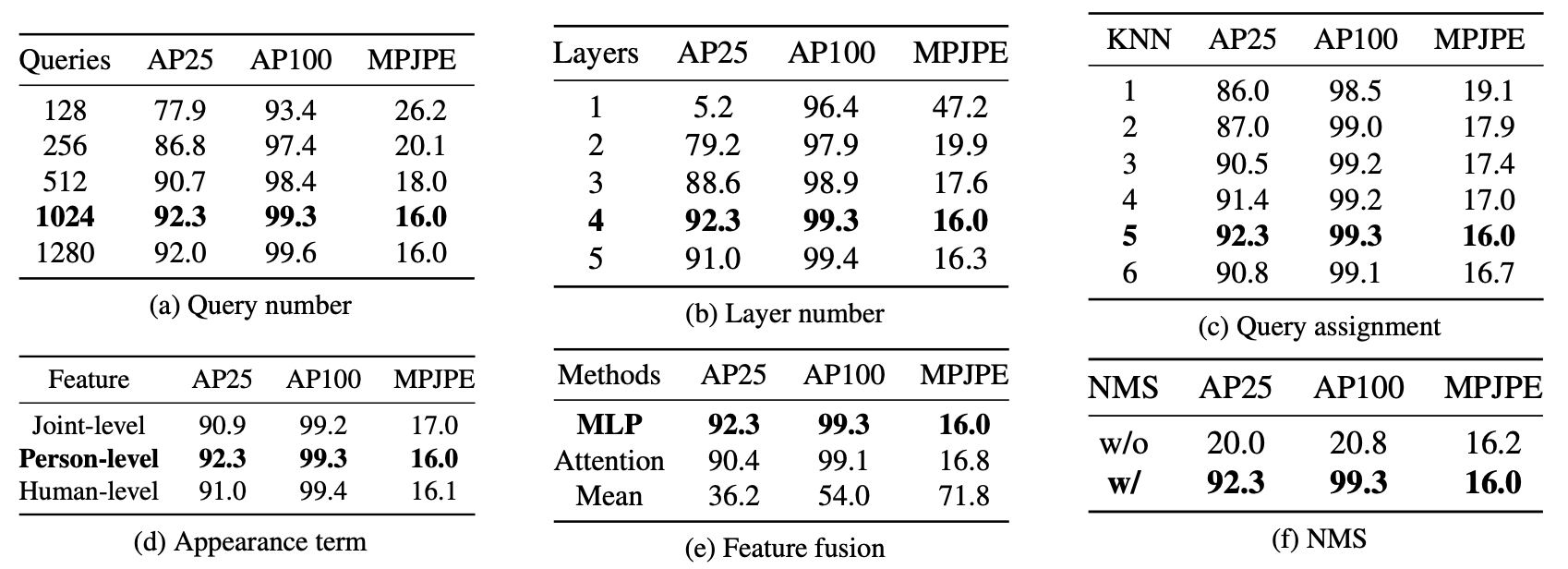
各种维度的Ablation
总结与发散
1.看效果视频遮挡方面效果还可以(可能是视角跨度比较大)
2.三角化、提取Attention Feature在端侧实际部署可能有问题