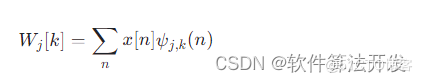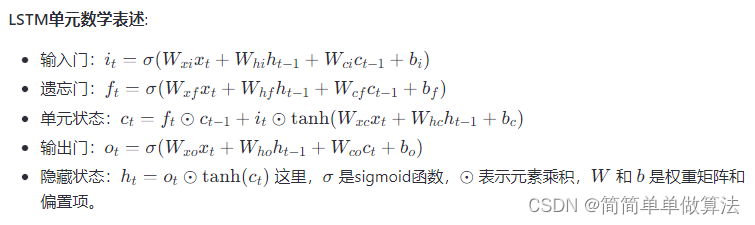个人项目———论文查重
| 这个作业属于哪个课程 | 计科12班 |
|---|---|
| 这个作业的要求在哪里 | 作业要求 |
| 这个作业的目标 | 实现论文查重,给定原文件和抄袭的文件,输出二者的相似度到答案文件中 |
GitHub链接:github
1.题目要求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
2.项目开发
2.1开发环境:
语言:JAVA
编译器:JDk-21
工具:IntelliJ IDEA
2.2项目结构
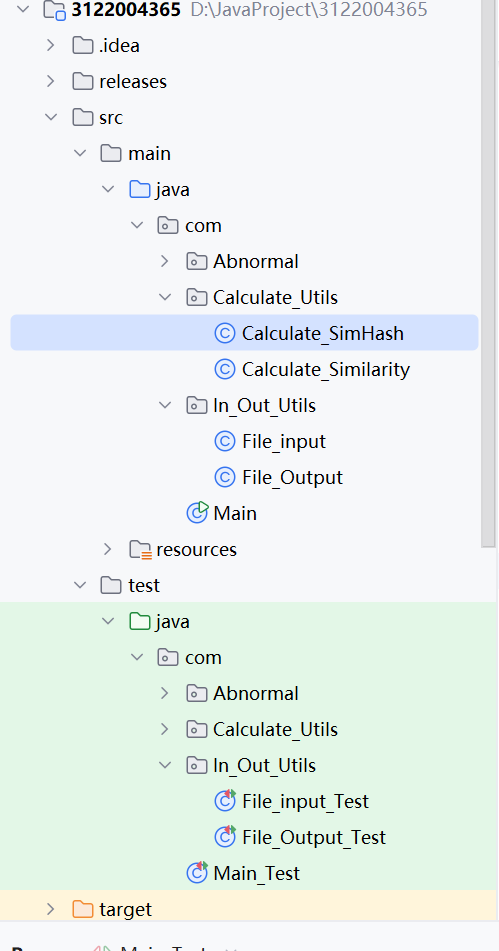
2.3项目模块介绍
- Abnormal---------处理各种异常类
- calcuture_Utils--主要算法的实现
- In_Out_Utils-----文件的输入和输出
- main-------------启动类主函数
- test-------------对其他各种类的测试
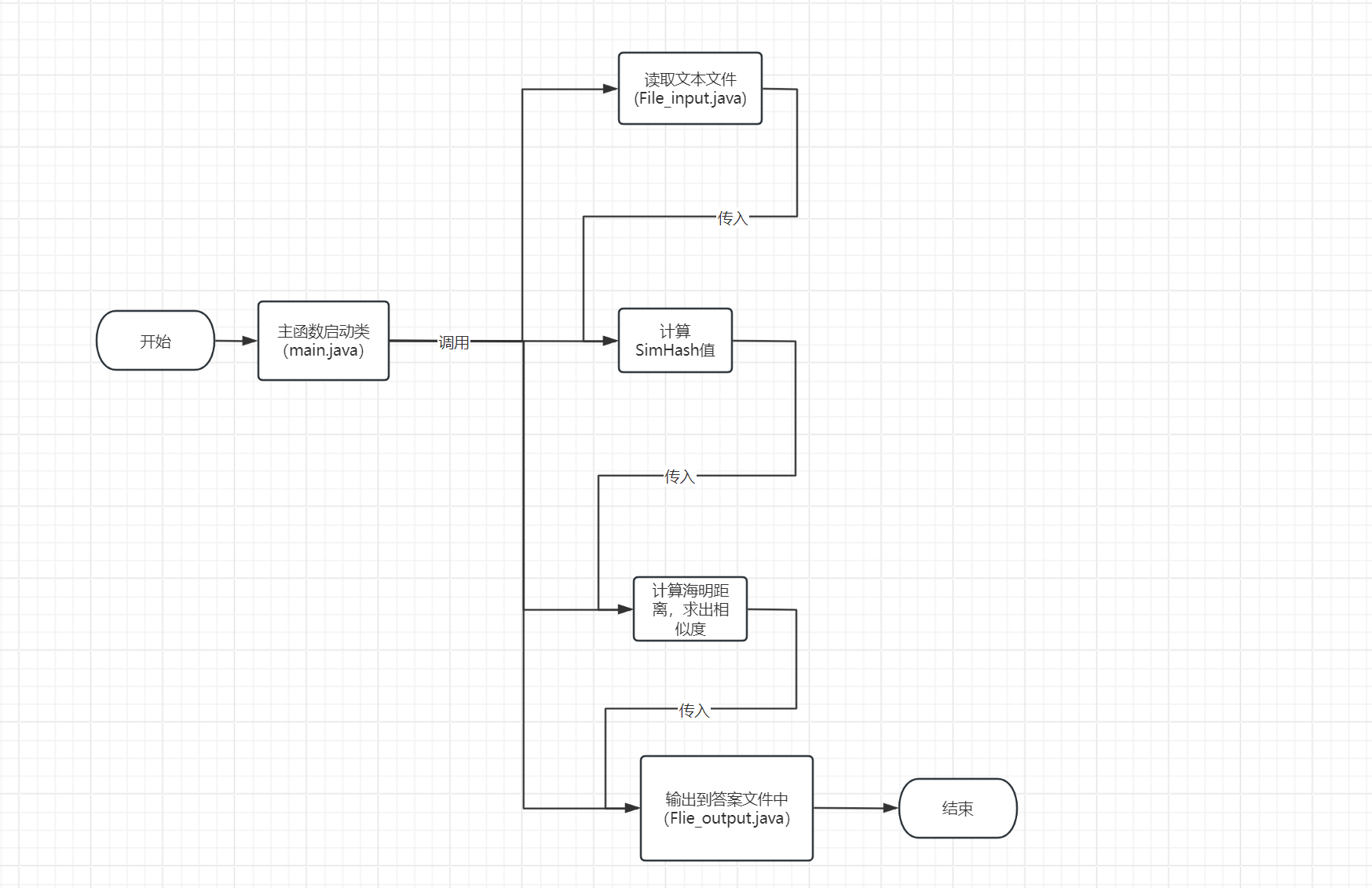
2.4项目的设计与实现过程(流程图)
2.5主要算法
①simhash算法:使用HanLP从文本中提取关键词,并储存在列表,遍历列表的关键词,使用MD5算法对每个关键词计算hash值,并对结果进行加权,与减权处理,再通过降维处理得到文本的simhash值。
实现代码:
点击查看代码
public class Calculate_SimHash {public static String gethash(String text){try {//首先创建对象,指定使用MD5算法MessageDigest messageDigest = MessageDigest.getInstance("MD5");//将字符串转换为UTF-8编码的字节数组,计算哈希值,以二进制字符串形式返回return new BigInteger(1, messageDigest.digest(text.getBytes(StandardCharsets.UTF_8))).toString(2);}catch (Exception e){//抛出异常throw new RuntimeException("操作失败",e);}}//设计方法——计算文本的simHash值public static String getSimHash(String text) throws Abnormal_TextShort {//验证文本是否过短,过短则抛出异常if(text.length() < 100) throw new Abnormal_TextShort("文本长度过短");//初始化整形数组作为特征向量int[] eigenvector = new int[128];//使用HanLP从文本中提取关键词,并储存在列表中List<String> keywords = HanLP.extractKeyword(text, text.length());int size = keywords.size();System.out.println("关键字的数量:" + size);int i = 0;//初始化一个计数器//遍历每个关键词,根据权重调整for(String keyword : keywords){//获取关键词的Hash值,并将其转换为一个对象//System.out.println(keyword);//System.out.println(gethash(keyword));StringBuilder keywordHash = new StringBuilder(gethash(keyword));//如果关键字的哈希值长度小于128,则在默末尾用0补齐if(keywordHash.length() < 128){int temp = 128 - keywordHash.length();for(int j = 0; j < temp; j++){keywordHash.append("0");}}//加权for(int j = 0; j < eigenvector.length; j++){//如果当前位是1,则根据位置进行加权,否则根据位置减权if(keywordHash.charAt(j) == '1'){eigenvector[j] += (10 - (i / (size / 10)));}else{eigenvector[j] -= (10 - (i / (size / 10)));}}i++;}//遍历特征向量每个元素根据正负值来构建转化为SimHashStringBuilder simHash = new StringBuilder();for(int element : eigenvector){simHash.append(element > 0 ? "1" : "0");//System.out.println(element);}return simHash.toString();}
}
②similarity算法:对于得到的两个文本的simhash值,计算二者的海明距离,并通过海明距离代入公式得到进计算相似度。
实现代码:
点击查看代码
package com.Calculate_Utils;public class Calculate_Similarity {public static int getHammingDistance(String simHash1, String simHash2){//设计方法——通过hash值来计算海明距离int Haiming_distance = 0;if(simHash1.length()!=simHash2.length()){return -1;} else {for(int i = 0; i < simHash1.length(); i++){//循环比较二者的字符if(simHash1.charAt(i) != simHash2.charAt(i)) {//遍历二者字符,如果不同,距离加一Haiming_distance += 1;}}}System.out.println("海明距离为:" + Haiming_distance);//输出海明距离return Haiming_distance;}public static double getSimilarity(String simHash1, String simHash2){//计算海明距离int distance = getHammingDistance(simHash1, simHash2);//通过海明距离计算相似度System.out.println("相似度为:" + (100 - (double)(distance * 100) / 128));return (100 - (double)(distance * 100) / 128);}
}
2.6异常处理
本项目对三种异常进行捕捉处理分别为:
①读取和写入文件发生错误的异常。
②提供路径参数小于三个(即原文件,抄袭文件,答案文件)的异常。
③输入的文本过短的异常。
3.项目类测试
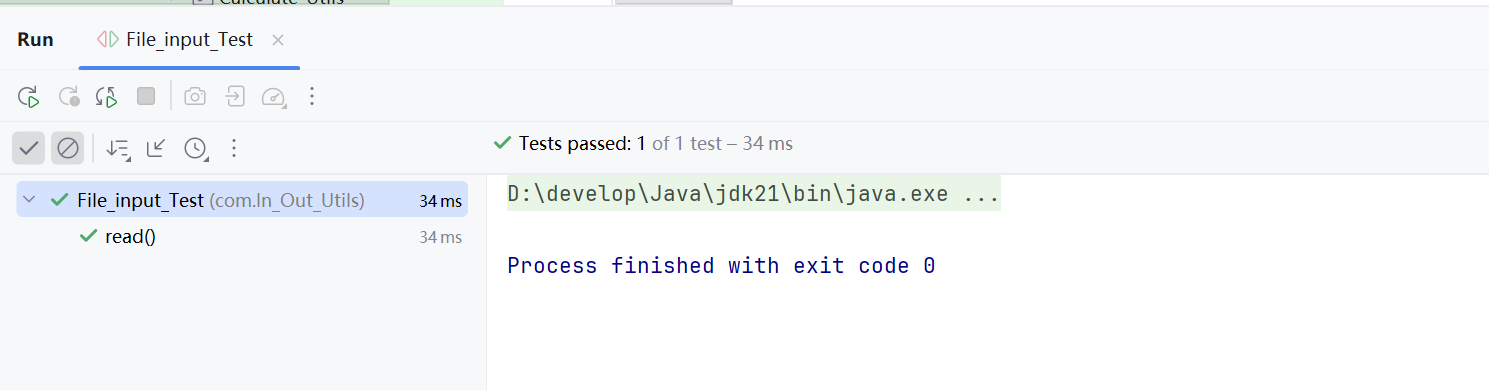
3.1读文件File_Input.java的测试
测试结果:
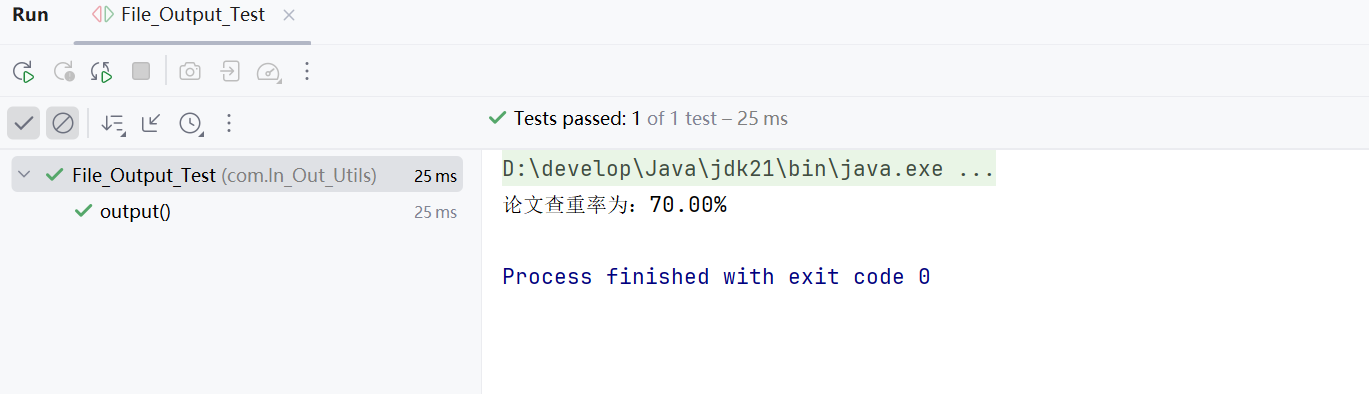
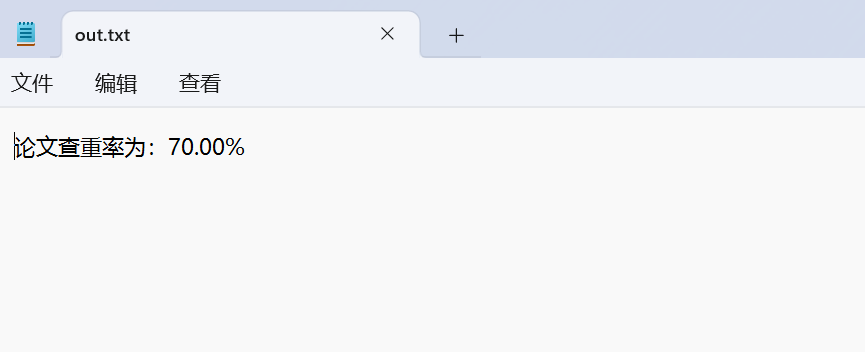
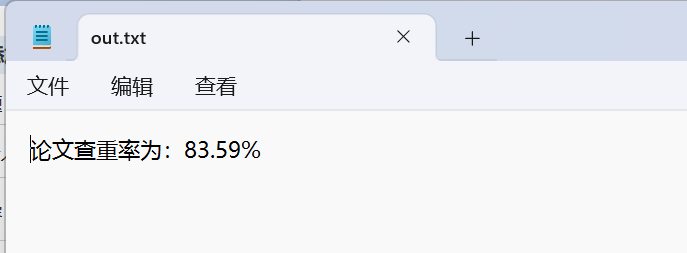
3.2写文件File_Output.java的测试
测试结果:
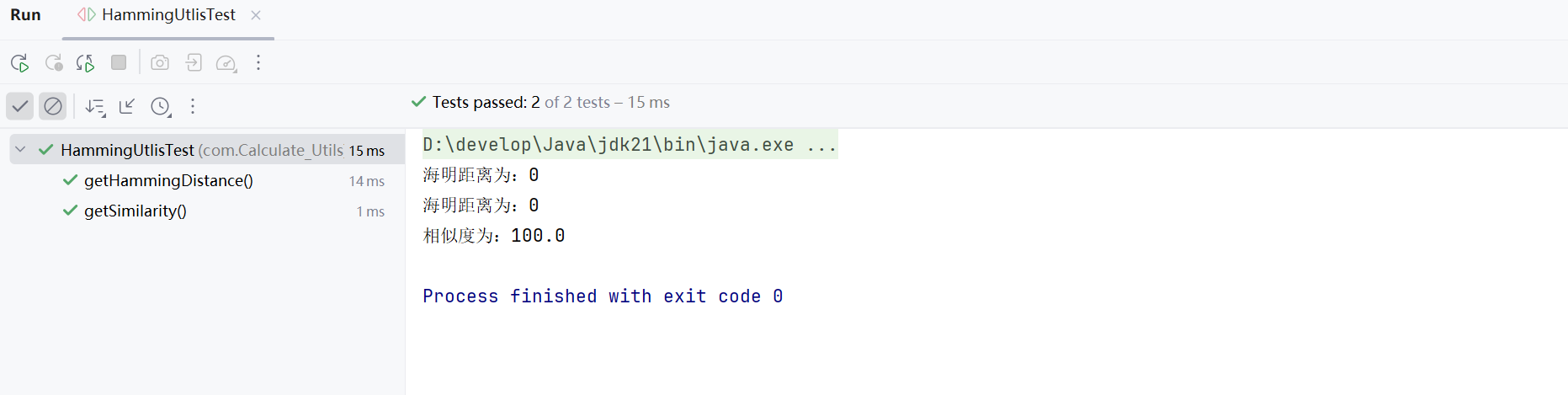
3.3simhash算法的测试
测试结果:
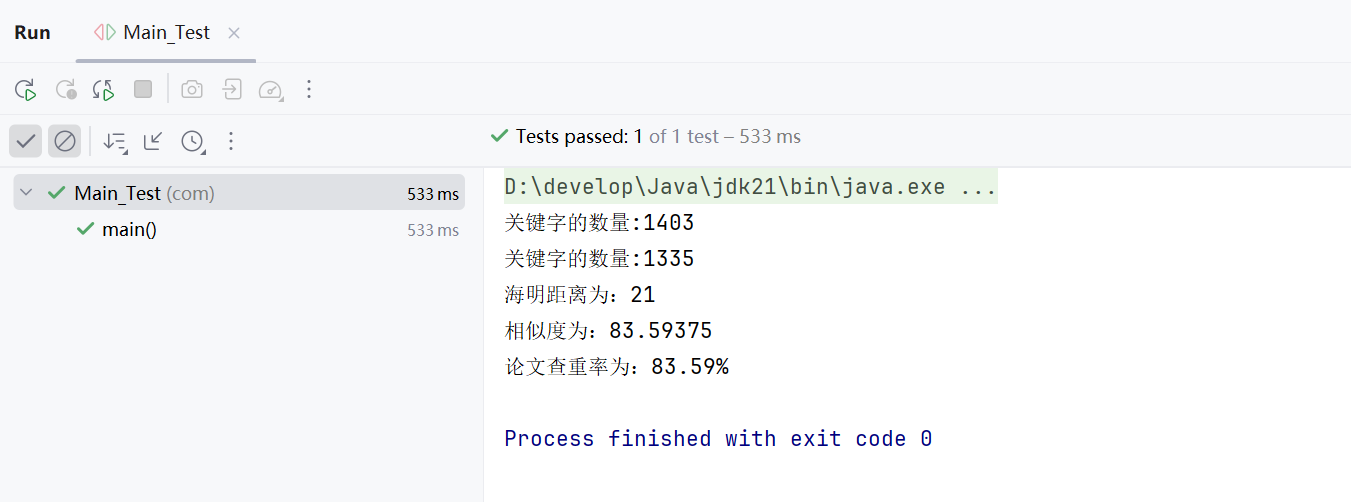
3.4主函数main.java的测试
测试结果:
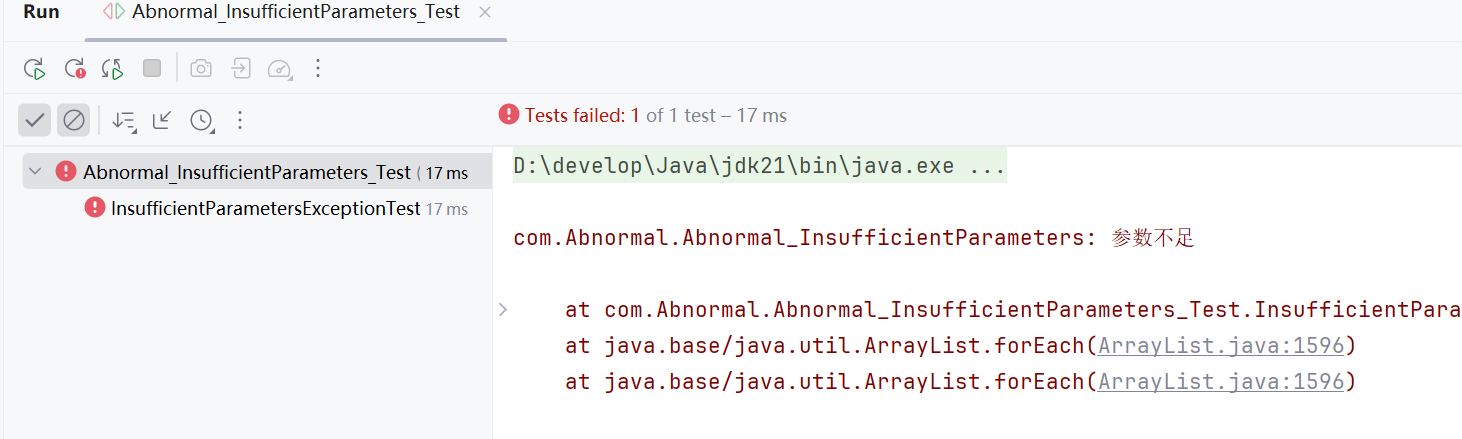
3.5传入的参数过少的异常测试
测试结果:
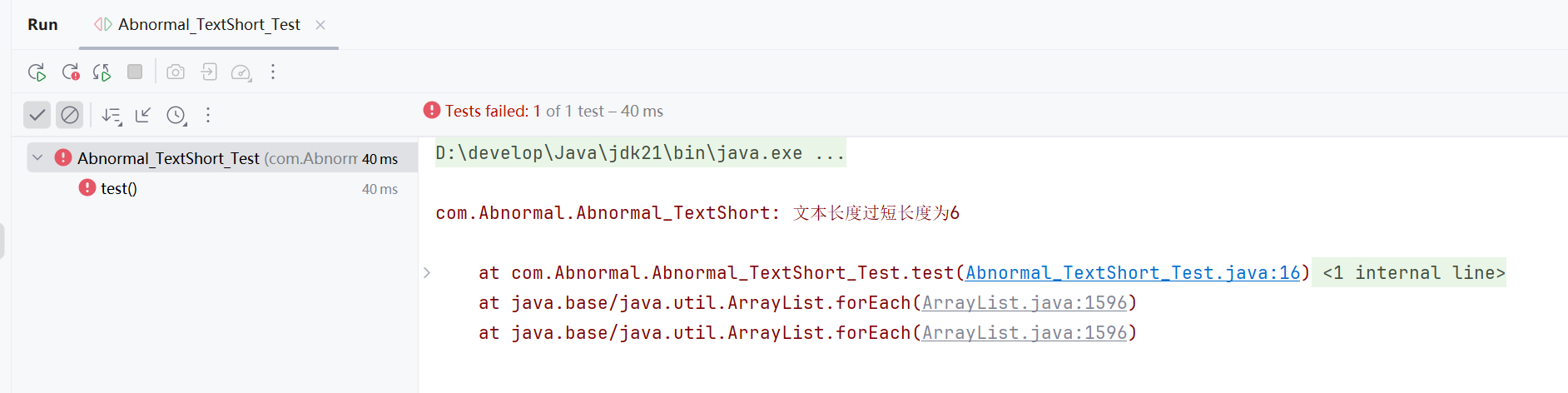
3.6文本过短的异常测试
测试结果:
3.7文件不存在的异常测试
测试结果:
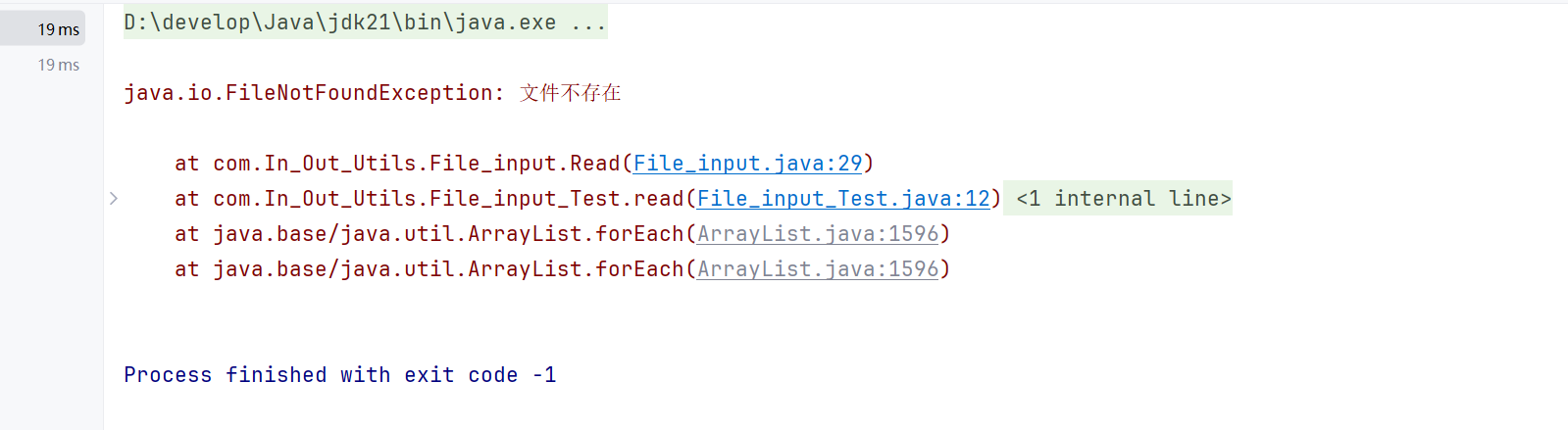
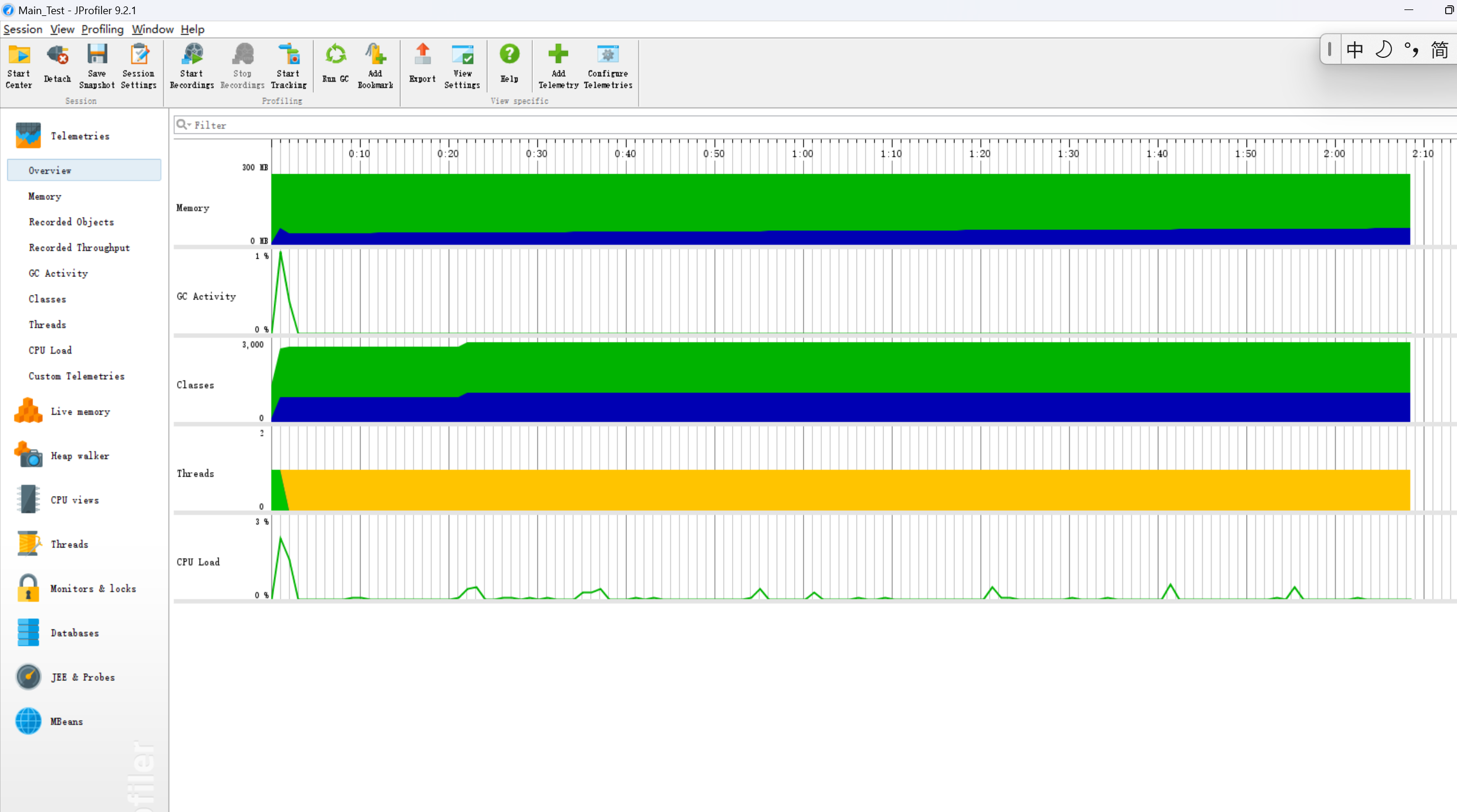
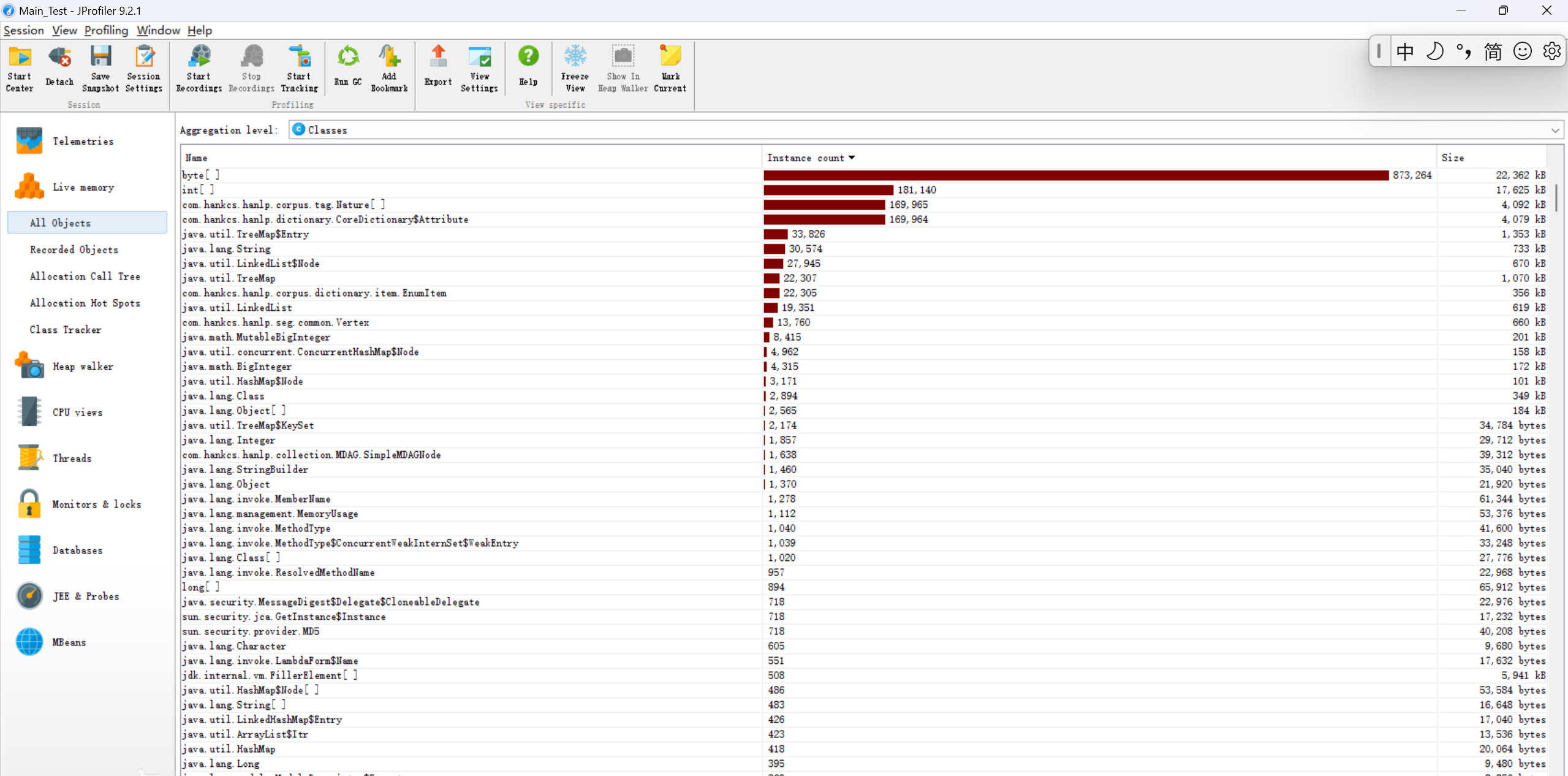
4.性能分析(本项目采用了JProfiler来分析)
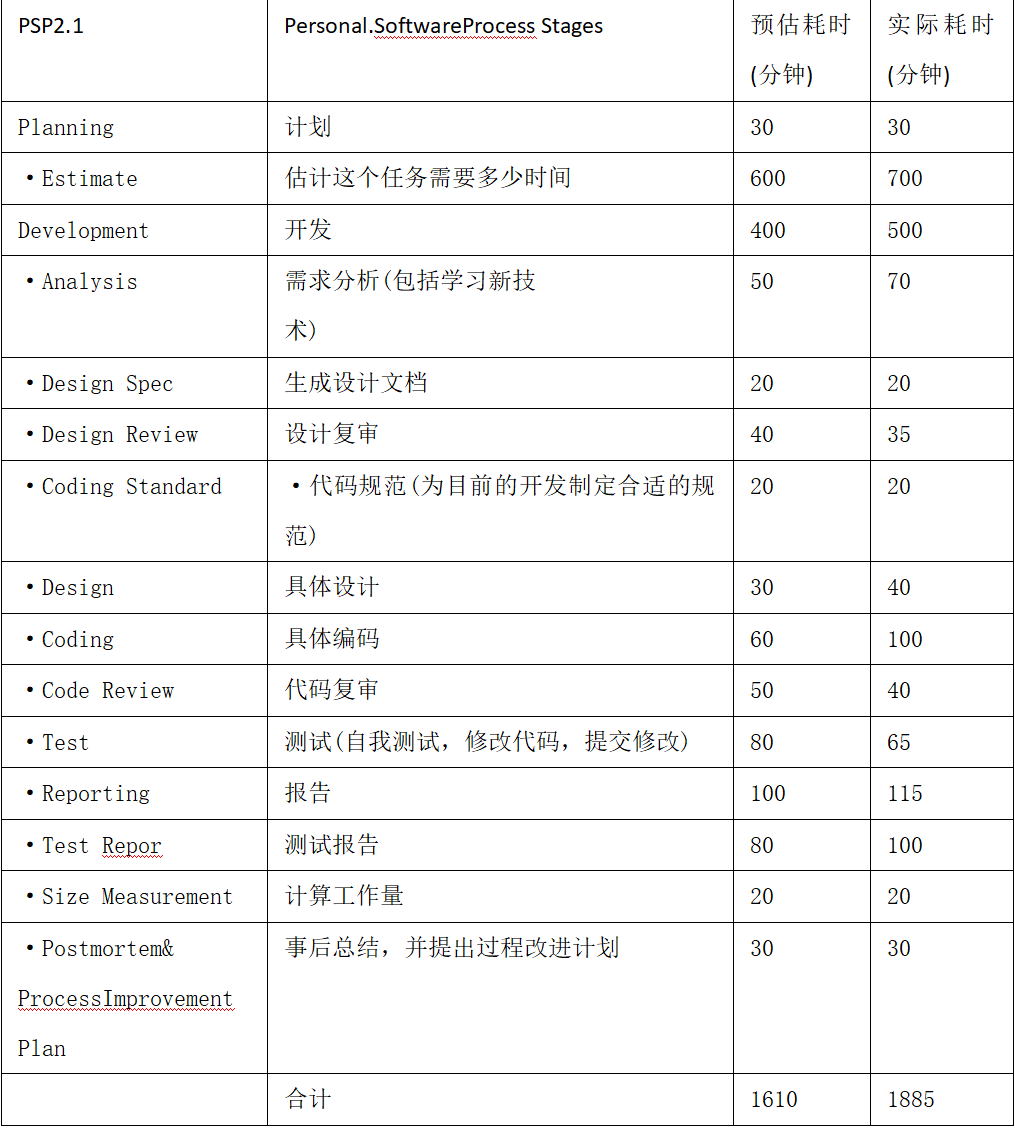
5.PSP表格