这是我参与创作者计划的第1篇文章
我叫艾佳,工作经验14年,编程经验30年。
我来自智能平台部,负责标签平台、标签圈人、标签选品、EasyData、算法数据流的架构工作。
致力于批量计算、流式计算、交互式计算的通用化数据应用构建,降低大数据计算的使用门槛。
在此,我跟大家分享一下我的个人经历和一些思考。
好玩儿
成长经历,说来话长,有多长呢?
上世纪80年代末,我参与了计算机输入指令的归一化:把穿孔纸带卷起来,当然也包括把它们搞乱。
那一年我6岁。
上世纪90年代初,我计划购入一台自己的计算机。
NES拥有8位处理器,很流行;不过我没有买它,倒不是因为日本进口比较贵,而是因为它主要擅长图形处理,机身红白相间,大人们都管它叫“游戏机”,预算审批不通过。
最终我申请购入一台Subor计算机,同样是8位处理器,可以学习打字,可以编程,中文品牌名叫小霸王,它当然不能是“游戏机”,它叫“学习机”,所以预算审批通过。
1994年,我用上述“升级版游戏机”写下了人生第一段代码,语言是BASIC,语句前面需要手写行号。
当时我上小学。
高中的时候,语文老师在上面讲课,我在下面看杂志:《微型计算机》,借同学的,他那一年12期我都看过。
后来同学攒动我和她组队参加网页设计大赛,她可以借我相关书籍。
1998年,我在学校机房设计了人生第一个网页,使用 Dreamweaver + Fireworks + Flash。
大学的时候,我并没有学计算机,主要是报志愿的时候,爸妈认为计算机毕业就是修电脑。
入学之后,我加入学生会科技部,协助搭建学院网站。
英语课的时候,我在下面看PHP书籍;我还用自己的电脑练习安装红帽Linux和MySQL。
2002年,我给学院搭建的网站面向公网开放。
研究生的时候,我难逃宿命,进入软件学院学习;某公司招聘实习生,现场面试,我和另一个女生一起去PK。
面试官问:“请说说你对JavaScript的理解?“
那个女生抢先回答”我平时会写一些Java程序。“
面试官一皱眉,看看我。
我把前一天晚上刷完的Ajax理论洋洋洒洒一说,搞定了。
2008年,我们写了一个3万行代码的JavaScript文件,在客户的机器上运行,那时JS还没有模块化机制。
2010年,我用C++实时求解偏微分方程组,完成了即时动力学仿真,最终得以毕业。
那时C++的下一代ISO标准叫 C++ 0x,谁知道最终2011年才搞定,最终定名 C++ 11。
成为你自己
武志红在他的心理学课中提到:人生的意义,在于成为你自己。
真正的架构师
工作三年后,我出差上海,我们为日本最大的银行交付解决方案。
当时,客户的交易系统,还是上个世纪的基于命令行的设计风格。
我们本次的任务就是将其升级为本世纪的基于网页的设计风格。
银行方面也有好多关联公司,为其交付存款、贷款、信用证、保理等等业务模块,我们公司的职责就是开发一个框架,让各个业务模块可插拔的加载到框架中,这就要求整个框架不能为某一个单一业务编写定制化的逻辑,要做到业务无关,这样才能适用于各个业务模块。
框架的架构设计,形成了好多架构决策,负责业务模块的关联公司经常来挑战这些架构决策。
我做为助理架构师,需要解答他们的疑问;最开始,我能唯一能做的,就是跟他们解释,这是主架构师定的,我也不知道他为何这样定;到后来,我觉得这样很丢脸,我只是一个传声筒,我的存在并没有价值。
后来,对于主架构师的每一个决定,我都会首先自己独立思考,为什么用这种方案而不是另外一种方案。我自己挑战自己,自己得出一个逻辑严谨的推理过程,并把疑问点记录下来。最后,我会拿着我的逻辑找主架构师求证,并提出一些疑问。终于有一天,我可以根据我的思考,独立回答关联公司提出的疑问,应对他们的挑战。
项目庆功会,觥筹交错,我给主架构师敬酒。
他说,小伙子不错,你是第一个挑战我的人。
那一刻,我觉得,我开始做我自己了。
那一刻,我觉得,我开始做真正的架构师。
业务无关
后来我出差昆明,为某能源公司交付解决方案。
这种企业服务的特点就是,客户是真金白银买你的解决方案,但是他要满意了才付钱。客户付钱了项目才有收入,不付钱项目收入就是零。然后公司会对每一个项目的收入和支出进行核算,人力成本会精确计量。成本大于收入,那这个项目就是赔钱的,这个项目就是失败的。
很快,我们组建了项目组,凑齐了项目经理、产品经理、架构师、主研发、主测试,分别是我我我我我,没错,都是我,就是我,就我一人儿。项目失败了是我的问题,产品设计让客户不满意是我的问题;技术无法落地是我的问题,技术落地了有很多缺陷还是我的问题。
昆明招人真是太难了,真是太难了,太难了。我费了九牛二虎之力,招来了两个小哥和我一起写代码,其中一个小哥是彝族的,代码写的还行,不过彝族左脚调跳的更带劲。无论从预算还是人力角度,这个项目的资源就是严重受限的。客户的需求,是要接入多个风格迥异的业务系统,如果每个系统接入都定制化开发,那工时会很多,成本会爆仓,项目会失败。所以,我就琢磨,如何将架构设计成业务无关的,也就是通用的一套架构,跟各个接入方约定好统一的接入方式,通过配置化,来弥合业务之前的差异。
2014年,给客户开发的系统上线了,是我独立设计的,基于配置化的系统。
后来,由于业务无关,快速接入,此能源公司的多个分公司,包括总部,都看好了这套系统。各分公司陆续接入,人力自然无需增加,收入却在持续增长,项目的财务数字很漂亮。
尚未踏入的世界
法国作家普鲁斯特,在他的代表作里写到:
唯一真实的乐园是我们已经失去的乐园,唯一有吸引力的世界是我们尚未踏入的世界。
大数据入其门
孩子大了,我也不能一直各地出差,到处跑;经过努力,我最终回到了北京,做北京的项目。
我们的任务是给一个大企业搭建员工报销系统,用户数量30万,每人可能不只一张报销单,那么评估下来,单表的记录数可能超过百万。当时的MySQL版本比较低,单表容量超过百万之后性能急剧下降,所以我们需要调研各种分库分表方案。当时的分库分表方案,和SSH这种通用的ORM框架不是很兼容,很多场景需要我们定制化的手写SQL来达到业务目的。
一期上线,解决了业务的问题;后面,客户又提出了报表的需求,那么SQL当中不可避免的要有 sum 或者 count 这些聚合的操作,分表的话,自己需要处理各个分片之间的聚合关系,挑战也很大。
其实问题的本质就是,如果将数据分割,分别计算,再合并,还是分治的思想。
我隐约觉得,需要学习一些大数据技术了,于是我在满足业务需求之余,废寝忘食地刷英文原版书籍,Hadoop、Spark、HBase、Storm…… 还在自己的个人电脑上搭建环境来练手。整体感受是,大数据技术是个好东西,它可以代替你对数据进行分割、分别计算、再合并;自己就不用通过分表等方式手工分割,也不用操心计算结果合并的问题了。
我按照大数据技术的思路提出报表系统的未来规划,向客户兜售。
客户的反馈很实在,也可以理解:“我们国企不需要什么先进的技术,我们需要求稳;此外,你们项目上线后是要交给我们的人维护的,我不相信我们的人能维护好。“
我突然惊醒了,可能这就是我接下来职业生涯的状态:不需要什么先进技术,求稳。
2015年,我离开了这家世界知名外企,去了一家初创公司,因为他们需要大数据技术。
云计算是被迫的
初创公司落定,手里握着10亿独立的手机MAC地址,而且有这10亿个体的标签和画像,保存在HBase中。HBase是个好东西,不需要关心分库分表的问题,而且数据在各个分片上重新均衡,也无需用户接入。马上,新的挑战就来了,数据还在持续增长,预计到年底将会增长到20亿,存储急需扩容。公司的HBase,是运维同学在裸机上手工安装的。我说,能不能看看现在机器的情况,然后运维同学给了我一把钥匙。
等等,一把钥匙?
他说对,咱们办公区你往那边走,小仓房隔壁有个防盗门,你不是问机器情况么,那里面就是。
打开防盗门,屋子很小,只有两个机柜,其中只有一个机柜上面有机器,刀片机的指示灯交替闪烁;由于网络组件经常有故障,所以不能稳定的远程SSH,所以接下来我要经常来这个小黑屋。
我给内存条拍了照,按照它上面的精确的型号,在京东上买内存条;到货之后,二十多根崭新的实物内存条攥在手里,现在想想还真有点儿赛博朋克呢。
借助京东商城,我们扩容完成,手机MAC数据也的确增长到了20亿,存储搞定了。
别急,新的挑战来了,现状是用 Java Worker 定时计算读写 HBase,随着数据量增长,上游一天产生的数据,我们可能一天都算不完。是时候展示真正的技术了,我手里攥着的Spark技术终于可以登上舞台了。通过使用 Spark 代替 Java Worker,我们使计算周期减半,并且可以更方便的解决扩缩容和数据倾斜问题;“一天的数一天算不完“ 的危机终于得到了化解。
2016年,我们实现了 Spark 直接读取 OSS 上的parquet文件进行计算,很像现在的数据湖的思想。
别停,挑战继续。我们手工在物理机上维护 Hadoop、HDFS、HBase、Spark 等等组件,今天这台机器出问题,明天那个软件有问题,这大数据的可用时间也不长啊。团队一共不到十个人,每天解决大数据运维的问题,根本抽不出来时间做业务需求了。
老板说,我有一张阿里云打折卡,你们要用么?
要用,要用,你咋不早说。
经过精确测算,量化存储计算成本和人力成本,上云后的成本更低,我们说服了高层全面转向云计算战略,这次我们就不用担心运维的问题了,以更低的成本将这一部分工作外包了出去,我们可以专注做业务需求了。
长夜无梦。
当时《程序员》杂志还未停刊,那我是每期必读啊。看着互联网的大佬们,针对如何应对双11和618的大促,侃侃而谈,流量动不动就是几百万几千万,如何压测的,如何限流的,可真是。那感觉就像听加勒比海盗讲述,他们手里紧攥着藏宝图,驾船穿过凶险的激流,攫取心目中的宝藏。
“佳哥你这大数据架构师不是做的挺好的么,为啥要走啊?再说了,你的期权还未兑现,走了可就都打水漂了。“ HR小姐姐在微信上问我。
“许巍的《完美生活》送给你:青春的岁月,我们身不由已;只因那胸中,燃烧着梦想。“
青春的岁月我们身不由己
整个人都精神多了
如愿加入了A记互联网公司,刚开始用钉钉还不太习惯,我老板钉钉的个人签名上写着:“得了精神病,整个人都精神多了“,我想这个老板可真是……深不可测啊。
2017年加入公司时,有一个金融风控引擎,底层使用MapReduce来完成计算的。如何描述计算步骤呢,每一个计算任务都会对应一个超级长的XML,来描述都从哪儿读取数据,中间如何过滤和变换,最终又写到哪儿。针对单条数据,这个引擎工作的很出色,尤其是大量的分支判断可以很好的表达,但是当涉及到大量表关联,大量聚合的时候,编写多个Mapper和Reducer串联就很费事儿了。
这都什么时代了,为什么不用Spark做呢?说干就干,我自己将离线引擎使用Spark重写。为了能够适应业务场景,我访谈重要的业务方,将多种多样的真实需求通过新引擎模拟运行。至此,金融风控引擎的计算周期大幅缩短。
接下来要搞定的就是实时计算部分,当时的状态是,实时计算,即使是分析型的预计算,也是Java Worker 来实现的,每个业务定制一个Java应用。与此同时,大部门又是偏向银行业务的部门,要求核心人员考取银行执业证,对新技术并不是很重视。
当我拿着我的基于Flink的实时计算方案,给老板讲解新的风控引擎的时候,
老板问我:“Flink 是什么?“
我说:“后会有期。“
2020年,独角兽传出上市消息的前夕,我怀揣着大数据的梦,毅然离开了A记。
朋友说:“你是不是神经了,财富自由的机会你不要了?“
我说:“是神经了,感觉整个人都精神多了。“
大促像过年
入职京东的第一天。
我问HR,开车来的话,停哪儿呢?
她说,公司的地面停车场在施工围挡里面。
虽然车位也不少,但是如果你来的比较晚的话,也没有位置,只能停到更远的4号楼。
我早上开车上班,到这儿一看,嚯,还真是,排队进场,提前一个路口就开始排了。
这难道是排队领饭票呢?现在想想,还真是。
入职的是数仓团队,他们最头疼的就是,业务方不仅要算数,还要用数,需要各种API来访问。数仓的数据加工,我们团队倒是不在话下,就是API开发可是很让人苦恼,因为在数据开发工程师里面非得挑几个Java开发工程师也不容易。就这么几个人,还得为每个业务定制化开发接口。我们能不能开发一个通用的平台,一劳永逸呢?翻看了业界各家的方案,包括A记的,都不是我想要的;我屏住呼吸,闭目冥想,做成什么样儿才是心目中的理想方案呢?对,就做成那种一贴SQL,就得到API的极简方案,把其他所有复杂的过程都砍掉。
入职以来经常停的那个地面停车场,不能用了,因为公司要盖楼。我在凯恩帝5层,看着路对面的停车场旧址上,领导们放炮、剪彩、培土、奠基,后面挖掘机就开始挖坑了。坑挖的大大的,有五层楼那么深。人行道旁有绿色的围挡,从凯恩帝到1号楼就得沿着围挡和马路之间的窄路慢慢走。
这一天,我和往常一样,沿着窄路慢慢走;这一天又不一样,此时不是早高峰,也不是晚高峰,但是总部附近车水马龙,川流不息,挤挤挨挨;有小推车推着食物的,有布置张灯结彩的,有拍照打卡的,那场面,感觉就像过年。
我拨开人群,挤入转门,穿过白色大理石地面的大堂,朝一间特别的房间走去。越走人越少,最后来到一道磨砂玻璃门前。刷卡之后,两扇长方形玻璃门向两侧徐徐打开。我走入房间,房间很大,但是灯还没开。房间的一整面墙是一整块大屏幕。屏幕上的数字,静静地跳动,一直跳动。灯开了,其他人来了,它仍然在跳动,一直跳动到午夜。
2021年,618,京东成交额几千亿。
各个媒体的战报报道,都从这块大屏发出。
这里面有数仓团队的辛勤付出,有大屏团队的夜以继日,当然也有EasyData工具的一份贡献。这个工具,就是前面提到的那个 “一贴SQL,就得API“ 的工具。大家用它贴了几百个SQL,得到了几百个API。
整体论与还原论
还是在凯恩帝,这一日是工作日,午后时光,保洁阿姨跟我说,这一层就我一个人。
索性,来到落地窗边,盘腿坐在地毯上;几张纸,一支笔,让阳光洒在纸上。
如何能把数据流做好呢?如何能让做出来的工具有人用呢?我们做出的工具一定是用来提升效率,要么是运行效率,要么是开发效率;运行效率的事儿,Apache的那帮人已经玩儿的透透的了,我们能做的可能是要提升设计开发效率,也就是“设计时“平台,而不是”运行时“平台。
我在纸上写写画画,推演设计目标,阳光在方形玻璃器皿内折返多次,那是一杯咖啡色的咖啡。
对面的3号楼,地基打好了,坑填上了,超过了地面,拔地而起。
大数据调度已经有了“任务流“,我们为什么还要做”数据流“呢?把工作流重做一遍,比比谁做的好吗?”任务流“ 是指令的流转,一个任务节点完成了,告诉另一个任务节点应该开始了,节点之间并不进行数据交换。而 ”数据流“,是希望整个分布式数据集在节点之间流动,而不仅仅是控制指令。
最近运气不错,我家的疫情等级一直很低,所以我是这一层唯一可以入场的人,包场办公。
把数据集当成整体看待,在日本作者写的《SQL进阶教程》中,把这种思考方式归为“整体论“,数据集是一个整体,可以计数、求和、交并差;所有面向SQL的数据技术,都是把数据当成一个整体看待,例如JDBC标准里,规定了 ResultSet;再比如 Spark 里面有 DataSet,都是把数据当成整体集合看待。甚至,当数据大到无法放到一台计算机中时,Spark等大数据技术做出了巨大的努力,在物理层面来管理数据在各个节点上的分布。为的是,从逻辑层面来看,数据还是一个整体,还是一个数据集。以上这是”整体论“。
跟“整体论“的思考方式相对的,是”还原论“,认为把每一个个体处理好,整体也就搞定了,可以还原出整体。在”大数据“概念出现之前,好多场景的数据是可以放到单台机器里的,不行就上小型机,再不行上大型机,反正我要一台机器搞定。原来的好多业务处理逻辑,例如对在线交易的处理,都是面向请求的,一个客户(Client)发出了请求(Request),我们如何服务好他(Server),然后给他及时的响应(Response)。进而,后来的Web应用,无论什么语言编写的,也都是假设如何处理好一个请求。当然,请求除了 HTTP 请求,还有消息等形式,为了应对这些请求,编写各种 Handler / Worker。以上这是 ”还原论“。
本次要设计的数据流,流入流出的都应该是一个数据集,秉承“整体论“的思想。整个数据集在DAG图上流动,可以聚合,可以关联。
对了,这不就是 Spark/Flink 做的事儿么;但现在问题是,这些技术还是有一定的技术门槛的,我们如何让算法工程师、软件开发工程师甚至产品经理都投入到大数据的革命洪流中来呢?必须进一步降低门槛。如果在“设计时“,也就是计算任务上线之前,在开发的时候就看到数据流转的图形就好了。进而,这个图形不只是用来看的,还可以编辑,可以拖拉拽,拖一个输入算子,几个处理算子,几个输出算子,数据加工的逻辑就搞定了。编辑好的图形直接发布线上就能运行,不用写代码,不用知道什么是Spark,那可太棒了。
2022年,“算法数据流“ 上线到dp.jd.com,用户自己累计编写了数据流4000多个,目前周增长2.4%
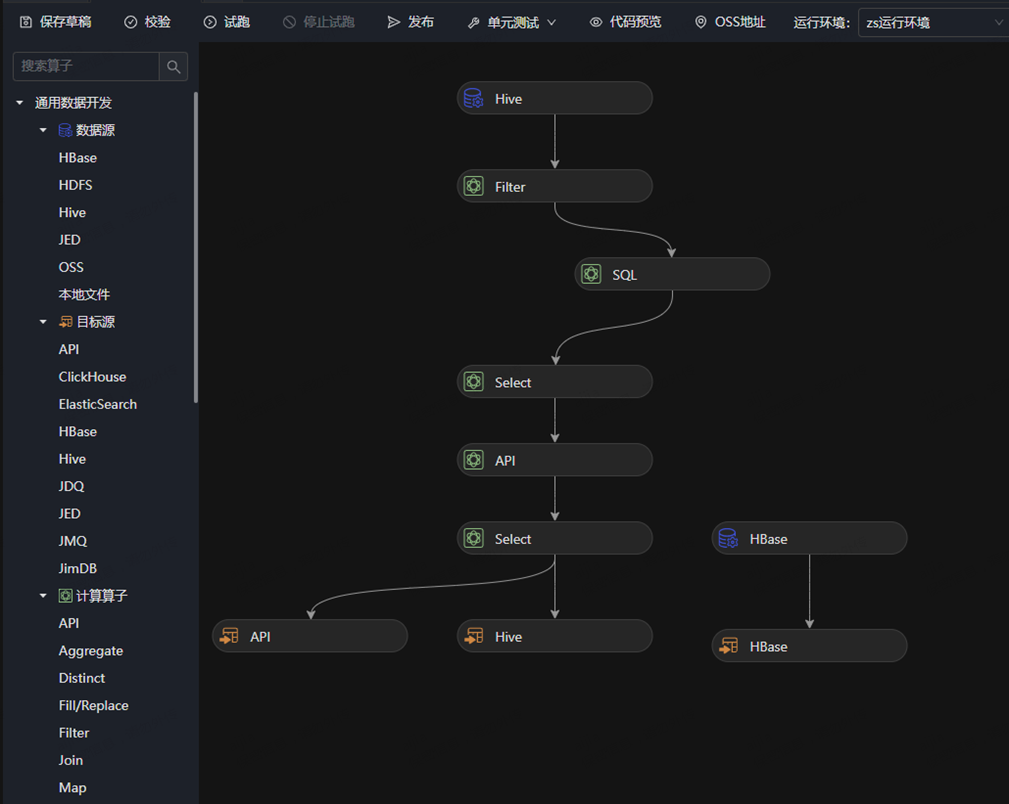
批量计算示例
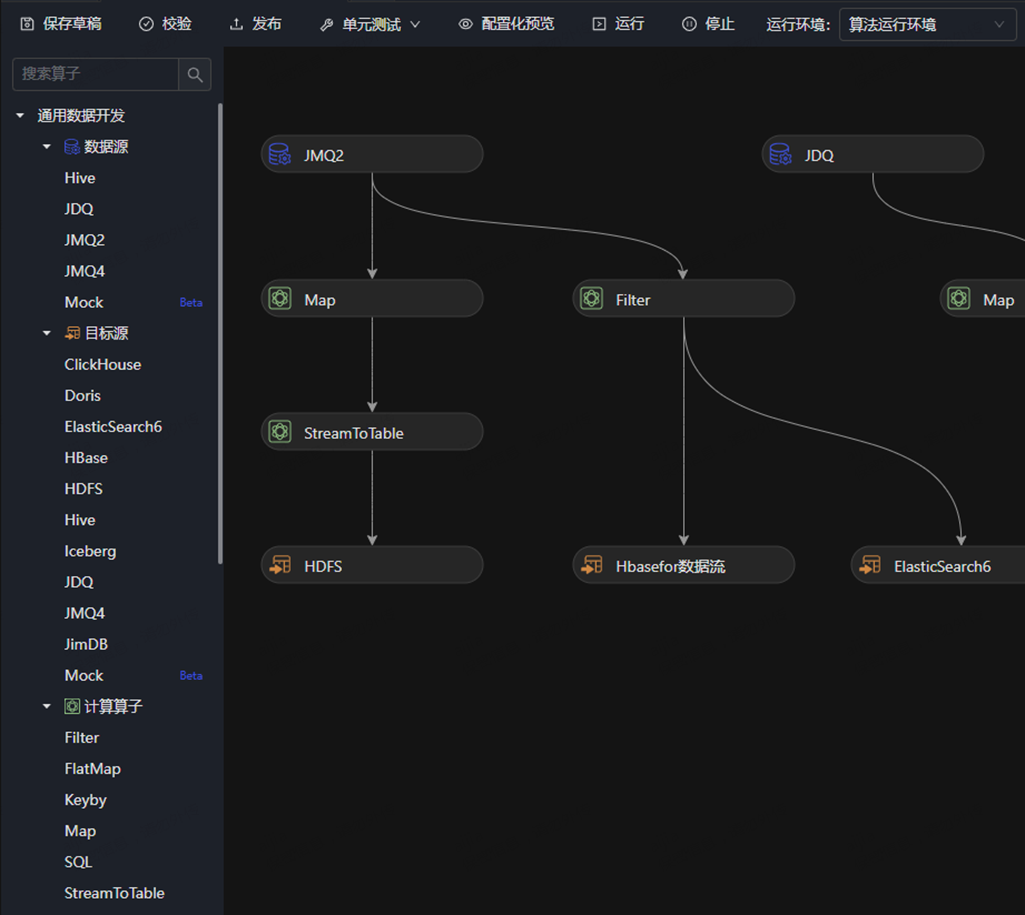
流式计算示例
百亿货大楼
3号楼封顶了,京东总部现在有1/2/3/4号这么多楼。
上个世纪,中国出现的百货大楼,虽然货品不只几百种,但也不会特别多。
京东的楼,我想叫他百亿货大楼。
这个量级的货,我们全塞到总部么?不可能。他们分布在全国不计其数的仓库中,甚至还只是躺在设计师的图纸上,就等有人点击那个购买按钮,从纸上再跳下来。
这么多货,组织一个618活动啥的,让谁上场呢?几百亿记录一页一页的浏览,最后都浏览成骨灰级玩家了,肯定不行。那就需要遴选出一批货品,参与某一个活动。怎么选呢?从不同角度给各个商品打上标签,例如有些是新品,有些是露营场景,有些是应季商品。然后再通过选择不同的标签组合,进而遴选出不同的商品,来去契合本次活动的主题。
那你说这个事儿离线计算能不能做?可以做,Hive / Spark 写SQL跑数就完了。但是这种方式,用户不能“在线等“,系统只能告诉用户:”您别着急,我得算一会儿,您先忙着,我好了告诉你“。用户说那不行啊,我选了标签ABC,计算结果不满意的话,我还要换成标签BCD再试,我要再试,反复试,一直试,一直到我满意的哇。所以”离线“还不行,还得满足用户”在线等“,进而,用户反复改变输入,反复观察机器的输出,这样就跟机器形成了一个互动,这种计算模式也就称之为”交互式计算“。
交互式计算,最典型的就是使用OLAP技术,在线分析处理,使用 ClickHouse 或者 Doris 等数据技术,把筛选需要用到的各种标签,都放到一张表里,跑SQL。随着标签越来越多,那这张表的列也会越来越多,这张表就会越来越宽,同时,计算周期也会越来越长,长到用户无法接受。
怎么办呢?
得拆表,每个表不要有那么多列。
按照什么粒度拆呢?
按照业务场景拆。
拆出来的小宽表叫底池,每一个底池对应一个业务场景,例如打新的场景,例如招商的场景。那每一个场景里面,都会用到哪些标签选品,业务、产品、研发是有共识的,是有相对确定的,标签数量可以限制在一个合理的范围内。“底池“这个概念,是做选品的先贤们想出来的,我觉得很好。
3号楼最终交付使用,正式命名为1号楼DEF座。
夜幕降临,华灯初上。
楼体外部流动的灯火,是能量流。
楼体内部流动的数据,是信息流。
中华大地上奔跑的货车,是物质流。
熠熠之辉,煌煌之炬。
昨天今天明天
总结昨天。
活在今天。
展望明天。
建筑设计师
软件架构师,Architect,实际和建筑设计师,是一个英文单词。
你说建筑设计师会不会搬砖?他肯定会。
那你说我会搬砖,我砖搬的好,砖搬的快,我会不会成为建筑设计师?那不一定。
建筑设计师会告诉你,建筑的骨架是什么样的,如何受力的;哪面墙是承重墙,一定不能砸。
当然,最基本的土木工程、建筑技术,那建筑设计师一定要了如指掌。
其实软件架构师类似。
最基本的编程技术、数据技术,不仅要精通,还需要灵活应用。
除此之外,需要知道系统是如何承压的,系统的核心链路是什么。
开发之前,需要先进行系统设计,让系统先在纸面上跑起来,各个场景都不会有逻辑漏洞。
设计之前,需要先确定设计原则,设计是基于哪些假设的,例如系统运行的前置条件是什么。
其实最重要的,就是要独立思考,要挑战自己;多构造一些边缘场景,来验证系统是否可以应对。
形容词
有一种价值观,认为事物的价值可以分为真、善、美。
真,真实,事实判断,这一项是机器擅长的,不仅可以判断此时此地的事实,而且可以同时判断多个空间,多个时间的事实。
那什么是善?什么是美呢?
古人曾以胖为美,今人以瘦为美;爱吃萝卜的,以萝卜为美食,爱吃白菜的,以白菜为美食。
“美“、”好货“、”高级货“、”潮牌“,所有这些形容词,都是主观的。主观的意思,就是它们都是人类对于客观事物的感受,而且是因人而异的。
机器可以感受吗?机器没有感受,他不知道什么是善,什么是美。
童话《绿野仙踪》里的铁皮人,没有心,这其实就是一个隐喻。
虽然人类做为老师,可以教它,可以教机器如何学习人类的这些感受,如何做一项价值判断。但这些感受,这些价值判断,也只是为了适应人类的感受,人类的价值判断,不是机器自己的。
不知美丑尚可,不知善恶就危险了。
尽管现在有层出不穷的算法模型,但是各大公司始终会制定一系列的规则。
这些规则是从人的角度发出的思考,用来监视机器,并对机器设定底线,使它“不作恶”。
卓别林在电影《大独裁者》最后,有一段演讲,截取送给大家。
Don’t give yourselves to these unnatural men
- machine men with machine minds and machine hearts!
You are not machines! You are not cattle! You are men!
You have the love of humanity in your hearts!
You, the people have the power
- the power to create machines.
The power to create happiness!
You, the people, have the power
to make this life free and beautiful,
to make this life a wonderful adventure.
来
为公司创造价值,为社会创造价值,那是必须的。
最初入行觉得信息技术很酷;对层出不穷的新技术,求知若渴。
希望自己不忘初心。