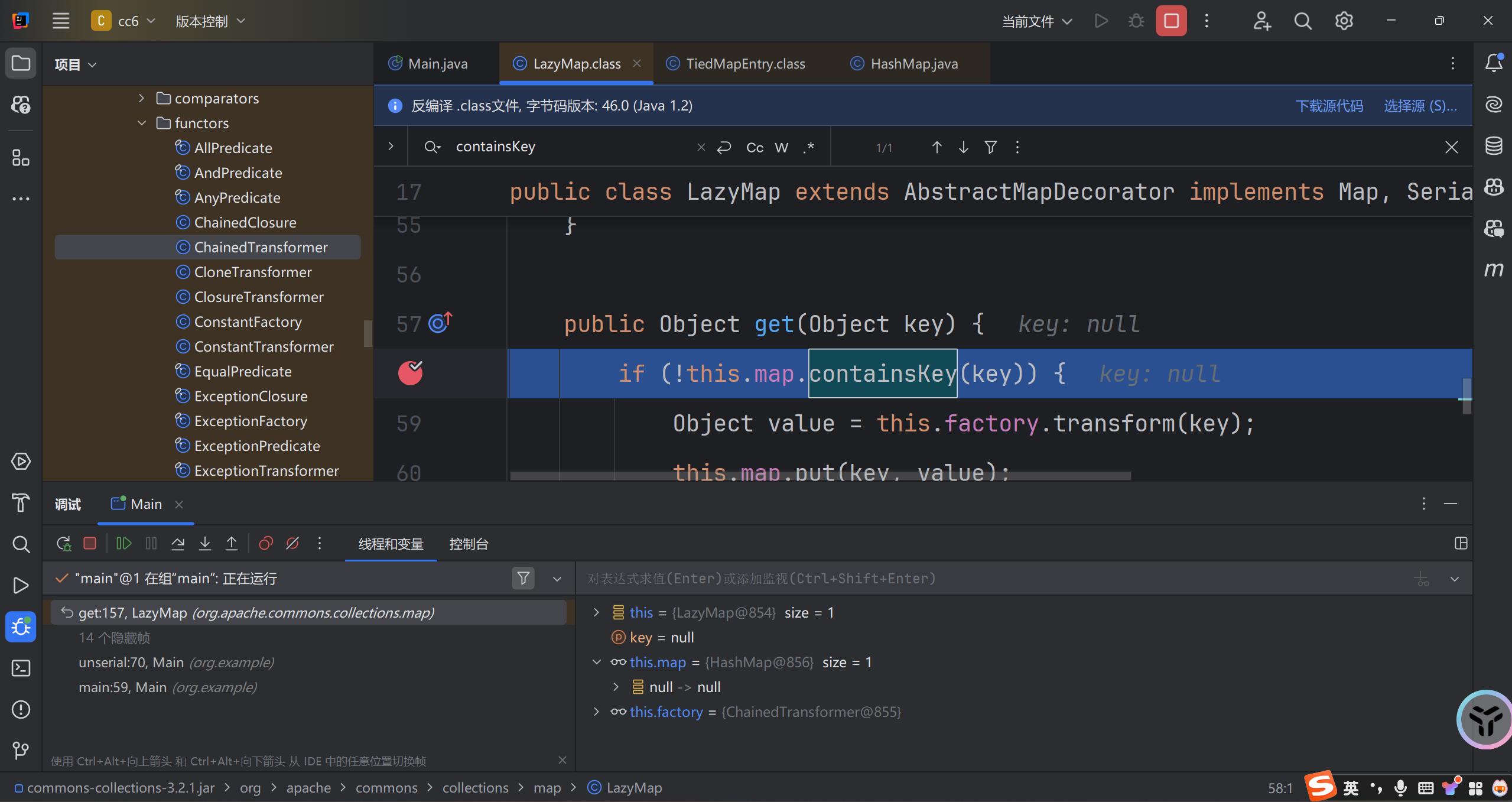
1. 没有代理对象时的处理
解决该问题的关键在于何时将实例化后的bean放进容器中,设置属性前还是设置属性后。现有的执行流程,bean实例化后并且设置属性后会被放进singletonObjects单例缓存中。如果我们调整一下顺序,当bean实例化后就放进singletonObjects单例缓存中,提前暴露引用,然后再设置属性,就能解决上面的循环依赖问题,执行流程变为:
- 步骤一:getBean(a),检查singletonObjects是否包含a,singletonObjects不包含a,实例化A放进singletonObjects,设置属性b,发现依赖B,尝试getBean(b)
- 步骤二:getBean(b),检查singletonObjects是否包含b,singletonObjects不包含b,实例化B放进singletonObjects,设置属性a,发现依赖A,尝试getBean(a)
- 步骤三:getBean(a),检查singletonObjects是否包含a,singletonObjects包含a,返回a
- 步骤四:步骤二中的b拿到a,设置属性a,然后返回b
- 步骤五:步骤一中的a拿到b,设置属性b,然后返回a
可见调整bean放进singletonObjects(人称一级缓存)的时机到bean实例化后即可解决循环依赖问题。但为了和spring保持一致,我们增加一个二级缓存earlySingletonObjects,在bean实例化后将bean放进earlySingletonObjects中(见AbstractAutowireCapableBeanFactory#doCreateBean方法第6行),getBean()时检查一级缓存singletonObjects和二级缓存earlySingletonObjects中是否包含该bean,包含则直接返回(见AbstractBeanFactory#getBean第1行)。
增加二级缓存,不能解决有代理对象时的循环依赖。原因是放进二级缓存earlySingletonObjects中的bean是实例化后的bean,而放进一级缓存singletonObjects中的bean是代理对象(代理对象在BeanPostProcessor#postProcessAfterInitialization中返回),两个缓存中的bean不一致。比如上面的例子,如果A被代理,那么B拿到的a是实例化后的A,而a是被代理后的对象,即b.getA() != a。
Mini-Spring容器
import java.util.HashMap;
import java.util.Map;public class MiniSpringContainer {// 一级缓存:存放完全初始化的单例beanprivate final Map<String, Object> singletonObjects = new HashMap<>();// 二级缓存:存放早期曝光的单例bean(未完成属性设置)private final Map<String, Object> earlySingletonObjects = new HashMap<>();// 模拟getBean方法public Object getBean(String beanName) {// 1. 先从一级缓存中获取已完成初始化的beanif (singletonObjects.containsKey(beanName)) {return singletonObjects.get(beanName);}// 2. 再从二级缓存中获取早期曝光的beanif (earlySingletonObjects.containsKey(beanName)) {return earlySingletonObjects.get(beanName);}// 3. 如果bean未被创建,则创建beanObject bean = createBean(beanName);// 4. 将创建的bean放入一级缓存singletonObjects.put(beanName, bean);return bean;}// 模拟bean创建过程private Object createBean(String beanName) {Object bean = null;if ("A".equals(beanName)) {// 5. 创建A的早期对象,并放入二级缓存bean = new A();earlySingletonObjects.put(beanName, bean);// 6. 设置A的依赖B((A) bean).setB((B) getBean("B"));} else if ("B".equals(beanName)) {// 5. 创建B的早期对象,并放入二级缓存bean = new B();earlySingletonObjects.put(beanName, bean);// 6. 设置B的依赖A((B) bean).setA((A) getBean("A"));}// 7. 从二级缓存移除,放入一级缓存中earlySingletonObjects.remove(beanName);return bean;}
}// A类和B类相互依赖
class A {private B b;public void setB(B b) {this.b = b;}
}class B {private A a;public void setA(A a) {this.a = a;}
}
说明:
- 当
getBean("A")被调用时,Spring会首先检查一级缓存singletonObjects是否存在A。如果不存在,进入createBean过程,开始创建A,并立即将A的早期对象(未初始化完全)放入二级缓存earlySingletonObjects中。 - A依赖B,故而
createBean("B")被调用,B也会被放入二级缓存中。此时B依赖A,但由于A已被放入二级缓存,B可以拿到A的早期对象。 - 最后,A和B的依赖关系设置完成后,它们会被从二级缓存中移入一级缓存。
通过这种方式,Spring可以在实例化过程中打破循环依赖,因为依赖项是从二级缓存中取的早期对象。
2. 有代理对象时的处理
在有代理对象的情况下,Spring采用了三级缓存机制。在这种情况下,代理对象不能直接放到二级缓存,而是通过工厂方法来生成并放入三级缓存。这里简化代码来展示如何处理代理对象的循环依赖。
Mini-Spring容器(带代理对象)
import java.util.HashMap;
import java.util.Map;
import java.util.function.Supplier;public class MiniSpringContainerWithProxy {// 一级缓存:存放完全初始化的单例bean(包括代理对象)private final Map<String, Object> singletonObjects = new HashMap<>();// 二级缓存:存放早期曝光的单例bean(未完成属性设置,未代理)private final Map<String, Object> earlySingletonObjects = new HashMap<>();// 三级缓存:存放bean工厂,生成代理对象的工厂private final Map<String, Supplier<Object>> singletonFactories = new HashMap<>();// 模拟getBean方法public Object getBean(String beanName) {// 1. 先从一级缓存中获取已完成初始化的beanif (singletonObjects.containsKey(beanName)) {return singletonObjects.get(beanName);}// 2. 再从二级缓存中获取早期曝光的beanif (earlySingletonObjects.containsKey(beanName)) {return earlySingletonObjects.get(beanName);}// 3. 从三级缓存中获取bean工厂,生成代理对象if (singletonFactories.containsKey(beanName)) {Object proxyBean = singletonFactories.get(beanName).get();earlySingletonObjects.put(beanName, proxyBean);return proxyBean;}// 4. 如果bean未被创建,则创建beanObject bean = createBean(beanName);// 5. 将创建的bean放入一级缓存singletonObjects.put(beanName, bean);return bean;}// 模拟bean创建过程private Object createBean(String beanName) {Object bean = null;if ("A".equals(beanName)) {// 创建A的实例,并放入三级缓存中,通过代理工厂暴露代理对象bean = new A();singletonFactories.put(beanName, () -> createProxy(bean));// 设置A的依赖B((A) bean).setB((B) getBean("B"));} else if ("B".equals(beanName)) {// 创建B的实例,并放入三级缓存中,通过代理工厂暴露代理对象bean = new B();singletonFactories.put(beanName, () -> createProxy(bean));// 设置B的依赖A((B) bean).setA((A) getBean("A"));}// 初始化完成后,从三级缓存移除,将bean放入一级缓存singletonFactories.remove(beanName);return bean;}// 模拟创建代理对象private Object createProxy(Object bean) {// 简化代理对象创建,实际中可能会用动态代理等方式return new ProxyBean(bean);}
}// A类和B类相互依赖
class A {private B b;public void setB(B b) {this.b = b;}
}class B {private A a;public void setA(A a) {this.a = a;}
}// 简化的代理对象类
class ProxyBean {private final Object target;public ProxyBean(Object target) {this.target = target;}
}
说明:
- 当
getBean("A")被调用时,Spring会创建A,并将A的代理工厂(Supplier<Object>)放入三级缓存中singletonFactories。这样,当B依赖A时,可以从三级缓存中获取A的代理对象。 - 同样,当B被创建时,其代理工厂也被放入三级缓存。
- 一旦代理对象被生成并注入到依赖链中,它会被移到二级缓存中供后续使用,最终完成初始化并移入一级缓存。
总结
- 没有代理对象时:使用一级和二级缓存,通过提前曝光未完全初始化的bean来解决循环依赖。
- 有代理对象时:通过三级缓存暴露代理对象工厂,以确保依赖链中获取到的是代理对象,解决代理bean的循环依赖。
整体流程
import java.util.HashMap;
import java.util.Map;
import java.util.function.Supplier;public class MiniSpringContainerWithObjectFactory {// 一级缓存:完全初始化的单例beanprivate final Map<String, Object> singletonObjects = new HashMap<>();// 二级缓存:提前曝光的单例bean,尚未完全初始化private final Map<String, Object> earlySingletonObjects = new HashMap<>();// 三级缓存:ObjectFactory,用来生成bean实例(包括代理对象)private final Map<String, Supplier<Object>> singletonFactories = new HashMap<>();// 模拟getBean方法public Object getBean(String beanName) {// 1. 检查一级缓存if (singletonObjects.containsKey(beanName)) {return singletonObjects.get(beanName);}// 2. 检查二级缓存(已曝光但未完全初始化的bean)if (earlySingletonObjects.containsKey(beanName)) {return earlySingletonObjects.get(beanName);}// 3. 检查三级缓存,通过ObjectFactory来生成代理或者实例化beanif (singletonFactories.containsKey(beanName)) {Object bean = singletonFactories.get(beanName).get();earlySingletonObjects.put(beanName, bean); // 将从三级缓存中取出的bean放入二级缓存return bean;}// 4. 如果没有缓存中的bean,则创建return createBean(beanName);}// 模拟bean的创建过程private Object createBean(String beanName) {Object bean;if ("A".equals(beanName)) {// 通过构造函数创建bean A,并将其ObjectFactory放入三级缓存中bean = new A();// 提前曝光bean AsingletonFactories.put(beanName, () -> bean);// 开始填充A的依赖,依赖于B((A) bean).setB((B) getBean("B"));} else if ("B".equals(beanName)) {// 通过构造函数创建bean B,并将其ObjectFactory放入三级缓存中bean = new B();// 提前曝光bean BsingletonFactories.put(beanName, () -> bean);// 开始填充B的依赖,依赖于A((B) bean).setA((A) getBean("A"));} else {throw new RuntimeException("Unknown bean: " + beanName);}// 完成bean的初始化,移除三级缓存中的ObjectFactorysingletonFactories.remove(beanName);// 从二级缓存移到一级缓存earlySingletonObjects.remove(beanName);singletonObjects.put(beanName, bean);return bean;}
}// 模拟相互依赖的A类和B类
class A {private B b;public void setB(B b) {this.b = b;}
}class B {private A a;public void setA(A a) {this.a = a;}
}
流程解释
- 检查 A 是否在缓存中:
getBean("A")时,首先检查一级缓存singletonObjects,如果不存在,则继续查找。 - 通过构造函数创建 A:如果A不存在,则调用
createBean("A")方法开始创建A。- 在这个过程中,将A的ObjectFactory提前曝光到三级缓存中
singletonFactories,为后续可能的依赖解决提供支持。
- 在这个过程中,将A的ObjectFactory提前曝光到三级缓存中
- A 开始属性填充,依赖 B:A发现自己依赖B,于是开始
getBean("B")。 - 检查 B 是否在缓存中:同样的,首先检查B是否在缓存中(一级、二级和三级)。
- 通过构造函数创建 B:如果B不存在,则调用
createBean("B")开始创建B,并将B的ObjectFactory提前曝光。 - B 依赖 A,检查 A 是否在缓存中:B的依赖A已经在三级缓存中被曝光,通过
ObjectFactory获取到A的早期对象,避免了重复创建。 - 返回 A 并完成 B 的创建:B获得A之后继续其创建流程,最终完成并返回给A。
- A 完成创建:最终A的依赖B被成功设置,A也完成了初始化,至此A和B的创建完毕。
关键点
- 提前曝光:通过
ObjectFactory将未完全初始化的bean提前放入三级缓存,避免重复创建。 - 三级缓存的使用:如果依赖的bean在初始化过程中被再次请求,Spring会从三级缓存中获取已经曝光的早期对象,而不会重复创建bean。
- 依赖填充:在创建bean时,Spring会自动检测依赖项并使用
getBean方法解决这些依赖,确保每个bean的依赖都能被正确填充。
![day9[探索 InternLM 模型能力边界]](https://img2024.cnblogs.com/blog/3229976/202410/3229976-20241004134318612-607741735.png)

![[leetcode 25]. K 个一组翻转链表](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)