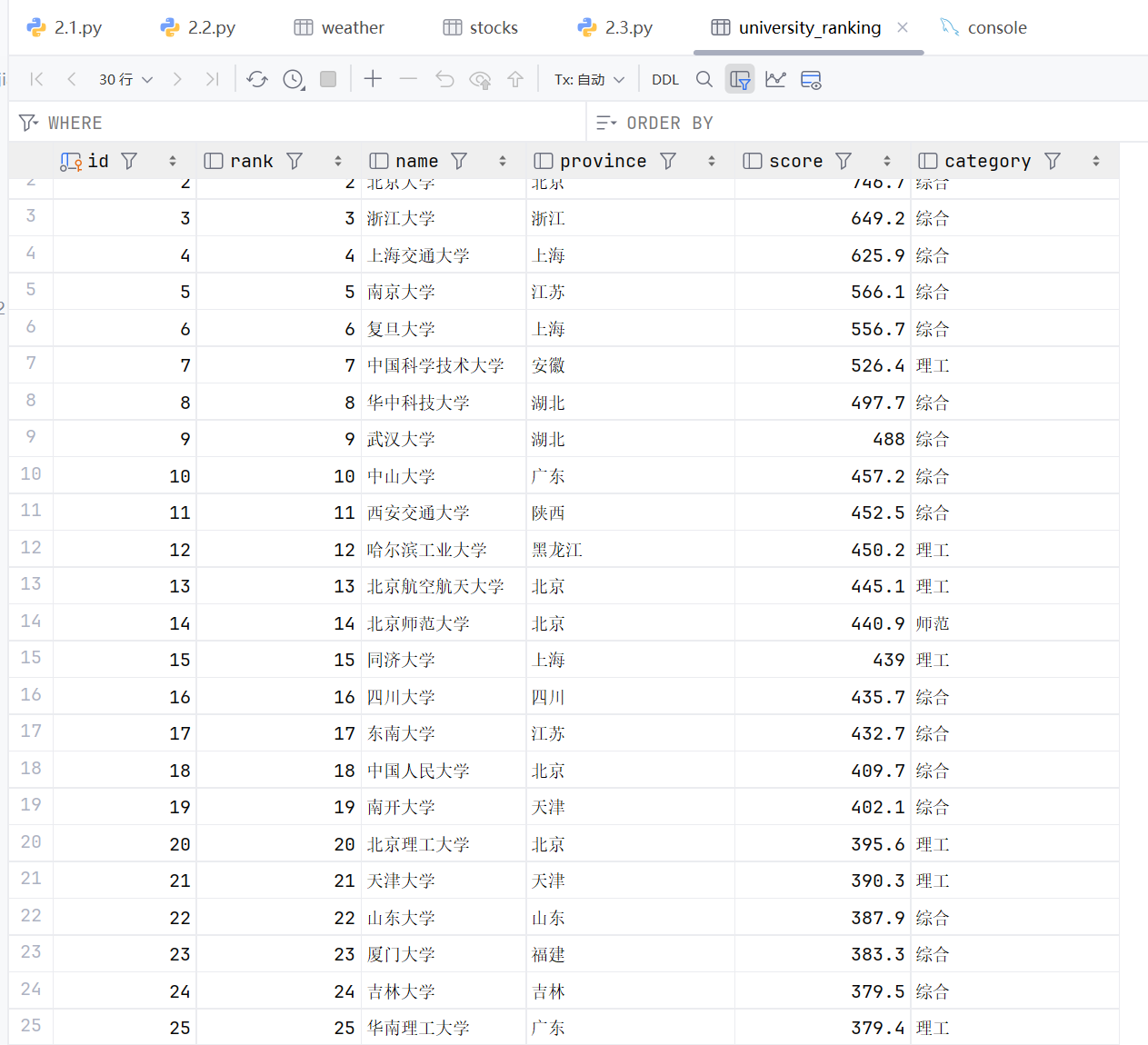
前言
扩展KMP又称Z函数,可以快速的求出一个字符串的每一个后缀的与其的LCP(最大公共前缀)长度。
至于为什么要学习exKMP,因为(数据规模很上进)我们都是上进的OIer。
算法思路
暴力朴素的算法
将\(n\)个字符的字符串S中第\(i\)位开始的后缀与S的开头一一比较,求出LCP数组Z。
CODE
for(int i=1;i<n;i++)
{while(z[i]+i<n&&s[z[i]]==s[z[i]+i]) z[i]++;
}
由于上述算法太朴实无华了,所以我们的时间复杂度也很朴实无华达到\(O(n^2)\)。
exKMP
为了解决上述过分朴实无华的时间复杂度,exKMP学会了剥削利用一切可以利用的数据。
在exKMP中,我们从\(1\)到\(n-1\)依次计算z数组,那么我们在计算\(z[i]\)时\(z[1,i-1]\)是已经计算好了的。我们在计算过程中维护一个\(r\),使\(r=max(z[j]+j-1)(j \lt i)\),同时使\(l\)等于这个区间的左端点,即\(j\)。(\(r,l,j\)如图)
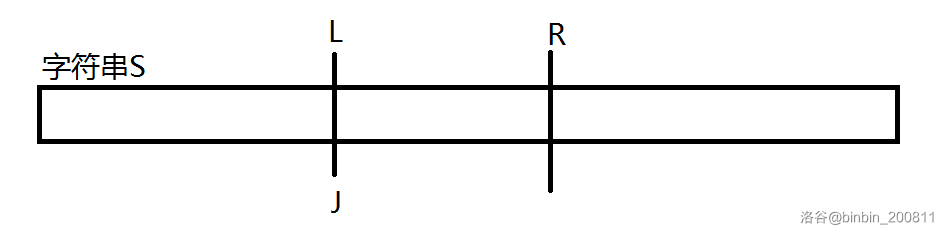
由z数值的定义可知,\(S[l,r]\)段是从第\(l\)位开始的字符串\(S\)的后缀与字符串\(S\)的LCP。那么\(S[0,z[l]-1]=S[l,r]\)。因为\(r=z[l]+l-1\),所以\(S[0,r-l]=S[l,r]\),且\(S[z[l]]!=S[r+1]\)(如果等于,那么z[l]就不是最大的)。(如图)
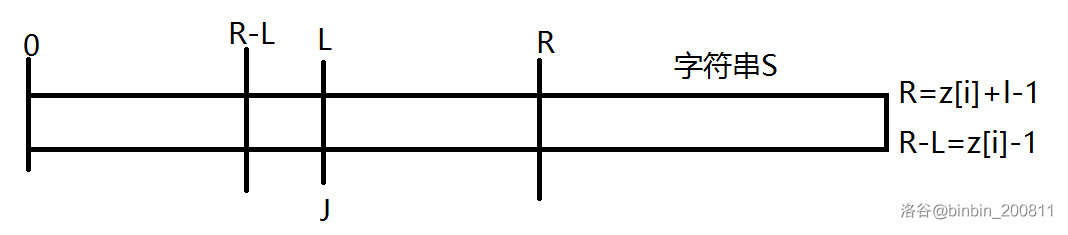
举个例子:
S={aaabb}(i=0,4),当\(l=1\)时,\(z[l]=2,r=2\)。可以看出\(S[0,r-l]=S[l,r]\)。
理解上面后,我们来计算\(z[i]\)
1.若\(l \lt i \leq r\),则\(S[i,r]=S[i-l,r-l]\)(上一个图所述情况可以看成\(i=l\)的情况,\(i\)每往后挪动一位,\(i-l\)也往后挪动一位)。
1.1若\(z[i-l] \lt r-l+1\),也就是如图蓝线所示部分:
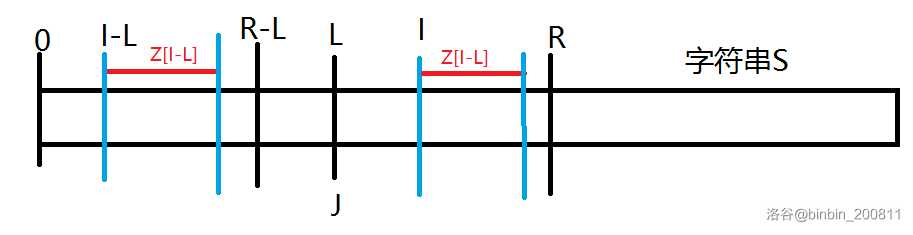
因为\(S[i-l,r-l]=S[i,r]\),所以\(S[i-l,i-l+z[i-l]-1]=S[i,i+z[i-l]-1]\)。即上图中蓝红线所示部分相同。
而且\(S[i-l+z[i-l]] \neq S[i+z[i-l]]\)(上文有类似证明),所以\(z[i]=z[i-l+1]\)。
1.2若\(z[i-l] \ge r-i+1\)时,使\(z[i]=r-i+1\),然后使用朴素的对比方法。(优质的食材往往使用最朴素的烹饪方法)(\(r\)以外的字符不清楚,那么就暴力查询)
2.若\(i \gt r\),朴素求\(z[i]\)。
注意每次求出z[i]后都要看当前的z[i]是否可以更新l和r。
代码:
for(int i=1,l=0,r=0;i<m;i++)
{if(i<=r&&z[i-l]<r-i+1) z[i]=z[i-l];//1.1的情况else{z[i]=max(0,r-i+1);//1.2或2的情况对z[i]的更新while(i+z[i]<n&&b[z[i]]==b[i+z[i]]) z[i]++;//暴力求法}if(i+z[i]-1>r) l=i,r=i+z[i]-1;//更新l,r
}
exKMP的时间复杂度
虽然我们看似进行了很多次的朴素方法,但是我们使用暴力求法时都是\(i+z[i-l] \ge r\)或\(i \gt r\)的时候,而且我们的\(r\)是不断向后变化的(不变化就一定是\(O(1)\)的解法),也就是说实际上我们只对\(S[]\)(也就是代码中的\(b[]\))只遍历了一次(对于整个exKMP来说,下同),而外围循环求\(z\)也只会遍历一次\(z\)。所以总时间复杂度\(O(n)\)。
后记
如果是两个字符串要求z函数,我们把他们拼成一条字符串,并且在连接处增加一个不属于这两个字符串的字符,就可以回归上述做法。









![shctf[Week3] 小小cms](https://img2024.cnblogs.com/blog/3527296/202410/3527296-20241024205041355-2085196337.png)