书接上回,我们继续来聊散列表的代码实现。
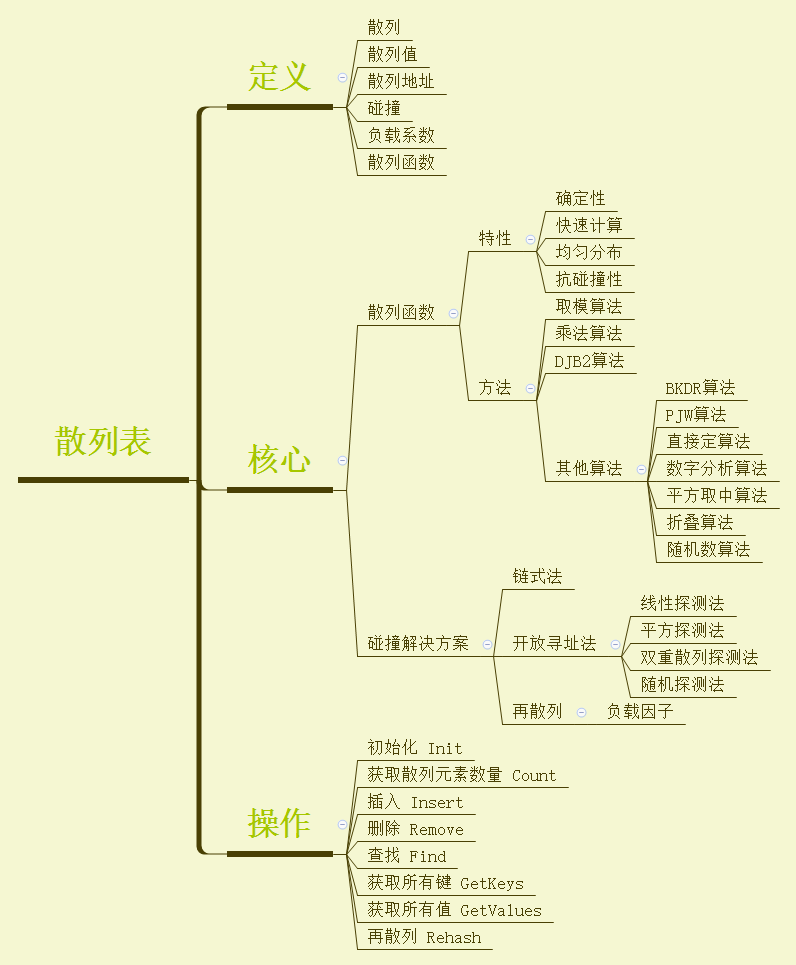
相信通过前面两章对散列表的学习,大家应该已经掌握了散列表的基础知识,今天我们就选用简单的取模方式构建散列函数,分别实现链式法和开放寻址法中的线性探测法来解决碰撞问题,而再散列法则以方法的形式分别在两种实现方法中实现。
01、链式法实现
1、元素定义
通过前面链式法的详细讲解,我们知道链式法需要构建散列桶,每个桶又指向一个链表,所以首先需要定义一个链表节点对象用来存储散列表的记,而记录中包括key、value以及指向下个节点的指针,代码如下:
//存储散列表的记录
private class Entry
{//键public TKey Key;//值public TValue Value;//下一个节点public Entry Next;public Entry(TKey key, TValue value){Key = key;Value = value;Next = null;}
}
2、初始化 Init
定义好链表,我们还需要定义散列桶,其实就是定义一个数组,同时我们在定义两个私有变量分别维护桶的数量和散列表总的元素个数。
而初始化方法主要就是根据指定初始容量来初始化这些变量,如果不指定初始容量则默认为16,具体代码如下:
//散列桶数组
private Entry[] _buckets;
//桶的数量
private int _size;
//元素数量
private int _count;
//初始化指定容量的散列表
public MyselfHashChaining<TKey, TValue> Init(int capacity = 16)
{//桶数量_size = capacity;//初始化桶数组_buckets = new Entry[capacity];_count = 0;return this;
}
3、获取散列元素数量 Count
获取散列表元素数量只需返回维护元素数量的私有字段即可,实现如下:
//元素数量
public int Count
{get{return _count;}
}
4、插入 Insert
插入方法相对比较复杂,我们可以大致分为以下几步:
(1)检测负载因子是否达到阈值,超过则触发再散列动作;
(2)构建好新的键值对象;
(3)检测新的键所在的桶是否有元素,没有元素则直接插入新对象;
(4)如果键所在桶有元素,则遍历桶中链表,已存在相同key则更新value,否则插入新对象;
(5)维护元素数量;
具体代码实现如下:
//插入键值
public void Insert(TKey key, TValue value)
{//负载因子达到 0.75 触发重新散列if (_count >= _size * 0.75){Rehash();}//计算key的散列桶索引var index = CalcBucketIndex(key);//新建一条散列表记录var newEntry = new Entry(key, value);//判断key所在桶索引位置是否为空if (_buckets[index] == null){//如果为空,则直接存储再此桶索引位置_buckets[index] = newEntry;}else{//如果不为空,则存储在此桶里的链表上//取出此桶中的记录即链表的头节点var current = _buckets[index];//遍历链表while (true){//如果链表中存在相同的key,则更新其valueif (current.Key.Equals(key)){//更新值current.Value = value;return;}//如果当前节点没有后续节点,则停止遍历链表if (current.Next == null){break;}//如果当前节点有后续节点,则继续遍历链表后续节点current = current.Next;}//如果链表中不存在相同的key//则把新的散列表记录添加到链表尾部current.Next = newEntry;}//元素数量加1_count++;
}
//计算key的散列桶索引
private int CalcBucketIndex(TKey key)
{//使用取模法计算索引,使用绝对值防止负数索引return Math.Abs(key.GetHashCode() % _size);
}
5、删除 Remove
删除逻辑和插入逻辑类似,都需要先计算key所在的散列桶,然后再处理桶中链表,只需要把链表上相应的节点删除即可,具体代码如下:
//根据key删除记录
public void Remove(TKey key)
{//计算key的散列桶索引var index = CalcBucketIndex(key);//取出key所在桶索引位置的记录即链表的头节点var current = _buckets[index];//用于暂存上一个节点Entry previous = null;//遍历链表while (current != null){//如果链表中存在相同的key,则删除if (current.Key.Equals(key)){if (previous == null){//删除头节点_buckets[index] = current.Next;}else{//删除中间节点previous.Next = current.Next;}//元素数量减1_count--;return;}//当前节点赋值给上一个节点变量previous = current;//继续遍历链表后续节点current = current.Next;}//如果未找到key则报错throw new KeyNotFoundException($"未找到key");
}
6、查找 Find
查找逻辑和插入、删除逻辑类似,都是先计算key所在桶位置,然后处理桶中链表,直至找到相应的元素,代码如下:
//根据key查找value
public TValue Find(TKey key)
{//计算key的散列桶索引var index = CalcBucketIndex(key);//取出key所在桶索引位置的记录即链表的头节点var current = _buckets[index];//遍历链表while (current != null){//如果链表中存在相同的key,则返回valueif (current.Key.Equals(key)){return current.Value;}//如果当前节点有后续节点,则继续遍历链表后续节点current = current.Next;}//如果未找到key则报错throw new KeyNotFoundException($"未找到key");
}
7、获取所有键 GetKeys
获取所有键,是遍历所有散列桶即桶中链表上的所有元素,最后取出所有key。
//获取所有键
public TKey[] GetKeys()
{//初始化所有key数组var keys = new TKey[_count];var index = 0;//遍历散列桶for (var i = 0; i < _size; i++){//获取每个桶链表头节点var current = _buckets[i];//遍历链表while (current != null){//收集键keys[index++] = current.Key;//继续遍历链表后续节点current = current.Next;}}//返回所有键的数组return keys;
}
8、获取所有值 GetValues
获取所有值,是遍历所有散列桶即桶中链表上的所有元素,最后取出所有value。
//获取所有值
public TValue[] GetValues()
{//初始化所有value数组var values = new TValue[_count];var index = 0;//遍历散列桶for (var i = 0; i < _size; i++){//获取每个桶链表头节点var current = _buckets[i];//遍历链表while (current != null){//收集值values[index++] = current.Value;//继续遍历链表后续节点current = current.Next;}}//返回所有值的数组return values;
}
9、再散列 Rehash
再散列也是比较有挑战的一个方法,这里并没有像上一篇文章中说的去实现分批次迁移老数据,而是一次性迁移,对分批次迁移感兴趣的可用自己实现试试。
这里的实现是非常简单的,就是遍历所有老数据,然后对每个老数据重新执行一次插入操作,具体代码如下:
//再散列
public void Rehash()
{//扩展2倍大小var newSize = _size * 2;//更新桶数量_size = newSize;//初始化元素个数_count = 0;//暂存老的散列表数组var oldBuckets = _buckets;//初始化新的散列表数组_buckets = new Entry[newSize];//遍历老的散列桶for (var i = 0; i < oldBuckets.Length; i++){//获取老的散列桶的每个桶链表头节点var current = oldBuckets[i];//遍历链表while (current != null){//调用插入方法Insert(current.Key, current.Value);//暂存下一个节点var next = current.Next;if (next == null){break;}//继续处理下一个节点current = next;}}
}
02、开放寻址法实现
1、元素定义
该元素的定义和链式法实现的元素定义略有不同,首先不需要指向下一个节点的指针,其次需要一个标记位用来标记空位或被删除。因为如果删除后直接置空则可能会导致后续查找过程中出现误判,因为如果置空,而后面还有相同散列值元素,但是探测方法探测到空值后会停止探测后续元素,从而引发错误,具体实现代码如下:
//存储散列表
private struct Entry
{//键public TKey Key;//值public TValue Value;//用于标记该位置是否被占用public bool IsActive;
}
2、初始化 Init
初始化方法主要就是根据指定初始容量来初始化散列表以及其大小和总的元素数量,如果不指定初始容量则默认为16,具体代码如下:
//散列表数组
private Entry[] _array;
//散列表的大小
private int _size;
//元素数量
private int _count;
//初始化指定容量的散列表
public MyselfHashOpenAddressing<TKey, TValue> Init(int capacity = 16)
{//散列表的大小_size = capacity;//初始化散列表数组_array = new Entry[capacity];_count = 0;return this;
}
3、获取散列元素数量 Count
获取散列表元素数量只需返回维护元素数量的私有字段即可,实现如下:
//元素数量
public int Count
{get{return _count;}
}
4、插入 Insert
此插入方法和链式法实现整体思路相差不大具体实现上略有差别,我们可以大致分为以下几步:
(1)检测负载因子是否达到阈值,超过则触发再散列动作;
(2)检测新的键所在的位置是否有元素,没有元素或位置非被占用则直接插入新对象;
(4)如果键所在位置有元素并且位置被占用,则线性探测后续位置,已存在相同key则更新value,否则插入新对象;
(5)维护元素数量;
具体代码实现如下:
//插入键值
public void Insert(TKey key, TValue value)
{//负载因子达到 0.75 触发重新散列if (_count >= _size * 0.75){Rehash();}//计算key的散列表索引var index = CalcIndex(key);//遍历散列表,当位置为非占用状态则结束探测while (_array[index].IsActive){//如果散列表中存在相同的key,则更新其valueif (_array[index].Key.Equals(key)){_array[index].Value = value;return;}//否则,使用线性探测法,继续探测下一个元素index = (index + 1) % _size;}//在非占用位置处添加新元素_array[index] = new Entry{Key = key,Value = value,IsActive = true};//元素数量加1_count++;
}
//计算key的散列表索引
private int CalcIndex(TKey key)
{//使用取模法计算索引,使用绝对值防止负数索引return Math.Abs(key.GetHashCode() % _size);
}
5、删除 Remove
删除逻辑和插入逻辑类似,都需要先计算key所在的散列表中的索引,循环探测后续位置元素如果发现相同的key,则标记元素为非占用状态,具体代码如下:
//根据key删除元素
public void Remove(TKey key)
{//计算key的散列表索引var index = CalcIndex(key);//遍历散列表,当位置为非占用状态则结束探测while (_array[index].IsActive){//如果散列表中存在相同的key,则标记为非占用状态if (_array[index].Key.Equals(key)){_array[index].IsActive = false;//元素数量减1_count--;return;}//否则,使用线性探测法,继续探测下一个元素index = (index + 1) % _size;}//如果未找到key则报错throw new KeyNotFoundException($"未找到key");
}
6、查找 Find
查找逻辑和插入、删除逻辑类似,都是先计算key所在索引,如果有元素并且位置标记为被占用且key相同则返回此元素,否则线性探测后续元素,如果最后未找到则报错,代码如下:
//根据key查找value
public TValue Find(TKey key)
{//计算key的散列表索引int index = CalcIndex(key);while (_array[index].IsActive){//如果散列表中存在相同的key,则返回valueif (_array[index].Key.Equals(key)){return _array[index].Value;}//否则,使用线性探测法,继续探测下一个元素index = (index + 1) % _size;}//如果未找到key则报错throw new KeyNotFoundException($"未找到key");
}
7、获取所有键 GetKeys
获取所有键,是遍历所有散列表所有元素,最后取出标记为被占用状态的所有key。
//获取所有键
public IEnumerable<TKey> GetKeys()
{//遍历散列表for (var i = 0; i < _size; i++){//收集所有占用状态的键if (_array[i].IsActive){yield return _array[i].Key;}}
}
8、获取所有值 GetValues
获取所有值,是遍历所有散列表所有元素,最后取出标记为被占用状态的所有value。
//获取所有值
public IEnumerable<TValue> GetValues()
{//遍历散列表for (var i = 0; i < _size; i++){//收集所有占用状态的值if (_array[i].IsActive){yield return _array[i].Value;}}
}
9、再散列 Rehash
这里的实现和链式法实现思路一样,就是遍历所有老数据,然后对每个老数据重新执行一次插入操作,具体代码如下:
//再散列
public void Rehash()
{//扩展2倍大小var newSize = _size * 2;//暂存老的散列表数组var oldArray = _array;//初始化新的散列表数组_array = new Entry[newSize];//更新散列表大小_size = newSize;//初始化元素个数_count = 0;//遍历老的散列表数组foreach (var entry in oldArray){if (entry.IsActive){//如果是占用状态//则重新插入到新的散列表数组中Insert(entry.Key, entry.Value);}}
}
注:测试方法代码以及示例源码都已经上传至代码库,有兴趣的可以看看。https://gitee.com/hugogoos/Planner