一、研究动机
虽然目前在图像识别任务中有许多有效后门攻击方法,直接扩展到人脸伪造检测领域却存在着一定的问题,例如存在一些伪造人脸检测的算法(SBI, Face X-ray)是通过真实图像合并转换为负样本进行模型训练的,这种情况下会导致:Backdoor label conflict
[!NOTE]
存在原因:对真实图像嵌入trigger时,在混合生成负样本时也会同时嵌入trigger,模型在训练时无法直接将trigger图像和正样本联系在一起,还会和负样本联系在一起
二、模型
[!tip]
backdoor 实现:首先通过
scalable trigger generator生成 triggertranslation-sensitive trigger pattern,紧接着使用relative embedding method based on landmark-based regions的方法嵌入trigger生成poisoned sample
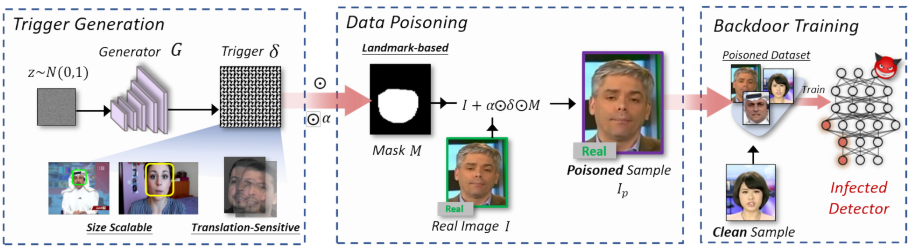
2.1 translation-sensitive trigger pattern
[!NOTE]
在研究动机中提到了人脸混合检测模型在训练过程中只使用真实样本,模型在训练时不会只将trigger和正样本联系在一起,还会与负样本(由正样本混合而成)联系在一起
解决思路:最大化正样本和负样本之间的trigger差异,如公式所示,最终的目标是最大化嵌入trigger变换图像和嵌入trigger图像的差异
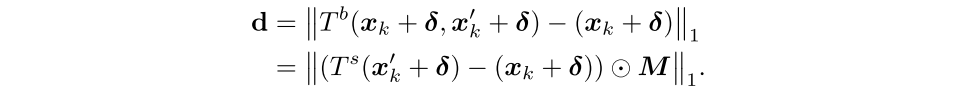
\(x_k\):表示真实图像 \(x_k'\):表示另一张真实图像
\(\delta\):trigger \(M\):表示关键点检测生成的掩码
\(T^b\) :混合两张图像操作 \(T^s\) :序列的图像变换操作(颜色抖动、平移..)
由于大多数变换计算是不可微的,无法直接得到差异最大值。平移变换是再现边界的关键步骤,并且是可以处理微分计算的,因此,作者在训练时在平移变换操作下优化trigger \(T_{m,n}\) ,m,n 分别表示横纵偏移量,只考虑平移变换trigger的最大化差异,\(M\)掩码可以视为一个常量,因此,差异函数为:
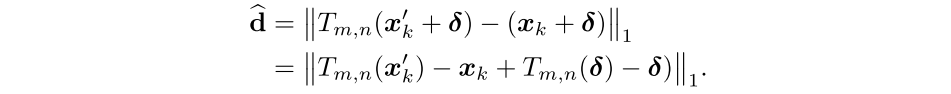
最终只需要求trigger和平移变换后的trigger的最大差异:
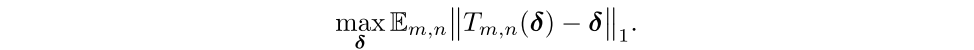
以上公式可以被看为是一个trigger的卷积操作。
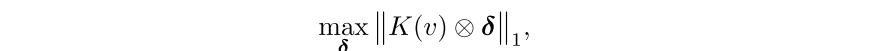
最终的损失函数可以记为:
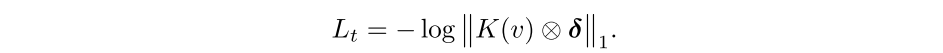
[!TIP]
在得到目标 trigger pattern 后,还需要注意:
- 适应不同大小的面部尺寸
- 隐蔽性
2.2 Scalable Backdoor Trigger Generation(适应不同大小的面部尺寸)
Zhanhao Hu, Siyuan Huang, Xiaopei Zhu, Fuchun Sun, Bo Zhang, and Xiaolin Hu. Adversarialtexture for fooling person detectors in the physical world. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13307–13316, 2022.
利用一个全连接卷积层生成器 G 将正态分布的样本 \(z~N(0,1)\) 生成 trigger \(\delta\)(任意大小尺寸),因此生成器 G 的损失函数为:
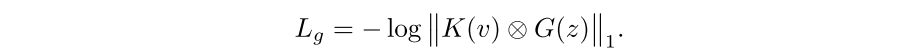
2.3 Landmark-based Relative Embedding(隐蔽性)
[!NOTE]
为了实现隐蔽性,作者在嵌入时限制了trigger的幅度和范围
-
范围:只在面部区域中生成;
-
幅度:采用低嵌入率,与采用固定的嵌入率相比,采用了基于像素值的相对相对嵌入方式
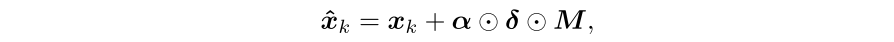
三、其他数据
-
数据集:
train_data:Faceforensics++,valid_data:Faceforensics++,Celeb-DF-2,DeepFakeDetection -
攻击模型:
- 伪影攻击:
Xception - 混合攻击:
SBI,Face X-ray
- 伪影攻击:
除了
batchsize,其他超参数一致
-
隐蔽性判断指标:
PSNR,L limit,IM-Ratio -
backdoor对比模型:
Badnet,Blended,ISSBA,SIG,Label Consistent
poisoning rateγ = 10% and randomly select 10% of the videos and embed backdoor triggers into frames.benchmark on the frequency based baseline, FTrojan(Wang et al., 2022a)
-
backdoor defence 模型:
Fine-tuning (FT)(Wu et al., 2022),Fine-Pruning (FP)(Liu et al., 2018),NAD(Li et al., 2021b), andABL(Li et al., 2021a). -
攻击效果指标 :
BD-AUC,AUC
BD-AUC:将测试集的所有真实标签换为嵌入了trigger的假图像, AUC 值越大说明攻击效果越好
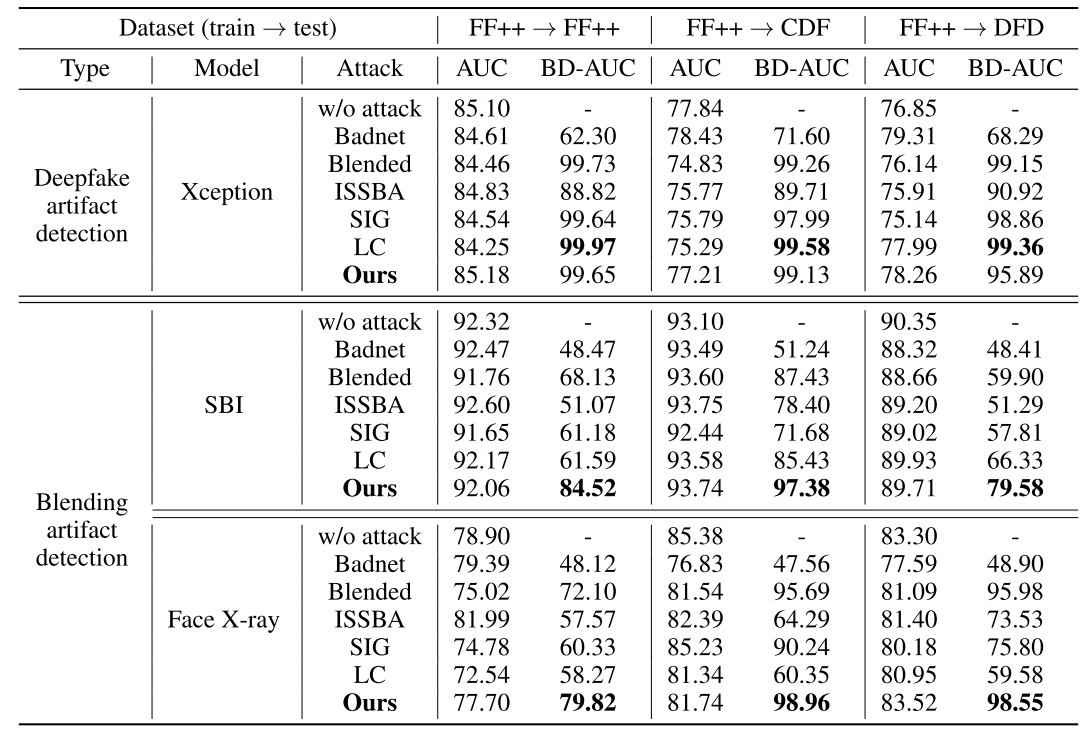
四、实验结果
- 攻击效果

- 攻击结果
[!tip]
- 攻击率太幅度提升
- 证明了强大的可移植攻击
- 伪影模型更容易遭受攻击,
Xception模型几乎100%
其他参考文献学习
-
后门攻击参考文献
- 使用一个3 * 3 的后门触发器 (Gu et al.)
- Turner et al. suggested that changing labels can be easily identified and proposed a clean-label backdoor attack.
- SIG (2019) 使用了正弦信号作为后门触发器
-
防御后门攻击
- 重新微调
- 知识蒸馏微调
-
参考文献
- 伪造检测器在推理阶段可以被对抗性例子欺骗
- 在训练阶段的第三方数据也可能导致这种风险