LightTR: A Lightweight Framework for Federated Trajectory Recovery
general的问题,数据来源于边缘设备。无法很好的训练一个最优的模型
框架分散训练的得问题 (边缘设备)
一般来说,这些网络是由一堆时空(ST)块组成的,旨在学习轨迹之间的复杂的时空依赖性。st块包含基st算子,可以进一步分为卷积神经网络(CNN)[18]、递归神经网络(RNN)[16]、[19]和基于注意神经网络(Attn)[15]的st算子。然而,现有的方法假设模型是用从边缘设备收集的集中数据进行训练的,这导致了较高的收集和存储成本,并且无法处理分散的训练数据。
specific的问题
数据中低采样率,存在数据缺失。因此需要补全===========》(所以这里是没有提出针对补全数据中的异质性提出问题)
由于移动传感设备的爆炸性采用和发展,大量的轨迹以分散的方式收集,使各种基于轨迹的应用[1]-[8],如交通预测[9]、目的地预测[10]和车辆导航[4]。尽管如此,在实践中,收集到的轨迹数据通常以低采样率[11]进行采样,称为不完全轨迹(a.k.a.低采样率轨迹),由于详细信息的丢失和高不确定性,损害了上述应用程序的有效性。因此,恢复被称为轨迹恢复的不完全轨迹的缺失点是很重要的,以便能够更有效地利用这些低采样率的轨迹
数据的时空依赖性===========》(针对轨迹数据中的特性,时空依赖性)
然而,现有的基于fl的方法[20]、[21]没有考虑到固有的时空依赖性,而这对于有效的轨迹嵌入[16]很重要。在本研究中,我们的目标是开发一种新的基于fl的轨迹恢复模型,它可以弥补分散数据处理和复杂的时空依赖建模之间的差距。尽管如此,由于以下挑战,开发这种模型是很重要的。
框架的问题
计算资源 (ST+MLP)
挑战一:可扩展性。现有流行的轨迹恢复方法通常具有较差的可伸缩性,因为这些基于深度学习的模型往往很大,其中训练和推理往往耗时和计算昂贵。这限制了轨迹恢复模型在资源约束的边缘计算设备上的可扩展性,这在分散计算中起着至关重要的作用。此外,这些方法可能会在大规模的轨迹学习设置中导致内存溢出,因为整个网络在训练过程中必须驻留在内存中。例如,给定N个轨迹,每个轨迹都有L个点,基于attn的st运算符的内存成本随L和N呈二次增加(见表II)。然而,目前的轨迹恢复模型中没有定制的闪电模块,简单地减轻这些模型会显著降低[22]的性能,这也限制了轨迹学习的可扩展性。
数据异质性问题,导致模型难以收敛 (知识蒸馏)
挑战二:通信成本。在FL培训过程中,中央服务器和所有参与客户之间存在一定的通信。有两行因素,如有限的网络带宽和爆炸性的参与客户端,可能会在FL环境中造成通信瓶颈,从而增加延迟并降低实用性。统计上,不同客户端收集的轨迹通常不是独立的、同分布的(Non-IID)和异构的,这导致通信轮显著增加以实现收敛,并难以获得最优的全局模型。系统地说,FL环境中涉及一定数量的客户端,而每个客户端的通信容量可能由于硬件、网络连接和电源方面的重大限制而不同。在联邦轨迹恢复中开发一种降低通信成本的方法,它能够解决这些统计和系统的问题是非常可取的,但也不是不简单的。
解决方案
客户端确保时空依赖
为了避免巨大的内存消耗和有限的可伸缩性(挑战I),我们为每个客户端设计了一个本地轻量级轨迹嵌入(LTE)模型。具体来说,LTE包含一个嵌入组件和一个st块堆栈来学习有效的时空表示。与以往的研究[19],我们形式化一个轻量级的运算符和取代流行的算符(如CNN和附加)纯MLP(多层感知器)架构考虑较低的空间复杂性(即O(L + D + 1))和时间复杂性(即O(N·(L + D)))的MLP,其中L表示每个轨迹,D是嵌入大小,N是轨迹的数量。在这里,我们只使用一个RNN层与MLP结合来确保时间依赖项捕获。
知识蒸馏解决通信成本问题
为了降低通信成本并加快模型的收敛速度(挑战II),我们提出了一种基于知识蒸馏的元知识增强的局部-全局训练模块。在联合培训之前,我们提出了一个教师模型(即元学习者),使用其中的一部分本地数据为每个客户学习本地元知识。我们将局部轻量级轨迹嵌入模型作为学生模型。在FL过程中,采用教师模型来指导学生模型的优化,以更好地学习共同特征,实现更快的收敛速度
实验,使用的都是车辆数据,并且是将以一个数据集拆分成20个客户端。每个数据集的实验是独立的
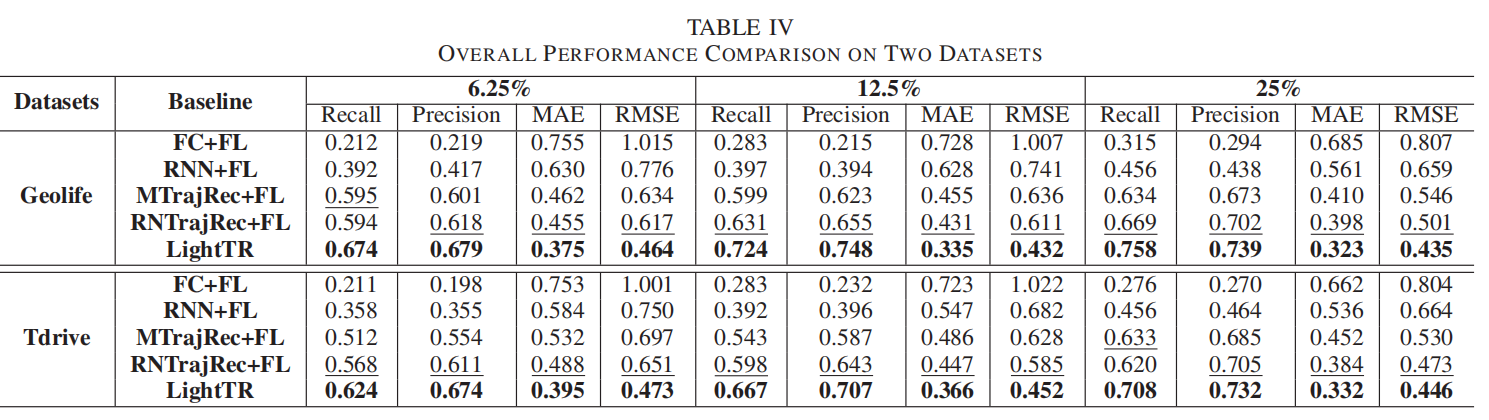
在这项研究中,提出了一个轻量级的联邦学习框架 LightTR,用于实现高效的轨迹恢复。研究使用了 Geolife 和 Tdrive 两个数据集,数据保留比例分别为 6.25%、12.5% 和 25%,并在每两个保留的轨迹点之间平均插入 6 个数据点,以实现高采样率的轨迹恢复。
LightTR 框架在客户端使用以下方法模块来协同完成轨迹恢复任务:
-
FC+FL:结合水平联邦学习 (FL) 和堆叠的全连接层 (FC) 用于轨迹恢复。在此方法中,使用隐马尔可夫模型 (HMM) 作为匹配算法。
-
RNN+FL:一种去中心化的轨迹恢复模型,通过堆叠递归神经网络 (RNN) 与水平联邦学习相结合,协作学习轨迹的表示。
-
MTrajRec+FL:利用 MTrajRec 作为本地模型的去中心化轨迹恢复方法。MTrajRec 是基于序列到序列 (Seq2Seq) 的先进轨迹恢复方法。
-
RTrajRec+FL:使用 RNtrajRec 作为本地模型的水平联邦学习轨迹恢复方法。RNtrajRec 应用了图神经网络,以捕捉轨迹中的丰富时空相关性。
LightTR 框架通过上述模块在客户端完成轻量化的轨迹嵌入,并结合联邦学习的水平协同训练,确保数据隐私和分散化。同时,LightTR 还采用了增强的本地-全局训练方案,以减少客户端与服务器之间的通信成本,从而进一步提升了计算效率。
实验结果表明,LightTR 框架在实现高效轨迹恢复的同时,能够有效保障数据隐私并降低计算资源消耗。
Physics-Informed Trajectory Prediction for Autonomous Driving under Missing Observation
specific的数据问题=====》缺失数据,传感器观测缺失
在自动驾驶汽车的领域中,在动态环境中有效预测周围车辆的轨迹遇到了两个经常被忽视但相互关联的挑战。最大的挑战来自于现实世界的观测限制,如传感器的限制和环境因素,包括障碍物、不利天气或交通拥堵。这些约束经常导致观察结果的缺失[Liao et al.,2024b],这对传统的深度学习模型构成了重大障碍。尽管这些模型在理想的数据集上很有效,但它们通常难以适应现实世界驾驶的不可预测和变化的条件特征[巴塔查里亚等人,2023年],这是一个问题
物理定律,运动学约束========》导致预测在统计上是准确的,但在运动学上不可行
其次,同样被忽视的挑战包括确保这些模型在轨迹预测中符合物理定律。目前的许多模型没有充分考虑车辆运动的运动学约束,导致预测在统计上是准确的,但在运动学上不可行。这种限制可能会损害无人机运动计划的安全性和可靠性[Huang等人,2022;Shen等人,2023],但在现有文献中还没有给予应有的关注
解决方案
为了弥补这些差距,我们的研究引入了一种新的双阶段轨迹预测方法,该方法将数据分割和基于物理的方法与物理增强阶段相结合,如图1所示,以及轨迹预测阶段。这种方法结合了深度学习的鲁棒性和物理信息原理,确保在缺少观测的情况下,即使是现实和稳健的轨迹预测。为了证明它的有效性,我们的方法始终优于最先进的(SOTA)
基于运动学的补全
我们介绍了一个开创性的物理增强阶段,其中包括一个小波重建网络和一个运动学自行车模型。这种集成促进了轨迹预测领域的显著进步,显著提高了该方法对缺失观测值的鲁棒性,并增强了预测轨迹的运动学可行性。我们创新的波聚变编码器,受到量子力学的启发,彻底改变了相互作用建模。通过将车辆特征概念化为波形,该模块促进了一种利用波叠加原理建模车辆相互作用的新方法。
实验
在实验设置部分描述的缺失率和时间步可能确实让人困惑。以下是对文中提到的时间步和缺失率的解析:
-
时间步的含义:文中提到的 "3秒用于轨迹历史"((t_h = 3))和"5秒用于模型预测"((t_f = 5))指的是时间跨度,而不是时间步的个数。通常在轨迹数据中,时间步是以更小的时间间隔采样的(例如每秒采样一次)。因此,虽然历史部分的总时长为3秒,但在采样频率较高的情况下,可能会包含多个时间步数据点(例如3秒内可能有3个或更多时间步,具体取决于采样频率)。
-
缺失率的理解:文中提到的缺失率(25%、50%、75%)是指在数据样本中,观察到的数据点被随机移除的比例,而不是时间段的缺失。例如,在“MoCAD-missing, NGSIM-missing, 和 HighD-missing”数据集中,25%、50% 或 75% 的观测点被随机移除。因此,如果原始轨迹包含多个时间步(多个采样点),即使总时间跨度为3秒或5秒,仍然可以设置较高的缺失率,因为每个样本包含的具体数据点数可能足够多,允许这种比例的随机移除。
-
73%的缺失率可能的原因:文件没有具体说明是如何达成 73% 缺失的,但推测是一个统计上的缺失率或一种特定的实验设定。例如,如果某些段的数据极其稀疏或故意以高缺失率设计以测试模型的适应性和鲁棒性,可能会出现非标准的缺失率。
总结来说,缺失率是在一个包含多个时间步的轨迹数据点上实施的,并非仅针对 3 秒或 5 秒的时间跨度。这样可以确保数据集能够包含足够的点数以支持实验,即使缺失率较高。
COLA: Cross-city Mobility Transformer for Human Trajectory
数据上的长尾问题。每个城市都基本上是长尾数据 (数据稀疏)========》通过迁移知识缓解数据稀疏的问题
普遍存在的数据稀缺问题促使我们将人类流动的普遍模式从丰富的外部城市转移过来,以帮助提高我们的目标城市的综合质量。如图1(a)所示,城市市民的日常活动通常受到类似的意图的驱动,包括工作、娱乐、通勤、购物、休息等。这些共同的意图表现出不同城市人类轨迹的普遍模式,导致了相似的长尾频率分布,如图1(b).所示如果能够适当地转移城市间的移动知识,就可以在很大程度上缓解人类发展轨迹的数据稀缺性。
数据异质性的问题
然而,与跨城市[22,28,36]的时空转移相比,跨城市移动转移带来了相当特殊的挑战。[22,28,36]研究空气质量指标[36]、大流行病例[28]或交通速度[22]。首先,外部城市的位置与目标城市的位置很难相互作用,导致位置嵌入不能在城市间转移,这称为知识转移中的领域异质性。相比之下,时空传输通常处理相同特征空间的指标,如空气质量指标,减轻了传输的难度。其次,由于城市文化或地理影响,不同城市呈现出细微不同的长尾频率分布。这些细微的差异需要在知识转移过程中仔细校准现有的过度自信的深度神经网络[18]。上述挑战要求我们重新思考跨城市流动转移的原则。
解决方案上的问题
针对轨迹数据,循环网络的不适应。对抗方法也不适应
最近的深度学习模型[9,10、14、20,43-45]在很大程度上促进了基于先进的序列生成技术的人类轨迹的合成质量。一方面,递归模型[9,14,20]涉及到人类轨迹序列的归纳偏差。DeepMove [9]设计了一种个体轨迹的注意机制来检索相关信息;CGE [14]利用个体轨迹的时空上下文信息。尽管如此,循环模型很难从零开始生成高保真度的轨迹,因为它们依赖于历史模型
轨迹另一方面,基于对抗的方法[10,43-45]结合了人类流动性的高阶语义,如地理关系[10]、活动动态[44]和Maslow的需求层次[45],同时基于双人最大游戏最大化长期生成奖励。尽管他们做出了努力,但人类轨迹数据的严重缺乏将导致这些专用模型的次优解决方案。
针对异质性的问题,使用transformer来迁移
为了解决这些挑战,我们在迁移学习框架中引入了强大的变压器[29,31]块,以学习基于标记(位置)之间的注意相似性的人类移动的通用模式,这已经证明了它在许多NLP任务中的泛化能力。具体地说,我们用一个模型不可知的传输框架[11,28]定制了一个跨城市的移动模型,称为COLA,以处理领域异质性和跨城市的位置的不同长尾频率分布。首先,可乐将变压器划分为城市专用模块共享模块占城市通用知识,称为半开放变压器。它将注意力计算机制置于共享模块中,以更好地促进城市人类轨迹之间的模式转移。一旦转移,目标城市就可以通过私人模块展示其特定的移动行为,包括不可转移的位置嵌入及其潜在的表示。其次,COLA将其位置的预测概率与真实的长尾频率分布进行事后[26]对齐,以解决过度自信问题[18]。与重加权损失函数[48,50]的迭代优化相比,预测概率的后调整仅对移动迁移完成后的目标城市有效,使得迁移框架复杂优化的变化最小。COLA可以有效地适应强大的变压器跨城市移动转移。
Improving Transferability for Cross-Domain Trajectory Prediction via Neural Stochastic Diferential Equation
数据异质性的困难
数据驱动模型的一个众所周知的问题是,当训练数据和测试数据之间的数据分布存在差异时,它们的性能有限。因此,要在一个特定的环境下构建一个轨迹预测系统,最优的方法是从该环境中收集数据。然而,最近的模型需要大量的数据来获得最佳性能,这需要一个繁琐的获取如此数量的数据。从这个意义上说,充分利用现有的大规模数据集在规避这一障碍方面具有优势。最近的方法试图通过提出领域自适应来克服这一挑战(Xu等人2022;Wang等人2022b)或通过多源数据集训练来增加模型的通用性(Wang等人20222a)。与这些处理域间隙的方法相比,每个数据采集策略之间的差异导致的数据集特定差异被排除在域间隙之外,访问次数较少。我们的工作表明,对这些数据集特定差异的充分处理可以释放出跨数据集运动模式的集体潜力。
在处理跨数据集的轨迹或运动模式时,不同数据集的采集方式会导致一些特有的差异,这种差异通常没有被视为“领域差异”(domain gap),也就是说,它们往往没有被认为是需要适应或处理的领域差异。这些差异指的是各个数据集因不同的采集策略或技术导致的数据特征差异,比如传感器的分辨率、采样频率、地理区域、甚至环境因素的不同。
许多最新的研究通过 领域适应(domain adaptation) 或 多源数据集训练 来提高模型的通用性,以此来应对不同领域之间的差异(即传统意义上的“领域差异”)。然而,这些研究通常忽略了由数据采集策略差异所带来的数据集特定的偏差(即数据集特定的差异,并不被视为典型的领域差异)。
本文的工作展示了,如果能够有效地处理这些数据集特有的差异,那么可以从不同数据集的运动模式中挖掘出一种集体的潜力,进而提升模型的性能。这意味着,通过充分利用各数据集的特定信息,可以更好地结合这些数据集的优势,提升模型对跨数据集任务的适应性和表现。
这段话讨论的是不同数据集之间在 时间步配置 上的差异,以及这种差异对模型表现的影响。这里的“偏差”指的是 由于各数据集的采样策略和预测配置不同,导致的输入输出特征空间的差异,这使得模型在跨数据集时难以适应。
具体来说:
- 时间步配置差异:不同的数据集有不同的时间配置,例如:
- 观察和预测时间长度:一个数据集可能使用短时间的过去轨迹来预测较长时间的未来轨迹,另一个数据集则可能配置不同的过去和未来时间长度。
- 采样频率:不同的数据集采样频率不同,比如 10Hz、2Hz 等,即每秒采样的次数不同,这会导致特征在时间上的分布不同。
- 特征空间的差异:时间步配置的不同会导致输入和输出轨迹的特征空间(feature space)存在差异。举例来说,如果一个模型在 WOMD 数据集上训练,它的任务是基于过去 1 秒的轨迹(10Hz 采样)预测未来 8 秒的轨迹,这个模型学习的是一种从 1 秒的运动特征映射到 8 秒未来特征的函数。
- 跨数据集问题:如果这个模型在 nuScenes 数据集上进行评估,而 nuScenes 的配置是基于 2 秒的轨迹(2Hz 采样)预测未来 6 秒的轨迹,那么模型在输入和输出特征空间上会遇到困难。这是因为 WOMD 和 nuScenes 数据集的时间配置差异导致它们的输入输出特征的分布(或称特征流形)并不相同,模型很难将过去的轨迹特征准确地映射到未来的轨迹特征。
总结来说,这里的“偏差”是指不同数据集之间 由于采样频率、观察和预测时间长度的不同,导致的输入输出特征空间的分布差异。这些差异增加了跨数据集任务的难度,因为模型必须适应不同的特征空间,这种特征空间的偏差并不是典型的“领域差异”,而是数据集采集策略本身带来的差异。
概念上的问题
好的,我们来梳理一下采样频率、观测时间和预测时间之间的关系。这三个因素共同决定了轨迹数据的结构,以及模型输入和输出的特征。
1. 采样频率(Sampling Frequency)
采样频率表示在单位时间内采集数据的次数,通常以Hz为单位。例如:
- 10Hz 表示每秒采集 10 个数据点。
- 2Hz 表示每秒采集 2 个数据点。
采样频率越高,每秒采集的数据点越多,轨迹信息的时间分辨率就越高。采样频率对轨迹的细节捕捉能力有很大影响,频率越高,可以捕捉到更细微的运动变化。
2. 观测时间(Observation Time)
观测时间是模型用于预测未来轨迹的过去时间长度,即模型的输入部分。例如:
- 观测时间为 1 秒,意味着模型仅使用过去 1 秒的数据进行预测。
- 观测时间为 2 秒,则使用过去 2 秒的数据。
观测时间决定了模型在做出预测前可以看到的轨迹长度。观测时间越长,模型能够利用的信息越多,这可能有助于更准确的预测。
3. 预测时间(Prediction Time)
预测时间是模型需要预测的未来轨迹的时间长度,代表模型的输出部分。例如:
- 预测时间为 8 秒,表示模型需要预测未来 8 秒的轨迹。
- 预测时间为 6 秒,表示模型预测未来 6 秒的轨迹。
预测时间决定了模型需要推测的未来轨迹的跨度。预测时间越长,模型的预测难度可能越大,因为需要在更长的时间跨度上推测运动趋势。
三者之间的关系
这三个因素的组合会影响输入输出的特征空间,具体关系如下:
-
采样频率和观测时间的关系:
采样频率决定了在观测时间内的采样点数量。例如,10Hz 采样频率下,1 秒观测时间内会有 10 个数据点,而 2 秒观测时间内会有 20 个数据点。因此,观测时间 × 采样频率 = 观测数据点的数量。 -
采样频率和预测时间的关系:
采样频率同样影响预测时间内的采样点数量。例如,8 秒预测时间在 10Hz 采样下会有 80 个数据点,而在 2Hz 采样下只有 16 个数据点。因此,预测时间 × 采样频率 = 预测数据点的数量。 -
观测时间和预测时间的关系:
观测时间和预测时间的比例决定了输入和输出之间的“跨度”关系。例如,如果模型使用 1 秒观测时间预测未来 8 秒的轨迹,模型的输入比输出少得多,需要根据短时的信息预测较长的未来。如果是 2 秒观测时间预测 6 秒未来,输入和输出的比值更接近,预测难度可能稍微减小。 -
三者共同影响特征空间的差异:
当不同的数据集具有不同的采样频率、观测时间和预测时间时,输入输出的轨迹分布和特征空间会有显著差异。例如:- 一个数据集可能是1 秒观测 + 8 秒预测 + 10Hz采样,输入输出点数是 10 和 80;
- 另一个数据集是2 秒观测 + 6 秒预测 + 2Hz采样,输入输出点数是 4 和 12。
这会导致输入和输出的特征在不同数据集中分布差异显著,使得模型难以在跨数据集的情况下泛化。
总结
- 采样频率决定了单位时间内的采样点数,影响轨迹的时间分辨率。
- 观测时间是输入数据的时间跨度,影响模型能观察到的轨迹长度。
- 预测时间是模型需要预测的时间跨度,决定了模型输出轨迹的长度。
- 三者的组合会影响输入和输出的特征空间,不同组合会导致不同的数据分布,使得模型在跨数据集时难以直接适应。
噪声的影响
这段话讨论了在轨迹数据集的采集过程中,由于传感器噪声和检测与跟踪误差带来的问题,以及它们对预测性能的负面影响。这些误差和噪声在不同的数据集中表现出独特的趋势和模式,从而给跨数据集的预测带来了额外的挑战。
具体来说,主要的问题包括:
-
传感器噪声和检测/跟踪误差:
轨迹数据集通常是通过从自车(ego-agent)传感器数据中检测并跟踪周围的目标物体(例如其他车辆或行人)来生成的。这些跟踪结果(tracklets)容易受到传感器噪声的影响,也可能因为检测和跟踪算法的精度不足而产生错误。这些噪声和误差会直接影响到后续模型的预测性能。 -
数据集特定的跟踪误差模式:
每个数据集的采集过程使用的传感器类型、检测器和跟踪器配置不同,导致不同数据集在跟踪误差上表现出独特的模式或趋势。不同数据集在噪声和误差的类型、分布和严重程度上有所不同,这使得模型在一个数据集上训练后,难以适应其他数据集的特定误差模式。 -
采样频率对噪声模式的影响:
跟踪噪声的模式还受到采样频率(时间步长配置)的影响。例如,较高的采样频率(即较小的时间步长 Δt)通常会导致更严重的噪声。文中提到 Argoverse 数据集比 nuScenes 数据集在相同的时间长度内表现出更严重的跟踪噪声,这可能是因为 Argoverse 的采样频率更高,因此更容易捕捉到微小的、但可能不准确的位移变化。 -
对预测性能的影响:
跟踪误差和噪声会导致模型的输入数据质量下降,从而降低模型的预测准确性。这种噪声还具有数据集特定的特点,增加了跨数据集迁移或泛化的难度,因为模型需要适应每个数据集特有的噪声模式。
总结
该段描述了由于传感器噪声、检测和跟踪误差带来的数据集特定问题,以及采样频率对噪声模式的影响。这些因素使得不同数据集在轨迹数据上表现出不同的噪声模式,给模型的跨数据集泛化和预测性能带来了挑战。这意味着在跨数据集预测中,除了领域差异,还必须考虑每个数据集特有的跟踪误差和噪声模式对模型的影响。
解决方案 处理时间步不同的问题
我们利用NSDE的连续表示来进行轨迹预测,以减少在任意时间混淆中收集的数据集之间的内部差异。
处理数据中存在噪声的问题
这里的第二个贡献点可以理解为,提出了一个特定于数据集的扩散网络框架及其训练方法,用于处理不同数据集中独特的跟踪误差。
具体来说:
-
数据集特定的扩散网络框架:
作者提出了一种框架,能够针对不同的数据集进行定制化处理,尤其是处理由于传感器、检测器和跟踪器配置的差异而导致的各数据集特有的跟踪误差(tracklet errors)。每个数据集的采集过程和配置不同,误差的类型、分布和严重程度也不同,这种特定于数据集的扩散网络框架能够识别和适应这些差异,从而提升预测性能。 -
训练方法:
提出了一个训练方法,使得这个数据集特定的扩散网络可以在有噪声和误差的情况下进行更有效的学习。扩散网络的设计使得它具有一定的随机性(stochasticity),因此可以更好地应对和纠正跟踪误差,增强模型的鲁棒性。
总结
这个贡献点的核心在于,作者为每个数据集设计了一个专门的扩散网络,以应对数据集采集过程中产生的特有噪声和误差。这种定制化的网络和训练方法能够帮助模型更好地处理不同数据集中的噪声模式和跟踪误差,从而提高预测的准确性和泛化能力。
实验=======》只使用了车辆轨迹
我们使用nuScenes(30k)和Lyft(160k)作为小规模的目标数据集,因为它们的规模相对较小。我们利用交互、Argogirse(200k)和WOMD(500k)数据集作为大规模的数据集进行额外的训练。为了利用数据集之间的公共信息,我们只使用过去/未来的轨迹和车道中心线信息。此外,虽然这些数据集同时有车辆和行人的轨迹数据,但为了简单起见,我们只训练和评估车辆的轨迹。为了展示我们的框架的有效性,我们选择了HiVT(Zhou等人. 2022)和MUSE-VAE(Lee et al. 2022)作为最新的回归和基于目标预测的轨迹预测方法,并表明即使是最先进的
设置不同的时间步
从实验设置和数据集的描述来看,本文的训练和预测方法大致如下:
训练过程
-
目标:
本文的目标是在目标数据集上的性能提升,并通过在大规模源数据集上的额外训练来实现。为了解决跨数据集传递性的问题,模型会联合多个数据集的训练集来训练,然后在目标数据集的验证集上评估。 -
训练数据组合:
- 基于回归的预测模型:
- 仅使用 nuScenes 训练集 (N)。
- 使用 nuScenes + Argoverse 训练集 (N+A)。
- 使用 nuScenes + WOMD 训练集 (N+W)。
- 基于目标条件的模型:
- 在 nuScenes 验证集上,模型只用 nuScenes 训练集 (N) 或 nuScenes + INTERACTION 训练集 (N+I)。
- 在 Lyft 验证集上,模型只用 Lyft 训练集 (L) 或 Lyft + INTERACTION 训练集 (L+I)。
- 基于回归的预测模型:
-
时间步配置的处理:
- 为了让基线模型适应不同的时间步配置,重新排列了两个数据集的时间序列数据。为每个时间步创建了空时间条,以对齐不同数据集的时间步配置。例如,在 nuScenes (2秒, 2Hz) 和 Argoverse (2/3秒, 10Hz) 的情况下,会创建 81 个 (2/6s, 10Hz) 的空时间条。
-
使用的数据集:
- 小规模目标数据集:nuScenes (30k samples) 和 Lyft (160k samples)。
- 大规模源数据集:INTERACTION, Argoverse (200k samples) 和 WOMD (500k samples)。
- 为了确保一致性,只使用了数据集中车辆的轨迹数据,并采用了历史/未来轨迹和车道中心线信息。
-
基线模型:
- 选择了 HiVT 和 MUSE-VAE 作为最新的基线方法,用于基于回归和目标预测的轨迹预测。
预测过程
-
验证集的评估:
- 在联合训练后,模型在目标数据集的验证集上进行预测和评估,特别是在 nuScenes 和 Lyft 验证集上。
-
评估指标:
- 使用 mADE10 作为评估指标(广泛使用的均方平均位移误差),用于衡量模型在目标数据集上的预测精度。
-
性能提升:
- 实验的重点在于通过融合多源数据集来提升模型的泛化能力和在目标数据集上的表现。即便是现有的最先进方法,通过融合作者提出的 SDE 框架仍然有改进空间。
总结
本文的训练过程是基于多源数据集联合训练,通过重新排列时间步配置来处理不同数据集的时间步差异。预测过程则在目标数据集的验证集上进行,并使用 mADE10 指标进行评估。通过这种方式,作者探索了如何利用源数据集的信息来增强目标数据集的性能,并展示了 SDE 框架的改进潜力。