"""
模型选择,欠拟合、过拟合
"""import math
import numpy as np
import torch
from d2l import torch as d2l
from IPython import display
import matplotlib.pyplot as plt
from torch import nnmax_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)# NumPy ndarray转换为tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]]features[:2], poly_features[:2, :], labels[:2]class Animator:"""在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5), pic_name=None):# 增量地绘制多条线if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使用lambda函数捕获参数self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsself.pic_name = pic_namedef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()plt.draw()plt.pause(0.1)plt.savefig(self.pic_name)display.display(self.fig)display.clear_output(wait=True)def show(self):display.display(self.fig)def evaluate_loss(net, data_iter, loss):"""评估给定数据集上模型的损失"""metric = d2l.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:out = net(X)y = y.reshape(out.shape)l = loss(out, y)metric.add(l.sum(), l.numel())return metric[0] / metric[1]def train_epoch_ch3(net, train_iter, loss, updater):"""训练模型一个迭代周期(定义见第3章)"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数# metric = d2l.Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使用PyTorch内置的优化器和损失函数updater.zero_grad()l.mean().backward()updater.step()else:# 使用定制的优化器和损失函数l.sum().backward()updater(X.shape[0])def train(train_features, test_features, train_labels, test_labels,num_epochs=400, state='正常'):loss = nn.MSELoss(reduction='none')input_shape = train_features.shape[-1]# 不设置偏置,因为我们已经在多项式中实现了它net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))batch_size = min(10, train_labels.shape[0])train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)),batch_size)test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)),batch_size, is_train=False)trainer = torch.optim.SGD(net.parameters(), lr=0.01)animator = Animator(xlabel='epoch', ylabel='loss', yscale='log',xlim=[1, num_epochs], ylim=[1e-3, 1e2],legend=['train', 'test'], pic_name=f'model_select_{state}')for epoch in range(num_epochs):train_epoch_ch3(net, train_iter, loss, trainer)if epoch == 0 or (epoch + 1) % 20 == 0:animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)))print('weight:', net[0].weight.data.numpy())# 三阶多项式函数拟合(正常)
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],labels[:n_train], labels[n_train:], state='正常拟合')# 线性函数拟合(欠拟合)
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],labels[:n_train], labels[n_train:], state='欠拟合')# 高阶多项式函数拟合(过拟合)
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],labels[:n_train], labels[n_train:], num_epochs=1500, state='过拟合')torch--模型选择-欠拟合-过拟合
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/827630.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
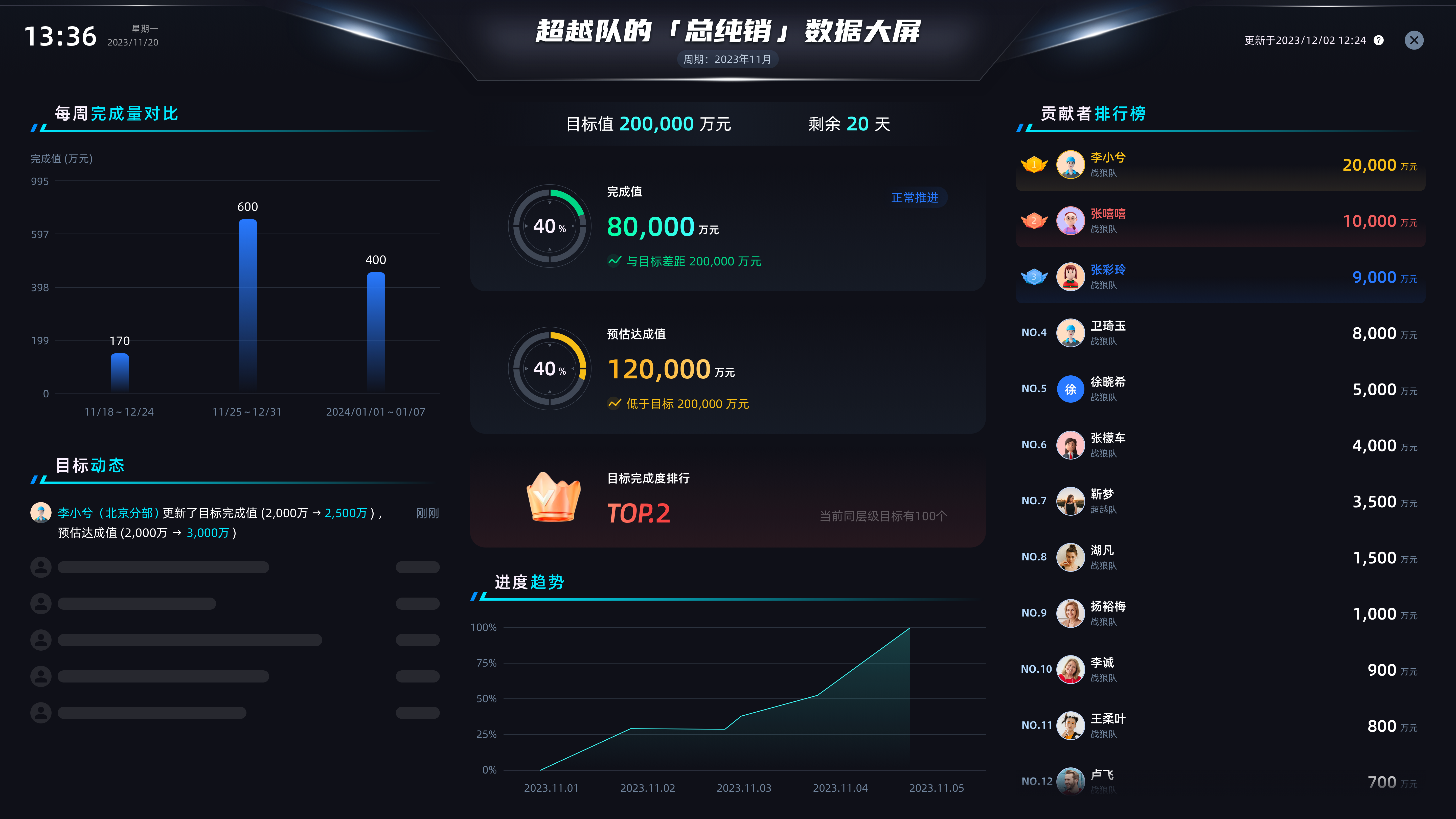
企业老板的最爱,KPI 数据大屏全屏监控企业经营数据目标达成
「KPI目标管理」,新增「目标数据大屏」,可视化追踪目标进度,老板最喜欢的目标数据追踪大屏,够炫酷!
应用场景
在企业管理中,每个人都面临着监控目标执行情况和管理团队的挑战。
每个人需要实时了解目标的落地情况、风险因素以及团队成员的贡献度,但传统的管理方式往往:…
IBM SPSS Amos 28下载与安装教程
1、安装包Amos28:
链接:https://pan.quark.cn/s/0f9dcffd2b38
提取码:Z18Q
2、安装教程
1) 双击安装,弹窗安装对话框2) 点击下一步,选择I accept ,点击Next3) 选择安装路径,建议安装C盘之外,选择完,点击Next4) 点击Install 开始安装5) …

Meta AR 眼镜团队前负责人加入 OpenAI;visionOS 2.2 Beta 引入超宽屏投屏模式丨 RTE 开发者日报
开发者朋友们大家好:这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的数据」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的…
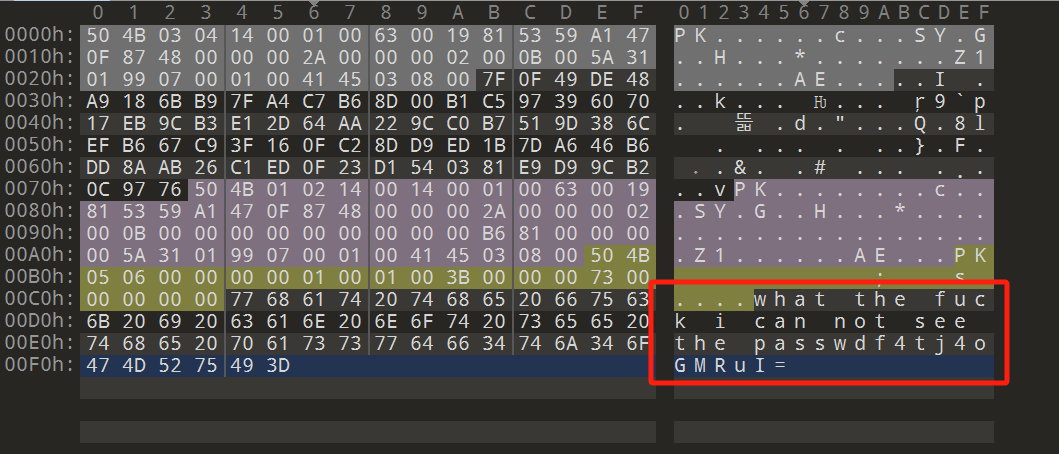
newstarctf WP存档
Week 1
Pwn
Real Login
Game
Overwrite
Gdb
Reverse
Web
Crypto
Misc
Week 2
Pwn
Reverse
Web
Crypto
Misc
Week 3
Pwn
不思議なscanf
One Last B1te
ezcanary
Easy_Shellcode
Reverse
011vm
simpleAndroid
SMc_math
flowering_shrubs
SecertsOfKawaii
PangBai 过家家(3)
取啥…

Ollama AI 框架缺陷可能导致 DoS、模型盗窃和中毒
近日,东方联盟网络安全研究人员披露了 Ollama 人工智能 (AI) 框架中的六个安全漏洞,恶意行为者可能会利用这些漏洞执行各种操作,包括拒绝服务、模型中毒和模型盗窃。知名网络安全专家、东方联盟创始人郭盛华表示:“总的来说,这些漏洞可能允许攻击者通过单个 HTTP 请求执行…
还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!前言
程序员的终极追求是什么?当系统流量大增,用户体验却丝滑依旧?没错!然而,在大量文件传输、数据传递的场景中,传统的“数据搬运”却拖慢了性能。为了解决这一痛点,Linux 推出了 零拷贝 技术,让数据高效传输几乎无需…

【日记】碰到了一个洗钱嫌疑很高的客户(755 字)
正文早上有个客户来开户,总感觉他洗钱的嫌疑很高。1. 没有财务章,甚至没有财务职位,会计工作是找的代理记账公司;2. 客户经理尽职调查时,注册地和实际经营地址不一致,3. 开企业网银觉得还不够,说外勤多,要开手机网银;4. 觉得每天 20 笔,总额 100 万的限额有些低;5. …

C++ 逆向之 forward 函数与完美转发
在进行 std::forward 函数的讲解之前,需要知道 std::move 的运行原理,还不是很清楚的朋友建议先看一下前置知识,本次内容是基于 std::move 内容的基础上进行讲解:
C++ 逆向之 move 函数
然后来讲解我们今天的主角:std::forward 函数与完美转发。
一、std::forward 函数的作…

中电金信:企业数据赋能效果差,科学试错体系了解一下?
Wuhu,咨询专题第五期内容来啦~
继先后讲解了企业数字化转型
过程中的价值创造、运营变革
以及平台化建设等难题如何解决后本期我们一起来关注
企业科学试错体系构建事情是这样的
👇 👇 👇
随着金融数字化转型的深入推进,以大数据为基础的智能化应用大量涌现,使得数…

【华为笔试-3】HJ20 密码验证合格程序
【华为笔试-3】HJ20 密码验证合格程序HJ20 密码验证程序输入:
021Abc9000
021Abc9Abc1
021ABC9000
021$bc9000输出:
OK
NG
NG
OK注:输入结束后有中止结束标志EOF【这个原题给的时候无说明,自己跑他的用例和看论坛看出来的】题解:
要点有三个,分别是:长度超过八位、包含三…

记Linux使用异常2
麒麟v10系统开机后提示如下信息,并进入initramfs模式,[0.224166][ 0l dmi: Firmware registration failed,
[0.936010][ 0] serial8250 serial8250.0: unable to register port at index 1 (IOFFFFF10204000000 MEM0 IRQ0): -22
[1.829735][ 0] i8042: i8042 controller self…

SVN集成ExcelMerge
在SVN中对比表格差异时,如果只是一个sheet的CSV表格,SVN自带的diff效果也很好,如果是多个Sheet的xlsx表格,,SVN自带的diff效果就很差
ExcelMerge是一个在Windows平台下比对Excel的工具,当Excel存在多个Sheet时也能很好的支持差异的比对,配合上svn可以很好的查看策划的数…