url:https://www.cnblogs.com/devcxx/p/18550789
一、Streamlit introduce
Streamlit is an open-source Python library for quickly building data visualization and interactive web applications. It is specifically designed for data scientists and engineers, using simple Python scripts to create powerful user interfaces. Official website:https://streamlit. .io/
二、installation and operation
1.install Streamlit:
pip install streamlit
2.launch app:
You need to create a python file, such as blog.py, and then run:
streamlit run blog.py
三、base grammar
- set page title
import streamlit as stst.title("我的第一个 Streamlit 应用")
st.header("这是一个标题")
st.subheader("这是一个子标题")
run on terminal
streamlit run blog.py
output:

- text
Use st.write to output any type of text or object.
st.text("这是普通文本")
st.markdown("**这是 Markdown 格式的文本**")
st.write("可以输出任意 Python 对象,比如数字:", 123)
output:

3.interaction
input:
user_input = st.text_input("请输入内容:")
st.write("你输入了:", user_input)
button:
if st.button("点击我"):st.write("按钮被点击了!")
selectbox:
option = st.selectbox("请选择一个选项:", ["选项 A", "选项 B", "选项 C"])
st.write("你选择了:", option)
slider:
value = st.slider("选择一个值:", 0, 100, 50)
st.write("你选择的值是:", value)
output:

4.show data
Streamlit supports multiple data visualization tools, such as Matplotlib, Altair and built-in charts.
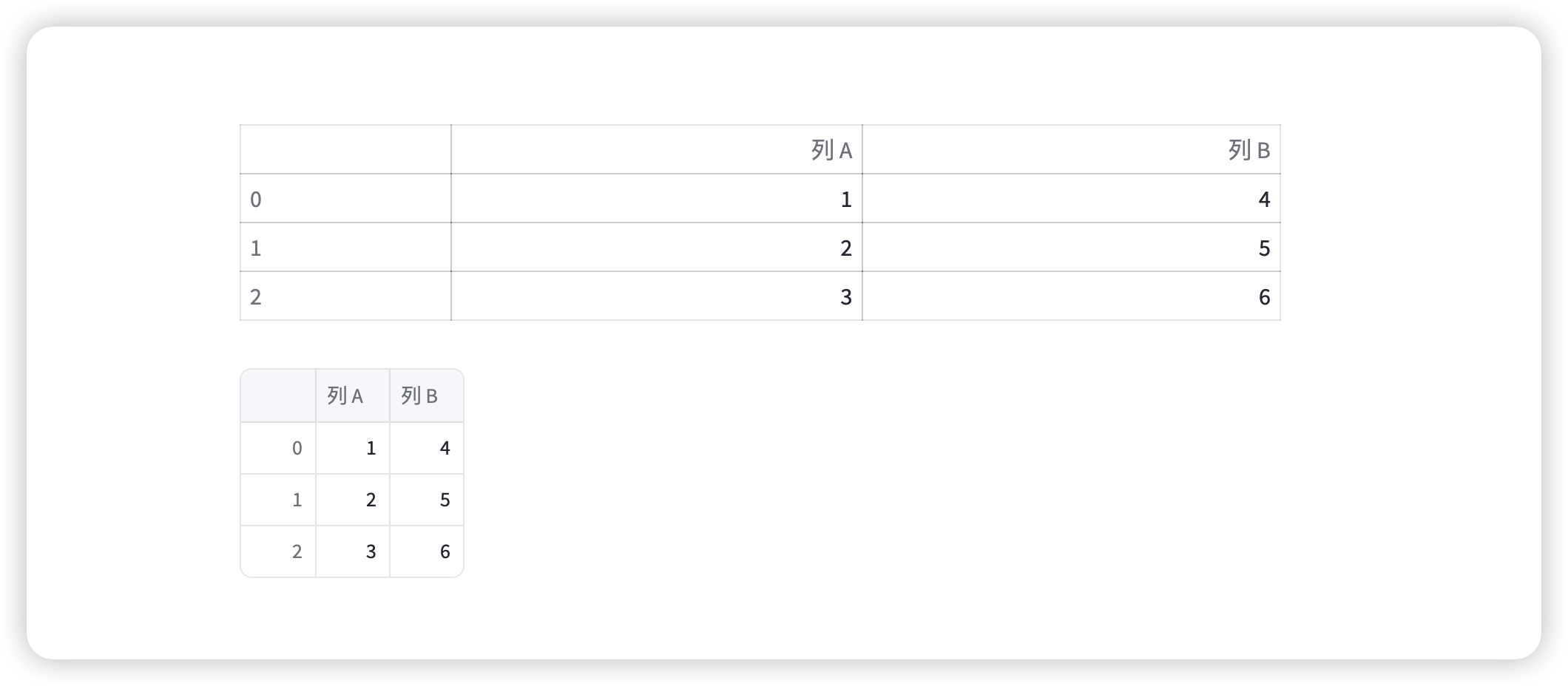
import pandas as pddata = pd.DataFrame({"列 A": [1, 2, 3], "列 B": [4, 5, 6]})
st.table(data)#dramatic table
st.dataframe(data)
5.data visualization
#plot
import numpy as np
import pandas as pddata = pd.DataFrame(np.random.randn(20, 2), columns=["列 A", "列 B"])
st.line_chart(data)#bar
st.bar_chart(data)#matplotlib图:
import matplotlib.pyplot as pltfig, ax = plt.subplots()
ax.hist([1, 2, 2, 3, 3, 3, 4, 4, 4, 4])
st.pyplot(fig)
output:

六、integrated external tools Langchain
Streamlit can be combined with external tools (eg LangChain) to complete complex tasks, or import databases to perform data queries.
Langchain Introduction:LangChain is a framework for building language model-driven applications. Its design philosophy is based on modularization and flexible architecture, sharing language models with external tools, memory modules, and multi-step logic integration, helping developers quickly implement complex Its intelligent transformation function.
Core grammar:
The LangChain Expression Language, or LCEL, is a declarative approach that allows you to easily group strings together. LCEL was designed from the ground up to support running a prototype into production without changing any code. The simplest “Hint+LLM” chain to the most complex chain (can be made more complex by a few hundred steps).
Basic example: prompt + model + output analysis
The most basic and common use case is to link the prompt template and model together.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAIprompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-4")
output_parser = StrOutputParser()chain = prompt | model | output_parserchain.invoke({"topic": "ice cream"})
core code:
chain = prompt | model | output_parser
| , The symbol is similar to the Unix pipe operator, it links different components together, making the output of one component serve as the input of the next component. In this chain string, user input is passed to the prompt template, then the output of the prompt template is passed. Model, then the output of the model is passed to the output parser. Let's look at each component to understand exactly what happened.
Langchain-Agent
The core idea of the proxy is to use LLM to select a series of actions. On the chain structure, a series of actions are hard-coded (in the code). On the proxy, the language model is used as the reasoning engine to determine what to take. Actions and their sequence.
key components
agent:
It is responsible for deciding what type of action to take next. It is based on the language model and prompt driven. The prompt can include the following content:
- Agent's personality (very useful for responding in a certain way)
- The background context of the agent (the context of the type of task is very useful)
- Invoke a better recommendation strategy (the most popular/widely used is ReAct)
tools
The tool is the proxy call function. There are two important factors to consider:
- Allow the agent to access the correct tool
2.The most helpful method description tools for the agent
If both of these are not correctly described, the agent will not be able to work. If the agent is not allowed to access the correct tools, it will never be able to accomplish its goal. If the tools are not described correctly, the agent will not know how to use them correctly.
agent-executor
This is part of the actual call agent and execution of the selected action.
next_action = agent.get_action(...)
while next_action != AgentFinish:observation = run(next_action)next_action = agent.get_action(..., next_action, observation)
return next_action
The above code includes:
- Handling agent selection missing tool situation
- Handling tools in case of error
- Handling agent generated cannot analyze output condition of tool call
- Records and observes at all levels (agent decisions, tool calls) - can be output to stdout or LangSmith
example:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
Load the proxy language model we want to use to control
llm = OpenAI(temperature=0)
Next, let's load some of the tools we want to use. Please note that the llm-math tool uses an LLM, so we need to pass it.
tools = load_tools(["serpapi", "llm-math"], llm=llm)
Finally, let's initialize a proxy using these tools, language models, and the type of proxy we want to use.
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
test
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
output:
> Entering new AgentExecutor chain...I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power.Action: SearchAction Input: "Leo DiCaprio girlfriend"Observation: Camila MorroneThought: I need to find out Camila Morrone's ageAction: SearchAction Input: "Camila Morrone age"Observation: 25 yearsThought: I need to calculate 25 raised to the 0.43 powerAction: CalculatorAction Input: 25^0.43Observation: Answer: 3.991298452658078Thought: I now know the final answerFinal Answer: Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.991298452658078.> Finished chain."Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.991298452658078."
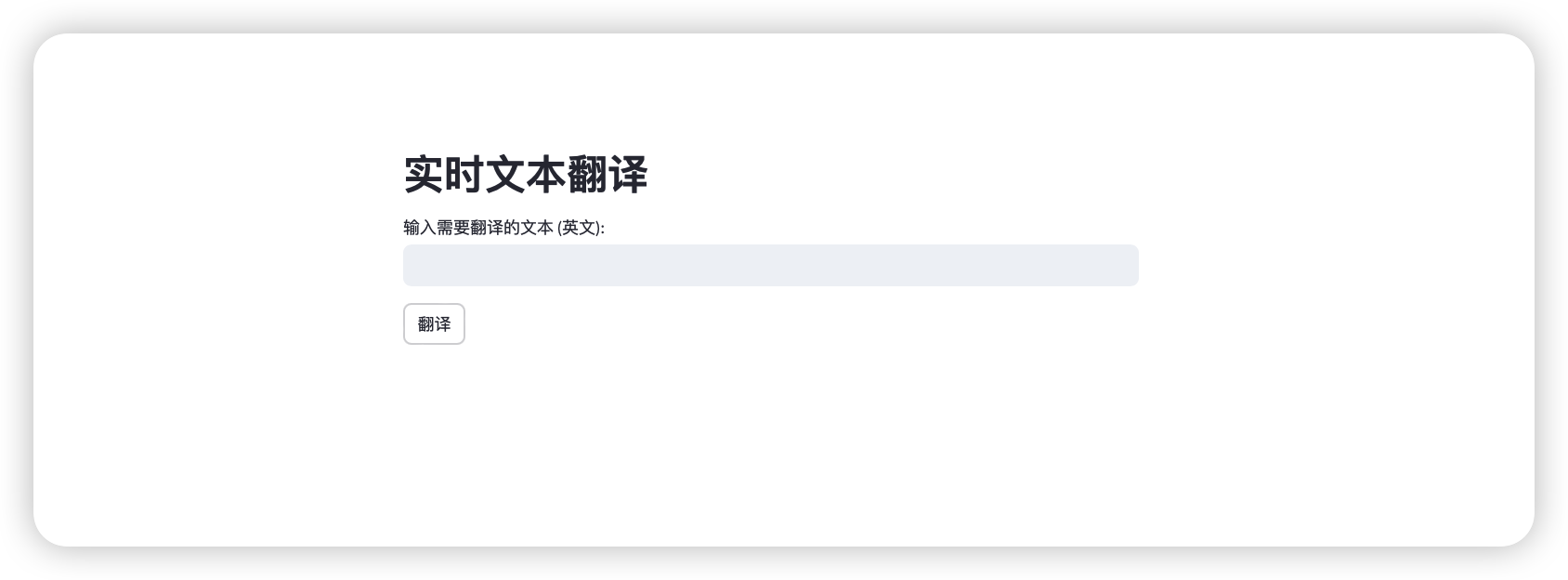
Langchain integrationstreamlit example - real-time translation project
title
st.title("实时文本翻译")
set prompt
prompt = PromptTemplate.from_template("Translate the text to French: {text}")
set module
llm = ChatOpenAI(model="gpt-4",temperature=0,max_tokens=2000,openai_api_key=api_key,request_timeout=60,http_client=httpx.Client(proxies=proxies)
)
Script LCEL, in which StrOutputParser can use the model to directly output the string result.
output_parser = StrOutputParser()
chain = prompt | llm |output_parser
input frame
input_text = st.text_input("输入需要翻译的文本 (英文):", "")
settings button and load page
if st.button("翻译"):if input_text.strip():with st.spinner("翻译中,waiting..."):try:translated_text = chain.invoke({"text": input_text})st.success("成功!")st.write(f"**法语翻译结果:** {translated_text}")except Exception as e:st.error(f"fail: {e}")else:st.warning("input must be vaild")
On terminal enter run command:
streamlit run blog.py

In the next blog, we will conduct a practical project, use the two frameworks to combine databases, and build a data analysis agent!