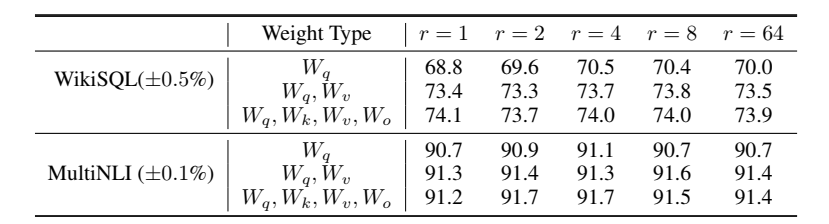
强化学习中的智能体基于目标的不同分为以下几类:
-
Policy-Based(基于策略的智能体)
- 这种智能体的目标是直接近似策略(policy),即在给定状态下选择动作的概率分布。
- 它们通常通过优化策略来最大化累积奖励。
- 示例:策略梯度方法(Policy Gradient Methods)。
-
Value-Based(基于价值函数的智能体)
- 这种智能体的目标是近似价值函数(value function),即估计在特定状态下的长期奖励总和(或在状态-动作对上的总回报)。
- 这些智能体通过价值函数的优化来间接地得出最优策略。
- 示例:Q-learning 和 Deep Q-Networks (DQN)。
-
Model-Based(基于模型的智能体)
- 这种智能体的目标是近似环境的动态模型(transition dynamics),即学习环境的状态转移概率(从一个状态到另一个状态的概率)和奖励函数。
- 一旦模型被学到,智能体可以通过模型进行规划(planning),如利用模拟预测未来。
- 示例:动态规划(Dynamic Programming)方法。
-
Actor-Critic(行为者-评论者智能体)
- 这种智能体结合了基于策略和基于价值函数的特点。
- 行为者(Actor)负责学习和输出策略,而评论者(Critic)负责估计价值函数,并通过其反馈改进策略。
- 这种方法的优势是策略优化的稳定性更高,结合了两种方法的优点。
- 示例:A3C(Asynchronous Advantage Actor-Critic)。
总结:
强化学习智能体可以通过上述任意一种或多种方式设计。每种方法都有其适用的场景和特点:
- 基于策略的适合连续动作空间问题。
- 基于价值函数的适合离散动作空间问题。
- 基于模型的适合需要高效探索的场景。
- Actor-Critic 适合需要结合稳定性与效率的场景。