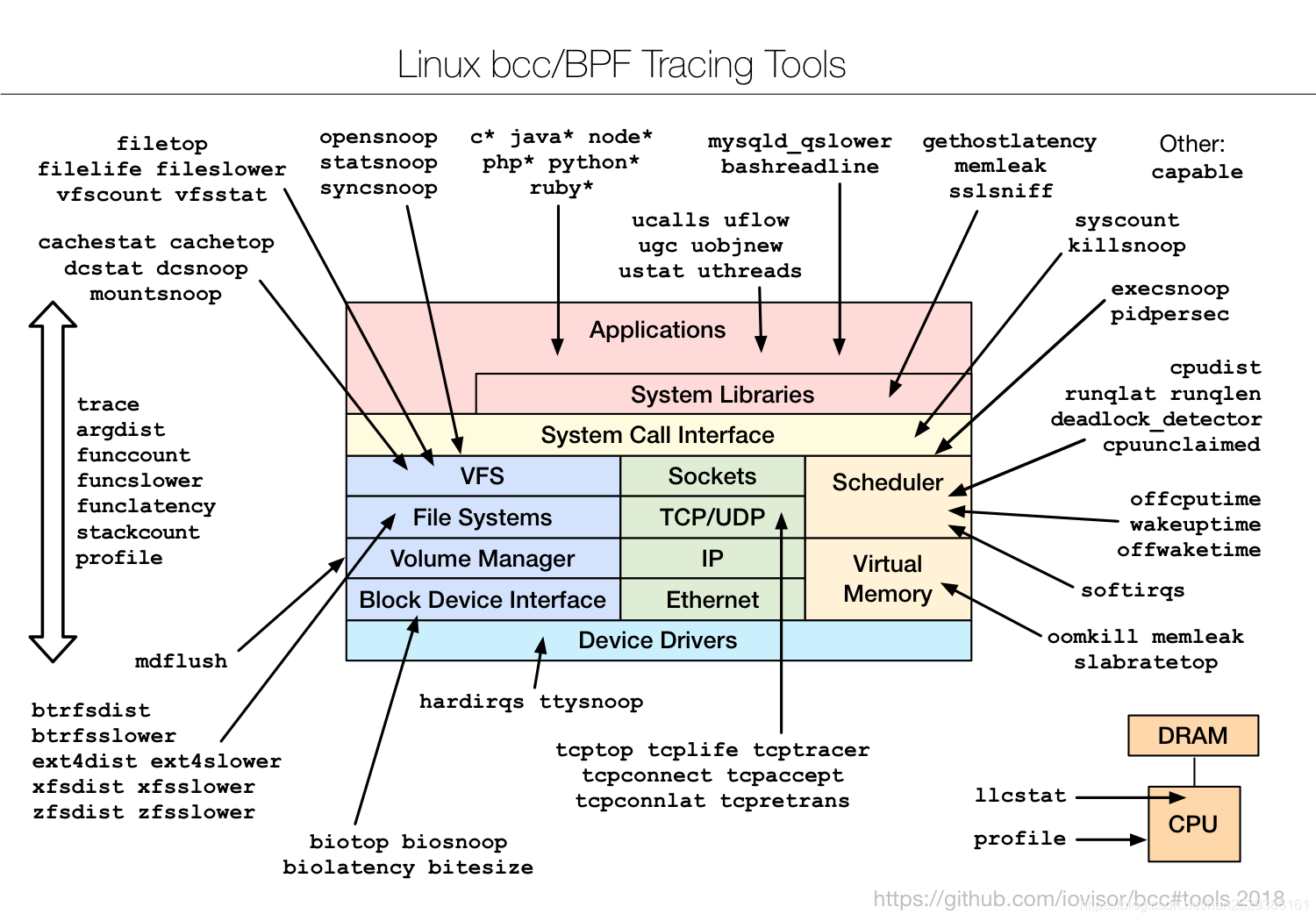
虚拟内存与物理内存
计算机系统把内存组织成固定大小的页( page),页的大小是基于处理器架构的,例如在 x86_64 上标准的页为 4K。物理内存被划分为页帧(frames),一个页帧包含一页数据。
进程不会直接寻址物理内存,每个进程都有一个虚拟地址空间,当进程请求内存时,内核通过查找页表将页帧的物理地址映射到进程地址空间中的虚拟地址。例如:
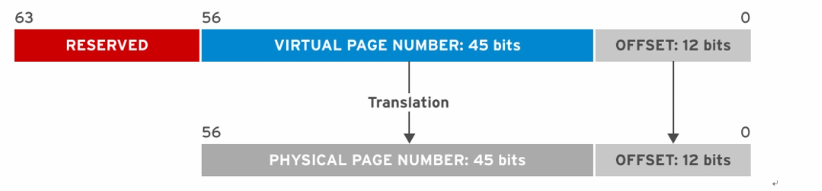
1、进程先使用 45bit 去寻址页帧(物理页)
2、内核将私有虚拟页号(45bit)转换为带有数据的物理页。
3、对于物理页面地址,进程使用低 12bit 作为偏移量来访问页面中的数据。
使用 ps和 top 指令可以查看到虚拟内存和物理内存。例如

页面错误(page faults )
每个进程都维护自己的虚拟地址空间,每个进程都拥有一张页表(page table),它用来跟踪虚拟页面到物理页面的映射。
页面错误:
Minor page fault:要访问的内存不在虚拟地址空间,但是在物理内存中,只需要建立映射关系即可,然后从 RAM 分配新的物理页面。
Major page fault:要访问的物理页不虚拟地址空间,也不在物理内存中,需要从慢速设备(磁盘)中载入。这种事件严重影响性能。
通过使用 ps指令查看 page faults,例如:

或者通过 perf 采用收集 page faults 事件,例如
TLB
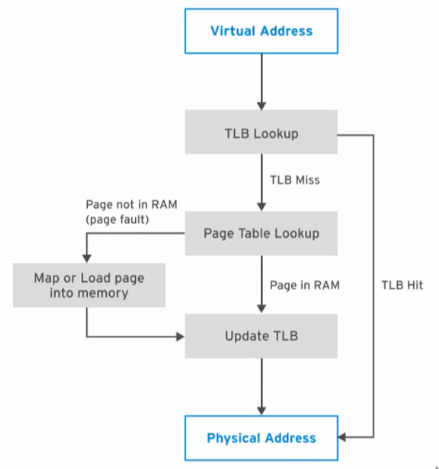
TLB 是CPU 中的一个高速缓存,它记录最近使用的页面映射来加速地址转换。因为总是查页表效率低下。
管理大页
TLB是CPU 中的一块空间极小的缓存区域,缓存的内容是虚拟地址到物理地址的映射关系,为了提供TLB 的 hit 率,应在 TLB 中尽量多的增加缓存数量,从而提供性能。
通过增加页面的大小(默认为 4K),可以大大减少TLB的 miss率,在x86 64 位中,可以支持 2M甚至 1G 的页面大小。默认是使用 2M。可以通过在/proc/meminfo 中查看到。
可以通过使用 vm.nr_hugepages 来设置所需的大页数量,例如:。

注意:分配大页内存的前提是必须有足够多的且连续的内存。为了能够使用大页,需要挂载 hugetlbfs 文件系统,例如:

使用透明大页
从 RHEL6.2 版本后,内核支持了透明大页(THP)功能。通过在/sys/kernel/mm/transparent_hugepage,目录下的设置,可以进行设置
Always:开启THP
Never:禁止THP
Madvise:禁止自动 THP 分配,希望使用THP 的进程必须同 madvise()系统调用通知内核。
注意:THP 不适合在数据库服务中使用。
配置页回收
Pagecache:内核使用未分配的内存作为缓存,当下次有进程需要访问数据时,直接从缓存中获得,提供了访问速度。
Anonymous pages:匿名页面是与磁盘上的数据无关联的,是用于存储器工作数据的页面。使用 free 命令查看,例如:

回收匿名页面
当内存不足时,内核可以选择从 pagecache中回收页面或回收匿名页面,没有文件背景的匿名页面可以被移动到交换分区中(swap),这些被回收的页面可以用于其他进程。
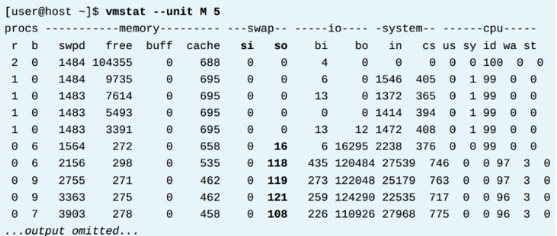
使用 vmstat 命令可以查看到 swap 信息,例如:
回收页面和配置 swappiness
当内核需要释放内存时,有两种方式:
-
将进程的匿名页换出到 swap 空间。
-
从 pagecache 中丢弃页,因为 pagecache 中的页面来自磁盘,因此当数据发送变换时(脏页)系统将其写回磁盘并回收页面。
通过使用 vm.swappiness,内核参数来影响内核的选择。该参数的数值为 0-100。
-
增大该值,系统会更加倾向使用 swap,内核更多保留页面缓存,提高了I/O 性能。
-
减小该值,系统尽量可能少的进行交换。提高了响应速度。
调整脏页清理
在/proc/meminfo 中可以查看到页面的不同状态
-
Free:该页面可以立即分配
-
Active:正在积极使用中的页面
-
Inactive clean:与磁盘中的内容一致,并且未被使用
-
Inactive dirty:内容已经被修改,还没被写回,回收inactive clean 类型的页面比较方便,但回收inactive dirty 类型的页面比较麻烦。
由于内存是易失性的,因此需要及时把内存中的数据写回磁盘。系统通过使用 flush 内核线程来处理脏页写回每个块设备上都会运行该线程。
通过一组 sysctl 参数控制 fush 线程的动作:
-
vm.dirty_expire_centisecs:指定脏页能够存活的最大时间(1/100秒),防止太过频繁的写回动作。
-
vm.dirty_writeback _centisecs:多久唤醒一次 flush 线程。
-
vm.dirty_background_ratio:脏页占总内存的百分比。
-
vm.dirty_ratio:脏页填充的绝对最大内存量,达到该值时,阻塞所有I/O,所有脏页必须写回。
注意:vm.dirty_background_bytes 和 vm.dirty_bytes 可以替代vm.dirty_background_ratio 和Vm.dirty_ratio。
管理内存不足
当出现内存不足时,一个名为 Out-memory killer(OOM)的内核子系统随机选择杀死一个进程来释放内存,如果条件仍然存在,系统会再次出发 OOM。
这样随机杀进程会造成程序有损害,因此可以设置vm.panic_on_oom,参数,将其值调节为 1。该值代表当内存不足时,系统 linux 进入崩溃,而不是随机杀进程。
每个进程都有一个维护“坏值”的文件,可以在/proc/PID/oom_score,中查看。数值越高越有可能被杀死。而内核和 systemd 进程对 OOM 免疫。可以手工调节“坏值”,范围是-1000 到 1000。默认为0,如果设置为-1000,则该进程免疫。
使用 systemd 调整内存不足评分
要对某个程序进行调节,可以在[Service]段落中设置 OOMScoreAdjust 参数,例如:
NUMA 架构
在老的多处理器系统中使用 UMA 架构,所有内存都可以被 CPU 平等访问。
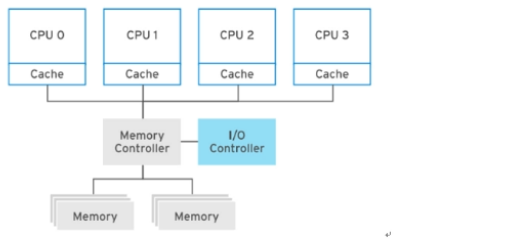
现代的多处理器系统使用 NUMA架构,每个CPU 组都可以访问一组内存,并通过高速链路将CPU互连。整个内存仍然可以被其他 CPU 访问,但访问本地内存要比通过互连访问远程内存快。
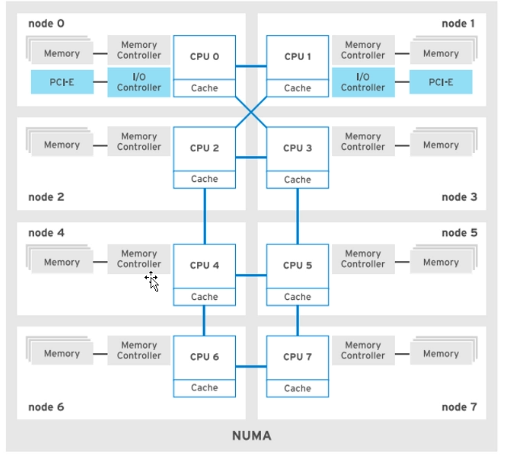
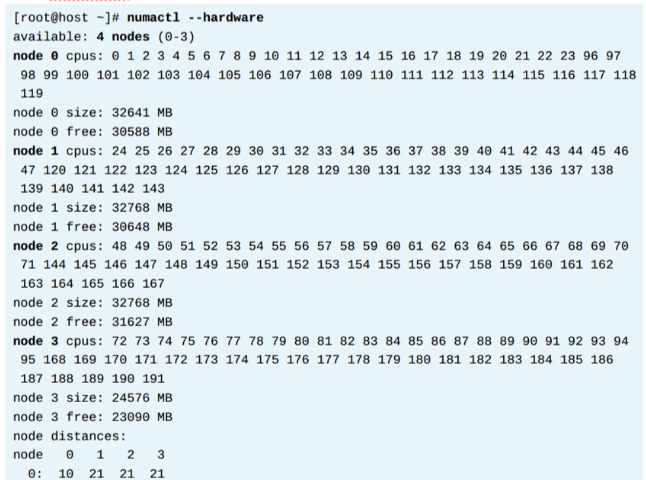
使用 numactl --hardware命令查看NUMA拓扑,例如:

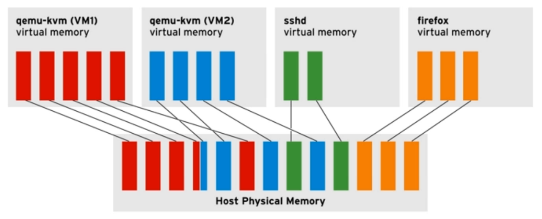
**管理内存 overcommit **
内核允许给进程分配超过可用内存的内存量。因为当进程请求内存时,内核只分配虚拟内存,并没有分配真实的物理内存。直到进程开始使用物理页面。
通过调整 vm.overcommit_memory 参数对过多分配进行调整:
- 0:默认值(从RHEL6),允许overcommit。过于严重的申请将会失败。
- 1:允许 overcommit,申请时不检查,永远分配成功。
- 2:禁止 overcommit,只能申请 swap+RAM*50%的大小。通过调整vm.overcommit_ratio