这篇文章是笔者阅读《深度学习推荐系统》第五章推荐系统的评估的学习笔记,在原文的基础上增加了自己的理解以及内容的补充,在未来的日子里会不断完善这篇文章的相关工作。
离线评估
在离线环境中利用已有的数据划分训练集和测试集对模型进行评估
划分数据集方法
机器学习常用划分方法:Holdout法、交叉验证、留一法、自助法
客观评价指标
机器学习模型常用指标:准确率、精确率、召回率、均方根误差、对数损失
对于推荐模型,点击率的预测(预测模型)正确与否并不是最终目标,最重要的是输出一个用户感兴趣的物品列表(排序模型),排序模型是根据模型的输出概率对兴趣物品排序,因此应该采用适合评估排序序列的指标来评估模型。
P-R曲线
- why work(能够更关注正样本的分数)
P-R曲线是精确率-查全率曲线,精确率和查全率两个指标都是关于正样本的相关计算,当阈值设置高时,查全率低,此时得分越高的物品被优先推荐,而不是简单的实现二分类,因此,P-R曲线更适合排序模型。
- 参考学习链接:
ROC/AUC
- why work
- 参考学习链接:【评价指标】ROC曲线与AUC-CSDN博客
mAP
NDCG
[!NOTE]
编者提到了在真正的离线实验中并不需要选择过多的评价指标,更重要的是快速定位,排除不可行的思路。
A/B 测试
又称为“分桶测试”、“分流测试”,设置单一变量,通过实验组A与对照组B进行对比评估,是模型上线前的最后一道测试,与离线测试不同,离线测试无法消除有偏数据的影响,并且无法还原实际工程环境(数据丢失、网络延迟)
分桶原则
-
层与层之间正交:层与层之间的对照实验时独立的,不相互影响;
-
同层之间互斥:同一个数据用于不同的实验组;

评估指标
与离线测试不同,线上测试能够直接计算业务的核心指标,因此更注重对点击率、转化率等实际业务之表的对比。
存在的问题
- A/B测试占用了过多的资源,当新提出的模型推荐效果差时还会对用户造成损害;
- 分组用户样本分布不平衡
Interleaving
Interleaving是一种快速线上评估方法,在大量初始算法中筛选出work的算法再进行A/B测试,解决A/B测试在测试时样本可能分布不平衡的问题,对相同用户给与两种方案,看用户更喜欢哪种(类似于chatgpt有时会给两种方案看用户更喜欢哪种)
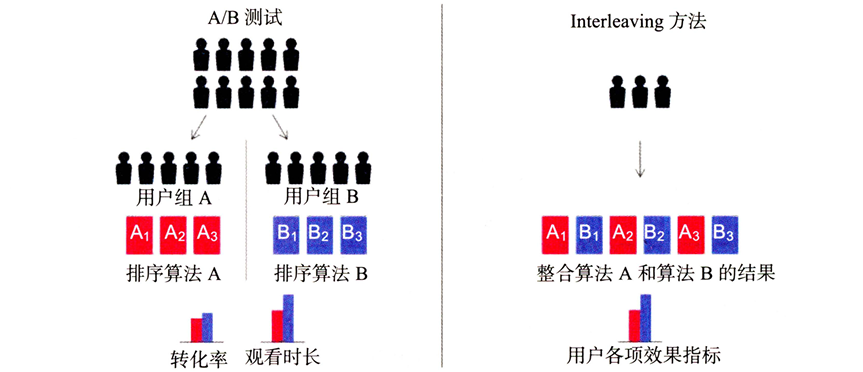
缺点
- 需要大量的辅助性数据标识;
- 只能对算法的相对评估;
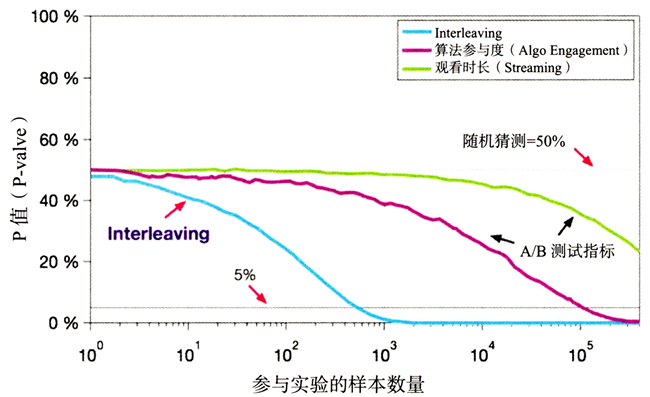
灵敏度对比
需要多少样本才可以评估不同算法的优劣性,图中可以看出, Interleaving 方法利用\(10^3\)个样本就能判定算法 A是否比 B 好,而 A/B 测试则需要\(10^5\)个样本才能将 p-value 降到 5%以下。这就意味着利用一组 A/B 测试的资源,可以做 100 组 Interleaving 实验,这无疑极大地加强了线上测试的能力。