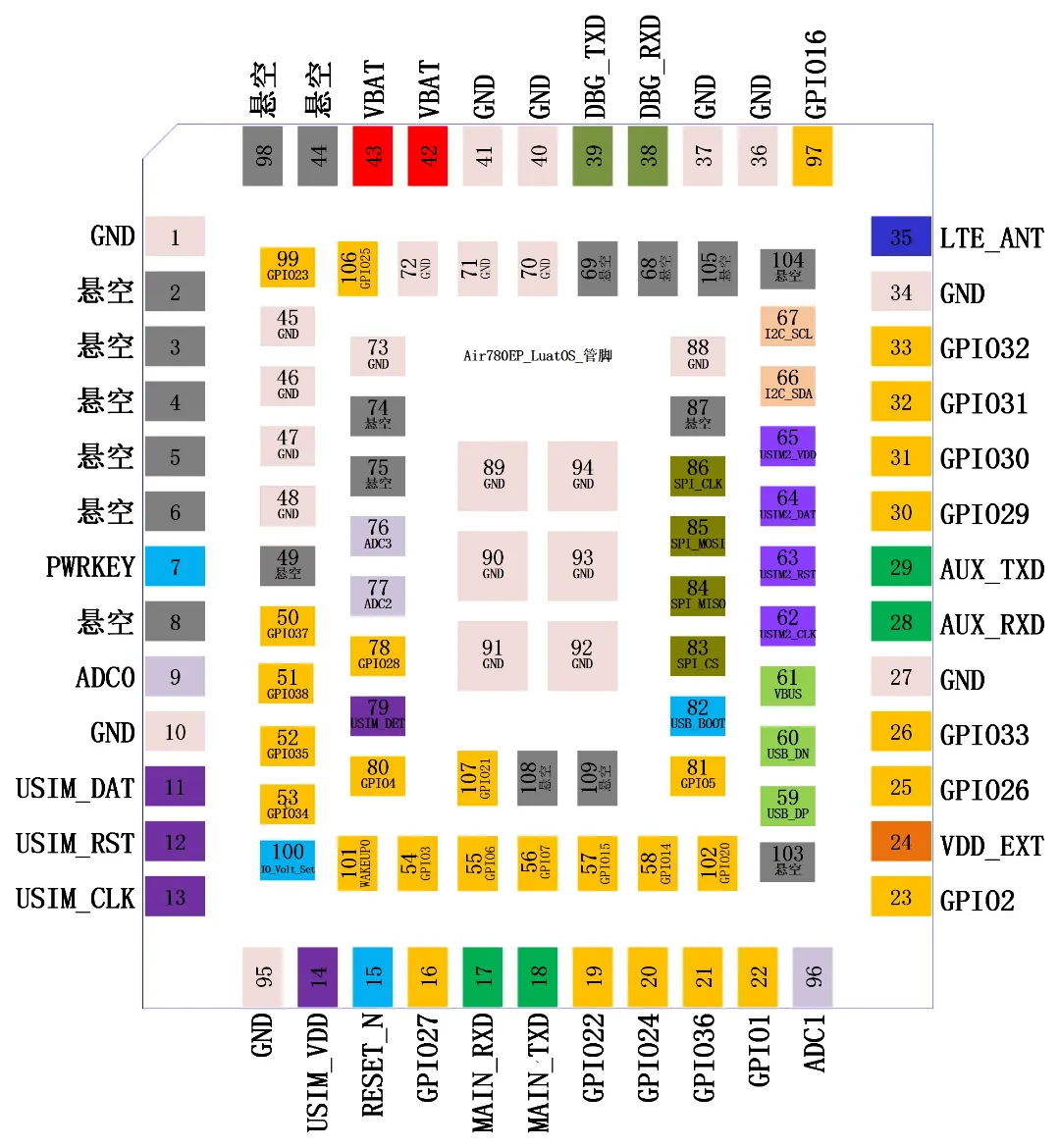
前言
在 Kafka 中,消息偏移量是什么?是文件中的索引吗?又是如何通过偏移量快速定位消息的?本文将深入探讨这些问题,帮助你更好地理解 Kafka 的偏移量机制。
Kafka 的偏移量是什么?
Kafka 中的 偏移量 实际上是每条消息的 序号。它为每条消息提供了一个唯一的标识。通过偏移量,消费者可以准确地找到并读取特定的消息。
偏移量在 Topic 中是唯一的吗?
答案是否定的,偏移量 仅在每个分区内是唯一的。一个 Topic 可能有多个分区,每个分区的消息都有一个递增的偏移量。因此,Kafka 不需要对所有分区的消息偏移量进行全局同步。每个分区独立管理自己的偏移量,这不仅减少了复杂性,还降低了性能开销。
消息的偏移量由谁决定?客户端还是服务端?
偏移量是由 服务端 决定的。客户端无法了解其他客户端的偏移量情况,如果由客户端决定,则需要额外的同步成本来实现全局偏移量管理。所以,消息的偏移量是由 Kafka 服务端来维护的。
单调递增的序号是否会达到最大值?
理论上,不会。Kafka 使用 64 位长整型(long)作为偏移量,其最大值为 2^63 - 1,即 9223372036854775807。在正常的消息生产速率下,偏移量的增长将持续数百年,远远不需要担心达到最大值。
举个例子:假设每个分区每秒钟写入 1 万条消息,那么偏移量达到上限大约需要 29,200 年。如此长的时间,几乎可以忽略不计。
Kafka 如何根据消息偏移量定位到文件中的位置?
既然我们知道 Kafka 的消息存储在文件中,那么问题就来了:如何根据“序号”定位到文件中的具体位置呢?
答案是 索引文件。Kafka 为每个分区维护一个索引文件,该文件记录了每个消息的偏移量及其对应的存储位置。通过索引文件,Kafka 可以非常快速地定位到某个偏移量对应的消息存储位置。
实际上,索引文件通常记录的是消息的起始位置,而每条消息的结束位置可以通过消息头来确定。
联想:Socket 通道的数据处理
这种设计让我联想到 Socket 通道 中的数据处理。Socket 通道也是连续的字节流,服务端根据 消息头 来解析报文的起始和结束位置,从而确定数据的边界。服务端可以连续地从字节流中提取完整的报文进行处理。
相同之处:
- 都是通过消息头来解析数据边界。
不同之处:
- Socket 通道中的数据是即时消费的,而 Kafka 的数据存储在磁盘中,等待被消费。
- Kafka 消费者并不是从头开始消费,而是从特定的偏移量位置开始消费,这需要额外的定位操作,即通过索引文件来定位消息的起始位置。
Kafka 如何高效读取多条消息?
假设我们要读取一批消息,比如 100 条。显然,Kafka 不会每次都查找索引文件并定位单独的消息偏移量。实际情况是,Kafka 会根据 起始消息的位置 和 最后一条消息的位置,一次性将这一段消息批量读取出来。通过这种方式,Kafka 避免了多次查询索引文件,从而显著提高了读取效率。
一个分区的日志段文件有多个,具体如何实现?
Kafka 的日志段文件有最大值(log.segment.bytes)和最大存活时间(log.segment.ms)限制。
当文件达到最大大小或超过最大存活时间时,Kafka 会关闭旧文件并开启新文件。
那么,是每个分区只有一个索引文件吗?
答案是否定的。实际上,每个日志段文件(以 .log 为后缀)都有一个对应的 索引文件(以 .index 为后缀)。
注意:关闭日志段仅意味着它不再接受新的消息写入,但已经存储的数据仍然可以被消费者访问。
日志段在被删除之前都能被访问,至于何时删除详见保留配置 log.retention.*
如何知道要查找哪个文件?
每个日志段文件的文件名就是该段的 起始偏移量。通过文件名,你可以知道消息存储在哪个文件中。接着,Kafka 通过该文件的索引文件来找到消息的具体位置。
- 00000000000000000000.log(偏移量从 0 到 9999)
- 00000000000000000000.index
- 00000000000000010000.log(偏移量从 10000 到 19999)
- 00000000000000010000.index
既然索引可以直接定位,Kafka为何还要限制日志段文件的大小?
因为内存映射。 Kafka 使用内存映射文件(Memory Mapped Files)来高效地处理日志的读取和写入。内存映射文件将文件映射到内存中,这样 Kafka 可以直接在内存中读取或写入数据,而无需频繁进行 I/O 操作,从而大大提高了性能。
但是,操作系统对内存映射文件的大小是有限制的,因此 Kafka 会限制单个日志段文件的大小。具体来说:
-
操作系统的内存映射限制: 每个操作系统对于内存映射的文件大小都有一定的限制。单个文件过大可能会超出这一限制,从而影响性能,甚至导致程序崩溃。
-
内存占用问题: 内存映射会将文件的部分内容加载到系统内存中,文件过大时,可能会导致系统内存占用过多,从而影响其他进程或系统的稳定性。尤其是在高负载环境下,操作系统可能无法为过大的文件提供足够的内存资源。
题外话:
1.正因如此,Kafka 通常建议将其单独部署在独立的服务器上,避免与其他应用争夺内存资源。这样能够确保 Kafka 的内存映射操作更加高效,并减少内存资源的竞争。
2.为了吞吐量,Kafka不会主动刷盘,刷盘依赖操作系统。刷新时间可能在几秒到几分钟之间。