Transformer可以接收一整段序列,然后使用self-attention机制来学习它们之间的依赖关系,但其在语言建模时受到固定长度上下文的限制(固定长度的输入、绝对位置编码的限制、注意力机制的计算复杂度)。
Transformer-XL以此为基础,引入一个片段级递归机制和一种新的位置编码方案,从而可以在不破坏时间连贯性的情况下实现超出固定长度的学习依赖性。
Vanilla Transformer 语言模型

标准的Transformer模型具有固定的输入长度限制,通常通过设置一个最大序列长度,以适应模型的内存和计算能力。当处理超过这个长度的文本时,Vanilla Transformer 通常将文本切分为多个独立处理的段落,每个段落独立进行模型训练和推理,而不共享跨段落的上下文信息(1.a)。这意味着,对于跨段落或跨文本的语义关系和依赖,模型无法充分捕捉,从而影响其对整体内容的理解和生成的连贯性。
在评估阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测(1.b)。
具有状态重用的段级循环
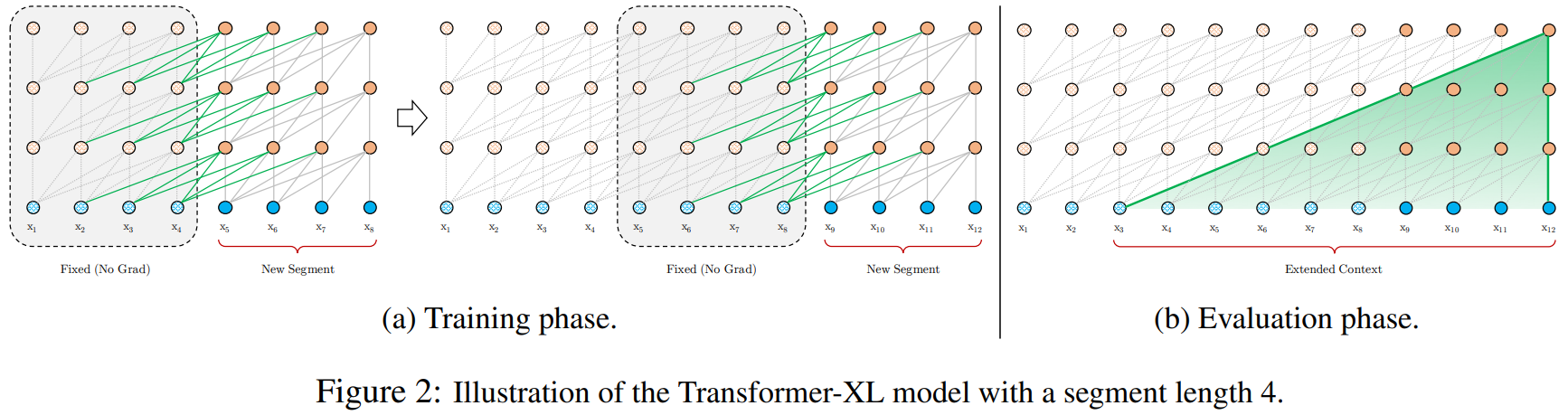
Transformer-XL与Vanilla Transformer思路一致,依旧使用分段机制,但Transformer-XL引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。
在训练期间,前一个段计算的隐藏状态序列被固定并缓存,以便在模型处理下一个新段时作为扩展上下文重用(2.a中的绿线)。将段内上下文和扩展上下文进行拼接,作为扩展后的上下文隐藏状态。这种额外的输入允许网络利用历史记录中的信息,从而能够对长期依赖关系进行建模并避免上下文碎片化。
相对位置编码
如果每个段直接使用Transformer中的位置编码,就会出现不同段的第i个位置具有相同的位置编码,但不同段对当前段的重要性不同,因此应当区分。
在Transformer中,\(q^T_i\)和\(k_j\)之间的注意力分数为:
展开之后就是:
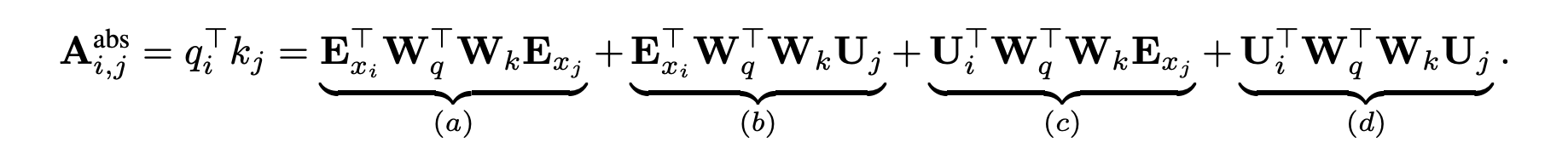
Transformer-XL使用词之间的相对距离进行位置编码,引入可变参数\(u\)和\(v\)作为全局偏置向量。
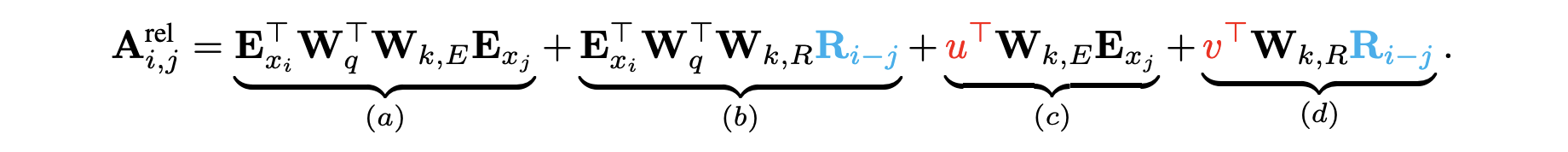
- 绝对位置向量\(U_j\)转换为相对位置向量\(R_{i-j}\),这是固定的编码向量,不需要学习。
- 引入可训练参数\(u\)来替换(3)中的\(U_i^TW_q^T\),表示内容全局偏置向量,引入可训练参数\(v\)来替换(4)中的\(U_i^TW_q^T\),表示位置相关的全局偏置向量。
- 同时将权重变换矩阵\(W_k\)转换为\(W_{k,E}\)(内容相关)和\(W_{k,R}\)(位置相关)。
在新的参数化下,(a)表示基于内容的寻址;(b)表示基于内容的位置偏差;(c)表示全局内容偏差;(d)表示全局位置偏差。
整体计算公式
具有单个注意力头的 N 层 Transformer-XL 的计算过程:

- 其中,\(\tau\)表示第几段,\(n\)表示第几层,\(SG(·)为停止梯度\),\(h_{\tau }^0 := E_{s_{\tau}}\)为词嵌入序列。
————————————————————
论文链接:https://arxiv.org/pdf/1901.02860