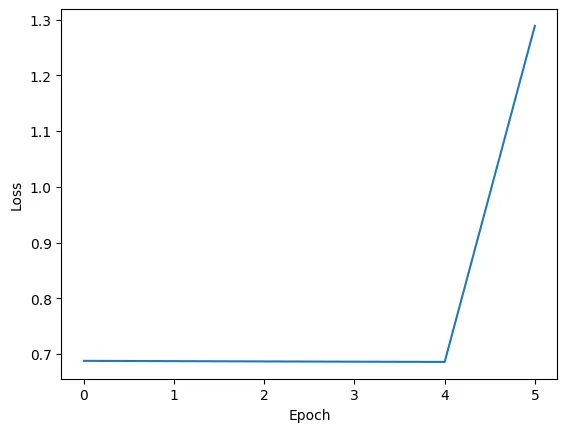
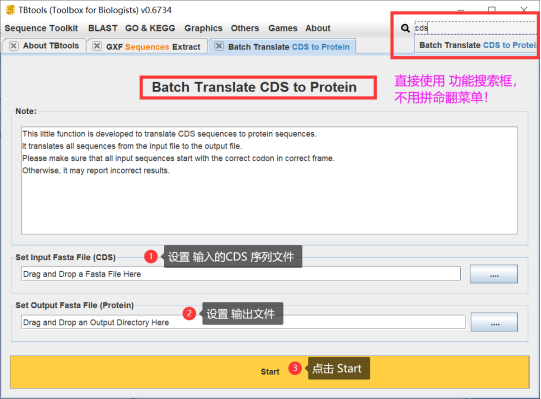
1. 双精度浮点向量处理器
双精度浮点向量处理涉及到对双精度浮点数构成的向量进行各种数学运算和操作。
双精度浮点数(double precision floating-point number) 使用64位(8字节)来存储一个浮点数,可以表示十进制的15或16位有效数字。这种数据类型在科学计算、工程应用、金融分析和高性能计算等领域中被广泛使用。
双精度浮点向量处理的应用
科学计算和工程应用:在数值模拟、大规模计算、天文学、物理学和工程计算等领域,双精度浮点向量处理用于求解复杂的数学模型和算法,以获得更准确的结果。
图形和游戏开发:在3D图形渲染中,双精度浮点数被用于坐标变换、光照计算和纹理映射等环节,以提高渲染质量和精确度。
金融分析:双精度浮点数可以处理更大的数值范围和更高的精度,确保金融计算结果的准确性和可靠性。
双精度浮点向量处理的实现
硬件支持:现代处理器通常具备浮点处理单元(FPU),如ARM的VFP(Vector Floating Point)和NEON,可以高效地处理双精度浮点向量运算。
兜兜转转最后还是回来这个FPU了
例如,NEON支持双精度浮点和完整IEEE 754操作,包括舍入模式、非规范化数字和NaN处理。
软件实现:在编程语言中,如C/C++和Java,可以通过定义双精度浮点数数组或使用专门的向量库来实现双精度浮点向量的处理。例如,在Java中,可以使用向量类来处理数学运算。
双精度浮点向量处理在需要高精度和大范围数值表示的应用中具有重要作用,但其存储空间和计算开销相对较大,因此在实际应用中需要根据具体需求进行权衡。
2. L1Cache
L1 Cache(一级缓存)是位于CPU内部的高速缓存,直接与CPU核心相连。它通常分为数据缓存(Data Cache,简称D-cache)和指令缓存(Instruction Cache,简称I-cache)。数据缓存用于存储CPU正在处理的数据,而指令缓存用于存储CPU正在执行的指令。
L1 Cache的特点:
位置:L1 Cache位于CPU内部,非常接近处理器核心。
速度:由于其位置靠近CPU核心,L1 Cache的访问速度非常快,通常比主内存快几个数量级。
容量:L1 Cache的容量相对较小,通常每个核心的L1 Cache容量范围在128 KB到2 MB之间。
结构:L1 Cache通常由静态RAM(SRAM)组成,这种存储器虽然成本较高,但速度非常快。
L1 Cache的作用
提高性能:通过存储最近访问的数据和指令,L1 Cache可以减少CPU访问主内存的次数,从而提高数据访问速度和整体性能。
减少延迟:由于L1 Cache的访问延迟非常低,它可以显著减少CPU等待数据的时间,提高程序的执行效率。
L1 Cache的工作原理
缓存命中:当CPU需要访问数据或指令时,首先会在L1 Cache中查找。如果所需数据或指令在L1 Cache中,则称为缓存命中,CPU可以直接从L1 Cache中读取。
缓存未命中:如果L1 Cache中没有所需数据或指令,则会发生缓存未命中,CPU将访问更高级别的缓存(如L2 Cache)或主内存。
L1 Cache的设计和实现对CPU的性能有着重要影响,它通过减少访问延迟和提高数据访问速度,显著提升了计算机的整体性能。
指令缓存(Instruction Cache,简称ICache)是计算机体系结构中的一个关键组件,专门用于存储CPU执行指令时需要的指令代码。其主要作用是减少CPU从主内存中读取指令代码的次数,从而提高指令执行的速度。
ICache的特点
位置:ICache位于CPU内部,非常接近处理器核心。
速度:由于其位置靠近CPU核心,ICache的访问速度非常快,通常比主内存快几个数量级。
容量:ICache的容量相对较小,通常每个核心的ICache容量范围在16 KB到64 KB之间。
只读性:由于指令通常不会被修改,ICache在硬件设计上可以是只读的,这在一定程度上降低了硬件设计的成本。
ICache的工作原理
缓存命中:当CPU需要执行一个指令时,会首先检查ICache中是否已经缓存了该指令。如果所需的指令已在ICache中,则称为缓存命中,CPU可以直接从ICache中快速读取指令。
缓存未命中:如果ICache中没有所需指令,则会发生缓存未命中,CPU将从主内存中读取指令,并将其存储到ICache中。
ICache通过减少CPU访问主内存的次数,显著提高了指令的访问速度和程序的执行效率。
3. GPR是什么
GPR是“通用寄存器”(General Purpose Register)的缩写,它是处理器中用于存储和处理数据的寄存器。通用寄存器在不同的处理器架构中数量和名称可能有所不同,但它们的基本功能是相似的。
GPR的作用
存储临时数据:GPR用于存储程序执行过程中产生的临时数据,如变量、中间计算结果等。
传递参数:在函数调用过程中,GPR可以用来传递函数参数。
存储地址和指针:GPR还可以存储内存地址和指针,用于访问内存中的数据。
常见的GPR
x86架构:包括EAX、EBX、ECX、EDX、ESP、EBP、ESI、EDI等。
ARM架构:包括R0、R1、R2、R3等。
RISC-V架构:定义了32个整型通用寄存器。
通用寄存器是处理器设计中的重要组成部分,对于计算机系统的整体性能和效率有着至关重要的影响。
4. 结果旁路的介绍
结果旁路(Bypass)是一种在计算机体系结构中用于解决指令流水线中的数据冒险的技术。其基本原理是当一条指令的执行结果被后续指令所需要时,不必等到该结果被写回到寄存器中,而是直接将结果从执行阶段传递到后续指令的执行阶段。这样可以避免流水线的停顿,提高处理器的性能。
应用领域
处理器设计:在现代处理器的指令流水线中,结果旁路技术被广泛应用,以减少数据冒险导致的流水线停顿。
计算机组成原理:在教学和研究中,结果旁路是理解现代处理器如何高效执行指令的重要概念。
通过结果旁路,处理器能够在指令流水线中更高效地处理数据依赖问题,从而提高整体的执行效率和性能。
5. 超标量弱乱序介绍一下
超标量弱乱序(Superscalar Out-of-Order Execution)是现代处理器设计中的一种技术,旨在提高指令执行的效率和性能。以下是其核心概念和特点:
超标量架构
定义:超标量架构是指处理器能够在单个时钟周期内同时执行多条指令。它通过增加指令流水线的宽度来实现,使得多个执行单元可以并行工作。
优势:相比于传统的标量架构(每个时钟周期只能执行一条指令),超标量架构可以显著提高处理器的吞吐量,充分利用硬件资源,从而提升程序的执行速度。
弱乱序执行
定义:弱乱序执行是指处理器在执行指令时,允许指令的执行顺序与程序中的指令顺序不完全一致,但最终结果仍然保持正确的程序顺序。
实现机制:
指令重排序:处理器会根据指令的依赖关系和资源可用性,动态地调整指令的执行顺序。例如,如果一条指令的执行依赖于另一条指令的结果,那么它会等待依赖指令完成后才开始执行。
寄存器重命名:为了避免寄存器冲突,处理器会使用一组额外的寄存器来存储中间结果,并通过寄存器重命名技术来消除寄存器之间的依赖。
优势:
提高指令级并行性:通过允许指令乱序执行,处理器可以更好地利用指令间的并行性,减少因指令依赖而导致的流水线停顿。
提高资源利用率:弱乱序执行使得处理器的执行单元可以更充分地工作,减少了空闲时间,提高了整体的资源利用率。
应用场景
高性能计算:在需要大量计算和数据处理的应用中,如科学计算、工程模拟、图形渲染等,超标量弱乱序技术可以显著提高处理器的计算效率。
复杂程序执行:对于包含复杂控制流和数据依赖的程序,如操作系统、数据库管理系统等,该技术能够更好地处理指令间的依赖关系,提高程序的执行速度。
挑战与优化
复杂度增加:超标量弱乱序架构的设计和实现相对复杂,需要处理大量的指令依赖和资源调度问题。
功耗和面积:由于需要更多的硬件资源来支持指令的乱序执行和寄存器重命名等操作,超标量弱乱序处理器的功耗和芯片面积相对较大。
优化策略:
动态调度算法:改进指令调度算法,更智能地预测指令的依赖关系和执行顺序,以提高指令执行的效率。
微架构优化:通过优化处理器的微架构设计,如增加执行单元的数量、改进寄存器重命名机制等,来进一步提升超标量弱乱序处理器的性能。
总的来说,超标量弱乱序技术是现代处理器设计中的重要方向之一,它通过提高指令执行的并行性和资源利用率,显著提升了处理器的性能和效率。
6. Loop Buffer
环形缓冲区(Ring Buffer)可以形象地理解为一个固定大小的环形跑道,数据在这个跑道上循环前进。当数据到达跑道的终点时,会自动回到起点继续前进。这种设计使得数据的存储和访问非常高效,因为不需要频繁地分配和释放内存空间,只需在固定大小的缓冲区内循环使用即可。
形象解释
想象一下,你有一个固定大小的环形跑道,上面有多个小车(数据)。每辆小车在跑道上前进,当它到达跑道的终点时,会自动回到起点继续前进。在这个过程中,跑道始终是满的,小车不断地循环前进,而不需要停下来等待新的跑道空间。
举例说明
音频播放:在音频播放器中,环形缓冲区可以用来存储音频数据。播放器从缓冲区中读取数据并播放,同时音频解码器将新的音频数据写入缓冲区。当缓冲区满了之后,新的数据会覆盖最早的数据,这样可以确保音频播放的连续性和流畅性。
网络通信:在网络通信中,环形缓冲区可以用于存储接收到的数据包。当缓冲区满时,新的数据包会覆盖最早的数据包。这样可以确保网络数据的及时处理,避免因缓冲区溢出而导致的数据丢失。
通过这种环形设计,环形缓冲区在处理连续数据流时表现出色,能够有效地平衡数据的生产速度和消费速度,提高系统的整体性能。
这种设计和传统的其他类型有什么区别?
环形缓冲区(Ring Buffer)与其他传统缓冲区设计的主要区别在于其结构和数据管理方式:
环形缓冲区的特点
固定大小和循环使用:环形缓冲区具有固定的大小,当数据填满缓冲区后,新数据会覆盖最早的数据。这种设计避免了动态内存分配和释放的开销,提高了数据处理的效率。
高效的数据存取:通过使用读写指针来管理数据,环形缓冲区可以在不移动数据的情况下进行读写操作。这减少了数据复制的需要,从而提高了性能。
适用于流数据处理:环形缓冲区非常适合处理连续的数据流,如音频、视频流或网络数据包,因为它可以持续地接收和发送数据。
与传统缓冲区的比较
动态缓冲区:传统动态缓冲区通常需要根据数据量动态调整大小,这可能导致频繁的内存分配和释放操作,增加了系统的开销。而环形缓冲区由于其固定大小,避免了这种开销。
线性缓冲区:线性缓冲区在数据填满后需要进行数据的移动或复制,以便为新数据腾出空间。环形缓冲区则通过覆盖旧数据的方式,简化了数据管理。
双缓冲区(Ping-Pong Buffer):双缓冲区通过使用两个缓冲区交替进行读写操作,以减少数据丢失。虽然它可以提供较低的延迟,但在数据量较大时,可能会导致内存使用效率较低。环形缓冲区则在固定大小的内存中循环使用,更有效地利用了内存资源。
总的来说,环形缓冲区通过其独特的循环结构和高效的指针管理方式,在处理流数据和需要高效内存利用的场景中具有明显的优势。
在形象的解释一下双缓冲区的原理
双缓冲区(Double Buffer)是一种缓冲技术,主要用于解决生产者和消费者之间速度不匹配的问题,以及在图形显示中减少闪烁和撕裂现象。以下是双缓冲区的原理和形象解释:
工作原理
两个缓冲区:双缓冲区由两个缓冲区组成,通常称为缓冲区 A 和缓冲区 B。这两个缓冲区交替用于数据的生产(写入)和消费(读取)。
交替使用:在任何时候,一个缓冲区用于生产者写入数据,而另一个缓冲区用于消费者读取数据。当一个缓冲区被写满或读空后,两个缓冲区的角色会进行切换。
互斥锁:为了确保生产者和消费者不会同时访问同一个缓冲区,通常会为每个缓冲区设置一个互斥锁。生产者或消费者在操作缓冲区之前必须先获取相应的互斥锁。
形象解释
想象一下,你有两个篮子(缓冲区 A 和缓冲区 B),一个用于装苹果(生产者写入数据),另一个用于卖苹果(消费者读取数据)。开始时,你用篮子 A 装苹果,同时顾客从篮子 B 买苹果。当篮子 A 装满后,你停止装苹果,开始用篮子 B 装苹果,同时顾客开始从篮子 A 买苹果。这样,你和顾客可以同时进行操作,而不会互相干扰。
应用场景
图形显示:在图形渲染过程中,双缓冲技术可以避免图像闪烁和撕裂现象。例如,在绘制复杂的图形时,先在一个缓冲区中完成所有绘制操作,然后一次性将该缓冲区的内容复制到显示缓冲区,从而提供更流畅的动画效果。
网络通信:在网络数据传输中,双缓冲区可以用于接收和发送数据。一个缓冲区用于接收数据,另一个缓冲区用于发送数据,从而提高数据传输的效率。
通过这种设计,双缓冲区有效地解决了生产者和消费者之间的速度不匹配问题,并在图形显示中提供了更平滑的视觉效果。
7. L1cache脱靶是什么意思
L1 Cache脱靶,也称为L1 Cache未命中,是指当CPU需要访问某个数据或指令时,该数据或指令不在L1 Cache中的情况。当这种情况发生时,CPU必须从更慢的存储层级(如L2 Cache、L3 Cache或主内存)中获取所需的数据或指令,这会增加访问延迟,从而影响整体的系统性能。这种现象是缓存层次结构中常见的问题,因为L1 Cache虽然速度快,但由于容量有限,不可能缓存所有可能需要的数据和指令。
8. 飞行取值有效位
"飞行取值"(Flying Data)这个术语在计算机体系结构和数字电路设计中通常指的是在流水线处理过程中,数据从一个阶段传递到下一个阶段时,并不实际写回到寄存器或内存中,而是直接在硬件电路中传递。
"有效位"(Valid Bit)是与数据一起存储或传输的一个标志位,用于指示数据是否有效。在流水线处理中,有效位通常用于以下目的:
数据转发:在指令流水线中,如果一个指令的结果需要被后续指令使用,并且这个结果在下一个指令周期中可用,那么可以通过数据转发(Data Forwarding)技术直接将结果传递给后续指令,而不是从寄存器文件中读取。有效位在这里用来指示转发的数据是否有效。
旁路技术:在旁路(Bypassing)技术中,有效位用于指示从执行阶段直接旁路到译码阶段的数据是否有效。这允许流水线在不等待写回阶段的情况下,直接使用最新的计算结果。
寄存器重命名:在超标量处理器中,为了解决数据相关性和避免流水线停顿,通常会使用寄存器重命名技术。有效位在这里用于指示重命名寄存器中的数据是否有效。
乱序执行:在乱序执行(Out-of-Order Execution)的处理器中,有效位用于指示指令是否已经准备好执行,即所有依赖的操作数都已准备好。
在这些情况下,有效位是确保数据正确性和避免错误的关键组成部分。它帮助处理器确定何时可以安全地使用数据,以及何时需要等待数据变得可用。这种机制对于提高处理器的性能和效率至关重要。