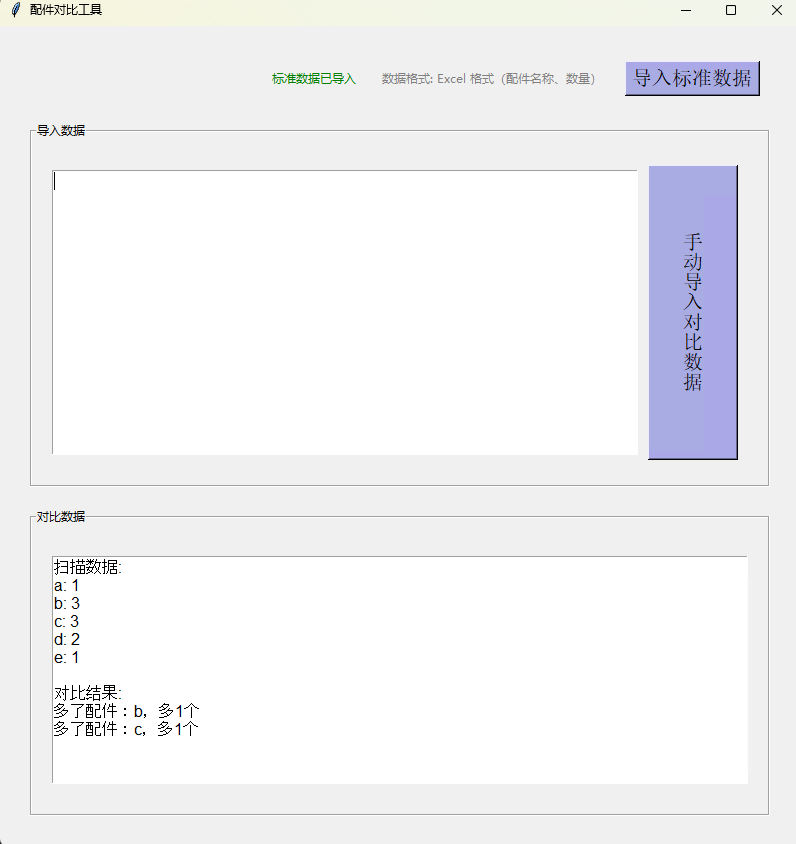
在工作中遇到一家工厂老板的需求:因为产品是有多个配件组成,在生产的时候,经常会多生产,少生产,在组装时,也会出现配件多少的问题,现就此问题设计一款程序。多出,少的,异常的,正常好,会开语音播报。现将全部代码给出以备。
import inspect import os import threading import time import tkinter as tk import uuid from collections import Counter from datetime import datetime from tkinter import filedialog, messagebox import pandas as pd import pyttsx3 from openpyxl import Workbook, load_workbook # from pyttsx3 import engine # 创建语音引擎 engine = pyttsx3.init()class DataComparatorApp:def __init__(self, root):self.root = rootself.root.title("配件对比工具")self.root.geometry("800x820")# 初始化数据self.input_data = Noneself.standard_data = Noneself.original_standard_data = Noneself.comparison_results = []self.scan_data = {} # 初始化扫描数据字典self.is_processing = False # 防止递归触发self.save_path = os.path.join(os.getcwd(), "result.xlsx") # 默认保存路径self.standard_data_written = False # 标志位,确保标准数据只写入一次self.comparison_results_written = False # 标志位,确保对比结果只写入一次# 创建界面控件 self.create_widgets()def create_widgets(self):# 主布局框架main_frame = tk.Frame(self.root)main_frame.pack(padx=20, pady=20, expand=True, fill="both")# 导入标准数据按钮放到最上方import_standard_frame = tk.Frame(main_frame)import_standard_frame.pack(padx=10, pady=10, fill="x")self.import_standard_button = tk.Button(import_standard_frame, text="导入标准数据", command=self.import_standard_data, bg="#AAA8E6", fg="black", font=15) # 淡蓝色按钮# 字体设置成幼圆self.import_standard_button.config(font=("幼圆", 15))self.import_standard_button.pack(side=tk.RIGHT, padx=10, pady=5) # 修改为使用 pack 和 side=tk.RIGHTself.data_format_label = tk.Label(import_standard_frame, text="数据格式: Excel 格式(配件名称、数量)", fg="grey")self.data_format_label.pack(side=tk.RIGHT, padx=10, pady=5) # 修改为使用 pack 和 side=tk.RIGHT# 新增标准数据导入状态提示标签self.standard_data_status_label = tk.Label(import_standard_frame, text="没有导入标准数据", fg="red")self.standard_data_status_label.pack(side=tk.RIGHT, padx=10, pady=5)# 导入数据区域import_frame = tk.LabelFrame(main_frame, text="导入数据", padx=20, pady=20)import_frame.pack(padx=10, pady=10, fill="x")# 调整手动导入数据按钮的高度和宽度self.import_input_button = tk.Button(import_frame, text="手\n动\n导\n入\n对\n比\n数\n据", command=self.import_input_data, bg="#AAA8E6", fg="black", height=14, width=8) # 修改高度和宽度self.import_input_button.config(font=("幼圆", 15))self.import_input_button.pack(side=tk.RIGHT, padx=10, pady=5) # 修改为使用 pack 和 side=tk.RIGHT# 调整扫描数据展示框的大小,铺满整个区域,并确保能够输入self.scan_data_display = tk.Text(import_frame, width=80, height=10, relief="sunken", wrap=tk.WORD, font=("Arial", 12)) # 修改宽度和高度,并设置字体大小self.scan_data_display.pack(pady=10, fill="both", expand=True)self.scan_data_display.focus() # 使扫描框获取焦点,以便扫描时能够输入# 监听文本框的变化,自动添加逗号和换行符self.scan_data_display.bind("<KeyRelease>", self.detect_singsong) # 监听输入框变化# 对比数据区域:增加高度compare_frame = tk.LabelFrame(main_frame, text="对比数据", padx=20, pady=20)compare_frame.pack(padx=10, pady=10, fill="x")# 使用文本框显示对比进度self.compare_progress_text = tk.Text(compare_frame, height=20, width=100, state=tk.DISABLED, font=("Arial", 12)) # 增大高度,并设置字体大小self.compare_progress_text.pack(pady=10, fill="both", expand=True)# 操作区域action_frame = tk.Frame(main_frame)action_frame.pack(padx=10, pady=10, fill="x")self.save_button = tk.Button(action_frame, text="保存对比结果", height=20, width=100, command=self.save_comparison_results, bg="#ADD8E6", fg="black")self.save_button.pack(side=tk.RIGHT, padx=10)# 新增的保存状态标签self.save_status_label = tk.Label(action_frame, text="", fg="red") # 显示文件保存状态self.save_status_label.pack(side=tk.RIGHT, padx=10)def detect_singsong(self, event=None):"""检测是否输入了 SINGSONG 并触发对比"""if self.is_processing:return# 获取扫描框的内容,并去掉前后空格scan_data = self.scan_data_display.get("1.0", tk.END).strip().lower()# 去掉所有空格scan_data = scan_data.replace(" ", "") # 去掉所有空格# 如果扫描到"SINGSONG",进行对比if "singsong" in scan_data:self.is_processing = Truetry:self.process_scan_data(scan_data) # 处理扫描数据并触发对比finally:self.is_processing = False # 确保 is_processing 被重置def process_scan_data(self, scan_data):"""处理扫描数据并与标准数据对比"""# 处理扫描数据,移除空格后每个配件加上逗号items = scan_data.split(",")items = [item.strip().replace(" ", "") for item in items if item.strip()] # 去除多余的空格# 排除掉"SINGSONG"items = [item for item in items if item.lower() != "singsong"]# 统计每个配件的数量scan_dict = dict(Counter(items))self.scan_data = scan_dictprint(f"处理后的扫描数据:{self.scan_data}") # 打印扫描处理后的数据self.compare_data() # 进行对比def import_input_data(self):"""导入输入源数据"""file_path = filedialog.askopenfilename(filetypes=[("Excel Files", "*.xlsx"), ("CSV Files", "*.csv")])if file_path:try:if file_path.endswith('.csv'):self.input_data = pd.read_csv(file_path, encoding='utf-8')else:self.input_data = pd.read_excel(file_path)# 更新已导入产品信息product_count = len(self.input_data)self.imported_label.config(text=f"已导入 {product_count} 个产品")messagebox.showinfo("提示", f"输入源数据导入成功!共 {product_count} 个产品")self.check_buttons()except Exception as e:messagebox.showerror("错误", f"导入输入源数据失败:{e}")def import_standard_data(self):"""导入标准数据"""file_path = filedialog.askopenfilename(filetypes=[("Excel Files", "*.xlsx")]) # 只支持Excel文件if file_path:try:# 使用pandas读取Excel文件df = pd.read_excel(file_path)# 检查列名是否存在if 'PIEZA' not in df.columns or 'CANTIDAD' not in df.columns:messagebox.showerror("错误", "Excel 文件中缺少 'PIEZA' 或 'CANTIDAD' 列")return# 处理 A 列和 C 列,创建标准数据字典self.standard_data = dict(zip(df['PIEZA'].str.lower(), df['CANTIDAD'])) # 只读取A、C列进行对比self.original_standard_data = df # 保存原始数据,以便在保存时使用print(f"标准数据:{self.standard_data}") # 打印标准数据 messagebox.showinfo("提示", "标准数据导入成功!")self.check_buttons()self.save_standard_data() # 在导入标准数据后,保存标准数据# 更新标准数据导入状态提示标签self.standard_data_status_label.config(text="标准数据已导入", fg="green")except Exception as e:messagebox.showerror("错误", f"导入标准数据失败:{e}")# 更新标准数据导入状态提示标签self.standard_data_status_label.config(text="没有导入标准数据", fg="red")else:# 更新标准数据导入状态提示标签self.standard_data_status_label.config(text="没有导入标准数据", fg="red")def check_buttons(self):"""检查按钮状态"""if self.input_data is not None and self.standard_data is not None:self.save_button.config(state=tk.NORMAL)# def compare_data(self):# """进行数据对比"""# self.compare_progress_text.config(state=tk.NORMAL)# self.compare_progress_text.delete(1.0, tk.END) # 清空对比结果# # comparison_results = []# total_parts = len(self.scan_data)# processed_parts = 0# # # 遍历扫描数据与标准数据对比# for part, quantity in self.scan_data.items():# standard_quantity = self.standard_data.get(part.lower(), 0)# # if standard_quantity == 0:# comparison_results.append(f"未在标准数据中找到配件:{part}")# elif quantity > standard_quantity:# comparison_results.append(f"多了配件:{part},多{quantity - standard_quantity}个")# elif quantity < standard_quantity:# comparison_results.append(f"少了配件:{part},少{standard_quantity - quantity}个")# else:# comparison_results.append(f"配件完整:{part}")# # # 更新进度# processed_parts += 1# progress = int((processed_parts / total_parts) * 100)# self.compare_progress_text.insert(tk.END, f"正在处理:{part} - {progress}% 完成\n")# self.compare_progress_text.yview(tk.END)# # # 对比标准数据中缺少的配件# for part, standard_quantity in self.standard_data.items():# if part not in self.scan_data:# comparison_results.append(f"缺少配件:{part},标准数量为 {standard_quantity}个")# # self.comparison_results = comparison_results# self.display_results()# self.voice_result()# # # 保存对比结果# if not self.comparison_results_written:# self.save_comparison_results() # 只有在第一次保存对比结果时调用# self.comparison_results_written = True# # # 清空扫描数据,准备下一轮输入# self.scan_data_display.delete(1.0, tk.END) # 清空文本框# self.scan_data = {}# self.is_processing = False # 允许再次处理def compare_data(self):"""进行数据对比"""self.compare_progress_text.config(state=tk.NORMAL)self.compare_progress_text.delete(1.0, tk.END) # 清空对比结果 comparison_results = []total_parts = len(self.scan_data)processed_parts = 0# 重置标志位,确保每次对比结果都被保存self.comparison_results_written = False# 遍历扫描数据与标准数据对比for part, quantity in self.scan_data.items():standard_quantity = self.standard_data.get(part.lower(), 0)if standard_quantity == 0:comparison_results.append(f"异常配件:{part}")elif quantity > standard_quantity:comparison_results.append(f"多了配件:{part},多{quantity - standard_quantity}个")elif quantity < standard_quantity:comparison_results.append(f"少了配件:{part},少{standard_quantity - quantity}个")# 更新进度processed_parts += 1progress = int((processed_parts / total_parts) * 100)self.compare_progress_text.insert(tk.END, f"正在处理:{part} - {progress}% 完成\n")self.compare_progress_text.yview(tk.END)# 对比标准数据中缺少的配件for part, standard_quantity in self.standard_data.items():if part not in self.scan_data:comparison_results.append(f"缺少配件:{part},标准数量为 {standard_quantity}个")# 检查是否所有配件都完全匹配if not comparison_results:comparison_results.append("全部配件完整")self.comparison_results = comparison_resultsself.display_results()# 修改语音播报逻辑 self.voice_result()# 保存对比结果if not self.comparison_results_written:self.save_comparison_results() # 只有在第一次保存对比结果时调用self.comparison_results_written = True# 写入分隔线self.compare_progress_text.insert(tk.END, "\n" * 20)# 清空扫描数据,准备下一轮输入self.scan_data_display.delete(1.0, tk.END) # 清空文本框self.scan_data = {}self.is_processing = False # 允许再次处理def display_results(self):"""显示对比结果"""scan_data_text = "\n".join([f"{key}: {value}" for key, value in self.scan_data.items()])self.compare_progress_text.config(state=tk.NORMAL)self.compare_progress_text.delete(1.0, tk.END)self.compare_progress_text.insert(tk.END, f"扫描数据:\n{scan_data_text}\n\n对比结果:\n")result_text = "\n".join(self.comparison_results)self.compare_progress_text.insert(tk.END, result_text + '\n')self.compare_progress_text.config(state=tk.DISABLED)def _voice_result(self):"""语音播报对比结果"""if self.comparison_results:def speak():try:# 直接运行语音播报,而不停止任何当前的语音for result in self.comparison_results:engine.say(result)engine.runAndWait() # 确保在语音播报完后再继续执行time.sleep(1)self.scan_data_display.delete(1.0, tk.END) # 扫描框清空except Exception as e:print(f"语音播报出错:{e}")thread = threading.Thread(target=speak)thread.start()def voice_result(self):"""语音播报对比结果"""if self.comparison_results:engine.stop() # 停止之前的语音播报for result in self.comparison_results:engine.say(result)engine.runAndWait() # 确保在语音播报完后再继续执行# 停留1秒后清空输入框time.sleep(1)self.scan_data_display.delete(1.0, tk.END)def save_standard_data(self):"""保存标准数据"""if self.standard_data_written:return # 如果已经保存过标准数据,则直接返回,不再保存# 获取MAC地址mac_address = ':'.join(['{:02x}'.format((uuid.getnode() >> elements) & 0xff) for elements in range(0, 2 * 6, 2)])# 获取当前时间timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")# 获取标准数据的完整内容standard_data_content = self.original_standard_data# 如果文件路径不存在,创建文件夹file_dir = os.path.dirname(self.save_path)if not os.path.exists(file_dir):os.makedirs(file_dir)try:# 检查文件是否存在if os.path.exists(self.save_path):workbook = load_workbook(self.save_path)else:workbook = Workbook()# 删除其他sheet,只保留对比数据和标准数据sheets_to_delete = [sheet for sheet in workbook.sheetnames if sheet not in ["对比数据", "标准数据"]]for sheet in sheets_to_delete:del workbook[sheet]# 处理“对比数据” sheetif "对比数据" not in workbook.sheetnames:sheet = workbook.create_sheet("对比数据", 0) # 将其放在第一个位置sheet.append(["配件", "数量", "类型"]) # 写入列名# 写入扫描数据和对比结果for part, quantity in self.scan_data.items():sheet.append([part, quantity, "扫描数据"])for result in self.comparison_results:sheet.append([result, "", "对比结果"])# 处理“标准数据” sheetif "标准数据" not in workbook.sheetnames:sheet = workbook.create_sheet("标准数据")# 写入原始数据的表头 sheet.append(standard_data_content.columns.tolist())# 写入原始数据for index, row in standard_data_content.iterrows():sheet.append(row.tolist())# 追加 MAC地址、时间、文件路径last_row = sheet.max_row + 1sheet.cell(row=last_row, column=1, value="MAC地址")sheet.cell(row=last_row, column=2, value=mac_address)sheet.cell(row=last_row + 1, column=1, value="时间")sheet.cell(row=last_row + 1, column=2, value=timestamp)sheet.cell(row=last_row + 2, column=1, value="文件路径")sheet.cell(row=last_row + 2, column=2, value=self.save_path)workbook.save(self.save_path)self.standard_data_written = Trueexcept Exception as e:messagebox.showerror("错误", f"保存标准数据失败:{e}")def save_comparison_results(self):"""保存对比结果"""# 如果文件路径不存在,创建文件夹file_dir = os.path.dirname(self.save_path)if not os.path.exists(file_dir):os.makedirs(file_dir)try:# 检查文件是否存在if os.path.exists(self.save_path):workbook = load_workbook(self.save_path)else:workbook = Workbook()# 删除其他sheet,只保留对比数据和标准数据sheets_to_delete = [sheet for sheet in workbook.sheetnames if sheet not in ["对比数据", "标准数据"]]for sheet in sheets_to_delete:del workbook[sheet]# 处理“对比数据” sheetif "对比数据" not in workbook.sheetnames:sheet = workbook.create_sheet("对比数据", 0) # 将其放在第一个位置sheet.append(["配件", "数量", "类型"]) # 写入列名else:sheet = workbook["对比数据"]# 如果有结果,插入分隔符行if sheet.max_row > 1: # 确保已经写入过内容sheet.append(["*************", "*************", "*************"]) # 添加分隔符行# 写入扫描数据和对比结果for part, quantity in self.scan_data.items():sheet.append([part, quantity, "扫描数据"])for result in self.comparison_results:sheet.append([result, "", "对比结果"])workbook.save(self.save_path)# 更新界面显示文件已保存self.save_status_label.config(text="文件已保存", fg="green")except Exception as e:messagebox.showerror("错误", f"保存对比结果失败:{e}")def _save_comparison_results(self):"""保存对比结果"""# 如果文件路径不存在,创建文件夹file_dir = os.path.dirname(self.save_path)if not os.path.exists(file_dir):os.makedirs(file_dir)try:# 检查文件是否存在if os.path.exists(self.save_path):workbook = load_workbook(self.save_path)else:workbook = Workbook()# 删除其他sheet,只保留对比数据和标准数据sheets_to_delete = [sheet for sheet in workbook.sheetnames if sheet not in ["对比数据", "标准数据"]]for sheet in sheets_to_delete:del workbook[sheet]# 处理“对比数据” sheetif "对比数据" not in workbook.sheetnames:sheet = workbook.create_sheet("对比数据", 0) # 将其放在第一个位置sheet.append(["配件", "数量", "类型"]) # 写入列名else:sheet = workbook["对比数据"]# 如果有结果,插入分隔符行if sheet.max_row > 1: # 确保已经写入过内容sheet.append(["*************", "*************", "*************"]) # 添加分隔符行# 写入扫描数据和对比结果for part, quantity in self.scan_data.items():sheet.append([part, quantity, "扫描数据"])for result in self.comparison_results:sheet.append([result, "", "对比结果"])# 保存工作簿 workbook.save(self.save_path)# 更新界面显示文件已保存self.save_status_label.config(text="文件已保存", fg="green")except Exception as e:messagebox.showerror("错误", f"保存对比结果失败:{e}")# 创建主窗口 root = tk.Tk()# 创建应用 app = DataComparatorApp(root)# 运行主事件循环 root.mainloop()