思路
本题要求对字符串进行操作。将字符串中所有指定的字母全部替换为另一个字母
传统方法是依次遍历这个字符串,当遇到需要被替换的字母c就将其更改为d
这种方法的时间复杂度是O(N*Q)
为了能更高效的更改,我想到的是能够尽快的将所有位置的信息一步更新,而不是遍历这个字符串来更新。如果能将同一字母的不同位置同时修改为指定的字母就可以大大提高更改的效率
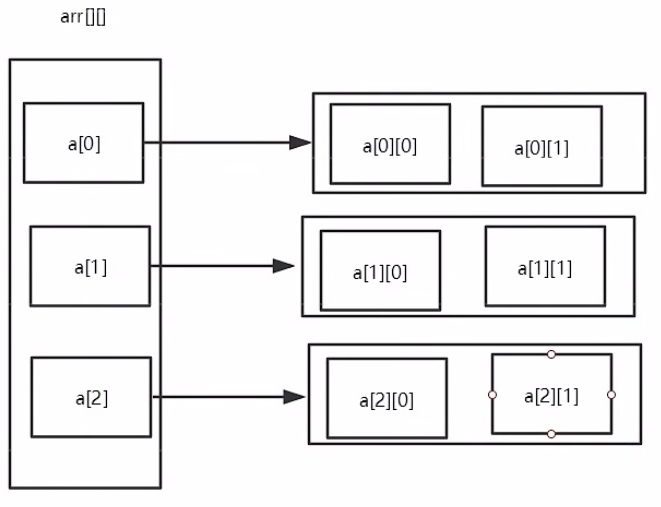
因此我通过并查集,将同一字母不同位置分布视为等效类,并且通过两个一维数组分别记录字母d对应等效类,和某一个等效类对应哪一个字母。
代码
#include<iostream>
using namespace std;
class uset{public:uset(int size):max_size(size+1){root=new int[max_size];parent=new int[max_size];for(int i=0;i<=size;++i) root[i]=parent[i]=1;}int uhead(int e){//找到祖宗是哪一个if(1==root[e]) return e;parent[e]=uhead(parent[e]);return parent[e];}int umerge(int i,int j){i=uhead(i),j=uhead(j);if(i==j) return i;root[i]=0;parent[j]+=parent[i];parent[i]=j;return j;}public:int*root,*parent;int max_size;
};
const int MAX=200001;
int ci_map[26];//下标代表字母,内容代表这个字母对应的等效类的uhead值
char ic_map[MAX];//某个数字对应的字母是哪个,如果数值范围会很大就会用map
int main(){int N,Q;char ch;char c,d;string s;cin>>N>>s>>Q;uset us(N);for(int i=1;i<=N;++i){if(ci_map[s[i-1]-'a']){us.umerge(i,ci_map[s[i-1]-'a']);}else{ic_map[i]=s[i-1];ci_map[s[i-1]-'a']=i;}}for(int i=1;i<=Q;++i){cin>>c>>d;if(c==d||0==ci_map[c-'a']) continue;if(ci_map[d-'a']){us.umerge(ci_map[c-'a'],ci_map[d-'a']);//将下标类合并为一个等效类//关于类“c"的数据都擦除ic_map[ci_map[c-'a']]=0;ci_map[c-'a']=0;}else{//没有类d就将类c改名为类dint x=ci_map[c-'a'];ci_map[c-'a']=0;ic_map[x]=d;ci_map[d-'a']=x;}}for(int i=1;i<=N;++i){cout<<ic_map[us.uhead(i)];}return 0;
}
学习总结
完成代码对我来说具有挑战的就是能够更新等效类对应字母,和字母对应等效类的状态更新的过程。我起初尝试拓展并查集的功能,在并查集的合并操作中同时更新ci_map和ic_map,但是实在太过凌乱,反倒是并查集的合并功能搞得漏洞百出。
于是想到合并一个等效类和更新这个等效类对应的字母两者之间并没有必然的联系,我完全可以不扩展并查集的合并操作,而是单独将更新状态拿出来写。最终这样,才将ci_map和ic_map的状态更新写清楚。
本题的另一种思路是只需要考虑每个字母最终被替换为了哪个字母即可,并不需要搞清楚字符串中间究竟变成了什么。也就是设置一个长度为26的一维数组用来表示26个小写字母,中间的replacement操作来更改对应位置的字母的值,这样就可以最快的更新得到最终字母c被替换成了哪一个字母d