多智能体微调是一种实现自我提升的补充方法,它将微调应用于语言模型的多智能体群体。一组均基于相同基础模型的语言模型,通过模型间的多智能体交互生成的数据,分别对各个模型进行更新,实现独立的专业化。通过在不同的数据集上训练每个模型,这种方法能够让各个模型实现专业化,并使整个模型集合更加多样化。
方法
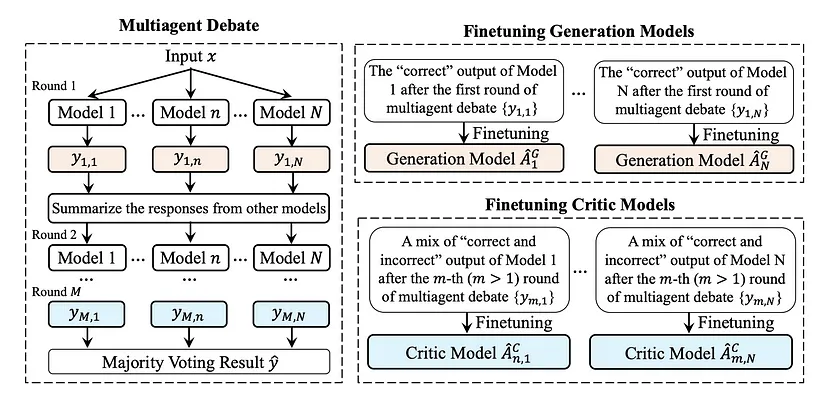
多智能体微调概述
该方法包含两个部分:
- 使用多智能体辩论方法构建用于训练模型的微调数据集。
- 引入多智能体微调,即通过在各自生成的数据上对每个大语言模型(LLM)进行微调,使其实现专业化。
多智能体辩论
多智能体辩论涉及一系列由N个语言模型智能体参与的过程,这些智能体可以是同一模型的特定副本或微调版本,每个智能体的任务都是针对给定问题生成一个回答。在生成初始回答后,智能体之间会展开一轮辩论。每个智能体需要根据自己之前的回答以及其他智能体的总结回答构建一个新的回答。最终结果由最后一轮辩论的输出进行多数投票决定 。
在生成数据上微调模型

给定一组自然语言输入$D_{task} = {x_i}$,使用具有N个智能体和M轮辩论的多智能体辩论方法,为$D_{task}$中的每个输入生成回答。对于每个$x_i$,最终预测输出$\hat{y}_i$通过最后一轮辩论的多数投票获得。这用于构建一个“ground truth”数据集${(x_i, \hat{y}_i)}$ 。在单个LLM模型设置中,然后在与给定输入$x_i$匹配$\hat{y}_i$的生成回答$y_i$集合上对模型进行微调。
虽然最终辩论结果$\hat{y}_i$是准确的,但它们在风格和方法上往往相似。因此,多次捕获${(x_i, \hat{y}_i)}$对的数据集用于多轮微调,通常会导致自我提升性能达到瓶颈。
有人提出创建不同的数据集来微调不同的模型。一组模型被训练为生成智能体,另一组被训练为评判智能体。生成模型对输入问题生成初始回答,而评判模型评估所有生成智能体的输出,然后选择或生成最有效的回答。
生成智能体$AG_n$由N个生成模型构建而成,这些模型会对给定输入$x$生成一个回答。对于每个智能体,选择其与最终辩论结果$\hat{y}$匹配的输出$y_n$,并构建输入 - 输出对$(x, y_n)$ 。为智能体$AG_n$生成的结果数据集是$D_n^G = {(x, y_n)}$。这种方法为所有N个智能体生成了一组微调数据集${D_1^G, · · ·, D_NG}$。每个数据集包含不同的输出,使得回答能够实现专业化和多样化。每个生成模型使用相应的数据集进行微调,以获得N个相应的微调智能体${\hat{A}_G1,···,\hat{A}_G^N}$ 。
评判智能体$AC_n$由评判模型构建而成,它们评估所有生成智能体的输出,然后选择或合成最佳回答。在多智能体辩论设置中,每个智能体在最后一轮辩论中的输出表示为$y_{M,n}$,其中M表示辩论轮数。识别出与最终辩论结果$\hat{y}$一致的输出$y_{M,n}$。这些一致的输出,连同之前的回答,然后用于构建输入 - 输出对$(x, (y_{1,n},..., y_{M,n}))$,以微调评判模型。
为了增强模型纠正辩论早期生成的错误答案的能力,对$y_{1,n}$与$\hat{y}$不同但$y_{M,n}$与$\hat{y}$匹配的对的子集进行采样,并构建一个数据集$D_C^- = {(x,(y_{1,n},…,y_{M,n}))|y_{1,n} \neq \hat{y},y_{M,n} = \hat{y}}$ 。这表明答案在辩论结束时被成功纠正。另一个数据集$D_C^+ = {(x,(y_{1,n},…,y_{M,n}))|y_{1,n} = \hat{y},y_{M,n} = \hat{y}}$,其中$y_{1,n}$和$y_{M,n}$都与$\hat{y}$匹配,展示了智能体在整个辩论过程中保持正确答案的能力。将这两个数据集组合起来,为每个评判模型创建一个全面的微调数据集,以构建更新后的评判智能体$AC_n$ 。
微调后的生成智能体${\hat{A}_G^1, · · ·, \hat{A}_GN}$和评判智能体${\hat{A}_C1, · · ·, \hat{A}_C^N}$用于通过多智能体辩论为下一次迭代收集数据集。
推理

在推理时,在微调后的智能体之间进行多智能体辩论。每个单独的生成智能体参与辩论的第一轮,随后每个单独的评判智能体参与后续轮次。每个智能体在每轮辩论中都会参考所有其他智能体的回答并生成一个新的回答。总结其他智能体的回答有助于消除冗余信息,同时保留最重要的细节,从而进一步提高性能。最终结果由最后一轮辩论的回答进行多数投票决定。
实验
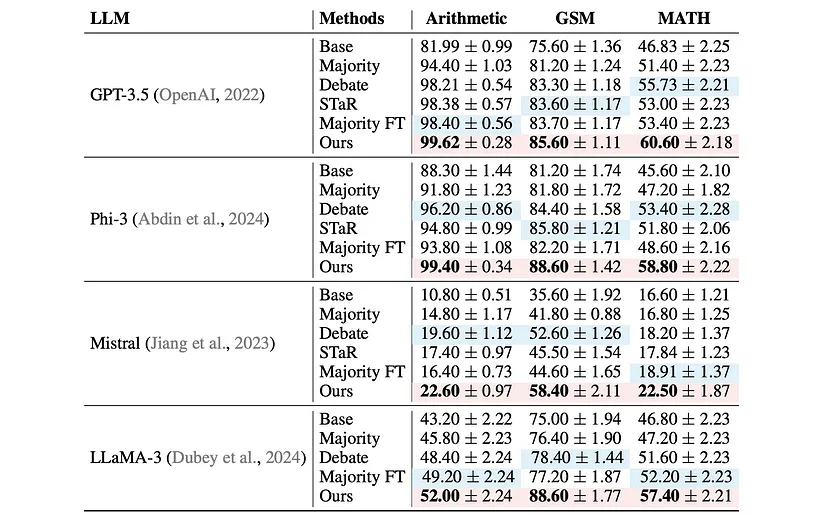
所提方法与基线方法的定量结果
所提出的多智能体微调方法在所有测试的数据集和语言模型上均优于所有基线方法。
该方法比迭代自训练基线(STaR)表现更好,尽管STaR使用了真实标签和多次微调迭代,而所提方法在初始比较中仅使用了单次微调迭代。
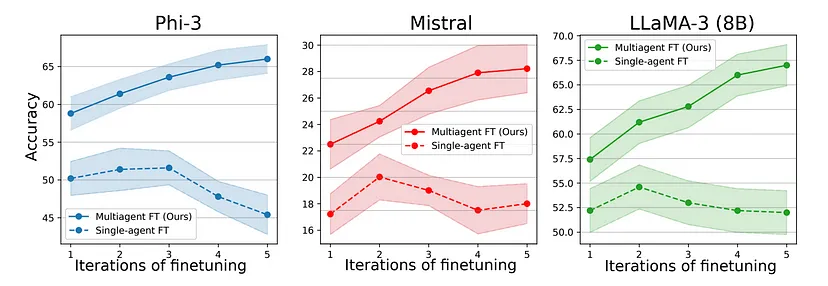
与单智能体基线相比,多数投票、多智能体辩论和微调都有助于提高性能。
多智能体微调在多轮微调中提高了推理性能。
所提多智能体微调方法的多次迭代进一步提高了性能,而单智能体微调性能在达到饱和后会下降,这表明出现了过拟合。
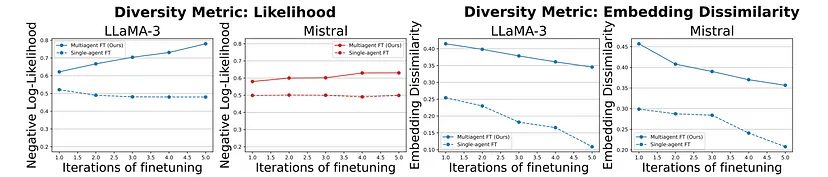
多样性
多样性得以保留,并且可以在微调迭代过程中得到改善。
多智能体微调方法在迭代过程中保持或提高了回答的多样性,而单智能体微调则降低了多样性。
论文
https://arxiv.org/abs/2501.05707
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains 2501.05707
LLM架构专栏文章
1. LLM大模型架构专栏|| 从NLP基础谈起
2.LLM大模型架构专栏|| 自然语言处理(NLP)之建模
3. LLM大模型架构之词嵌入(Part1)
4. LLM大模型架构之词嵌入(Part2)
5. LLM大模型架构之词嵌入(Part3)
6. LLM架构从基础到精通之循环神经网络(RNN)
7. LLM架构从基础到精通之LSTM
8. LLM架构从基础到精通之门控循环单元(GRUs)
9. 20000字的注意力机制讲解,全网最全
10. 深入探究编码器 - 解码器架构:从RNN到Transformer的自然语言处理模型
11. 2w8000字深度解析从RNN到Transformer:构建NLP应用的架构演进之路
欢迎关注公众号 柏企科技圈 与柏企阅文 如果您有任何问题或建议,欢迎在评论区留言交流!
本文由mdnice多平台发布





![折腾笔记[11]-使用rust进行直接法视觉里程计估计](https://img2024.cnblogs.com/blog/1048201/202501/1048201-20250123123551774-423709835.png)