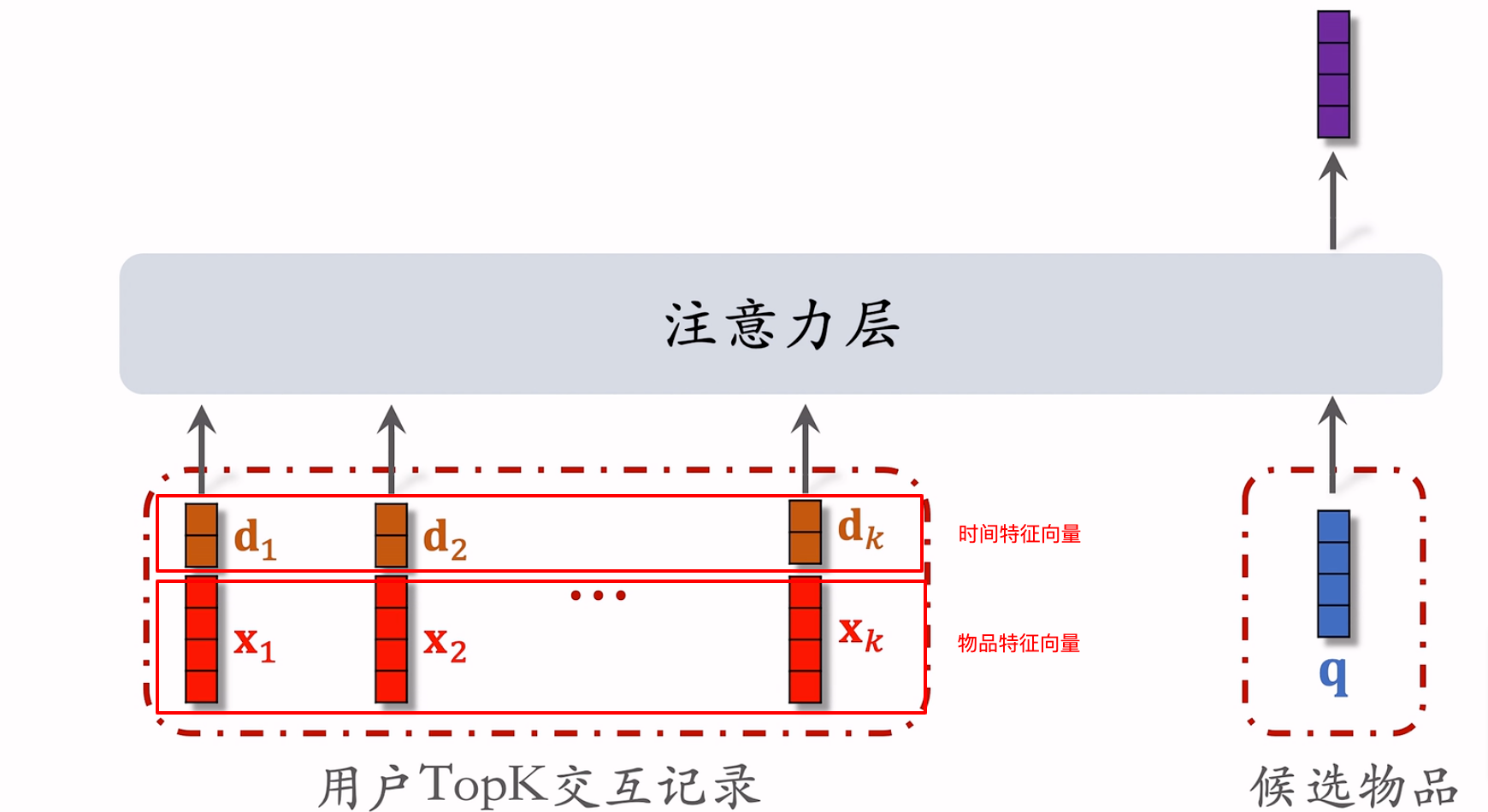
点击率预测模型
点击率:把点击事件h看成一个二元取值的随机变量,取值为真(h=1)的概率就是点击率
点击事件分布:表示成以点击率μ为参数的二项分布
点击率基础模型:逻辑回归(LR),在(a,u,c)组合与点击率μ之间建立函数关系,表示成对μ(a,u,c)=p(h=1|a,u,c)的概率建模问题
- LR正是当目标值的分布服从伯努利分布时广义线性模型的特例,映射函数是logit(t)=log
- L2-norm避免过拟合
LR模型优化
- 梯度下降法
- L-BFGS
- 置信域法
工业界常用模型训练思路
- 1.降低模型训练次数,通过特征侧的方法捕捉信号的快速变化
- 2.增量求解,降低模型收敛所需的迭代次数
- 3.精心设计最优化算法如ADMM,降低模型收敛所需的迭代次数
点击率模型的矫正:正负样本不平衡可能带来预估模型的偏差,原因如下:
- 高斯分布方差的最大似然估计是有偏的(为了得到方差的无偏估计,需要将样本数目-1来计算方差)
- 偏差的方向是对方差有所低估,且样本数目越少,低估越严重。
- 由于正样本(h=1)远远小于负样本(h=0)的数据量,对前者的低估更严重。
其他点击率预估模型
- 因子分解机FM
- GBDT
- 深度学习点击率预估模型
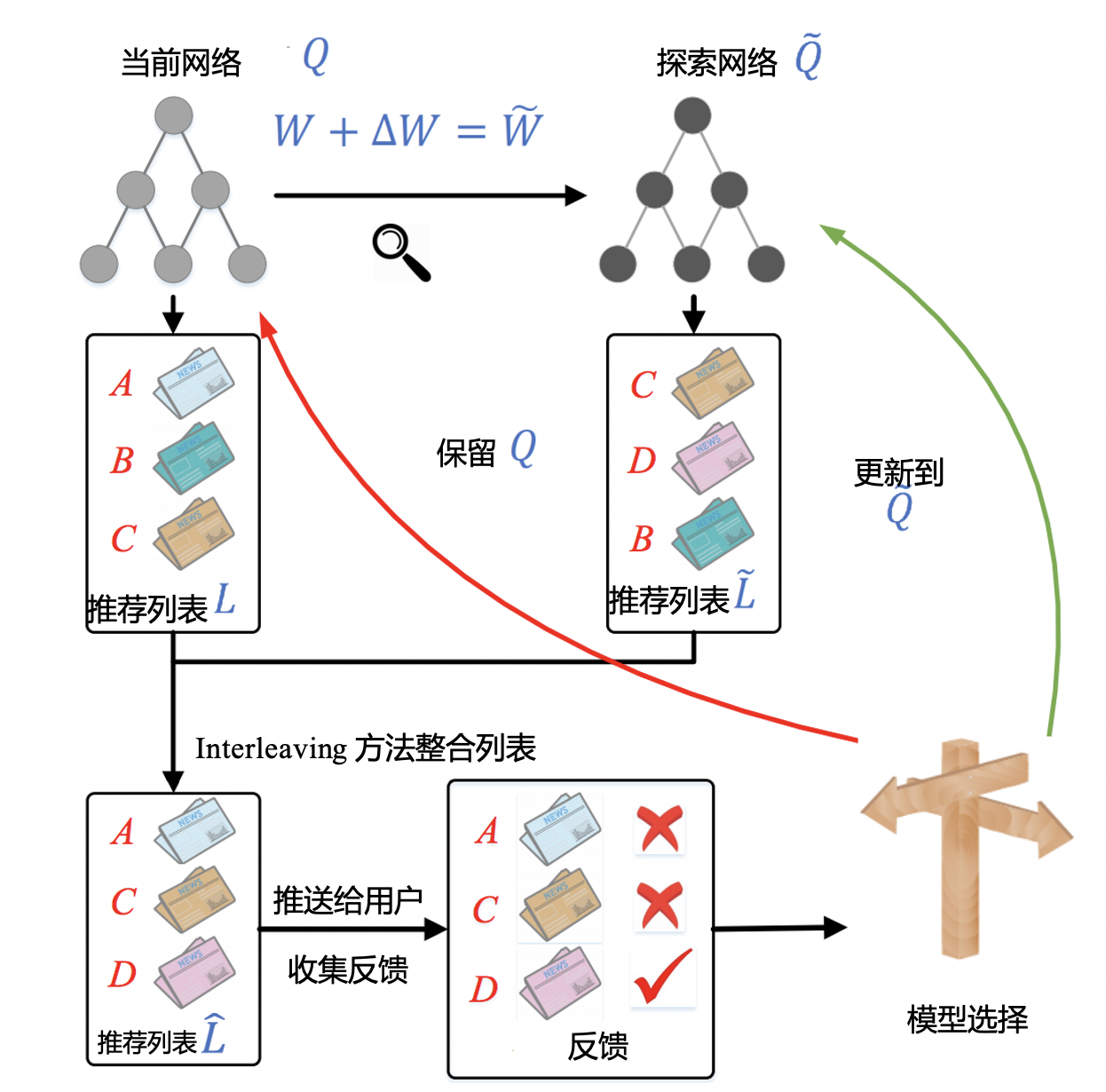
探索与利用
-
α贪婪法
-
决策过程
- 总是用比例为α的小部分流量做探索,在探索流量上随机选择A个广告中的1个;
- 在剩余1-α比例的流量上,总是选择经验收益最高的那个。
-
-
置信上界(UCB)方法
-
概念:每次投放时,不但简单的选择经验最优广告,而且考虑到经验估计的不确定性,进而选择估计值有可能达到的上界最大的那个广告
-
UCB决策过程
- 1.根据过去的观测值,利用某概率模型计算出每个a的期望回报的UCB
- 2.选择UCB最大的a
-
UCB计算方法
-
-
考虑上下文的bandit
- LinUCB方法
点击率模型特征
基本特征:广告侧特征、用户侧特征、上下文特征
特征的非线性化
- 特征离散化:将连续特征切成一组分区,当特征值落在某个区间时,对应区间离散特征值标1,否则标0
- 引入特征的非线性变化,如平方、平方根、log等
特征组合
- 静态特征组合:用户侧、广告侧、上下文侧的标签组合,如性别和地点、广告主题和性别等
- 动态特征组合:如用户对某个广告的历史点击率,即当某个组合特征被触发时,不再标为1,而是使用历史点击率作为特征值
偏差特征
-
常见的偏差特征包括广告位位置、广告位尺寸、广告投放延迟、日期和时间、浏览器
-
如何消除?CoEC
-
期望点击
- 概念:将某广告位相当长一段时间内的平均点击数作为其关注程度的近似估计
- 评估对象:在广告质量完全随机的情况下,广告位或其他属性对应的平均点击率
-
偏差模型:从数据中近似学习除期望点击的方法是只用那些偏差因素作为特征,训练一个点击率模型,称为偏差模型
-
CoEC:归一化点击率指标,即点击与期望点击的比值
-
点击反馈的平滑
- 当使用点击率或CoEC特征时,若展示数较小,可在分子和分母上各加上一个常数进行平滑