1. 引言
无论是哪个平台哪种编程语言,字符串乱码真是一个让人无语的问题:你说这个问题比较小吧,但是关键时刻来一下真是受不了。解决方式也有很多种,但是与其将编码转换来转换去,不如统一使用同一种编码方式,比如国际通用的UTF-8编码。因此,新的程序代码最好都统一使用UTF-8编码的方式。但是C++作为一种历史悠久的编程语言,肯定存在很多存量代码,如何将其改造成UTF-8编码也是一个问题,笔者在这里总结一二,可能不是很全,如果有遗漏就再开一篇补充。
2. 详述
2.1 操作系统
统一使用统一使用UTF-8编码还有个好处是跨平台。但是操作系统本身也是有字符编码的,这会影响到与操作系统相关的应用,比如说终端。Linux系统一般不用担心,目前一般都默认使用UTF-8编码。Windows系统则有点麻烦,一般使用ANSI码(本地码)。本地码的意思就是基于当前系统区域设置的字符编码,以国内大陆的来说就是国标码:GB2312/GBK/GB18030。这就是为什么Windows的终端总是出现乱码的原因,因为编码不一致:GBK编码的终端遇到UTF-8编码字符串当然不会正确展示了。
当然现在Windows系统也能设置成UTF-8编码了,如下图1所示。但是还是建议不要轻易这么设置,Windows系统没有将UTF-8编码设置系统的默认编码主要也是为了保证兼容性,在Unicode编码大规模使用之前本地码还是使用了相当长的时间的,有相当数据量的遗留程序都是使用的本地码。为了避免大规模应用程序乱码问题的出现,不能要求每个用户都这么设置。
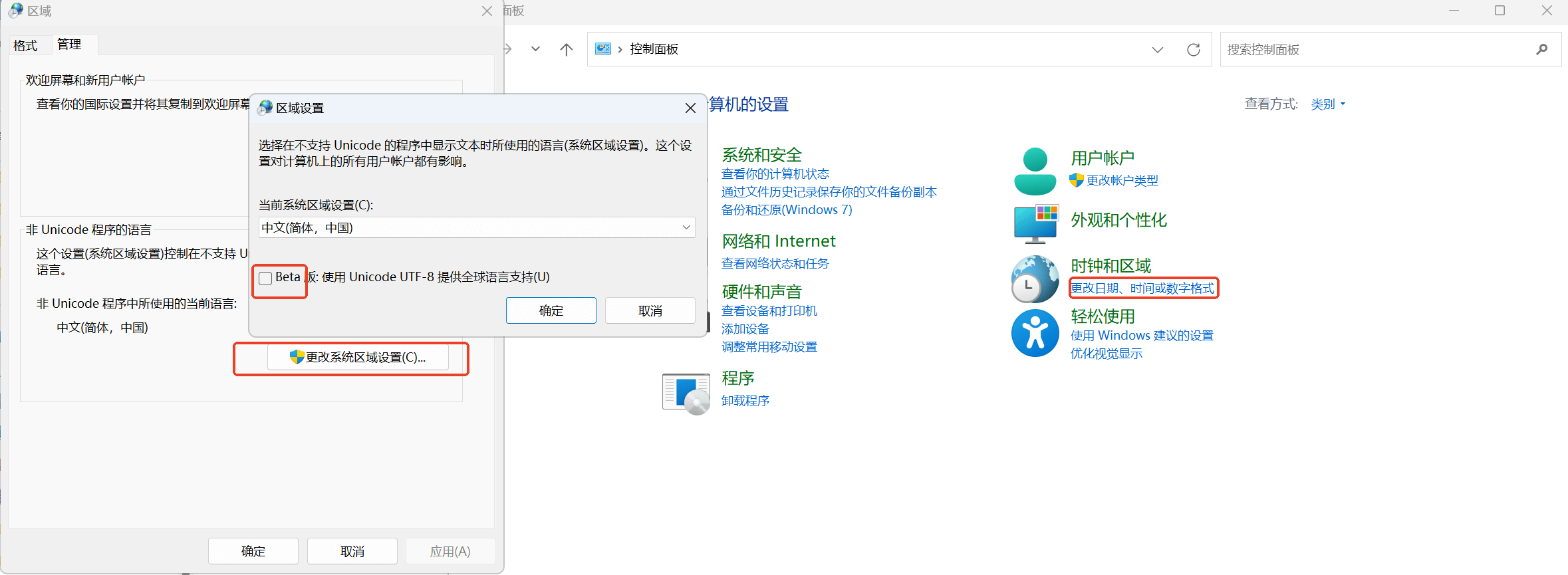
2.2 编译器
虽然最好不要在操作系统层面设置成UTF-8编码,但是还是可以编写基于UTF-8编码的程序的。将代码文件修改成UTF-8编码是一方面,另外一方面是编译器要将代码文件按照UTF-8编码进行编译。因为无论是ASCII、GB18030还是UTF-8编码的文本文件,其实都是没有具体的标识符的,编译器需要知道以哪种字符编码来编译代码文件中的字符。
Linux系统还是不用担心,默认情况下文本文件通常使用UTF-8编码,GCC编译器也会默认使用系统的默认字符编码也就是UTF-8编码来进行编译。麻烦的还是Windows系统,暂时不讨论各种复杂的情况,笔者以Visual Studio的MSVC编译器为例,介绍一下自己的做法。
首先还是要将代码文件修改成UTF-8编码,这里推荐使用Visual Studio的一个扩展:FileEncoding,它可以很方便的在代码页面的右下角修改代码文件编码,如下图2所示。不过有一点要注意,选择使用UTF-8编码而不是UTF-8(BOM)编码。
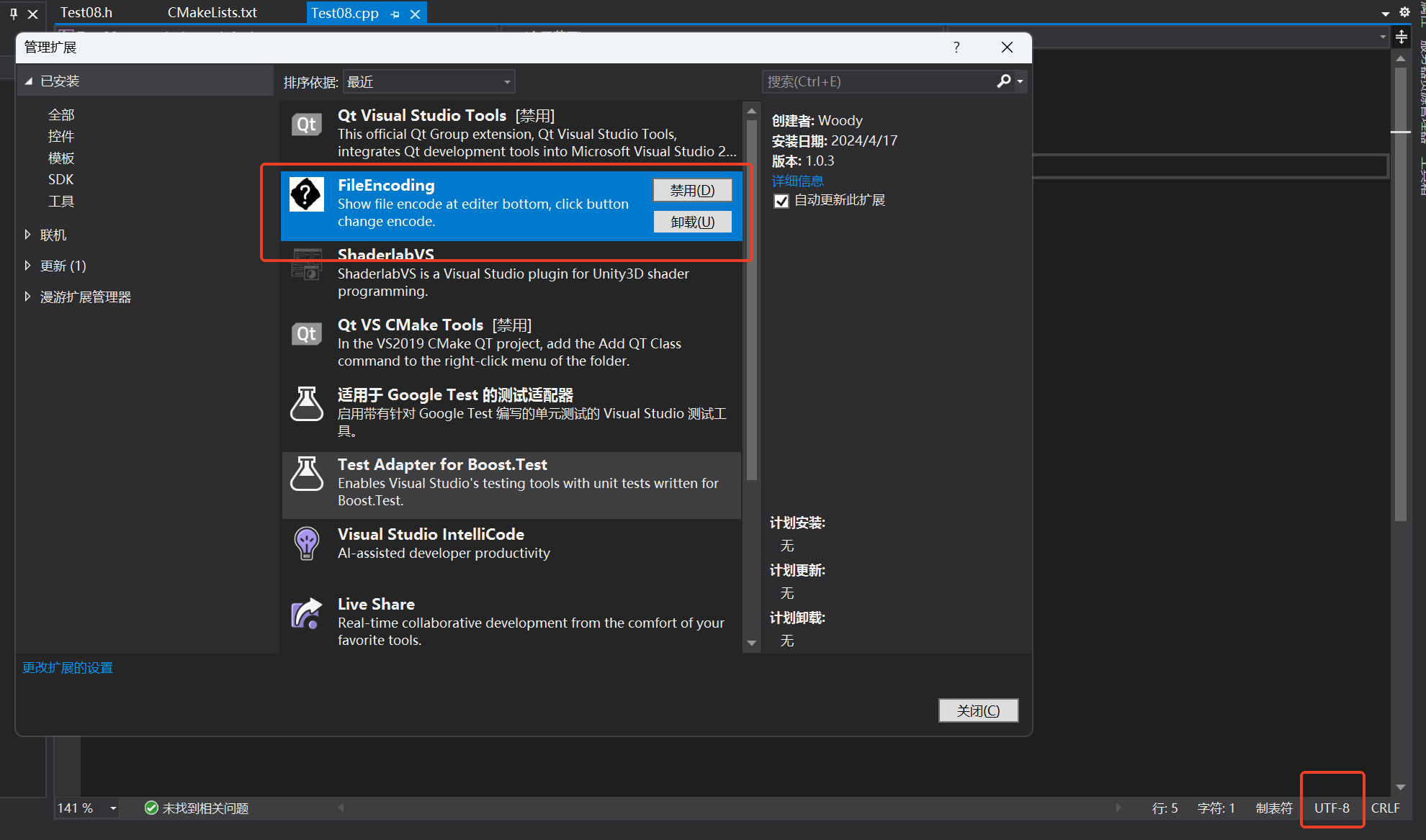
然后是给MSVC编译器增加一个编译选项:/utf-8,这个编译选项会将源代码字符集和执行字符集指定为使用UTF-8编码字符集。具体来说,如果你是原生的MSVC的项目,应该执行的操作是:
- 打开项目“属性页” 对话框。
- 依次选择“配置属性”->“C/C++”->“命令行”属性页。
- 在“附加选项”中,添加/utf-8选项以指定首选编码。
- 选择“确定”以保存更改。
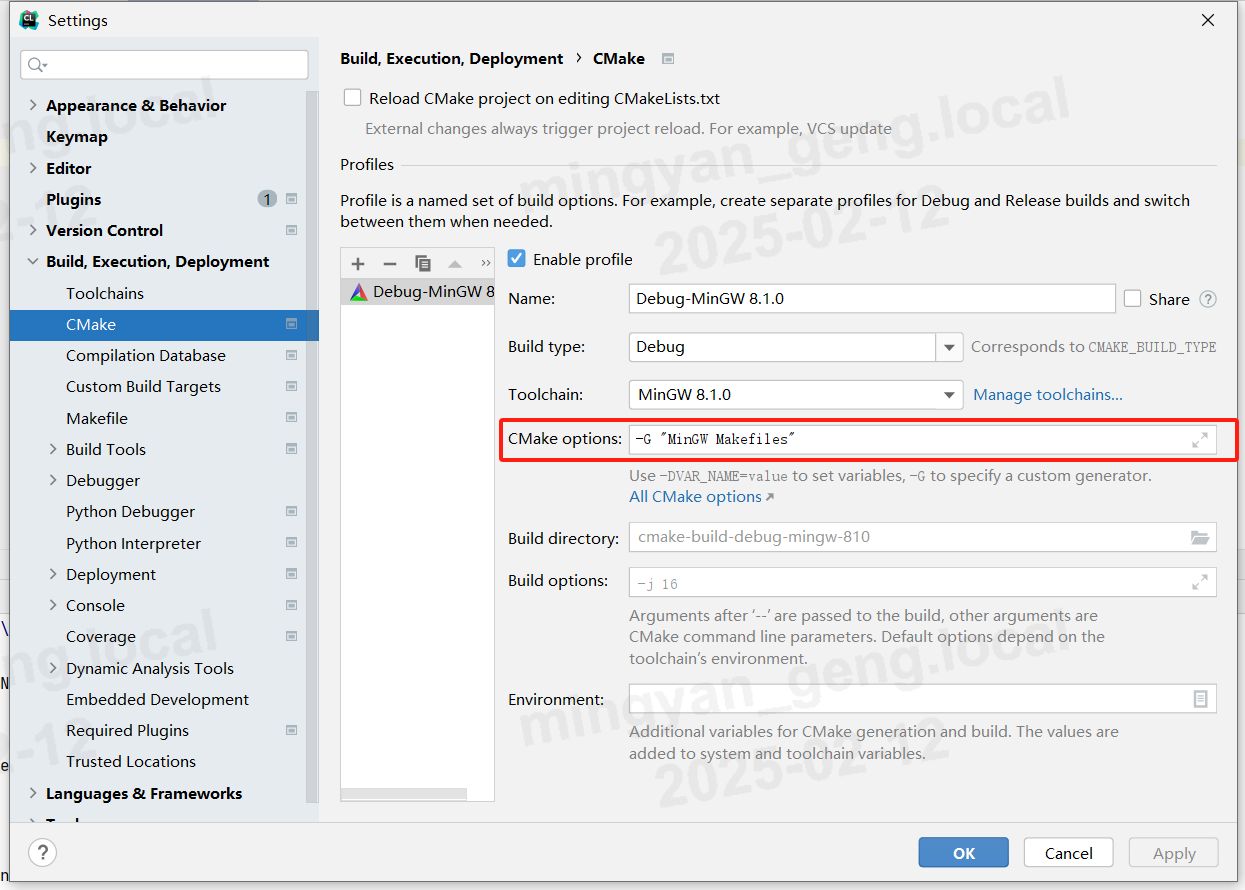
如果是CMake项目,那么在CMakeLists.txt中增加如下配置,意思是如果是MSVC编译器,就增加/utf-8选项:
# 判断编译器类型
if ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Clang")message(">> using Clang")
elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "GNU")message(">> using GCC")
elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Intel")message(">> using Intel C++")
elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "MSVC")message(">> using Visual Studio C++")add_compile_options("/utf-8")
else()message(">> unknow compiler.")
endif()
最后,还需要考虑一点,字符最终需要显示到终端的,无论是GUI终端还是命令行终端,你必须确保终端的字符编码也是UTF-8编码才行。例如打印字符串到命令行终端,可使用如下示例代码(C++17环境下):
#include <iostream>
#ifdef _WIN32
#include <Windows.h>
#endifusing namespace std;int main() {
#ifdef _WIN32SetConsoleOutputCP(65001);
#endifstring str = "这是中文字符串,测试能否正确显示!";std::cout << str << endl;return 0;
}
这段代码的意思是在Windows环境下,设置控制台输出窗口的代码页是65001,也就是UTF-8编码。同时由于代码文件是UTF-8编码,字符串常量"这是中文字符串,测试能否正确显示!"也是UTF-8编码。std::string与具体的字符编码无关,它只是个8位字符数组,因此可以接受UTF-8编码的字符串并被打印输出。
2.3 渐进升级
按照以上步骤编写新的基于UTF-8编码的程序是没有问题的,但是实际操作大概率不行。因为C++程序往往有足够多的存量代码,我们往往需要以库的形式或者组件的形式来调用它们。问题是C++程序调用库是需要include头文件的,一旦设置了/utf-8编译选项,MSVC就会强制将这些旧代码按照UTF-8编码进行编译。在这种情况下,有很大的概率会出现乱码问题,或者出现如下编译错误:
warning C4828: 文件包含在偏移 0x66f 处开始的字符,该字符在当前源字符集中无效(代码页 65001)。
一般而言,MSVC项目的存量代码一般为本地编码(GBK编码),最直接的解决方案是一个一个地按照上述方式去升级这些代码,但是这样做就要看存量代码有多少、是否有权限这么做了,如果工作量太大还是不建议这么做。比较合理的办法还是渐进式更新:
- 只在新的代码项目中使用UTF-8编码的方式。
- 旧的代码项目还是使用GBK编码。
- 修改调用的旧代码库的头文件,保证没有非ASCII字符(中文字符)。
由于UTF-8编码是兼容ASCII字符的,因此即使强制要求MSVC按照UTF-8编码编译这个文件,也是不会出现乱码或者编译不通过的问题的。并且这样也是有可行性的,一般头文件的代码内容很少,修改起来也不容易出错。其实在大部分情况下也确实不需要修改什么,大多数常用库为了方便国际通用,头文件很少出现非ASCII字符。
当然这样做也存在一个问题:旧的代码接口是本地编码,新的代码却是UTF-8编码,调用的时候字符串传参需要将UTF-8编码转换成GBK编码字符串。但是这也是没有办法的办法,只修改接口部分的代码总比大规模修改程序好。想要完全避免字符编码的问题就要统一使用UTF-8,最好按照这个原则,从调用端到底层框架逐渐将代码都升级成UTF-8编码。
3. 案例
所有接口统一使用UTF-8编码真的是任何程序开发的金玉良言,否则就总是会遇到字符编码转换的问题,非常影响工作效率。不过可能因为兼容性或者其他原因,目前还做不到将所有的接口统一编码。笔者这里就列举一些常用的组件和库的接口的字符串编码案例。
3.1 std::filesystem::path
个人认为C++17的std::filesystem使用起来还是很方便的,但是std::filesystem::path的初始化并没有如我所想统一使用UTF-8编码。在Linux环境下初始化std::filesystem::path使用的确实是UTF-8编码字符串,但是在Windows环境下,初始化需要使用UTF-16编码字符串。例如一个初始化路径的跨平台代码:
#ifdef _WIN32
std::filesystem::path launchConfigPath =L"C:/Github/中文路径/launch-config.json";
#else
std::filesystem::path launchConfigPath ="/home/Github/中文路径/launch-config.json";
#endif
在MSVC编译器中,以L开头的字符串是一个宽字符字符串,对应于UTF-16编码。而如果本身是一个UTF-8编码的std::string,那么就需要将其转换成UTF-16编码的字符串std::wstring,Windows下std::filesystem::path能使用std::wstring对象进行初始化。std::string和std::wstring的相互转换如下所示:
std::wstring Utf8StringToWideString(const std::string& utf8_str) {std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;return converter.from_bytes(utf8_str);
}std::string WideStringToUtf8String(const std::wstring& wstr) {std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;return converter.to_bytes(wstr);
}
经过笔者的验证,其实Windows环境下使用GBK编码字符串初始化std::filesystem::path也可以。不过这不是重点,重点是我很疑惑Windows环境下为什么不干脆统一使用UTF-8编码初始化呢?本身标准库的意义就在于统一不同系统环境下的行为,这里为了保证统一不得不又采用预编译的办法来跨平台,感觉这里标准库白标准了,微软真是不做人啊。
不过,虽然std::filesystem::path的初始化使用的字符编码不统一,但是却可以返回UTF-8编码字符串,函数接口是u8string()。另外,generic_u8string()接口不仅可以返回UTF-8编码字符串,而且所有路径的目录分隔符被转换为正斜杠(/)。所以,笔者采用的策略是只要是路径相关的字符串,一开始就初始化成std::filesystem::path,路径相关的操作就局限在这个对象中进行,从而避免考虑字符编码的问题。并且,std::fstream也能接受std::filesystem::path作为参数,使用起来还是很方便的。
3.2 Qt的QString
Qt的QString笔者认为是最好的C++字符串实现,字符编码实现的非常不错。在代码文件保存为UTF-8编码,并且编译器按照UTF-8编码字符串的情况下,可以直接使用字符串字面量进行初始化:
QString str = "这是中文字符串";
这是因为"这是中文字符串"使用的是UTF-8编码,这个字符串字面量会被正确地解释为Unicode字符。接着当构造QString时,它能够自动处理Unicode字符并将其转换成内部使用的 UTF-16编码。
但是对于已经存在的std::string或者其他形式的C风格字符串,需要显式指明其编码格式,以确保QString能够正确地解码它们,例如:
std::string stdString = "一些UTF-8编码的文本";
QString str = QString::fromUtf8(stdString.c_str());
这是因为QString默认假设传入的C风格字符串是以ISO 8859-1(Latin-1)编码的。
3.3 GDAL
在统一使用UTF-8编码之后,就不用再设置文件路径的字符编码不是UTF-8了,直接传递到GDALOpen函数中即可。
//CPLSetConfigOption("GDAL_FILENAME_IS_UTF8", "NO");
const char* imgPath = "E:\\Data\\lena.bmp";
GDALDataset* img = (GDALDataset *)GDALOpen(imgPath, GA_ReadOnly);
3.4 OpenCV
OpenCV的读取图像接口cv::imread使用的应该是本地编码,在Windows环境下需要进行编码转换:
#ifdef _WIN32img = cv::imread(Utf8ToGbk(externalTexPath.u8string()), cv::IMREAD_UNCHANGED);
#elseimg = cv::imread(externalTexPath.u8string(), cv::IMREAD_UNCHANGED);
#endif
笔者之前的博文《c++中utf8字符串和gbk字符串的转换》中提供了Utf8编码与GBK编码之间的转换。
4. 补充
笔者查阅字符编码相关的资料的时候,就感叹这方面的知识还真就是一本烂账,除非深入了解,否则是无法完全论述清楚的。个人看法是要认清字符编码的本质是将有意义的字符与二进制数据类型类型对应起来。以国内的情况来说,我们只需要理解三种字符编码:ASCII、ANSI以及Unicode,它们大致分别对应于1个字节、2个字节、以及4个字节。
- ASCII编码是原始编码,包含大小写英文字符+数字+标点符号+控制字符+特殊字符,总共是128个。因此准确来说ASCII编码是7位字符编码,但在高级语言中使用最小的数据类型就是1字节整型了。
- ANSI编码是本地编码,在国内的Windows环境中通常指国标码(国家标准标码),更加具体一点就是GB2312、GBK和GB18030这三种编码。其中,GB2312编码是第一版国标码,GBK编码最常用,但是GB18030编码是最新的。国标码最初被设计出来的时候,是2个字节对应于1个字符,同时没有占用ASCII编码的内容,因此是兼容ANSI编码的。
- Unicode编码是国际编码,它被设计出来的目的就是囊括并且统一世界上所有的字符,以此解决世界上不同本地编码字符编码转换的问题。Unicode编码最初被设计出来的时候,同样是2个字节对应于1个字符,这就是UTF-16编码。但是字符的增加,Unicode编号很快不够用了,就扩展成了4字节对应于1个字符,这就是UTF-32编码。UTF-32编码的问题就是太浪费了,比如UTF-32编码的前128位与ANSI编码的编号是一样的,但是却要用4个字节表示,实际上与ANSI编码一样,同样使用1个字节即可。基于这样的思想就诞生了UTF-8编码,每个字符根据所分配的Unicode编号大小,使用1~4个字节来表示。
- 那么原来2个字节的UTF-16编码遇到超过2字节范围的字符怎么办呢?答案是使用2个连续的2个字节来进行表示。UTF-16编码的影响还是非常深远的,C#的
string、Java的string、Qt的QString以及Win32 API普遍都使用UTF-16编码。为了保证对4个字节字符的兼容,它们往往会采用“代理对”的技术,由系统实现正常处理字符串长度、索引或其他涉及字符级别的操作。 - UTF-8变长编码的思想也影响了国标码的设计,最新的国标码GB18030编码也扩展成为了变长编码,并且兼容ASCII字符的单字节编码,以及GB2312和GBK的双字节编码部分。
- 本文中笔者不想将问题复杂化,特意没有论述到UTF-8 BOM编码的内容。UTF-8 BOM编码与UTF-8编码是一样的,只不过在字符内容的部分加了几个标识符,从而可以让编辑器知道该字符内容是UTF-8编码的。UTF-8 BOM编码也是微软搞出来的,主要是用来方便在本地编码的环境中识别出UTF-8编码。一般国际上更推荐统一使用标准的UTF-8编码。
5. 参考
- /utf-8 (Set source and execution character sets to UTF-8)
- 探究 Visual Studio 中的乱码问题
- VS2019 报错“常量中有换行符”错误原因分析
- vs2015:/utf-8 选项解决 UTF-8 without BOM 源码中文输出乱码问题



![[tldr]通过指令获取github仓库的单个文件的内容](https://img2024.cnblogs.com/blog/3573053/202502/3573053-20250212185738941-1108203471.png)