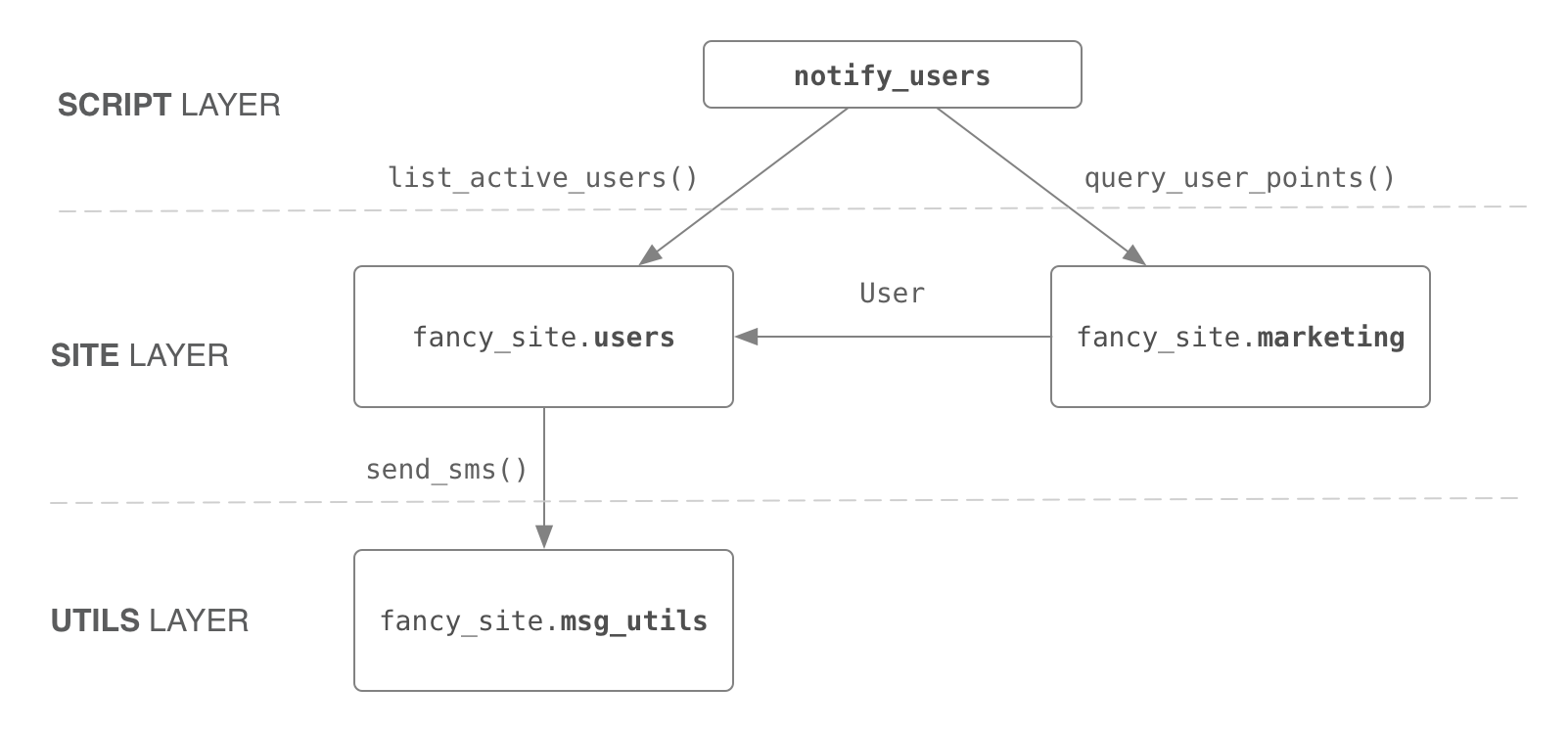
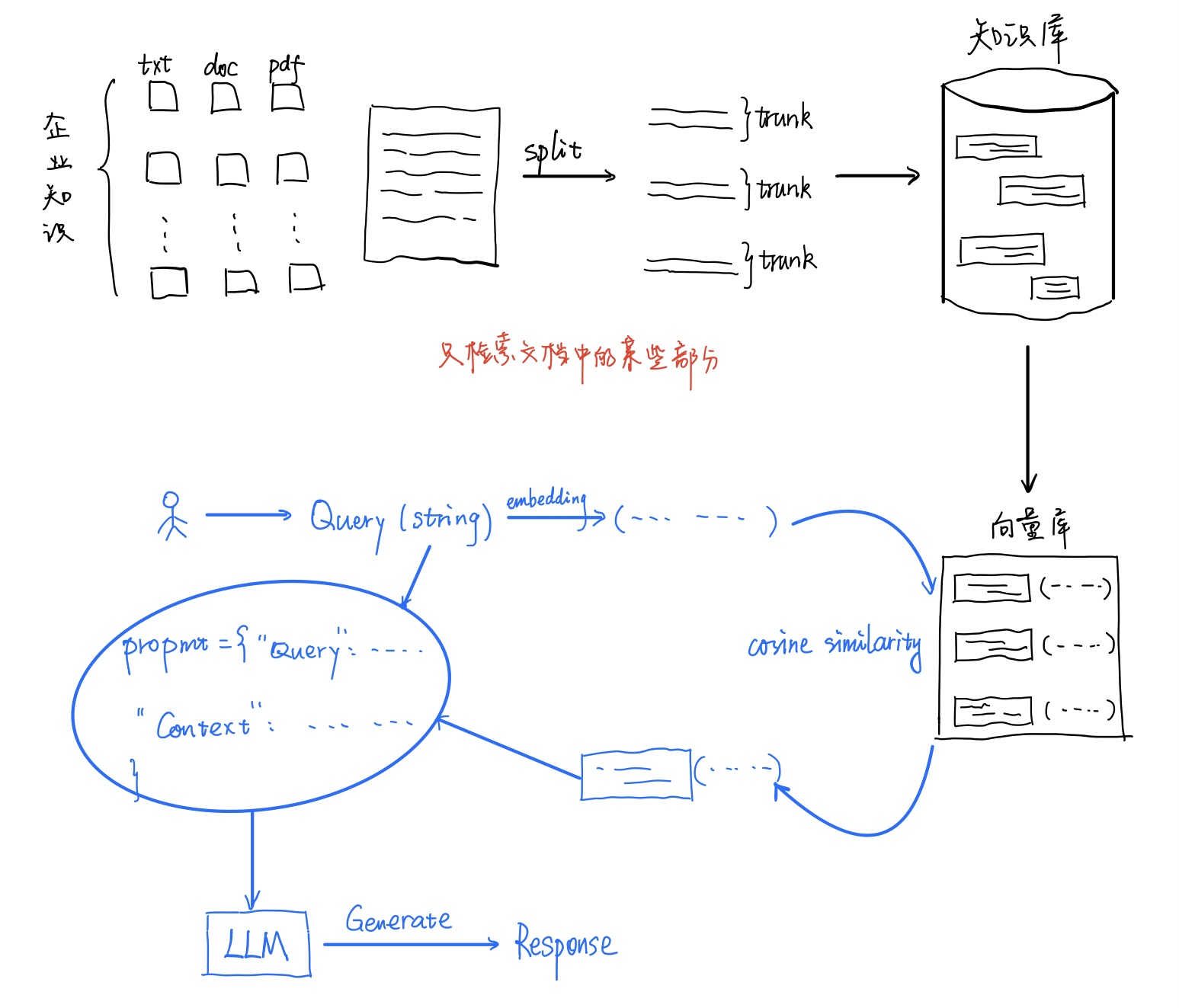
张量生成
l = [[1., -1.], [-1, 1]]
tensor_from_list = torch.tensor(l)
print(tensor_from_list)
print(tensor_from_list.dtype)
print(tensor_from_list.device)
tensor([[ 1., -1.],[-1., 1.]])
torch.float32
cpu
arr = np.array([[1, 2, 3], [4, 5, 6]])
tensor_from_arr = torch.tensor(arr)
print(tensor_from_arr)
print(tensor_from_arr.dtype)
print(tensor_from_arr.device)
tensor([[1, 2, 3],[4, 5, 6]])
torch.int64
cpu
arr = np.array([[1, 2, 3], [4, 5, 6]])
tensor_from_numpy = torch.from_numpy(arr)
print(tensor_from_numpy)
# 修改numpy数组,tensor也随之改变
arr[0, 0] = 0
print(tensor_from_numpy)
tensor([[1, 2, 3],[4, 5, 6]])
tensor([[0, 2, 3],[4, 5, 6]])
t = torch.zeros((3, 3))
print(t)
t = torch.ones((3, 3))
print(t)
tensor([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])
tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]])
t = torch.zeros_like(tensor_from_arr)
print(t)
t = torch.ones_like(tensor_from_arr)
print(t)
tensor([[0, 0, 0],[0, 0, 0]])
tensor([[1, 1, 1],[1, 1, 1]])
print(torch.arange(1, 2.51, 0.5))
tensor([1.0000, 1.5000, 2.0000, 2.5000])
# 包含start,end
print(torch.linspace(3, 10, steps=5))
tensor([ 3.0000, 4.7500, 6.5000, 8.2500, 10.0000])
print(torch.eye(3))
print(torch.eye(3, 4))
tensor([[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
tensor([[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.]])
mean = torch.arange(1, 11.)
std = torch.arange(1, 0, -0.1)
normal = torch.normal(mean=mean, std=std)
print("mean: {}, \nstd: {}, \nnormal: {}".format(mean, std, normal))
mean: tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]),
std: tensor([1.0000, 0.9000, 0.8000, 0.7000, 0.6000, 0.5000, 0.4000, 0.3000, 0.2000,0.1000]),
normal: tensor([ 3.4626, 1.9700, 3.6703, 5.2298, 4.3230, 5.8943, 6.7460, 8.4585,8.7591, 10.0207])
print(torch.rand((3, 4)))
tensor([[0.6506, 0.8247, 0.2877, 0.9992],[0.8475, 0.7129, 0.6558, 0.1091],[0.8137, 0.9395, 0.7801, 0.1788]])
print(torch.randint(1, 5, (2, 3)))
tensor([[1, 4, 4],[1, 3, 3]])
张量维度的理解
# 零维:只是一个数字
torch.tensor(5).shape
torch.Size([])
# 一维:有三个元素
torch.tensor([1, 2, 3]).shape
torch.Size([3])
# 二维:有两个一维张量,每个一维张量有三个元素(矩阵:行数 * 列数)
torch.tensor([[1, 2, 3], [4, 5, 6]]).shape
torch.Size([2, 3])
# 三维:有两个二维张量,每个二维张量是3 * 4矩阵
torch.tensor([[[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]], [[5, 6, 7, 8], [5, 6, 7, 8], [5, 6, 7, 8]]]).shape
torch.Size([2, 3, 4])
# 四维:有两个三维张量
torch.tensor([[[[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]], [[5, 6, 7, 8], [5, 6, 7, 8], [5, 6, 7, 8]]],[[[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]], [[5, 6, 7, 8], [5, 6, 7, 8], [5, 6, 7, 8]]]]).shape
torch.Size([2, 2, 3, 4])
t1 = torch.tensor([[[1, 2, 3, 3], [1, 2, 3, 3], [1, 2, 3, 3]], [[4, 5, 6, 6], [4, 5, 6, 6], [4, 5, 6, 6]]])t2 = torch.tensor([[[1, 2, 3, 6], [1, 2, 3, 6], [1, 2, 3, 6]], [[4, 5, 6, 5], [4, 5, 6, 5], [4, 5, 6, 5]]])
concat测试
总结:dim等于几,就改变哪一维,就在哪一维上面堆积
torch.concat([t1, t2], dim=0).shape
torch.Size([4, 3, 4])
torch.concat([t1, t2], dim=1).shape
torch.Size([2, 6, 4])
torch.concat([t1, t2], dim=2).shape
torch.Size([2, 3, 8])
transpose测试
t1
tensor([[[1, 2, 3, 3],[1, 2, 3, 3],[1, 2, 3, 3]],[[4, 5, 6, 6],[4, 5, 6, 6],[4, 5, 6, 6]]])
# 交换两个维度
## 此处交换后两个维度,实际上就是矩阵转置
t1.transpose(1, 2)
tensor([[[1, 1, 1],[2, 2, 2],[3, 3, 3],[3, 3, 3]],[[4, 4, 4],[5, 5, 5],[6, 6, 6],[6, 6, 6]]])
permute测试
拧魔方
假设tensor的形状为(a, b, c),执行permute(1, 2, 0)
则重排后的形状为(b, c, a)
解读:
- 重排的第0维放原张量的第1维b
- 重排的第1维放原张量的第2维c
- 重排的第2维放原张量的第0维a
t1
tensor([[[1, 2, 3, 3],[1, 2, 3, 3],[1, 2, 3, 3]],[[4, 5, 6, 6],[4, 5, 6, 6],[4, 5, 6, 6]]])
# 0维不动,矩阵转置
t1.permute(0, 2, 1)
tensor([[[1, 1, 1],[2, 2, 2],[3, 3, 3],[3, 3, 3]],[[4, 4, 4],[5, 5, 5],[6, 6, 6],[6, 6, 6]]])
# 0维动
t1.permute(1, 0, 2)
tensor([[[1, 2, 3, 3],[4, 5, 6, 6]],[[1, 2, 3, 3],[4, 5, 6, 6]],[[1, 2, 3, 3],[4, 5, 6, 6]]])
t1.permute(2, 0, 1)
tensor([[[1, 1, 1],[4, 4, 4]],[[2, 2, 2],[5, 5, 5]],[[3, 3, 3],[6, 6, 6]],[[3, 3, 3],[6, 6, 6]]])
t1.permute(1, 2, 0)
tensor([[[1, 4],[2, 5],[3, 6],[3, 6]],[[1, 4],[2, 5],[3, 6],[3, 6]],[[1, 4],[2, 5],[3, 6],[3, 6]]])
t1.permute(2, 1, 0)
tensor([[[1, 4],[1, 4],[1, 4]],[[2, 5],[2, 5],[2, 5]],[[3, 6],[3, 6],[3, 6]],[[3, 6],[3, 6],[3, 6]]])
reshape测试
相当于将原tensor的元素按行取出,然后按行放入到新形状的tensor中
保持reshape前后张量内元素个数一致
t1
tensor([[[1, 2, 3, 3],[1, 2, 3, 3],[1, 2, 3, 3]],[[4, 5, 6, 6],[4, 5, 6, 6],[4, 5, 6, 6]]])
t1.reshape((2, 4, 3))
tensor([[[1, 2, 3],[3, 1, 2],[3, 3, 1],[2, 3, 3]],[[4, 5, 6],[6, 4, 5],[6, 6, 4],[5, 6, 6]]])
t1.reshape((1 ,4, 6))
tensor([[[1, 2, 3, 3, 1, 2],[3, 3, 1, 2, 3, 3],[4, 5, 6, 6, 4, 5],[6, 6, 4, 5, 6, 6]]])
squeeze测试
可去掉维度为1的轴,实现张量的压缩。
torch.tensor([[[1, 2, 3, 3], [1, 2, 3, 3], [1, 2, 3, 3]]]).shape
torch.Size([1, 3, 4])
torch.tensor([[[1, 2, 3, 3], [1, 2, 3, 3], [1, 2, 3, 3]]]).squeeze()
tensor([[1, 2, 3, 3],[1, 2, 3, 3],[1, 2, 3, 3]])
torch.tensor([[[1, 2, 3, 3], [1, 2, 3, 3], [1, 2, 3, 3]]]).squeeze().shape
torch.Size([3, 4])
张量乘法测试
torch.mul()
同torch.multiply()
- 逐元素相乘
- 支持广播机制
a = torch.tensor([1, 2, 3])
b = torch.tensor([1, 2, 3]).reshape((3, 1))
print(a)
print(b)
tensor([1, 2, 3])
tensor([[1],[2],[3]])
torch.mul(a, b)
tensor([[1, 2, 3],[2, 4, 6],[3, 6, 9]])
torch.dot()
向量点乘
只支持两个一维向量
torch.dot(a, a)
tensor(14)
torch.mm()
矩阵乘法,需满足矩阵乘法规则
mat1 = torch.tensor([[1,2,3], [4,5,6]])
mat2 = torch.tensor([[1,2], [3,4], [5,6]])
print(mat1.shape)
print(mat2.shape)
torch.Size([2, 3])
torch.Size([3, 2])
torch.mm(mat1, mat2)
tensor([[22, 28],[49, 64]])
mat3 = torch.tensor([[1,2], [3,4], [5,6], [7,8]])
torch.mm(mat1, mat3)
---------------------------------------------------------------------------RuntimeError Traceback (most recent call last)Cell In[106], line 21 mat3 = torch.tensor([[1,2], [3,4], [5,6], [7,8]])
----> 2 torch.mm(mat1, mat3)RuntimeError: mat1 and mat2 shapes cannot be multiplied (2x3 and 4x2)
torch.mv()
矩阵与向量相乘,需满足矩阵乘法规则
torch.bmm()
批量矩阵乘法
batch_matrix_1 = torch.tensor([ [[1, 2], [3, 4], [5, 6]] , [[-1, -2], [-3, -4], [-5, -6]] ])
batch_matrix_2 = torch.tensor([ [[1, 2], [3, 4]], [[1, 2], [3, 4]] ])
print(batch_matrix_1.shape)
print(batch_matrix_2.shape)
torch.Size([2, 3, 2])
torch.Size([2, 2, 2])
torch.bmm(batch_matrix_1, batch_matrix_2)
tensor([[[ 7, 10],[ 15, 22],[ 23, 34]],[[ -7, -10],[-15, -22],[-23, -34]]])
torch.matmul()
torch.matmul(input, other, *, out=None) → Tensor
结果根据input和other的维度确定。
def print_info(A, B):print(f"A: {A}\nB: {B}")print(f"A 的维度: {A.dim()},\t B 的维度: {B.dim()}")print(f"A 的元素总数: {A.numel()},\t B 的元素总数: {B.numel()}")print(f"torch.matmul(A, B): {torch.matmul(A, B)}")print(f"torch.matmul(A, B).size(): {torch.matmul(A, B).size()}")
# input_d = 1, other_d = 1, 两个一维向量,点积
A = torch.randint(0, 5, size=(2,))
B = torch.randint(0, 5, size=(2,))print_info(A, B)
A: tensor([0, 2])
B: tensor([4, 2])
A 的维度: 1, B 的维度: 1
A 的元素总数: 2, B 的元素总数: 2
torch.matmul(A, B): 4
torch.matmul(A, B).size(): torch.Size([])
# input_d = 2, other_d = 2, 两个二维矩阵,矩阵乘法
A = torch.randint(0, 5, size=(2,1))
B = torch.randint(0, 5, size=(1,2))print_info(A, B)
A: tensor([[4],[2]])
B: tensor([[2, 3]])
A 的维度: 2, B 的维度: 2
A 的元素总数: 2, B 的元素总数: 2
torch.matmul(A, B): tensor([[ 8, 12],[ 4, 6]])
torch.matmul(A, B).size(): torch.Size([2, 2])
# input_d = 1, other_d = 2, 第一个是一维向量,第二个是二维矩阵,广播机制+矩阵乘法
A = torch.randint(0, 5, size=(2, ))
B = torch.randint(0, 5, size=(2, 2))print_info(A, B)
A: tensor([4, 2])
B: tensor([[1, 3],[2, 2]])
A 的维度: 1, B 的维度: 2
A 的元素总数: 2, B 的元素总数: 4
torch.matmul(A, B): tensor([ 8, 16])
torch.matmul(A, B).size(): torch.Size([2])
## 下面的例子说明一维向量和二维矩阵不能以矩阵乘法相乘
torch.mm(A, B)
---------------------------------------------------------------------------RuntimeError Traceback (most recent call last)Cell In[149], line 1
----> 1 torch.mm(A, B)RuntimeError: self must be a matrix
## 要实现相乘,要用到广播机制
## A(2) -> A(1*2)
A_re = A.reshape((1, 2))
torch.mm(A_re, B)
tensor([[ 8, 16]])
## 再移除扩展之后的维度
torch.mm(A_re, B).squeeze()
tensor([ 8, 16])
# input_d = 2, other_d = 1, 第一个是二维矩阵,第二个是一维向量,广播机制+矩阵乘法
print_info(B, A)
A: tensor([[1, 3],[2, 2]])
B: tensor([4, 2])
A 的维度: 2, B 的维度: 1
A 的元素总数: 4, B 的元素总数: 2
torch.matmul(A, B): tensor([10, 12])
torch.matmul(A, B).size(): torch.Size([2])
## 类似地,广播机制
## A(2) -> A(2*1)
A_re = A.reshape((2, 1))
torch.mm(B, A_re).squeeze()
tensor([10, 12])
# input_d > 2, other_d = 1, 第一个是三维张量,第二个是一维向量
A = torch.randint(0, 5, size=(2, 1, 2))
B = torch.randint(0, 5, size=(2, ))print_info(A, B)## 这里可以看成单拎出 A 的最后 2 维与 B 做 input_d = 2 和 other_d = 1 的乘法:(1, 2) * (2, )
A: tensor([[[4, 1]],[[2, 0]]])
B: tensor([2, 0])
A 的维度: 3, B 的维度: 1
A 的元素总数: 4, B 的元素总数: 2
torch.matmul(A, B): tensor([[8],[4]])
torch.matmul(A, B).size(): torch.Size([2, 1])
# input_d > 2, other_d = 2, 第一个是三维张量,第二个是二维矩阵
A = torch.randint(0, 5, size=(2, 1, 2))
B = torch.randint(0, 5, size=(2, 1))print_info(A, B)## 类似地,这里可以看成单拎出 A 的最后 2 维与 B 做 input_d = 2 和 other_d = 2 的矩阵乘法:(1, 2) * (2, 1)
A: tensor([[[2, 3]],[[3, 0]]])
B: tensor([[2],[2]])
A 的维度: 3, B 的维度: 2
A 的元素总数: 4, B 的元素总数: 2
torch.matmul(A, B): tensor([[[10]],[[ 6]]])
torch.matmul(A, B).size(): torch.Size([2, 1, 1])
# input_d > 2, other_d > 2, 第一个是三维张量,第二个是二维矩阵
A = torch.randint(0, 5, size=(2, 1, 2, 1))
B = torch.randint(0, 5, size=(2, 1, 2))print_info(A, B)
A: tensor([[[[1],[1]]],[[[4],[3]]]])
B: tensor([[[4, 3]],[[0, 3]]])
A 的维度: 4, B 的维度: 3
A 的元素总数: 4, B 的元素总数: 4
torch.matmul(A, B): tensor([[[[ 4, 3],[ 4, 3]],[[ 0, 3],[ 0, 3]]],[[[16, 12],[12, 9]],[[ 0, 12],[ 0, 9]]]])
torch.matmul(A, B).size(): torch.Size([2, 2, 2, 2])
## 分析
## A(2, 1, 2, 1)
## B( , 2, 1, 2)
##->A(2, 2, 2, 1) A广播机制,后两维矩阵乘法(2,1)*(1,2)
print_info(B, A)
A: tensor([[[4, 3]],[[0, 3]]])
B: tensor([[[[1],[1]]],[[[4],[3]]]])
A 的维度: 3, B 的维度: 4
A 的元素总数: 4, B 的元素总数: 4
torch.matmul(A, B): tensor([[[[ 7]],[[ 3]]],[[[25]],[[ 9]]]])
torch.matmul(A, B).size(): torch.Size([2, 2, 1, 1])
## 分析
## B( , 2, 1, 2)
## A(2, 1, 2, 1)##->B(2, 2, 1, 1) B广播机制,复制一个三维张量,对应A的两个三维向量
##->A(2, 2, 2, 1) A广播机制,复制一个二维矩阵,对应B的两个三维向量