2024年2月24日至28日,国内AI领军企业DeepSeek以"开放即进化"为核心理念,举办了一场震动全球AI社区的"开源周"。在这场持续五天的技术盛宴中,DeepSeek连续发布了5款核心开源项目,覆盖算法优化、通信加速、矩阵计算、并行策略、数据存储全栈技术领域,展现出国产AI在底层技术上的突破性实力。其开源项目不仅以代码量为单位实现效率跃升(如300行代码定义矩阵乘法新范式),更通过真实场景测试数据证明:国产技术已具备重构全球AI基础设施的潜力。
第一天 FlashMLA
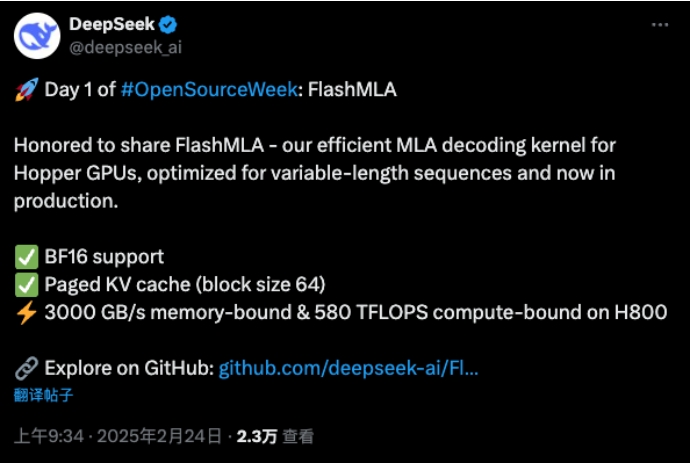
DeepSeek(深度求索)发布首个开源项目FlashMLA。根据DeepSeek在GitHub社区披露的信息,FlashMLA是适用于Hopper GPU(一种英伟达图形处理器架构)的高效MLA(多头潜注意力)解码内核,针对可变长度序列服务进行了优化。
https://github.com/deepseek-ai/DeepEP
FlashMLA 的主要应用场景包括:
长序列处理:适合处理数千个标记的文本,如文档分析或长对话。
实时应用:如聊天机器人、虚拟助手和实时翻译系统,降低延迟。
资源效率:减少内存和计算需求,便于在边缘设备上部署。
目前 AI 训练或推理主要依赖英伟达 H100 / H800,但软件生态还在完善。
由于 FlashMLA 的开源,未来它可以被集成到 vLLM(高效 LLM 推理框架)、Hugging Face Transformers 或 Llama.cpp(轻量级 LLM 推理) 生态中,从而有望让开源大语言模型(如 LLaMA、Mistral、Falcon)运行得更高效。
同样的资源,能干更多的活,还省钱。
因为 FlashMLA 拥有更高的计算效率(580 TFLOPS)和更好的内存带宽优化(3000 GB/s),同样的 GPU 资源就可以处理更多请求,从而降低单位推理成本。
对于 AI 公司或者云计算服务商来说,使用 FlashMLA 也就意味着更低的成本、更快的推理,让更多 AI 公司、学术机构、企业用户直接受益,提高 GPU 资源的利用率。
第二天 DeepEP
发布专家并行通信库 DeepEP:首个面向MoE模型的开源EP通信库,支持实现了混合专家模型训练推理的全栈优化!
https://github.com/deepseek-ai/FlashMLA

DeepEP 的核心亮点
✅ 高效优化的 All-to-All 通信: DeepEP 提供了高性能、低延迟的 GPU 集群内和集群间 all-to-all 通信内核,这正是 MoE 模型中专家路由和组合的关键所在。 你可以把它理解为 MoE 模型数据高速公路的升级版!
✅ 集群内 (Intranode) 和集群间 (Internode) 全面支持: 无论是单机多卡,还是多机多卡,DeepEP 都能完美驾驭。 它充分利用 NVLink 和 RDMA 等高速互联技术,最大化通信带宽
✅ 训练和推理预填充 (Prefilling) 的高性能内核: 对于模型训练和推理预填充阶段,DeepEP 提供了高吞吐量的内核,保证数据传输速度,加速模型迭代和部署
✅ 推理解码 (Decoding) 的低延迟内核: 针对对延迟敏感的推理解码场景,DeepEP 也准备了低延迟内核,采用纯 RDMA 通信,最大限度减少延迟,让你的模型响应更快!
✅ 原生 FP8 精度支持: 紧跟前沿技术,DeepEP 原生支持 FP8 低精度运算,进一步提升计算效率,节省显存
✅ 灵活的 GPU 资源控制,实现计算-通信重叠: DeepEP 支持精细化的 SM (Streaming Multiprocessors) 数量控制,并引入了基于 Hook 的通信-计算重叠方法,巧妙地在后台进行通信,不占用宝贵的 GPU 计算资源! 这意味着什么? 你的 GPU 可以更专注于计算,通信交给 DeepEP 在幕后默默加速!
第三天 DeepGEMM
DeepGEMM是一个专注于为FP8高效通用矩阵乘法(GEMM)库,支持普通及混合专家(MoE)分组的矩阵计算需求,可动态优化资源分配以提升算力效率。值得一提的是,DeepGEMM设计目标是为DeepSeek-V3/R1模型的训练与推理提供简洁高效的底层支持,尤其针对Hopper架构GPU(如H800)优化,兼顾高性能与低成本。
https://github.com/deepseek-ai/DeepGEMM

DeepGEMM 在各种计算场景下表现出色。 对于标准矩阵乘法,与基于 CUTLASS 3.6 的优化实现相比,速度提升 1.0 到 2.7 倍不等。小批量数据处理(M=64 或 128)获得了最显著的加速,最高达到 2.7 倍。
对于混合专家模型的计算,DeepGEMM 提供的两种特殊数据排列方式也有明显优势。 连续排列方式适用于训练和批量推理阶段,速度提升约 1.1 到 1.2 倍;掩码排列方式专为实时推理设计,支持与 CUDA 图技术配合使用,同样能提速 1.1 到 1.2 倍。
在 Hopper GPU 上最高可达 1350+FP8 TFLOPS。其他优点包括:
✅没有过多的依赖,像教程一样简洁
✅完全即时编译
✅核心逻辑约为 300 行,但在大多数矩阵大小上均优于专家调优的内核
✅支持密集布局和两种 MoE 布局
第四天 DualPipe、EPLB和profile-data
DeepSeek“开源周”第四弹,开源最新优化并行策略,包括DualPipe、专家并行负载均衡器(EPLB)和全流程性能数据(profile-data)。
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
据介绍,DualPipe和EPLB是面向大规模AI模型训练的两项核心技术,分别聚焦于分布式训练效率优化和专家并行负载均衡,均为V3/R1而设计。
具体而言,DualPipe是一种双向流水线并行算法,它通过“双向管道调度”和“计算通信重叠”,旨在减少分布式训练中的流水线“气泡”(空闲时间),让训练过程像流水线一样顺畅,提升GPU利用率。
l 架构适配:专为英伟达 Hopper 架构 GPU 定制,深度契合其特性,大幅提升运行效率。
l 分页 KV 缓存:创新分页存储关键数据,GPU 可快速精准定位,减少读取延迟,加速计算流程。
l BF16 精度:平衡计算准确性与内存占用,降低内存负担,提升数据传输效率,节约硬件资源成本。
l 可变序列处理:能灵活应对自然语言处理、视频分析等场景中输入数据长度的差异,高效完成任务,拓展应用场景。
l 高性能表现:在 H800 GPU 上实现 3000GB/s 内存带宽与 580 TFLOPS 计算性能,轻松应对复杂模型训练与实时推理任务。
l 实践验证:已在 DeepSeek 实际业务中成功部署,经受高并发、大数据量考验,证明其在真实生产环境中的可靠性与价值。
第五天 3FS
DeepSeek开源周第五天,DeepSeek在官方X账号宣布开源3FS,它是所有Deepseek数据访问的助推器。
https://github.com/deepseek-ai/3FS
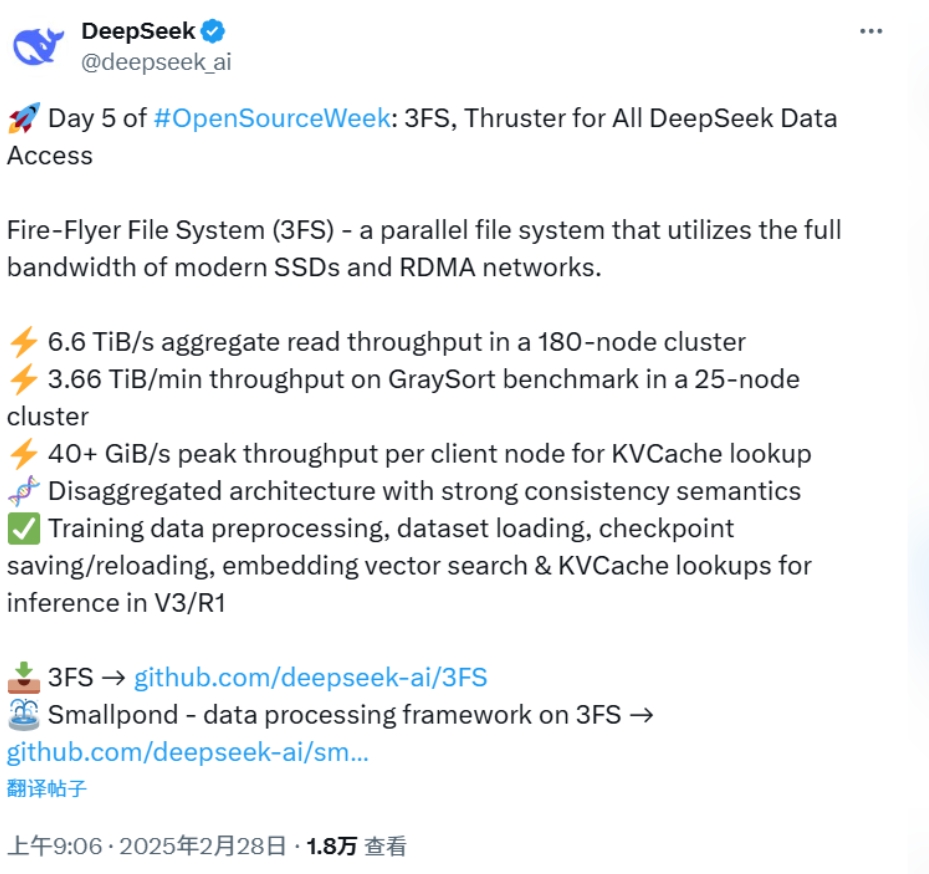
萤火虫文件系统(3FS)是一个高性能的分布式文件系统,旨在应对AI训练和推理工作负载的挑战。它利用现代SSD和RDMA网络,提供一个共享存储层,简化分布式应用程序的开发。3FS的主要特性和优势包括:
性能与易用性
解耦架构:结合数千个SSD的吞吐量和数百个存储节点的网络带宽,使应用程序能够以无位置感知的方式访问存储资源。
强一致性:通过链式复制与分配查询(CRAQ)实现强一致性,使应用程序代码简单且易于理解。
文件接口:开发了由事务性键值存储(如FoundationDB)支持的无状态元数据服务。文件接口广为人知且无处不在,无需学习新的存储API。
多样化工作负载
数据准备:将数据分析管道的输出组织成层次化的目录结构,并高效管理大量中间输出。
数据加载器:通过跨计算节点随机访问训练样本,消除了预取或混排数据集的需求。
检查点:支持大规模训练的高吞吐量并行检查点。
推理的KVCache:提供了一种经济高效的替代方案,替代基于DRAM的缓存,提供高吞吐量和显著更大的容量。
总结
在这场开源盛宴中,最值得关注的是DeepSeek展现出的技术普惠理念:
- 300行代码定义矩阵乘法新范式,降低芯片研发门槛
- 双向流水线设计让中小企业也能玩转千卡集群
- RDMA+SSD组合方案推动数据基础设施平民化
正如DeepSeek官方所言:"我们相信,AI技术的发展速度应该由全球开发者共同决定。"这场开源周不仅是一次技术展示,更是中国AI企业向世界发出的开放宣言——通过共享底层技术,加速人工智能惠及全人类的进程。