1 啥是文本张量表示?
将一段文本使用张量表示,一般将词汇表示成向量,称作词向量,再由各个词向量按序组成矩阵形成文本表示,如:
["人生", "该", "如何", "起头"]==># 每个词对应矩阵中的一个向量
[[1.32, 4,32, 0,32, 5.2],[3.1, 5.43, 0.34, 3.2],[3.21, 5.32, 2, 4.32],[2.54, 7.32, 5.12, 9.54]]
2 作用
文本表示成张量(矩阵)形式,能使语言文本可作为计算机处理程序的输入,进行后续的解析工作。
3 表示方法
3.1 one-hot词向量表示
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同。
n的大小是整个语料中不同词汇的总数,如:
["改变", "要", "如何", "起手"]`
==>[[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]
one-hot编码实现
# 导入用于对象保存与加载的joblib
from sklearn.externals import joblib
# 导入keras中的词汇映射器Tokenizer
from keras.preprocessing.text import Tokenizer
# 假定vocab为语料集所有不同词汇集合
vocab = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# 实例化一个词汇映射器对象
t = Tokenizer(num_words=None, char_level=False)
# 使用映射器拟合现有文本数据
t.fit_on_texts(vocab)for token in vocab:zero_list = [0]*len(vocab)# 使用映射器转化现有文本数据, 每个词汇对应从1开始的自然数# 返回样式如: [[2]], 取出其中的数字需要使用[0][0]token_index = t.texts_to_sequences([token])[0][0] - 1zero_list[token_index] = 1print(token, "的one-hot编码为:", zero_list)# 使用joblib工具保存映射器, 以便之后使用
tokenizer_path = "./Tokenizer"
joblib.dump(t, tokenizer_path)
输出效果:
鹿晗 的one-hot编码为: [1, 0, 0, 0, 0, 0]
王力宏 的one-hot编码为: [0, 1, 0, 0, 0, 0]
李宗盛 的one-hot编码为: [0, 0, 1, 0, 0, 0]
陈奕迅 的one-hot编码为: [0, 0, 0, 1, 0, 0]
周杰伦 的one-hot编码为: [0, 0, 0, 0, 1, 0]
吴亦凡 的one-hot编码为: [0, 0, 0, 0, 0, 1]# 同时在当前目录生成Tokenizer文件, 以便之后使用
one-hot编码器的使用
# 导入用于对象保存与加载的joblib
# from sklearn.externals import joblib
# 加载之前保存的Tokenizer, 实例化一个t对象
t = joblib.load(tokenizer_path)# 编码token为"李宗盛"
token = "李宗盛"
# 使用t获得token_index
token_index = t.texts_to_sequences([token])[0][0] - 1
# 初始化一个zero_list
zero_list = [0]*len(vocab)
# 令zero_List的对应索引为1
zero_list[token_index] = 1
print(token, "的one-hot编码为:", zero_list)
输出:
李宗盛 的one-hot编码为: [1, 0, 0, 0, 0, 0]
one-hot编码评价
- 优势:操作简单,易理解
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存
正因这明显劣势,该编码方式应用越来越少,取而代之是稠密向量的表示方法word2vec和word embedding。
3.2 word2vec
一种将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,包含如下两种训练模式:
3.2.1 CBOW(Continuous bag of words)
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇:
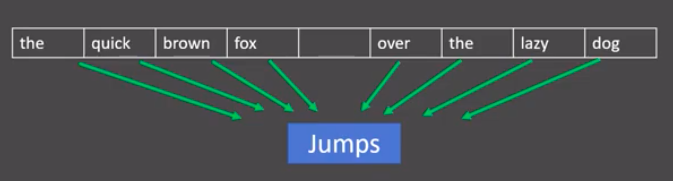
图中窗口大小为9,使用前后4个词汇对目标词汇进行预测。
执行过程
若给定训练语料仅一句话:Hope can set you free(愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set。CBOW模式,所以将使用Hope和set作输入,can作输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码,如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5,3指最后得到的词向量维度)相乘之后再相加,得到上下文表示矩阵(3x1):
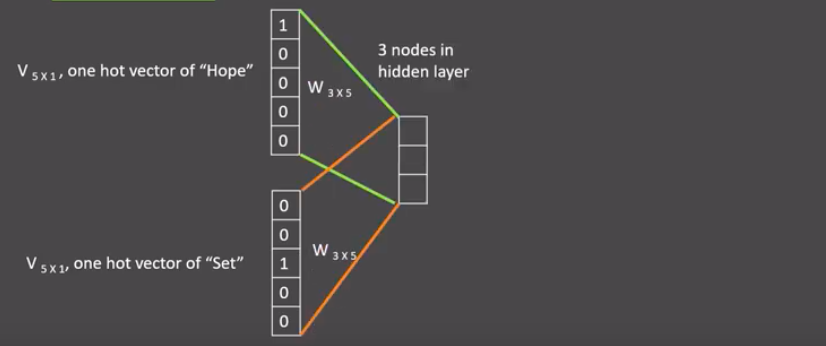
再将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘,得到5x1的结果矩阵,它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失计算,再更新网络参数完成一次模型迭代。
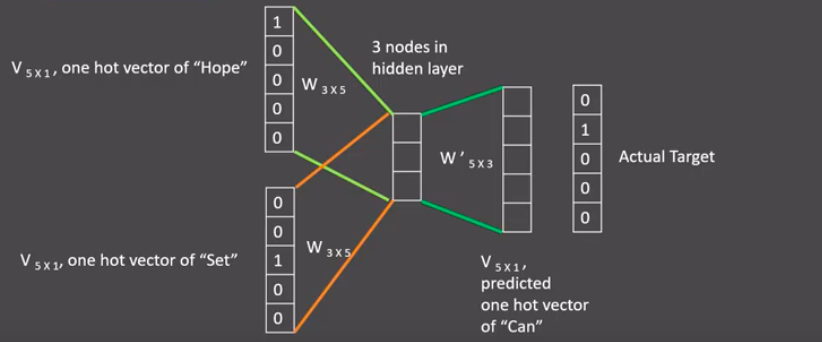
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
3.2.2 skipgram
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇。
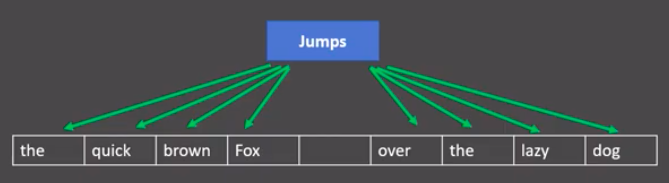
图中窗口大小为9, 使用目标词汇对前后四个词汇进行预测。
执行过程
Hope can set you free,窗口大小为3,因此模型的第一个训练样本来自Hope can set,因skipgram模式,所以将用can作输入 ,Hope和set作输出。
模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1)。
再将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算,再更新网络参数完成一次模型迭代。
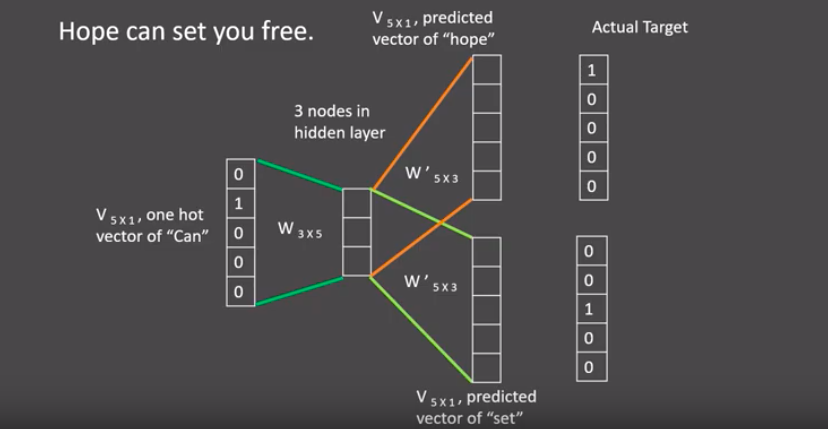
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。
4 使用fasttext训练和使用word2vec
4.1 第一步: 获取训练数据
将研究英语维基百科的部分网页信息,大小约300M。可通过Matt Mahoney的网站下载。
# 下载数据的zip压缩包, 存储在data目录
$ wget -c http://mattmahoney.net/dc/enwik9.zip -P data
# 解压后在data目录下会出现enwik9文件夹
$ unzip data/enwik9.zip -d data
查看原始数据:
$ head -10 data/enwik9# 原始数据将输出很多包含XML/HTML格式的内容, 这些内容并不是我们需要的
<mediawiki xmlns="http://www.mediawiki.org/xml/export-0.3/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.3/ http://www.mediawiki.org/xml/export-0.3.xsd" version="0.3" xml:lang="en"><siteinfo><sitename>Wikipedia</sitename><base>http://en.wikipedia.org/wiki/Main_Page</base><generator>MediaWiki 1.6alpha</generator><case>first-letter</case><namespaces><namespace key="-2">Media</namespace><namespace key="-1">Special</namespace><namespace key="0" />
原始数据处理:
# 使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容
# 注: wikifil.pl文件已为大家提供
$ perl wikifil.pl data/enwik9 > data/fil9
查看预处理后的数据:
# 查看前80个字符
head -c 80 data/fil9# 输出结果为由空格分割的单词anarchism originated as a term of abuse first used against early working class
4.2 第二步: 训练词向量
# 代码运行在python解释器中
# 导入fasttext
>>> import fasttext
# 使用fasttext的train_unsupervised(无监督训练方法)进行词向量的训练
# 它的参数是数据集的持久化文件路径'data/fil9'
>>> model = fasttext.train_unsupervised('data/fil9')# 有效训练词汇量为124M, 共218316个单词
Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 53996 lr: 0.000000 loss: 0.734999 ETA: 0h 0m
查看单词对应的词向量:
# 通过get_word_vector方法来获得指定词汇的词向量
>>> model.get_word_vector("the")array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,...-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],dtype=float32)
4.3 第三步: 模型超参数设定
# 在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如:
# 无监督训练模式: 'skipgram' 或者 'cbow', 默认为'skipgram', 在实践中,skipgram模式在利用子词方面比cbow更好.
# 词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大.
# 数据循环次数epoch: 默认为5, 但当你的数据集足够大, 可能不需要那么多次.
# 学习率lr: 默认为0.05, 根据经验, 建议选择[0.01,1]范围内.
# 使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同.>>> model = fasttext.train_unsupervised('data/fil9', "cbow", dim=300, epoch=1, lr=0.1, thread=8)Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 49523 lr: 0.000000 avg.loss: 1.777205 ETA: 0h 0m 0s
4.4 第四步: 模型效果检验
# 检查单词向量质量的一种简单方法就是查看其邻近单词, 通过我们主观来判断这些邻近单词是否与目标单词相关来粗略评定模型效果好坏.# 查找"运动"的邻近单词, 我们可以发现"体育网", "运动汽车", "运动服"等.
>>> model.get_nearest_neighbors('sports')[(0.8414610624313354, 'sportsnet'), (0.8134572505950928, 'sport'), (0.8100415468215942, 'sportscars'), (0.8021156787872314, 'sportsground'), (0.7889881134033203, 'sportswomen'), (0.7863013744354248, 'sportsplex'), (0.7786710262298584, 'sporty'), (0.7696356177330017, 'sportscar'), (0.7619683146476746, 'sportswear'), (0.7600985765457153, 'sportin')]# 查找"音乐"的邻近单词, 我们可以发现与音乐有关的词汇.
>>> model.get_nearest_neighbors('music')[(0.8908010125160217, 'emusic'), (0.8464668393135071, 'musicmoz'), (0.8444250822067261, 'musics'), (0.8113634586334229, 'allmusic'), (0.8106718063354492, 'musices'), (0.8049437999725342, 'musicam'), (0.8004694581031799, 'musicom'), (0.7952923774719238, 'muchmusic'), (0.7852965593338013, 'musicweb'), (0.7767147421836853, 'musico')]# 查找"小狗"的邻近单词, 我们可以发现与小狗有关的词汇.
>>> model.get_nearest_neighbors('dog')[(0.8456876873970032, 'catdog'), (0.7480780482292175, 'dogcow'), (0.7289096117019653, 'sleddog'), (0.7269964218139648, 'hotdog'), (0.7114801406860352, 'sheepdog'), (0.6947550773620605, 'dogo'), (0.6897546648979187, 'bodog'), (0.6621081829071045, 'maddog'), (0.6605004072189331, 'dogs'), (0.6398137211799622, 'dogpile')]
4.5 第五步: 模型的保存与重加载
# 使用save_model保存模型
>>> model.save_model("fil9.bin")# 使用fasttext.load_model加载模型
>>> model = fasttext.load_model("fil9.bin")
>>> model.get_word_vector("the")array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,...-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],dtype=float32)
5 word embedding(词嵌入)
通过一定方式将词汇映射到指定维度(一般是更高维)的空间:
- 广义包括所有密集词汇向量的表示方法,如word2vec
- 狭义指在神经网络中加入的embedding层,对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵
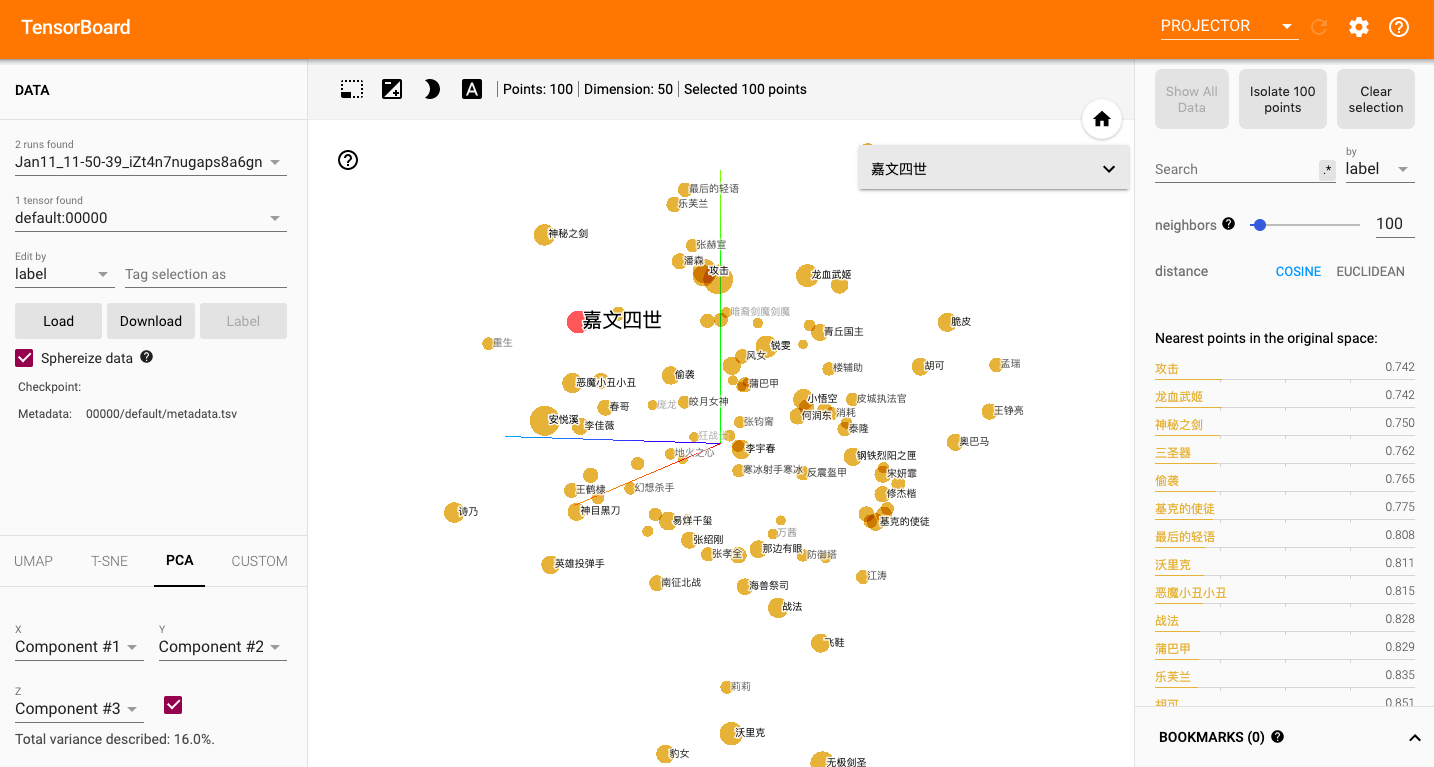
5.1 可视化分析
通过tensorboard可视化嵌入的词向量:
# 导入torch和tensorboard的摘要写入方法
import torch
import json
import fileinput
from torch.utils.tensorboard import SummaryWriter
# 实例化一个摘要写入对象
writer = SummaryWriter()# 随机初始化一个100x50的矩阵, 认为它是我们已经得到的词嵌入矩阵
# 代表100个词汇, 每个词汇被表示成50维的向量
embedded = torch.randn(100, 50)# 导入事先准备好的100个中文词汇文件, 形成meta列表原始词汇
meta = list(map(lambda x: x.strip(), fileinput.FileInput("./vocab100.csv")))
writer.add_embedding(embedded, metadata=meta)
writer.close()
终端启动tensorboard服务:
$ tensorboard --logdir runs --host 0.0.0.0# 通过http://0.0.0.0:6006访问浏览器可视化页面
浏览器展示并可以使用右侧近邻词汇功能检验效果:
本文由博客一文多发平台 OpenWrite 发布!