示例3–V_MFMA_F64_4x4x4F64
考虑V_MFMA_F64_4x4x4F64指令,它计算大小为4×4的四个独立矩阵块的MFMA。执行的操作是
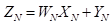
,其中

,
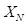
,
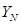
和
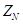
都是大小为4×4元素的矩阵,N=0,1,2,3。
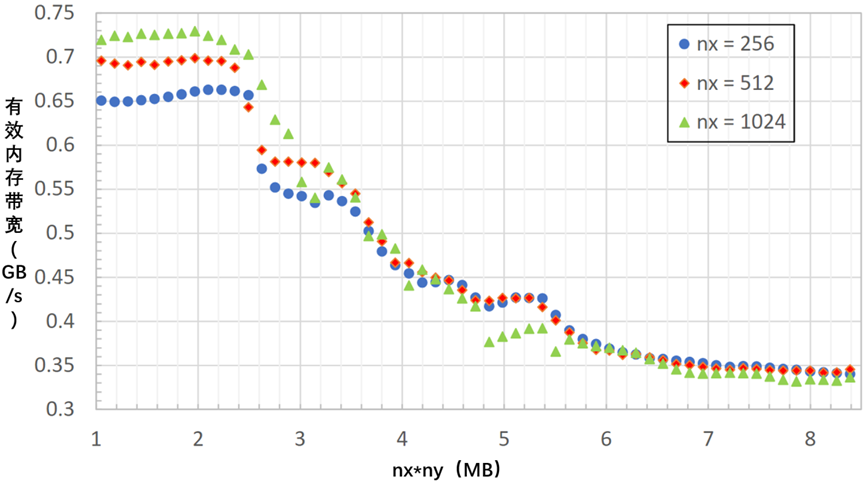
下面的两张图显示了
1)输入参数A和B的四个分量的大小和形状,如图4-18所示。
2)分量映射到波阵面所拥有的寄存器中的通道。此指令的参数包括A、B、C,并返回D,因此理解每个参数和输出包含4个矩阵,如图4-19所示。

图4-18 输入参数A和B的四个分量的大小和形状

图4-19 分量映射到波阵面所拥有的寄存器中的通道
输出D和输入C的布局与输入的B布局相同。
6. 关于rocWMMA的说明
介绍了三个使用编译器内部函数利用AMD Matrix内核的示例。更多的例子可以在这里找到。内置函数将来可能会发生变化,因此最好使用AMD的rocWMMA C++库来加速混合精度MFMA操作。rocWMMA API有助于将矩阵多重累积问题分解为片段,并将其用于并行分布在波前上的分块操作。API是GPU设备代码的头库,允许矩阵核心加速可以直接编译到内核设备代码中。这可以从内核程序集生成中的编译器优化中受益。更多详细信息请参见rocWMMA仓库。
7. AMD矩阵指令计算器工具说明
对于那些对各种MFMA指令在AMD Radeon™和AMD Instinct™加速器上的执行方式感到好奇,并想了解矩阵元素和硬件寄存器之间的映射的人,建议使用AMD矩阵指令计算器工具。这个强大的工具可用于描述给定架构的WMMA指令以及MFMA ISA级指令。欢迎来自社区的问题和反馈。
8. 基于ROCm的GPU感知MPI
MPI是高性能计算中进程间通信的事实标准。MPI进程在彼此广泛通信的同时对其本地数据进行计算。这使得MPI程序能够在具有分布式内存空间的系统上执行,例如集群。MPI支持不同类型的通信,包括点对点和集体通信。点对点通信是发送过程和接收过程都参与通信的基本通信机制。发送方有一个保存消息的缓冲区和一个包含接收方将使用的信息(例如,消息标签、发送方排名号等)的信封。接收器使用信封中的信息来选择指定的消息,并将其存储在接收器缓冲区中。在集体通信中,消息可以在一组进程之间交换,而不仅仅是两个进程。集体通信为进程提供了以方便、便携和优化的方式执行一对多和多对多通信的机会。集体沟通的一些例子包括广播、allgather、alltoall和allreduce。
9. GPU感知MPI
许多MPI应用程序支持在GPU集群上执行。在这些应用程序中,代码的计算密集型部分在GPU(也称为设备)上卸载和加速。当涉及到MPI通信时,MPI进程需要通信驻留在GPU缓冲区中的数据。GPU感知MPI提供了将GPU缓冲区传递给MPI调用的机会。这消除了程序员通过主机内存暂存GPU缓冲区的负担,使他们能够开发出更可读、更简洁的应用程序。此外,它可以通过利用ROCm RDMA(远程直接内存访问)等加速技术使应用程序更有效地运行。ROCm RDMA使Mellanox Infiniband HCA(主机通道适配器)等第三方设备能够在没有主机干预的情况下,与GPU内存建立直接的对等数据路径。大多数知名的MPI实现,包括OpenMPI、MVAPICH2和Cray MPICH,都支持GPU感知通信。
以下代码显示了一个简单的GPU感知点对点通信示例:
#include <stdio.h>
#include <hip/hip_runtime.h>
#include <mpi.h>
int main(int argc, char **argv) {
int i,rank,size,bufsize;
int *h_buf;
int *d_buf;
MPI_Status status;
bufsize=100;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
//分配缓存
h_buf=(int*) malloc(sizeof(int)*bufsize);
hipMalloc(&d_buf, bufsize*sizeof(int));
//初始化缓存
if(rank==0) {
for(i=0;i<bufsize;i++)
h_buf[i]=i;
}
if(rank==1) {
for(i=0;i<bufsize;i++)
h_buf[i]=-1;
}
hipMemcpy(d_buf, h_buf, bufsize*sizeof(int), hipMemcpyHostToDevice);
//通信
if(rank==0)
MPI_Send(d_buf, bufsize, MPI_INT, 1, 123, MPI_COMM_WORLD);
if(rank==1)
MPI_Recv(d_buf, bufsize, MPI_INT, 0, 123, MPI_COMM_WORLD, &status);
//验证结果
if(rank==1) {
hipMemcpy(h_buf, d_buf, bufsize*sizeof(int), hipMemcpyDeviceToHost);
for(i=0;i<bufsize;i++) {
if(h_buf[i] != i)
printf("错误:缓冲区[%d]=%d,但应为%d\n", i, h_buf[i], i);
}
fflush(stdout);
}
//释放缓存
free(h_buf);
hipFree(d_buf);
MPI_Finalize();
}
从代码中可以看出,将GPU缓冲区(d_buf)传递给MPI_Send和MPI_Recv调用。此缓冲区是使用hipMalloc在GPU上分配的。
要编译和运行此代码,需要ROCm以及系统上可用的GPU感知MPI实现。可以在AMD ROCm™安装中找到ROCm安装说明。档稍后将讨论使用不同MPI实现构建和运行上述代码(gpu-aware.cpp)的说明。
10. 与OpenMPI进行GPU感知通信
大多数知名的MPI实现都支持GPU感知通信。将提供构建支持ROCm的GPU感知OpenMPI的说明。
要构建支持ROCm的GPU感知OpenMPI,首先需要安装统一通信X(UCX)。UCX是一个用于高带宽和低延迟网络的通信框架。使用以下命令构建UCX(版本1.14):
git clone https://github.com/openucx/ucx.git
cd ucx
git checkout v1.14.x
./autogen.sh
./configure --prefix=$HOME/.local --with-rocm=/opt/rocm --without-knem --without-cuda --enable-gtest --enable-examples
make -j
make install
成功安装后,UCX将在$HOME/.local目录中可用。现在,可以使用以下命令安装支持ROCm的GPU Aware OpenMPI:
git clone --recursive -b v5.0.x git@github.com:open-mpi/ompi.git
cd ompi/
./autogen.pl
./configure --prefix=$HOME/.local --with-ucx=$HOME/.local
make -j
make install
在OpenMPI 5.0之后,还可以在configure命令中添加--With-rocm=/opt/rocm,以利用Open MPI中的一些rocm功能,例如派生数据类型、MPI I/O等。成功安装后,带有rocm支持的OpenMPI将在$HOME/.local中提供。现在,可以按如下方式设置PATH和LD_LIBRARY_PATH:
export PATH=$HOME/.local/bin:$PATH
export LD_LIBRARY_PATH=$HOME/.local/lib:$LD_LIBRARY_PATH
要使用OpenMPI编译GPU感知的MPI程序,如GPU-ware.cpp,请设置OMPI_CC环境变量,将mpicc封装编译器更改为使用hipcc。然后,可以分别使用mpicc和mpirun编译和运行代码:
export OMPI_CC=hipcc
mpicc -o./gpu-aware./gpu-aware.cpp
mpirun -n 2./gpu-aware
11. 与Cray MPICH进行GPU感知通信
将讨论如何使用Cray MPICH构建和运行GPU感知MPI程序。首先,确保系统上加载了ROCm、Cray MPICH和craype-accel-amd-gfx90a/craype-accel-amd-gfx908模块。编译代码有两种选择:
使用Cray编译器封装器编译代码并链接ROCm:
cc -o./gpu-aware./gpu-aware.cpp -I/opt/rocm/include/ -L/opt/rocm/lib -lamdhip64 -lhsa-runtime64
用hipcc编译代码并链接Cray MPICH:
hipcc-o./gpu-aware./gpu-aware.cpp -I/opt/cray/pe/mpich/8.1.18/ofi/cray/10.0/include/ -L/opt/cray/pe/mpich/8.1.18/ofi/cray/10.0/lib -lmpi
编译成功后,可以使用以下命令运行代码:
export MPICH_GPU_SUPPORT_ENABLED=1
srun -n 2./gpu-aware
注意,MPICH_GPU_SUPPORT_ENABLED设置为1以启用GPU感知通信。
12. OSU微基准测试的性能测量
OSU微基准测试(OMB)提供了一系列MPI基准测试,用于衡量各种MPI操作的性能,包括点对点、集体、基于主机和基于设备的通信。将讨论如何使用OSU微基准测试来测量设备到设备的通信带宽。使用前面讨论的OpenMPI安装进行的实验。
可以使用以下命令构建支持ROCm的OSU微基准测试:
tar -xvf osu-micro-benchmarks-7.0.1.tar.gz
cd osu-micro-benchmarks-7.0.1
./configure --prefix=$HOME/.local/ CC=$HOME/.local/bin/mpicc CXX=$HOME/.local/bin/mpicxx --enable-rocm --with-rocm=/opt/rocm
make -j
make install
成功安装后,OMB将在$HOME/.local/上提供。可以使用以下命令运行带宽测试:
mpirun -n 2 $HOME/.local/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw
在带宽测试中,发送方进程向接收方发送固定数量的背靠背消息。在接收到所有这些消息后,接收方进程会发送一个回复。此过程重复几次迭代。带宽是根据经过的时间和传输的字节数计算的。上述命令末尾的D D指定希望在设备上分配发送和接收缓冲区。
如果使用上述命令没有获得预期的带宽,则OpenMPI默认情况下可能没有使用UCX。要强制OpenMPI使用UCX,可以将以下参数添加到mpirun命令中:
mpirun --mca pml ucx --mca pml_ucx_tls ib,sm,tcp,self,cuda,rocm -np 2 $HOME/.local/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw D D
还可以使用以下命令运行集体通信测试:
mpirun -n 4 $HOME/.local/libexec/osu-micro-benchmarks/mpi/collective/osu_allreduce -d rocm
上面的命令使用四个进程运行MPI_Allreduce延迟测试。在这个测试中,基准测试测量了MPI_Allreduce集合操作在四个进程中的平均延迟,针对不同的消息长度,经过大量迭代-d rocm指定进程应在GPU设备上分配通信缓冲区。