引言
自然语言处理(Natural Language Processing, NLP)是人工智能领域中最具活力和潜力的分支之一。从智能客服到机器翻译,再到语音识别,NLP技术正以其强大的功能改变着我们的生活方式和工作模式。
Catalyst的推出极大降低了NLP技术的应用门槛。它支持文本分类、实体识别等多种功能,并配备了详尽的API文档和预训练模型,让开发者能够快速上手并构建功能强大的应用。无论是打造智能对话系统、自动化文本分析工具,还是实时监测平台,Catalyst都能提供可靠的支持。
本文将通过一个具体的实践任务——使用Catalyst进行操作,深入展示如何在.NET环境中应用NLP技术。这个实践任务贴近实际业务需求,不仅能帮助读者掌握Catalyst的核心用法,还能加深对NLP基本原理的理解。
Catalyst简介
在深入实践之前,我们先来了解Catalyst的本质及其在NLP开发中的价值。
什么是Catalyst?
Catalyst是一个开源的.NET库,专为自然语言处理任务设计,旨在为.NET开发者提供一个简单而强大的工具集。它支持多种NLP功能,如文本分类、命名实体识别(NER)和词性标注,并通过直观的API和预训练模型,帮助开发者快速构建和部署智能应用。
Catalyst融合了先进的机器学习和深度学习技术,它与.NET生态系统无缝集成,开发者可以使用C#或F#直接调用其功能,无需转向Python或其他语言环境。
此外,Catalyst还支持与主流NLP框架(如Transformers、spaCy)的集成,使开发者能够轻松利用最新的技术成果。无论是处理简单的文本分类,还是构建复杂的对话系统,Catalyst都能提供灵活而高效的解决方案。
Catalyst的优势
相比其他NLP工具,Catalyst具有以下独特优势:
无缝集成:通过NuGet包分发,开发者可在Visual Studio等IDE中轻松安装使用。 功能全面:支持文本分类、实体识别等多种任务,覆盖广泛的应用场景。 预训练支持:内置多种预训练模型,开箱即用,同时支持模型微调。 性能优异:针对.NET环境优化,确保高效的数据处理和模型推理。 社区活跃:拥有开放的社区支持,开发者可通过GitHub等问题平台获取帮助。
这些特性使Catalyst成为.NET开发者探索NLP的理想选择。无论你是初学者还是资深开发者,都能借助Catalyst快速实现创意,开发出智能化的应用程序。
安装和配置Catalyst
在使用Catalyst之前,我们需要完成其安装和基本配置。以下是详细步骤,确保你的开发环境顺利就绪。
安装Catalyst
Catalyst通过NuGet包管理系统分发,安装过程简单明了:
打开Visual Studio,创建一个新的.NET项目(如控制台应用程序)。 在解决方案资源管理器中,右键项目,选择“管理NuGet包”。 在NuGet包管理器中搜索“Catalyst”,选择最新版本的“Catalyst”核心包并安装。 根据需求,可选安装附加包,如“Catalyst.Models.Chinese”以加载中文预训练模型。
安装完成后,项目将自动引用Catalyst的程序集,你即可开始编写NLP代码。
配置开发环境
Catalyst的配置相对简单,通常无需复杂调整。为确保最佳体验,建议以下设置:
目标框架:项目需使用.NET Core 3.1或更高版本,以保证兼容性。 GPU加速(可选):若需使用GPU提升性能,需安装CUDA工具包并配置环境变量,具体参考官方文档。 模型下载:部分功能依赖预训练模型,Catalyst支持自动下载,也可手动指定路径。
注意事项
版本匹配:确保Catalyst版本与项目框架一致,避免兼容性问题。 网络环境:首次使用可能需要下载模型,需确保网络畅通。 开源许可:Catalyst遵循MIT许可证,可自由使用和修改。
完成以上步骤,你的开发环境已准备就绪,可以进入NLP开发的实战环节。
文本处理基础
在进一步使用之前,我们需要掌握文本处理的基本技能,包括文本加载、分词、词性标注和清洗。这些操作是所有NLP任务的基础。
文本加载与分词
Catalyst提供了便捷的工具来加载和分词文本。以下是一个中文的简单示例,注意安装 NuGet 包Catalyst.Models.Chinese:
using Catalyst;
using Mosaik.Core;
string text = "你好, 朋友";
Catalyst.Models.Chinese.Register();
// 创建中文NLP管道
Pipeline? nlp = Pipeline.For(Language.Chinese);
// 处理文本
IDocument? doc = nlp.ProcessSingle(new Document(text, Language.Chinese));
// 输出分词结果
foreach (IToken? token in doc.ToTokenList())
{
Console.WriteLine(token.Value);
}
Console.WriteLine(doc.ToJson());
输出示例:
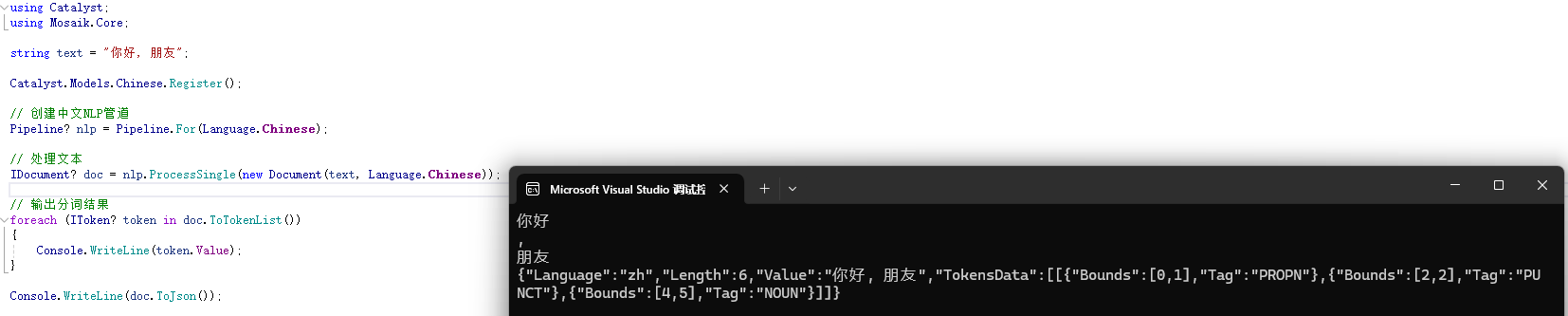
代码解析:
Pipeline.For创建了一个针对英文的NLP处理管道。Document封装了输入文本及其语言信息。ProcessSingle对文本进行分词,Tokens属性返回分词结果。
词性标注
词性标注是NLP的核心任务,用于识别每个词的语法类别。Catalyst内置支持:
// 输出词性标注
foreach (var token in doc.ToTokenList)
{
Console.WriteLine($"{token.Value}: {token.POS}");
}
输出示例:

这里,token.POS返回词性标签,如名词(NOUN)、动词(PUNCT)等。
文本数据表示
Catalyst使用Document类表示文本数据,包含原始文本、分词结果和词性信息等。例如:
Console.WriteLine($"语言: {doc.Language}");
Console.WriteLine($"分词数: {doc.TokensCount}");
输出示例:
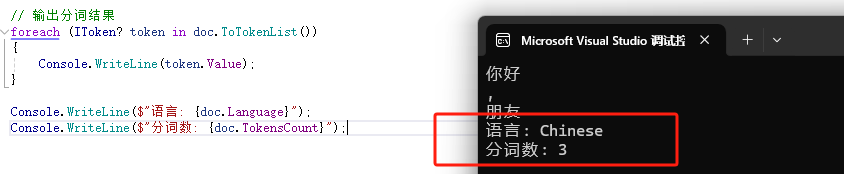
理解Document的结构有助于后续的高级任务。
实体识别实践
掌握文本处理后,我们将通过实体识别任务展示Catalyst的实战能力。实体识别分析旨在判断文本的实体,在信息提取、机器翻译、问答系统中应用广泛。
使用预训练模型
Catalyst提供预训练实体识别分析模型主要有三类:
Spotter:基于词典的模型 PatternSpotter:基于正则的模型 AveragePerceptronEntityRecognizer:感知机模型
由于我尝试了多次的中文文本,但都没有取得比较好的效果,所以我改用了英文文本。
Spotter
Spotter 是 Catalyst(一个 C# 自然语言处理库)中提供的一个实体识别工具,其主要作用是进行 基于词典的实体识别(Dictionary-based Entity Recognition)。它通过一个预定义的实体词典,快速识别和标注文本中的特定实体,适用于需要高效、定制化实体识别的场景。
主要功能
Spotter 的核心功能是通过匹配用户提供的词典来识别文本中的实体,具体包括:
词典匹配:将文本中的词或短语与预定义的实体列表进行精确匹配。 实体标注:将匹配到的文本片段标注为用户指定的实体类型,例如“编程语言”、“公司名称”等。 快速处理:基于词典的直接查找使其速度快,适合实时或轻量级应用。
工作原理:
构建词典:用户需要为 Spotter提供一个包含目标实体的词典,词典条目可以是单个词(如“C#”)或短语(如“New York”)。文本匹配:在处理输入文本时, Spotter将文本分词(tokens)后,与词典中的实体进行逐一比对。标注实体:当发现匹配时, Spotter会为该文本片段添加实体标签,例如标记“C#”为“ProgrammingLanguage”。
此外,Spotter 支持一些灵活性设置,例如通过 IgnoreCase 属性忽略大小写,从而提高匹配的适应性。
使用场景:
专有名词:如人名、地点、组织名称(例如“Microsoft”)。 技术术语:如编程语言(“Python”)、科学名词等。 自定义实体:用户可以根据需求定义特定领域的实体列表,例如产品名称或品牌。 快速原型开发:在需要快速实现实体识别功能的场景中, Spotter是一个简单高效的选择。
使用方式
Spotter spotter = new Spotter(Language.Any, 0, "programming", "ProgrammingLanguage")
{
Data =
{
IgnoreCase = true
}
};
spotter.AddEntry("C#");
spotter.AddEntry("Python");
spotter.AddEntry("Python 3");// 条目可以有多个词,会自动在空格处进行标记化
spotter.AddEntry("C++");
spotter.AddEntry("Rust");
spotter.AddEntry("Java");
Pipeline? nlp = Pipeline.TokenizerFor(Language.English);
nlp.Add(spotter);
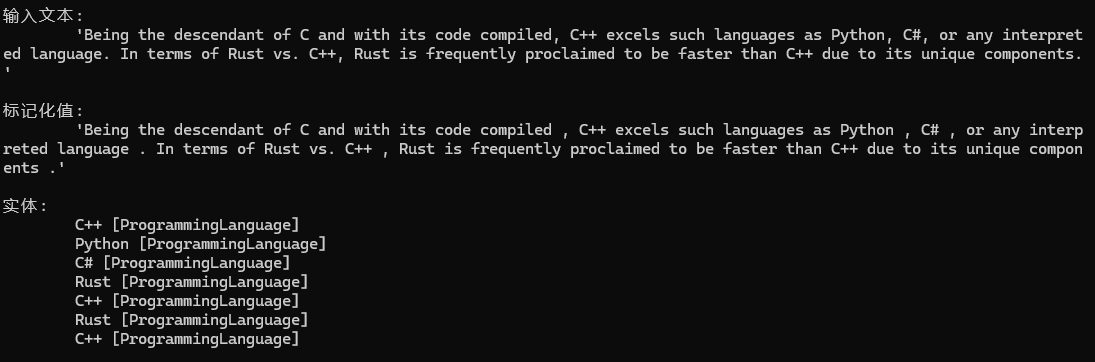
Document docAboutProgramming = new Document(Data.SampleProgramming, Language.English);
nlp.ProcessSingle(docAboutProgramming);
PrintDocumentEntities(docAboutProgramming);
输出示例
PatternSpotter
该类的主要作用是进行基于模式的实体识别(Pattern-based Entity Recognition),允许用户通过定义自定义的语言模式来识别和标注文本中的特定实体或结构。
主要功能
PatternSpotter 提供了一种灵活的方式,用于在文本中识别符合特定语言规则的片段,例如:
语法结构:如 "is a" 后面的名词短语。 词性组合:如动词后跟多个名词或专有名词。 自定义实体:根据用户定义的规则识别特定类型的实体。
这种方法类似于使用正则表达式进行文本匹配,但 PatternSpotter 是在标记化(tokenized)的文本上操作,结合了词性(POS)、实体类型等语言特征,使得模式匹配更加智能和精确。
工作原理
定义模式:用户通过 PatternSpotter 类定义一个或多个模式,这些模式可以基于词性、词形、实体类型等特征。 文本:在处理文本时,PatternSpotter 会扫描标记化的文本,寻找与定义的模式相匹配的片段。 标注实体:一旦找到匹配的片段,PatternSpotter 会将这些片段标注为用户指定的实体类型。
使用场景
义实体识别:识别特定领域中的专有术语,如法律文件中的法律条款或医疗文本中的疾病名称。 关系抽取:识别文本中的特定关系模式,如 "X 是 Y" 结构中的 X 和 Y。 文本结构分析:识别文本中的特定句法结构,如引用、列表等。
使用方式
PatternSpotter isApattern = new PatternSpotter(Language.English, 0, tag: "is-a-pattern", captureTag: "IsA");
isApattern.NewPattern(
"Is+Noun",
mp => mp.Add(
new PatternUnit(P.Single().WithToken("is").WithPOS(PartOfSpeech.VERB)),
new PatternUnit(P.Multiple().WithPOS(PartOfSpeech.NOUN, PartOfSpeech.PROPN, PartOfSpeech.AUX, PartOfSpeech.DET, PartOfSpeech.ADJ))
));
nlp.Add(isApattern);
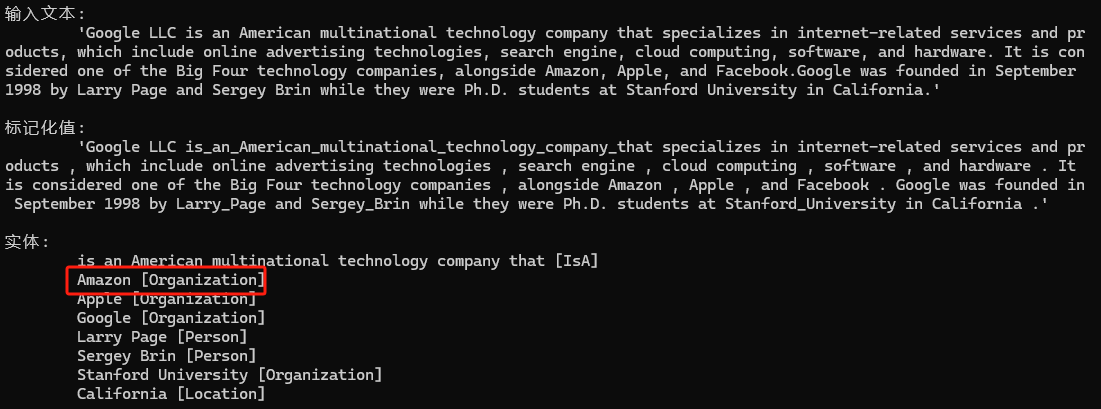
输出示例1
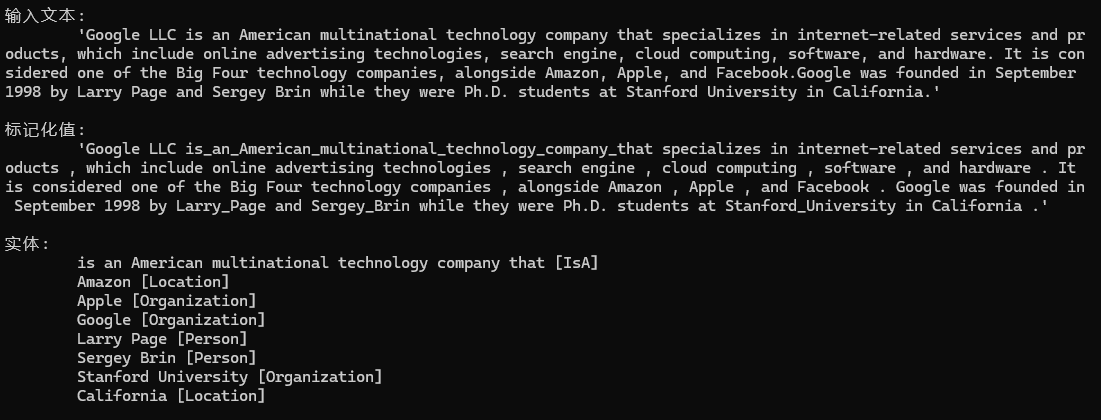
在这个示例里面Amazon既是地点名称,又是企业组织的名称,所以可以考虑使用纠错类Neuralyzer,帮助我们得到想要的答案。
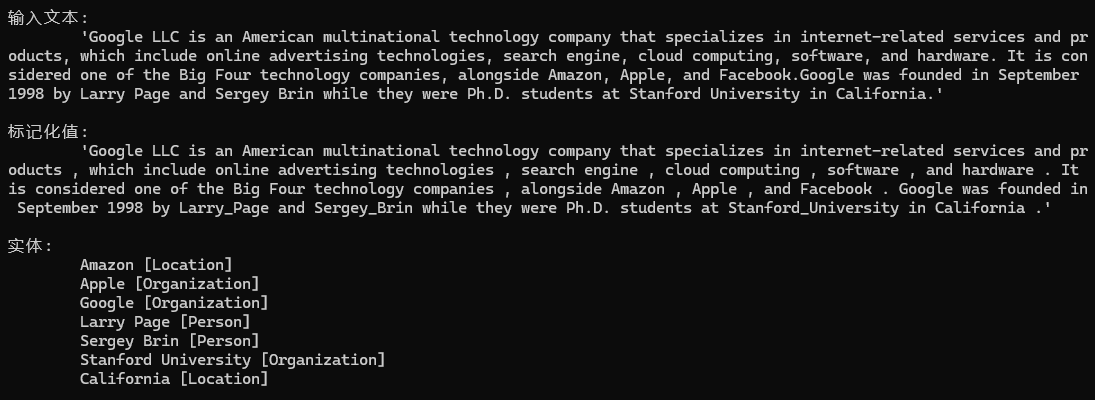
Neuralyzer neuralizer = new Neuralyzer(Language.English, 0, "WikiNER-sample-fixes");
neuralizer.TeachForgetPattern("Location", "Amazon", mp => mp.Add(new PatternUnit(P.Single().WithToken("Amazon").WithEntityType("Location"))));
neuralizer.TeachAddPattern("Organization", "Amazon", mp => mp.Add(new PatternUnit(P.Single().WithToken("Amazon"))));
// 将 Neuralyzer 添加到管道中
nlp.UseNeuralyzer(neuralizer);
输出示例2
现在你可以看到Amazon被正确识别为实体类型Organization.
AveragePerceptronEntityRecognizer
利用平均感知机(Average Perceptron)算法来训练和执行实体识别任务。
AveragePerceptronEntityRecognizer 利用平均感知机(Average Perceptron)算法来训练和执行实体识别任务。它的核心功能包括:
主要功能
训练模型:通过带标签的训练数据(如 WikiNER 数据集),学习如何识别不同类型的实体。 实体识别:对新的文本进行处理,识别并标注出其中的命名实体。 多语言支持:支持多种语言的实体识别,适应不同语言环境下的需求。
2.##### 工作原理
特征提取:将输入文本分解为标记(tokens),并提取每个标记的特征,例如词形、词性、上下文信息等。 分类:使用平均感知机算法对每个标记进行分类,判断其是否属于某个实体类别。 实体标注:根据分类结果,将连续的标记组合成完整的实体,并赋予相应的标签(如“人名”、“地点”)。
平均感知机算法是感知机的一种改进版本,通过对多次迭代的权重取平均值,提升了模型的稳定性和泛化能力,使其在处理大规模文本数据时表现更为出色。
使用场景
信息抽取:从新闻文章、社交媒体等文本中提取关键信息,如公司名称、事件地点等。 问答系统:识别用户提问中的实体,以便提供更精准的回答。 文本分析:作为预处理步骤,为情感分析、主题建模等任务提供实体信息。
它通过高效的训练和识别能力,帮助开发者从文本中提取结构化的实体信息,适用于多种 NLP 应用场景。
使用方式
本示例使用预训练的 WikiNER 模型,详情请查看 https://github.com/dice-group/FOX/tree/master/input/Wikiner。
为英文创建一个新的管道,并将 WikiNER 模型添加到其中
Pipeline? nlp = await Pipeline.ForAsync(Language.English);
nlp.Add(await AveragePerceptronEntityRecognizer.FromStoreAsync(language: Language.English, version: Version.Latest, tag: "WikiNER"));
输出示例
Catalyst的意义与挑战
Catalyst为.NET开发者带来了NLP的强大能力,但其应用也伴随着深远意义和现实挑战。
意义
用户体验:分析和对话系统提升交互质量。 效率提升:自动化文本任务节省资源。 全球化:多语言支持助力跨国应用。
挑战
模型优化:需根据任务选择合适模型并调优。 性能瓶颈:实时应用中需平衡速度与资源。 隐私保护:处理用户数据需遵守法规。 文化差异:多语言模型需适应多样化语境。
技术伦理
Catalyst不仅是一款工具,更启发我们思考NLP的深层问题:
伦理考量:模型偏见可能导致不公,开发者需确保公平性。 隐私权衡:数据处理需兼顾功能与用户权益。
❝这些议题提醒我们,开发者具备技术与伦理的双重素养。
结语
本文通过Catalyst的基础知识、安装配置、文本处理、实体识别分析实践及意义挑战的全面探讨,为.NET开发者提供了一份深入的NLP指南。Catalyst以其易用性和强大功能,为开发者开启了智能语言处理的大门。希望你能从中获得启发,加深自己对.NET的理解和使用!
参考链接
https://github.com/curiosity-ai/catalyst/blob/master/samples/EntityRecognition/Program.cs