0. 背景
上游厂家生产信令数据,我方消费kafka数据,过滤后插入HBase。
上游生产的信令数据分了4个主题,每个主题有若干分区,这4个主题的数据消费后都插入同一张HBase表。
问题:kafka消息积压达到百亿。
以下以topic1为例,有6个分区。
1. 查看消费滞后情况
kafka-consumer-groups.sh --zookeeper node1:2181 --describe --group group1
| GROUP | TOPIC | PARTITION | CURRENT-OFFSET | LOG-END-OFFSET | LAG | OWNER |
|---|---|---|---|---|---|---|
| group1 | topic1 | p1 | 763268411801 | 765604526970 | 2336115169 | none |
| group1 | topic1 | p2 | 758609405216 | 760945694615 | 2336289399 | none |
| group1 | topic1 | p3 | 792287818058 | 792288073608 | 255550 | none |
| group1 | topic1 | p4 | 760978756871 | 760979013415 | 256544 | none |
| group1 | topic1 | p5 | 726235588657 | 728571879016 | 2336290359 | none |
| group1 | topic1 | p6 | 757874708350 | 760210948121 | 2336239771 | none |
- 观察LOG-END-OFFSET,各分区都在不断增加,说明各分区都在正常地生产。
- 观察CURRENT-OFFSET,除了p3、p4其他分区的CURRENT-OFFSET一直不变,说明已停止消费。
- LAG在100W以内都正常,但是除了p3、p4 其他分区的LAG都很大,达到十亿级,而且还在不断地积压。
2. 分析原因及优化
将源代码反编译后,根据代码画出以下示意图
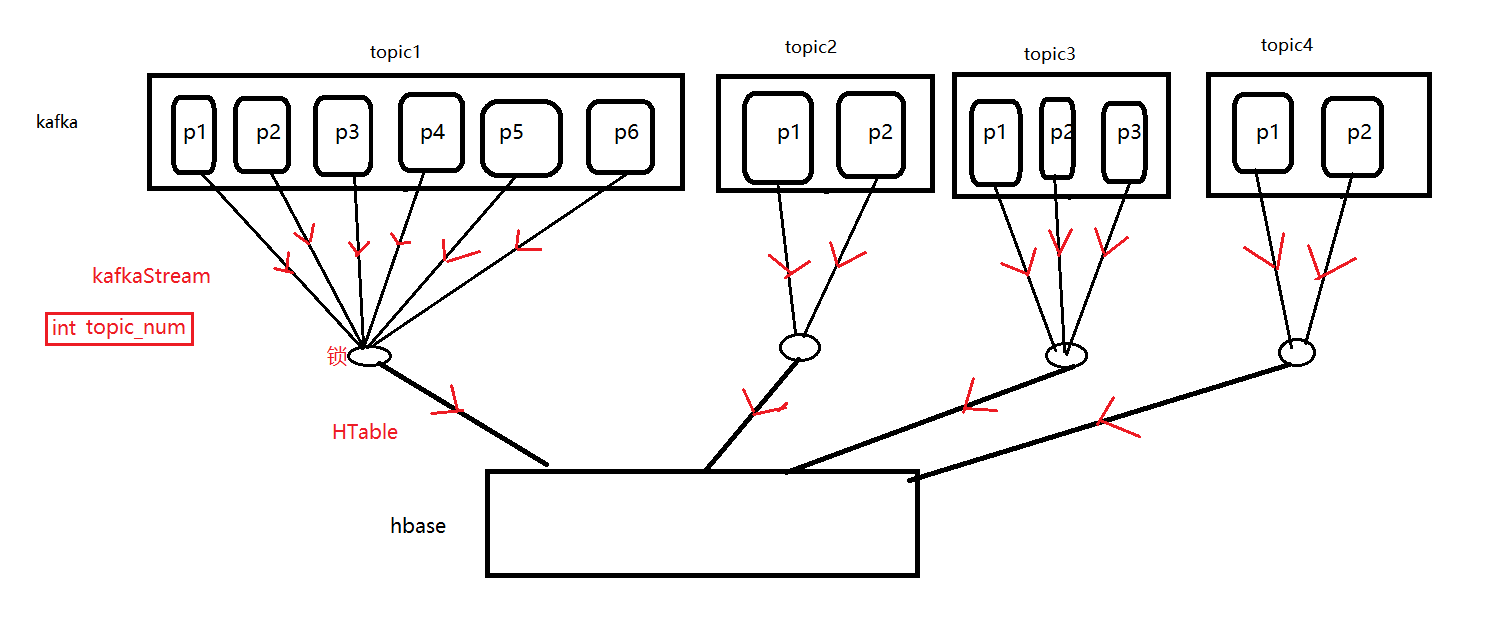
同一主题下各分区的消费流共享同一个HTable,每个HTable会创建一个HConnection
HConnectionManager.getConnection(conf);
2.1 集群的吞吐量统计
- 生产者 主题topic1,共6个分区。每个分区生产消息1W3W/秒,生产消息520W/秒,每5分钟3000W上下,每天约100亿。
- 消费者 每秒5~20W,每5分钟消费约3000W消息,每天约100亿
- HBase 1000多W次put每5分钟,每天约40亿。
HBase吞吐量瓶颈,在6节点,万兆网卡情况下,每条记录put一次。一个HTable连接的put上限在3W次每秒。
2.2 优化
每个分区创建一个consumer,每个consumer创建一个HTable连接
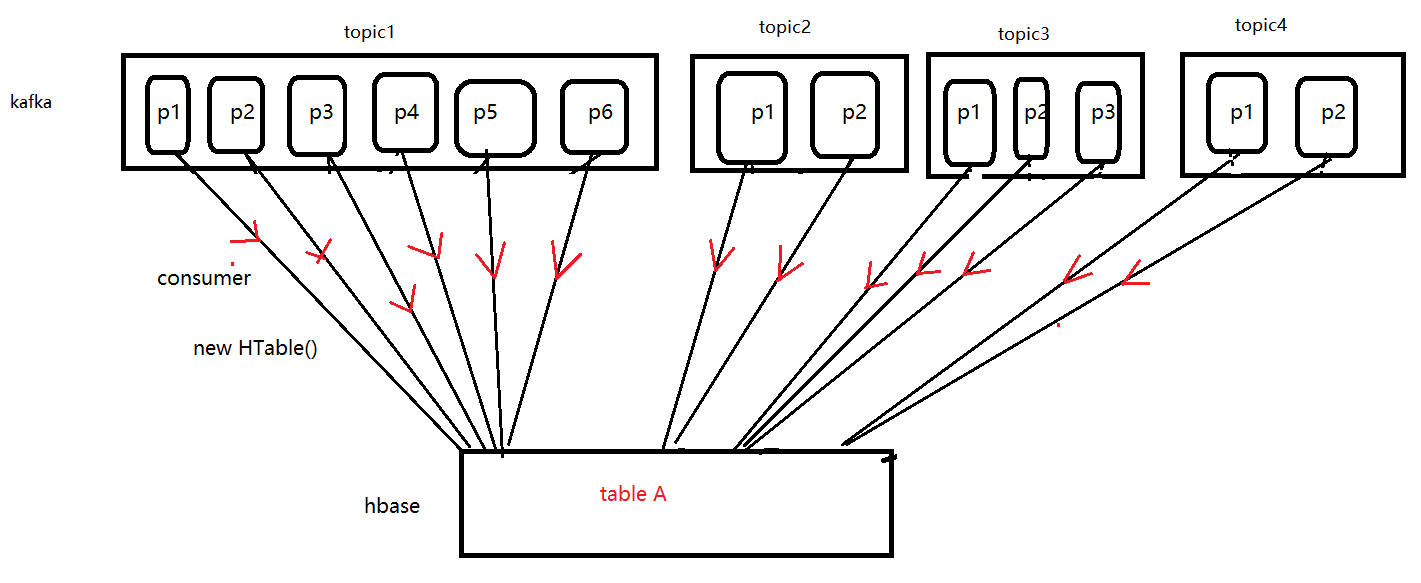
根据图中思路优化代码后,再次查看LAG,无积压
3. KafkaStream相关API
官网API介绍
/*** Create a list of message streams of type T for each topic, using the default decoder.*/public Map<String, List<KafkaStream<byte[], byte[]>>> createMessageStreams(Map<String, Integer> topicCountMap);This API is centered around iterators, implemented by the KafkaStream class. Each KafkaStream represents the stream of messages from one or more partitions on one or more servers. Each stream is used for single threaded processing, so the client can provide the number of desired streams in the create call. Thus a stream may represent the merging of multiple server partitions (to correspond to the number of processing threads), but each partition only goes to one stream.
这个 API 以迭代器为中心,由 KafkaStream 类实现。 每个 KafkaStream 代表来自一台或多台服务器上的一个或多个分区的消息流。 每个流都用于单线程处理,因此客户端可以在创建调用中提供所需流的数量。 因此一个流可能代表多个服务器分区的合并(对应于处理线程的数量),但每个分区只进入一个流。
The createMessageStreams call registers the consumer for the topic, which results in rebalancing the consumer/broker assignment. The API encourages creating many topic streams in a single call in order to minimize this rebalancing. The createMessageStreamsByFilter call (additionally) registers watchers to discover new topics that match its filter. Note that each stream that createMessageStreamsByFilter returns may iterate over messages from multiple topics (i.e., if multiple topics are allowed by the filter).
每次调用createMessageStreams 会为topic注册consumer,多次调用可能会导致rebalance consumer/broker分配。 API 鼓励在一次调用中创建多个主题流,以最大程度地减少这种重新平衡。 (另外)调用 createMessageStreamsByFilter 注册观察者以发现与其过滤器匹配的新主题。 请注意, createMessageStreamsByFilter 返回的每个流都可以迭代来自多个主题的消息(即,如果过滤器允许多个主题)。
kafkaStream如何消费消息?
// 创建 kafka stream流 的迭代器
ConsumerIterator<byte[], byte[]> it = kafkaStream.iterator();while (it.hasNext()) {// 读取消息byte[] message = (byte[])it.next().message();String s = new String(message);
}4. 遗留问题
-
采用put(list)优化, 各分区都消费,仍有滞后。
-
如何更好地监控kafka / hbase?
- kafka-eagle ?
- HBase优化配置,提高吞吐量?
- HBase吞吐量监控? jmx ?
// HBase 官网API
// BalancerRegionLoad.getWriteRequstCount()RegionMetrics.getWriteRequstCount()
- kafka数据存储策略,保留一周?