综述: LLM 量化
1. Intro
低比特量化主要是减少tensor的bit-width,可以有效减少内存以及计算需求;主要可以压缩权重, 激活值, 和梯度,使得可以在受限资源的设备上使用。
2. 低比特LLM的基础
在这一届,我们主要引入从以下三个方面讨论:
- low-bit 数值格式
- 量化粒度
- 动态或者静态量化
2.1 low-bit 数值格式
2.1.1 标准格式
浮点数的一般格式为:
$$X_{FPk} = (-1)s2(1.mantissa)=(-1)s2(1+\frac{d_1}{2}+\frac{d_2}{2^2}+...)$$
这里的s是符号位, p是指数的整型, bias需要应用到这个指数上;最后s p 和m的bits加起来应该等于k。
我们可以使用$EeMm$来表示对应的浮点数格式,例如float16可以表示$E5M10$, bfloat16表示为$E8M7$;因此bfloat16可以表示更大的数,但相对的数值分布更稀疏。除此之外,对于fp8也来两种主要的格式$E4M3$和$E5M2$。
NormalFloat(NF): 主要用在weight-only的量化策略
Micro scaling FP: 对tensor的sub-blocks有一个scale系数 $E8M0$ 可以进行更细粒度的量化
integer number: 将浮点数划分为 $2^k$个等间距的离散整型, 格式如下:
$$X_{INT_k} = (-1)s(d_12m+d_22{m-1}+...+d_m20)$$
对于有符号整型,我们使用$m=k-1$ 以及 $s \in {0,1}$;对于无符号,我们使用$m=k$和$s=0$
二元数: 直接抽象出值的符号;即 ${-1,1}$ 和 ${0,1}$
2.1.2 自定义格式
TODO
2.2 量化粒度
Tensor-wise, Token-wise, channel-wise, group-wise(将token以及channel划分成组), element-wise(只应用在训练权重时,在推理前,这个scale将被合并到量化权重上)
token-wise的激活值和channel-wise的权重经常一起使用;因为对应量化scale可以先进行一个计算,减少overhead
2.3 动态和静态量化
这里的两个策略主要指PTQ中的策略,我们可以看出哪些方式是需要反量化的计算,哪些则不需要:

动态量化: 裁剪和存储被量化的值,通常不需要输入数据,但对于weight来说可以搜索出最优的scale系数以及零点偏移$Z_w$。在推理时,激活值将作为输入进入量化模块计算出最优的scaling factor和零点偏移,之后动态地进行量化。scaling和zero point可以基于当前批次的数据实时获取。这种方法会引入额外的计算scale的复杂度。
静态量化: 需要输入数据,可以找到对于weight和activation或者weight-only的最优scale系数
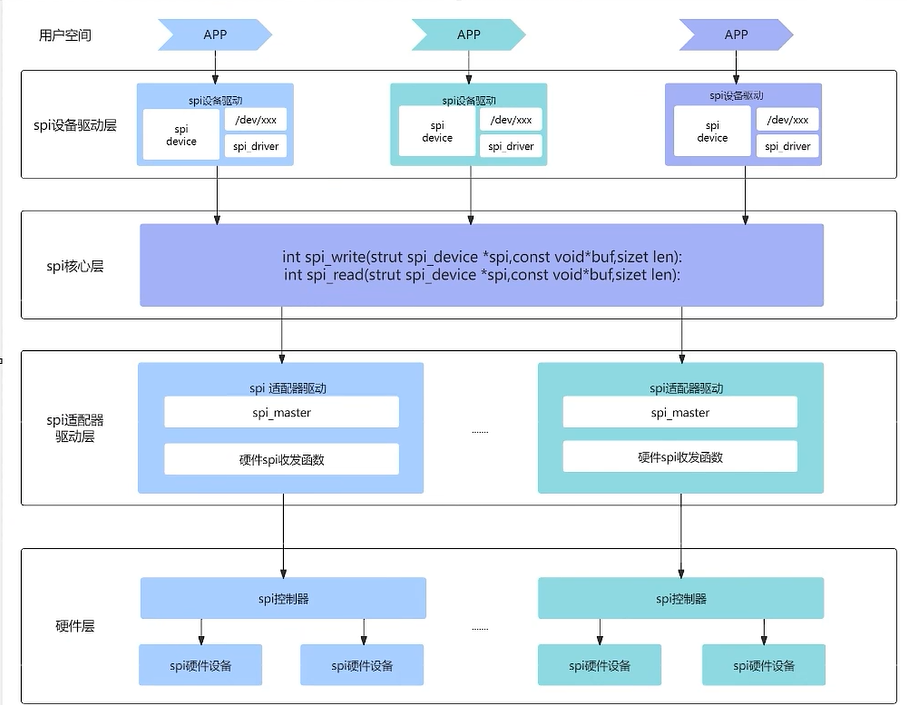
3. 框架与系统支持
3.1 量化推理框架
bitsandbytes, mlc-llm, vLLM, llama.cpp, sglang...
一些主流的量化算法: GPTQ, AWQ, SmoothQuant
bit-width 支持:
- weight-only: 只量化权重,激活值保持fp16。这种量化的权重将会dequantize成fp16,之后执行fp16的mma运算。减少了计算设备与host之间数据传输的延迟;但是dequantize需要额外的时间。
- W & A: 算法量化了权重和激活值,可以直接执行低比特的乘法;所有框架都支持INT8和FP16的矩乘;受限于GPU的计算能力,只有部分硬件支持INT4 FP8的MatMul. 很少有支持不同bitwidth的框架,例如Wint4Aint8,这需要自定义的计算kernel(需要汇编的GEMV指令)。值得注意的是,如果想使用低bit的MatMul,你的硬件必须支持特定的low-bit的计算。
- KV cache: 与weight-only的算法类似,量化的kv cache通常在进行矩乘时,需要先将其dequant为fp16,
3.2 量化的系统支持
我们很容易会提出一个问题:量化是怎样达到加速和内存的减少的?
我们首先可以讨论模型推理时的数据传输过程:
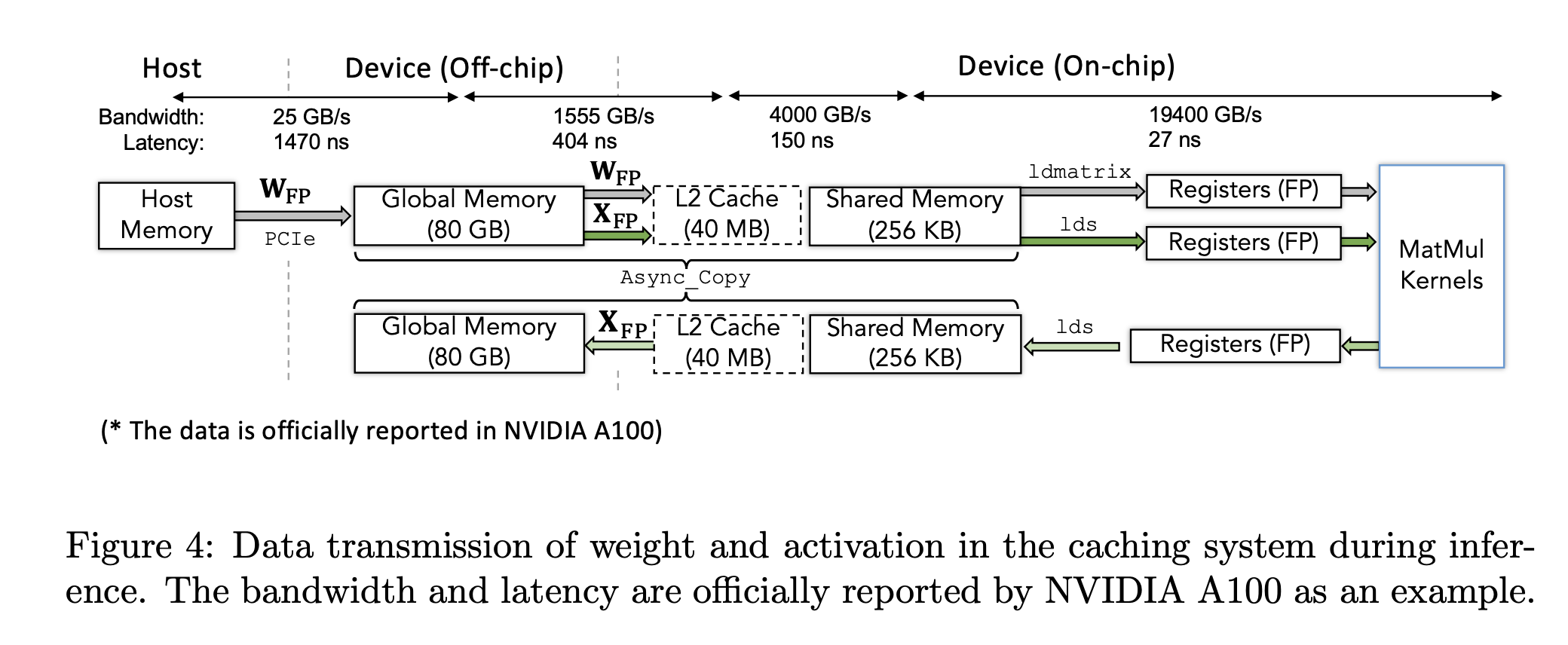
- host mem -> device mem: 对于权重来说,我们首先将每一层layer的权重从host移动到device上;量化可以减少这部分传输延迟,激活值一般都存储在device上,不需要特殊的移动。
- off-chip -> on-chip: 将一块权重和激活值从global memory传输到片上的L2 cache和shared memory
- shared memory -> register: 为了更快的计算,quantize和dequant操作以及matmul总是在registers上计算。
- off-loading(register->shared memory->device memory)
3.2.1 weight-only 量化
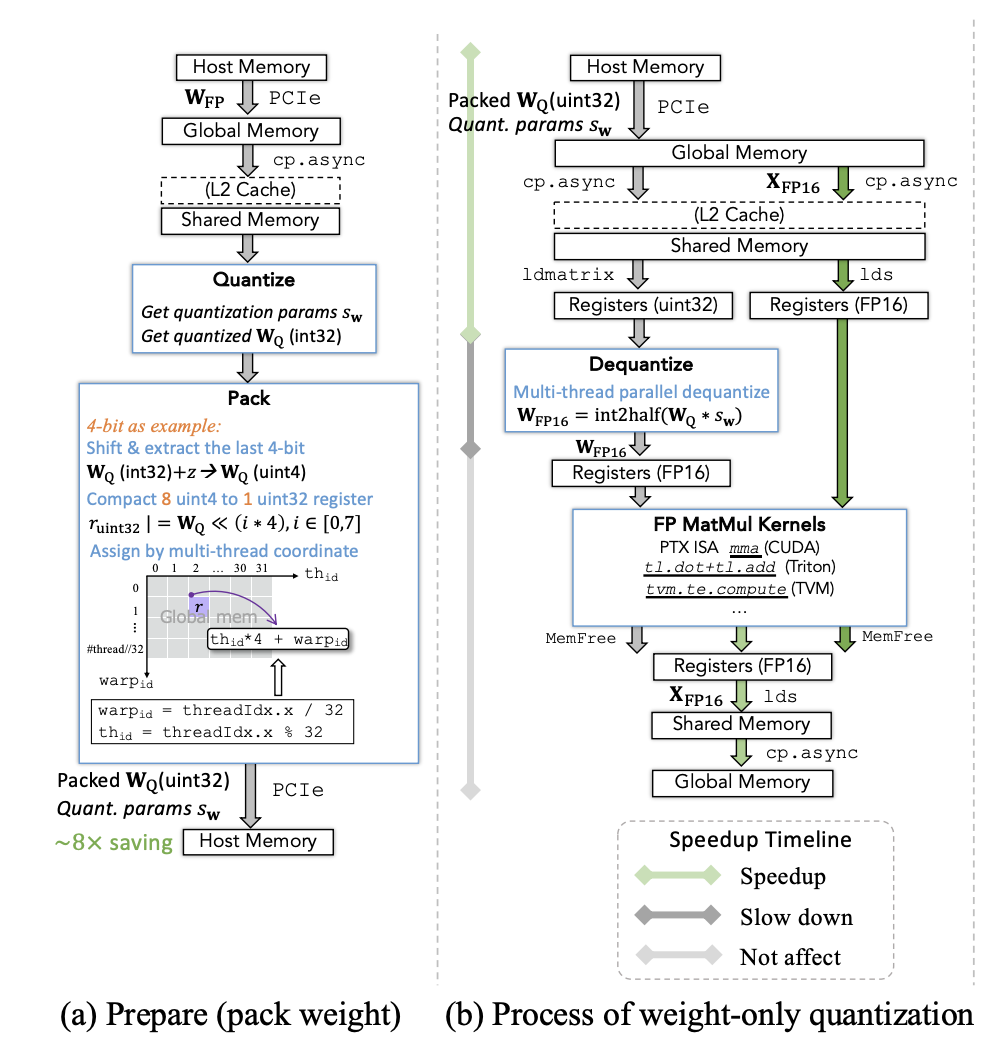
weight-only和W&A量化都牵涉到a过程:
- 将weight量化到更低位宽,得到对应量化参数
- 将这些量化后的权重pack为uint32
- offload以及存进host mem
注意weight-only减少了从host mem到on-chip mem的传输时间,但引入了额外的dequant开销。我们甚至没有必要设计一个线性的从低比特数到真实值的满射;换句话说,我们可以将整数映射为任意的浮点数,通过lookup table的机制。
3.2.2 W & A 量化
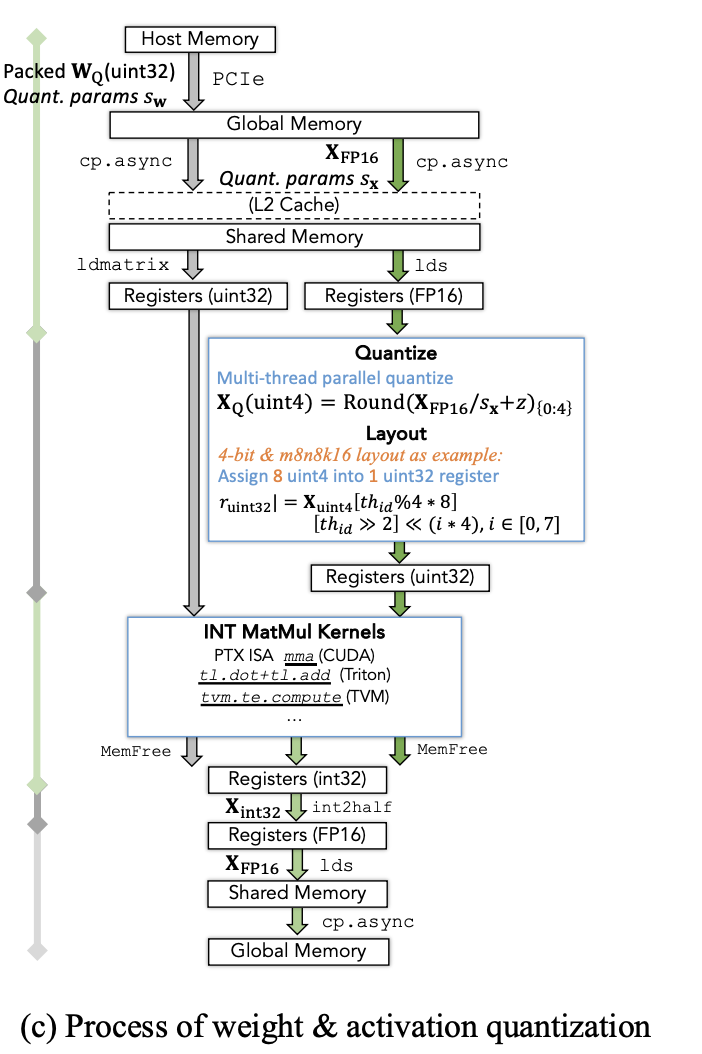
我们需要执行额外的将激活值从fp16量化为更低bit的整型;在计算完成后,将INT32转为FP16。
有两种自定义的设计:
- faster quant & dequant
- faster matmul kernel: gemv相比gemm对于适配不同位宽具有更高的灵活性和效率;通过将一些矩阵和向量的乘法进行组合可以得到最终的结果矩阵。
3.2.3 KV cache 量化
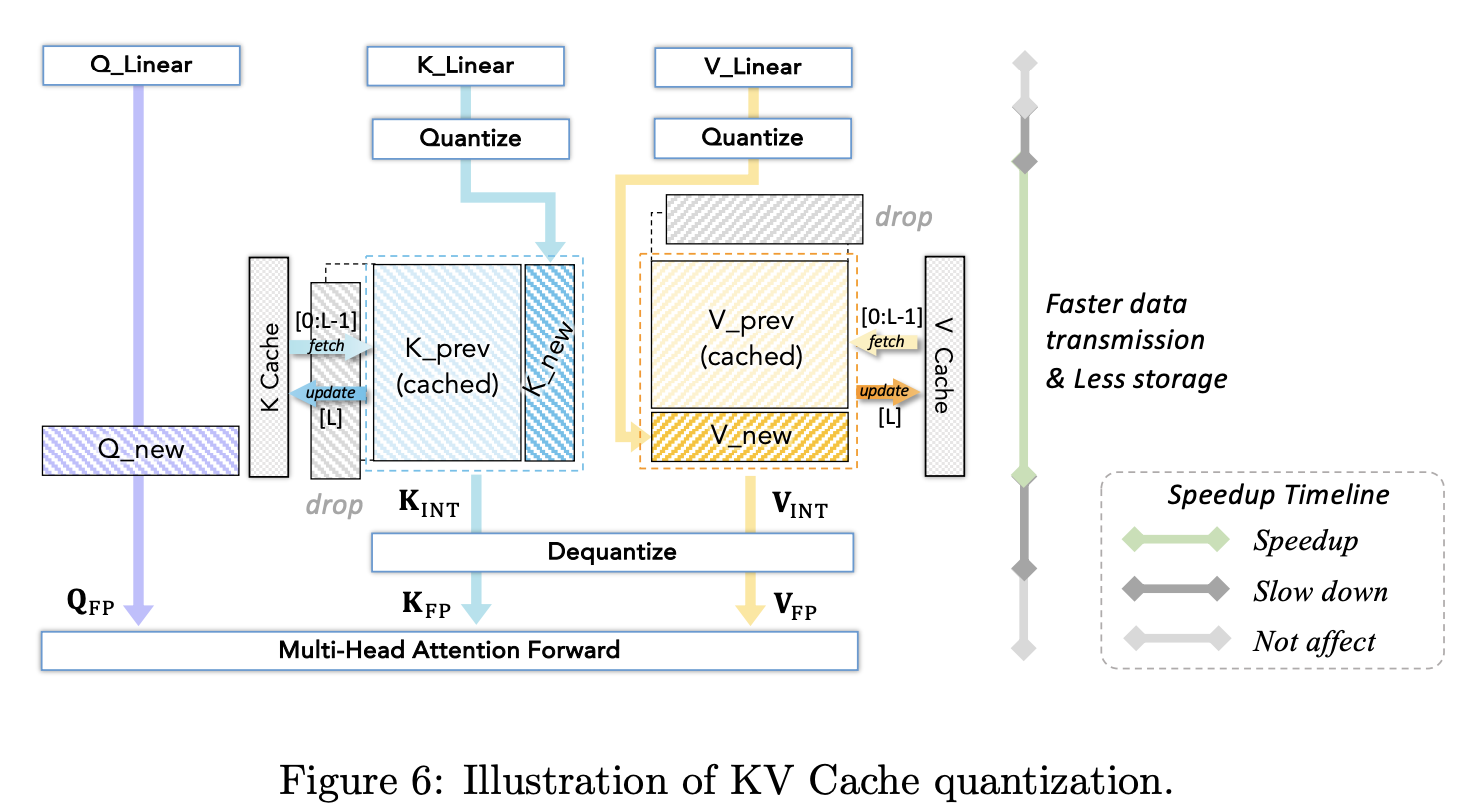
有三种技术:
- quant to lower bitwidth:
- quantizing window: 推迟量化发生的时机
- 跳过Knew的dequant: 先将其与先前dequant的kv进行concat,防止丢失信息
- 优化outliers
3.2.4 quant和dequant
Floating-point quant: 将更高bit的浮点数quant为低bit,实际上是mantissa bit的裁剪。我们可以总结出以下的流程:
- scale。 目标占据更少的bit,表示范围将会大大减小;这个scaling可以通过学习或者裁剪来预先获取
- 检查上溢和下溢。检查source是否overflow了目标的表示范围;如果是,直接返回最大或最小。
- 拷贝和round。如果值没有overflow或underflow,我们可以直接round
float-point dequant: 直接0️⃣填充
Int quant:
$$X_{INT_k}=clamp(round(\frac{X_{FP}}{s})+z, q^{min}, q^{max})$$
其中$s$可以被初始化为$\frac{q{max}-q{min}}{X{max}_{FP}-X_{FP}}$.
对于系统支持,很多框架都应用了marlin quant作为基础过程。
Int dequant: $$X_{FP}=s(X_{INT_x}-z)$$。可以通过某个算法找到最优的s
二元量化
4. LLM training的高效量化策略
4.1 低比特训练
FP16 训练: 通常使用BF16进行模型训练,然而需要特定的硬件支持;对于老硬件,我们使用fp16进行加速,但是有under/overflow的风险。
fp8 traning: 利用transformer engine;需要对每个fp8的tensor都有一个scaling factor,注意需要延迟获取。
4.2 PEFT的量化策略
QLora:
5. LLM 推理的高效量化策略
TODO