由于性能测试需要,需采集某业务系统海量日志(百万以上)来使用。但Elasticsearch的结果分页size单次最大为10000(运维同事为保证ES安全)。为了能够快速采集ELK平台业务日志,可以使用以下2种方式采集:
1)结果分页方式:
通过使用 from 和 size 参数来完成。 from 参数定义了您要提取的第一个结果的偏移量。 size 参数允许您配置要返回的最大匹配数。虽然 from 和 size 可以设置为请求参数,但它们也可以在搜索正文中设置。from 默认值为 0,size 默认为 10。
注意 from + size 不能超过 index.max_result_window 索引设置,默认为 10,000
2)滚动方式(Scroll,类似于游标):
可以用于从单个搜索请求中检索大量结果(甚至是所有结果),与在传统数据库上使用游标的方式大致相同。滚动不是用于实时用户请求,而是用于处理大量数据,例如,以便将一个索引的内容重新索引到具有不同配置的新索引中。
综合考虑,滚动方式对于采集数据更方便实用,且不用关注from的值及不受size 10000的限制。
主流程图:
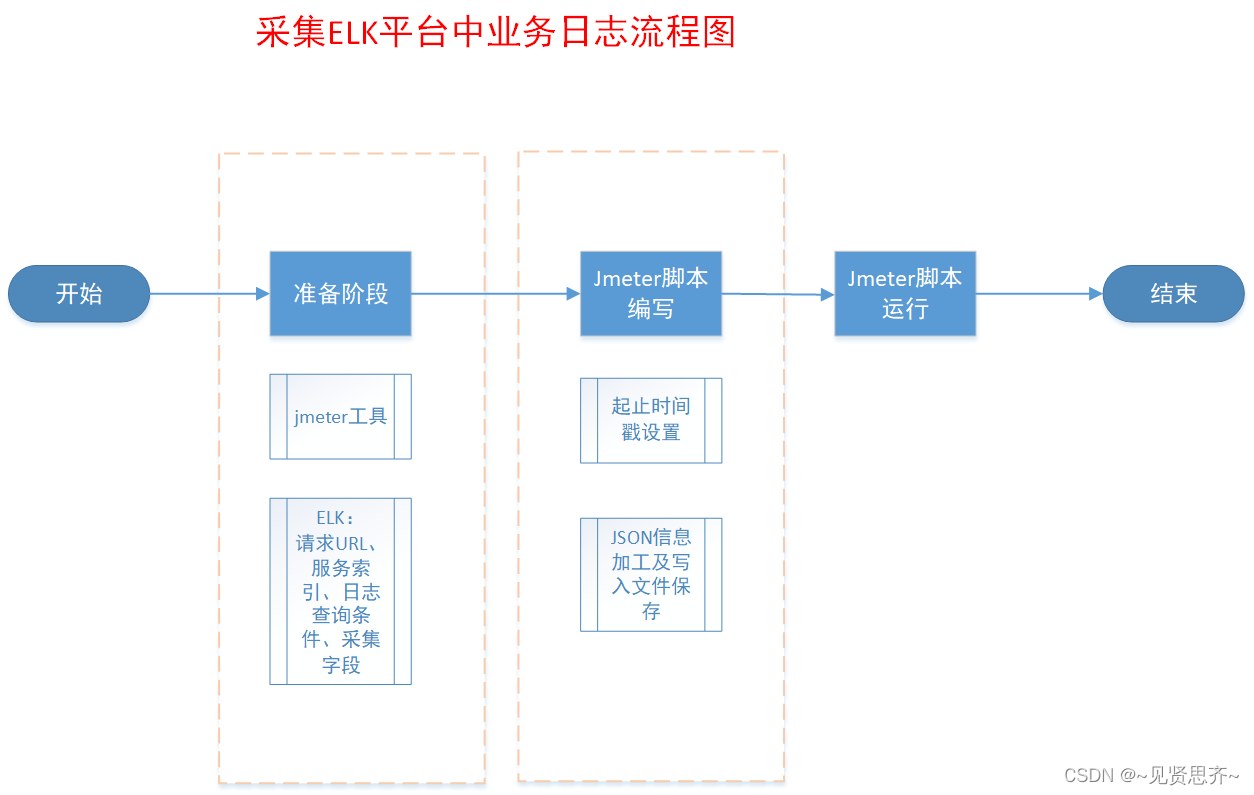
ELK日志平台业务日志:
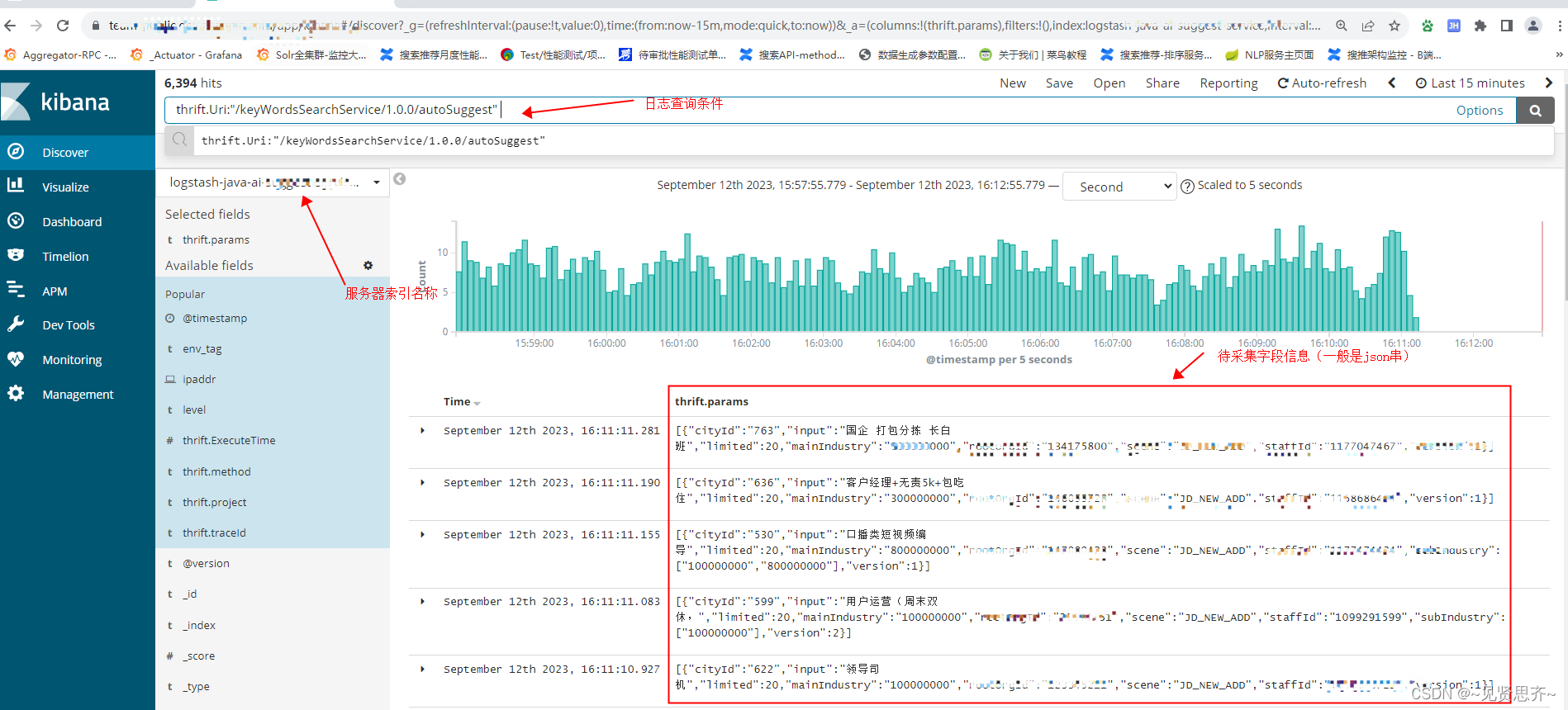
以下为使用 jmeter 工具的详细实例:
Jmeter脚本全貌:
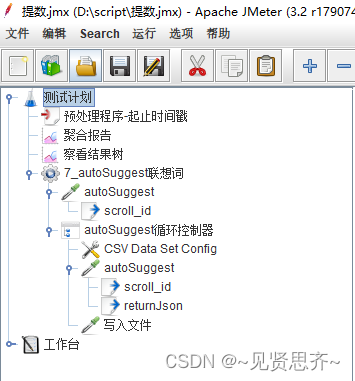
下面开始详细分段说明:
- BeanShell PreProcessor前置处理器。用来获取起止时间戳。如下图:
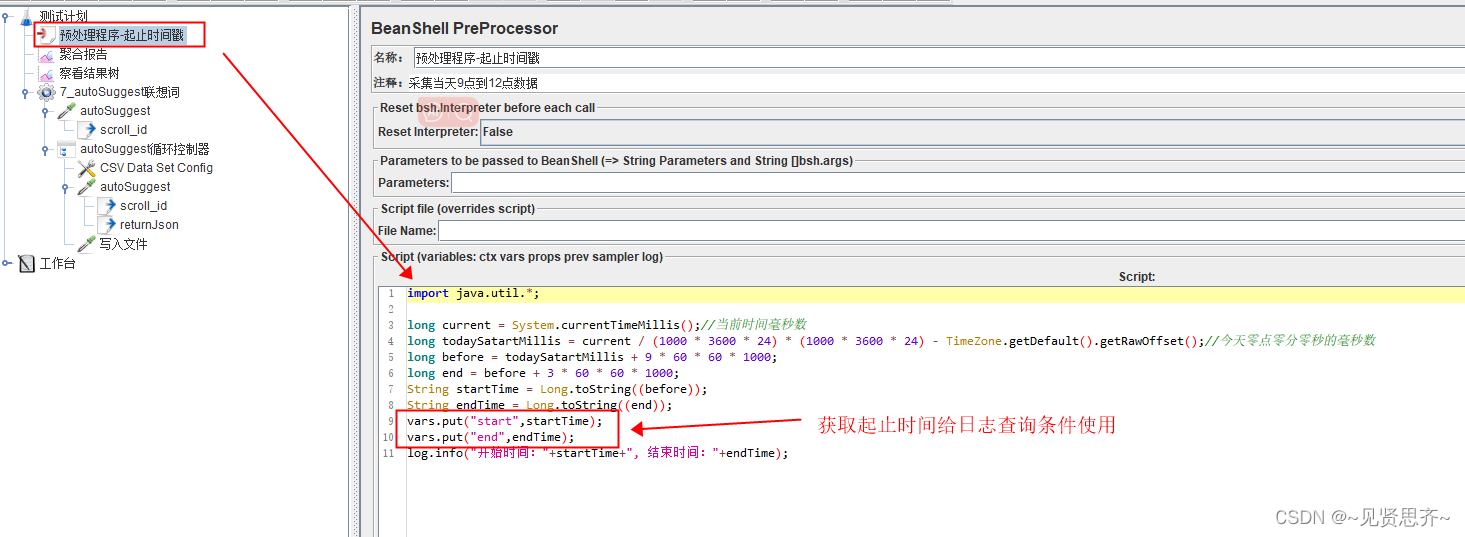
BeanShell 代码
import java.util.*;
long current = System.currentTimeMillis();//当前时间毫秒数
long todaySatartMillis = current / (1000 * 3600 * 24) * (1000 * 3600 * 24) - TimeZone.getDefault().getRawOffset();//今天零点零分零秒的毫秒数
long before = todaySatartMillis + 9 * 60 * 60 * 1000;
long end = before + 3 * 60 * 60 * 1000;
String startTime = Long.toString((before));
String endTime = Long.toString((end));
vars.put("start",startTime);
vars.put("end",endTime);
log.info("开始时间:"+startTime+", 结束时间:"+endTime);
2. 线程组
1)线程组下 HTTP请求插件中参数设置(非常重要)
如下图所示
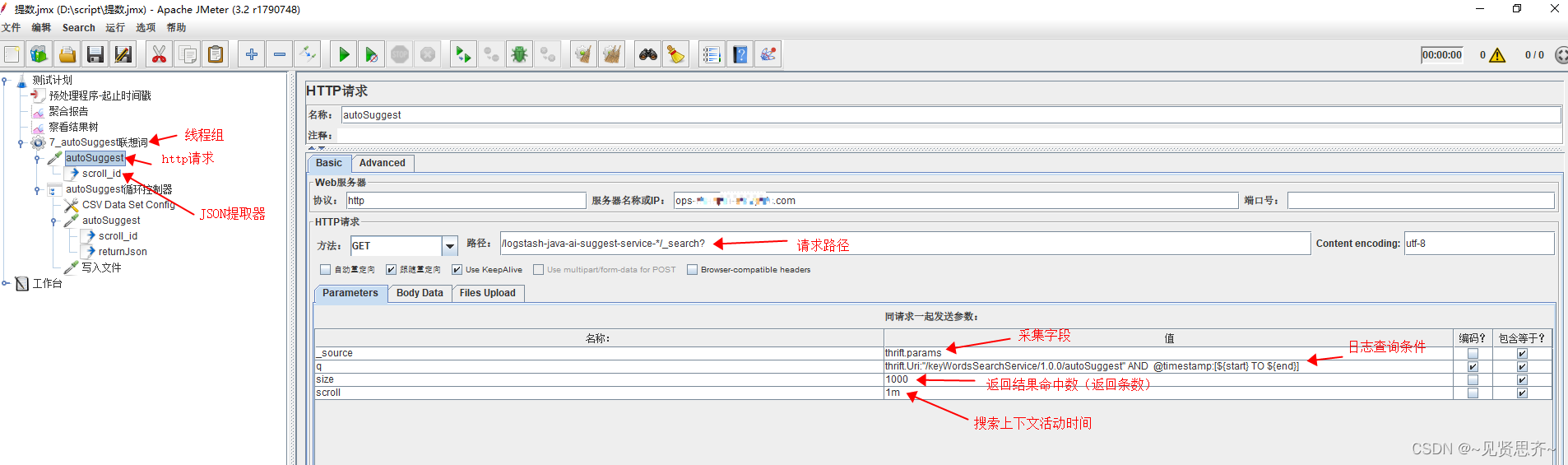
查询条件信息
| _source | thrift.params |
| q | thrift.Uri:"/keyWordsSearchService/1.0.0/autoSuggest" AND @timestamp:[${start} TO ${end}] |
| size | 1000 |
| scroll | 1m |
2)JSON提取器。
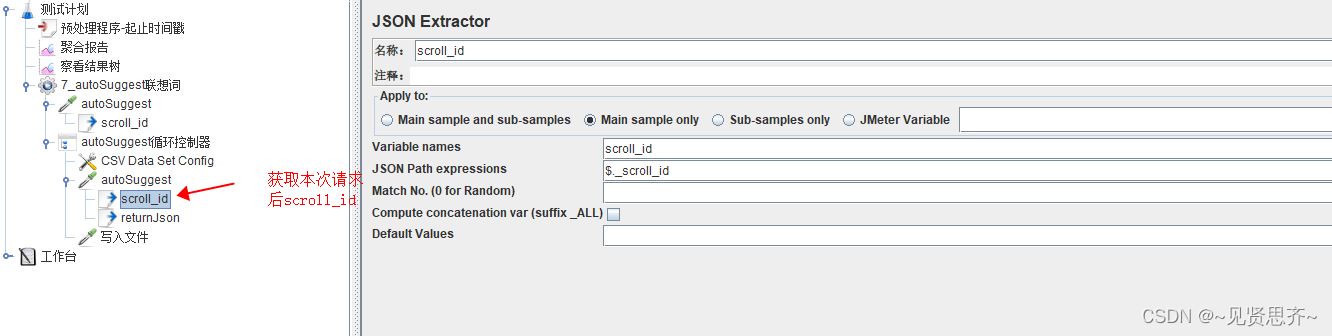
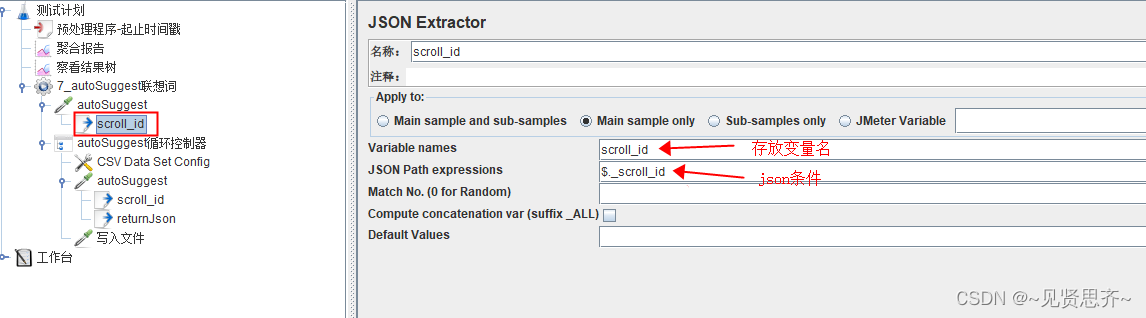 用来按条件获取HTTP请求后返回结果中_scroll_id字段的值,因为下次请求的入参需要_scroll_id字段的值。如下图。
用来按条件获取HTTP请求后返回结果中_scroll_id字段的值,因为下次请求的入参需要_scroll_id字段的值。如下图。

3)使用迭代器循环调用日志采集http请求插件。
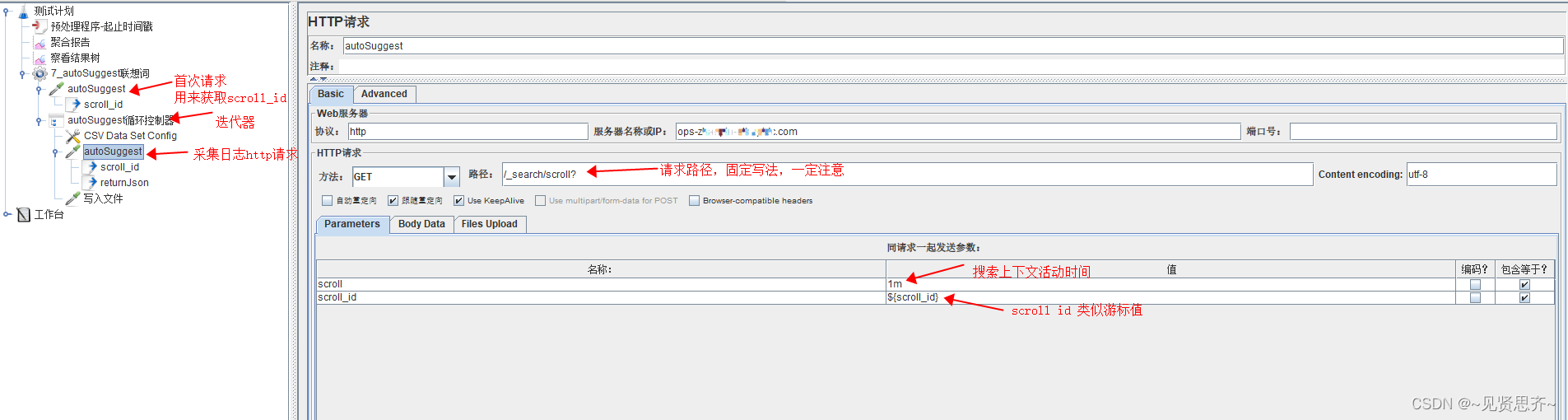
http请求插件下,需要创建2个JSON 提取器,如下图所示:
JSON提取器一
JSON提取器二
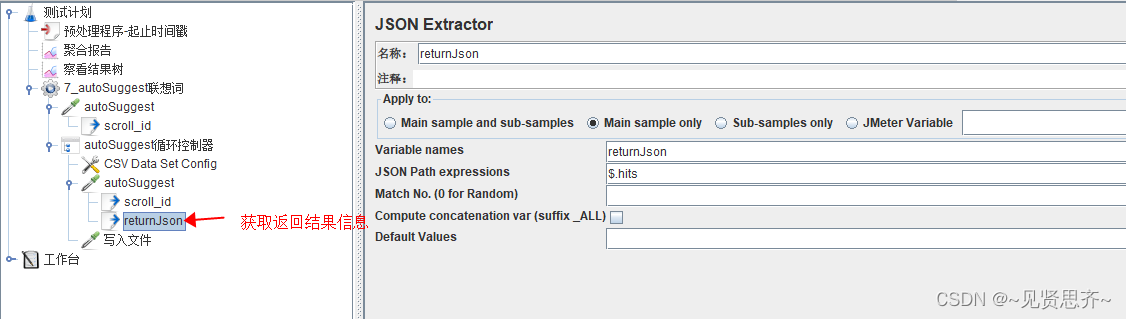
获取 json中 htis节点值。
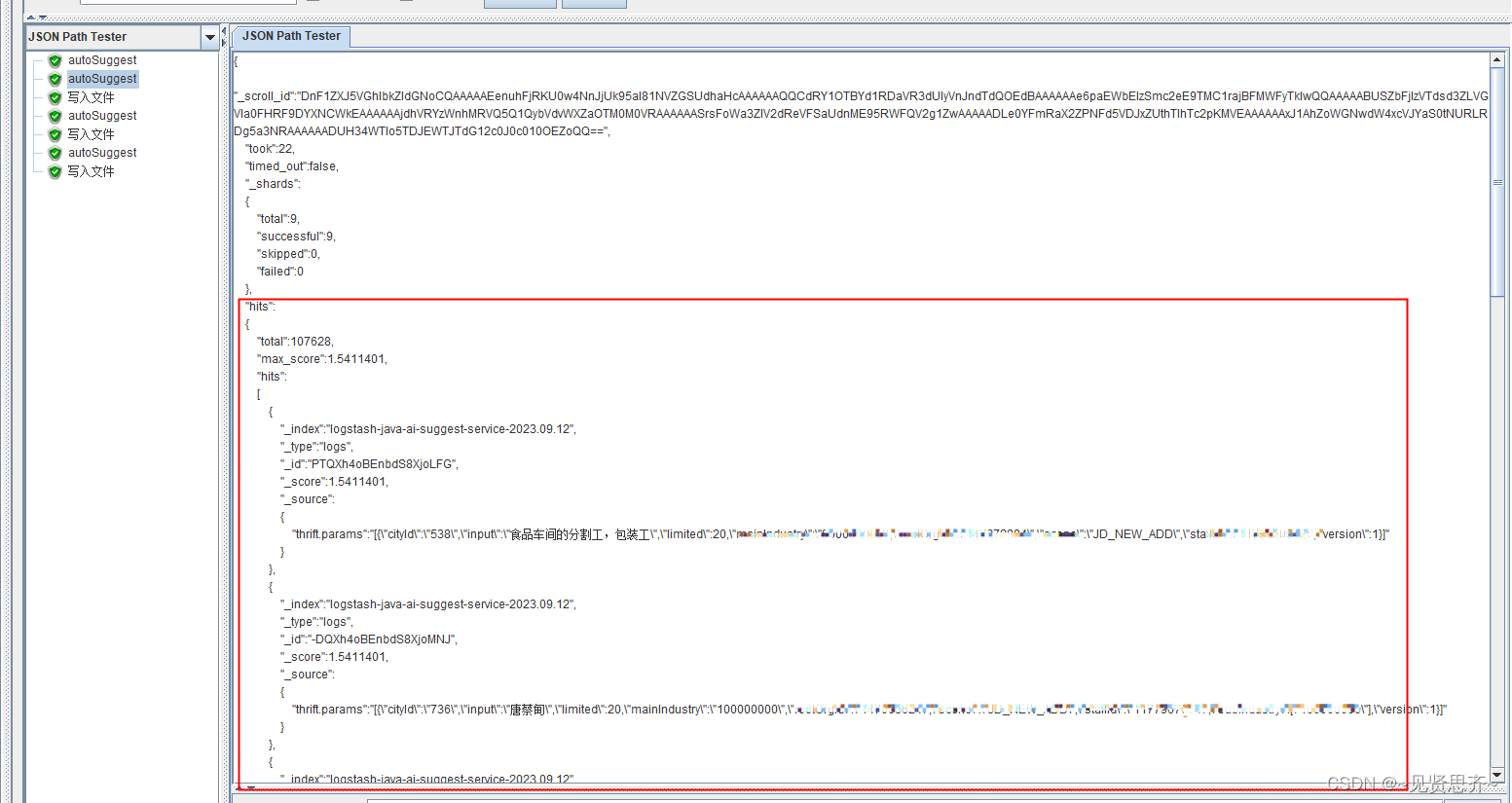
4)迭代器下创建BeanShell Sampler。用来对返回结果值(hits节点)加工处理后,存入指定目录下文件。
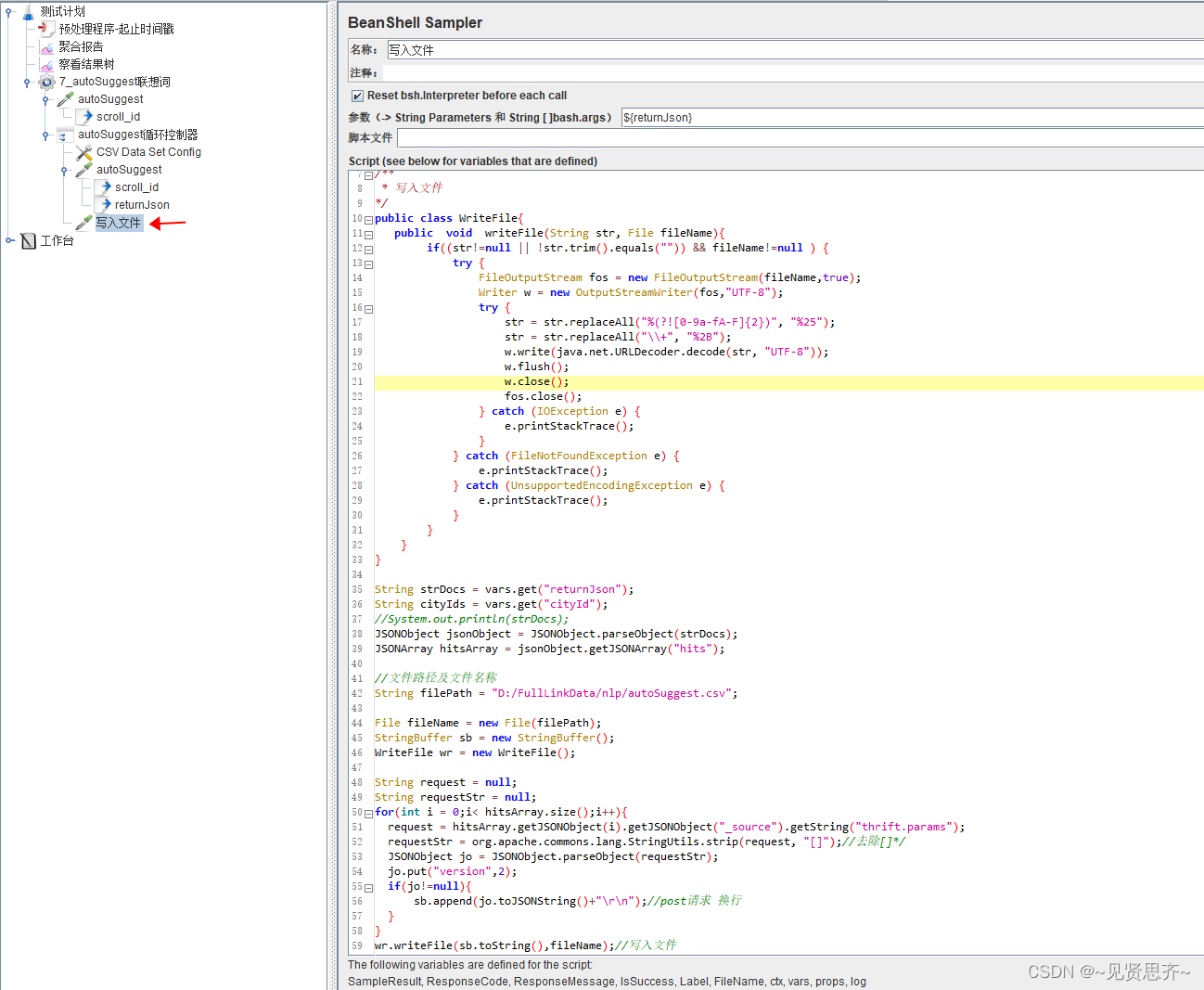
Beanshell 代码如下:
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONArray;
import org.apache.commons.lang.StringUtils;
import java.io.*;
import java.io.File;/*** 写入文件
*/
public class WriteFile{public void writeFile(String str, File fileName){if((str!=null || !str.trim().equals("")) && fileName!=null ) {try {FileOutputStream fos = new FileOutputStream(fileName,true);Writer w = new OutputStreamWriter(fos,"UTF-8");try {str = str.replaceAll("%(?![0-9a-fA-F]{2})", "%25");str = str.replaceAll("\\+", "%2B");w.write(java.net.URLDecoder.decode(str, "UTF-8"));w.flush();w.close();fos.close();} catch (IOException e) {e.printStackTrace();}} catch (FileNotFoundException e) {e.printStackTrace();} catch (UnsupportedEncodingException e) {e.printStackTrace();}}}
}String strDocs = vars.get("returnJson");
String cityIds = vars.get("cityId");
//System.out.println(strDocs);
JSONObject jsonObject = JSONObject.parseObject(strDocs);
JSONArray hitsArray = jsonObject.getJSONArray("hits");//文件路径及文件名称
String filePath = "D:/FullLinkData/nlp/autoSuggest.csv";File fileName = new File(filePath);
StringBuffer sb = new StringBuffer();
WriteFile wr = new WriteFile();String request = null;
String requestStr = null;
for(int i = 0;i< hitsArray.size();i++){request = hitsArray.getJSONObject(i).getJSONObject("_source").getString("thrift.params");requestStr = org.apache.commons.lang.StringUtils.strip(request, "[]");//去除[]*/JSONObject jo = JSONObject.parseObject(requestStr);jo.put("version",2);if(jo!=null){sb.append(jo.toJSONString()+"\r\n");//post请求 换行}
}
wr.writeFile(sb.toString(),fileName);//写入文件最后,运行后,生成文件如下,采集速度杠杠滴!(敏感信息已处理)

参考:Scroll - Elasticsearch 高手之路
手工整理不易,如转载请注明出处~~


![[学习笔记]Node2Vec图神经网络论文精读](https://img-blog.csdnimg.cn/0a93ff14423d4563b2a0d327367c1fe7.png)