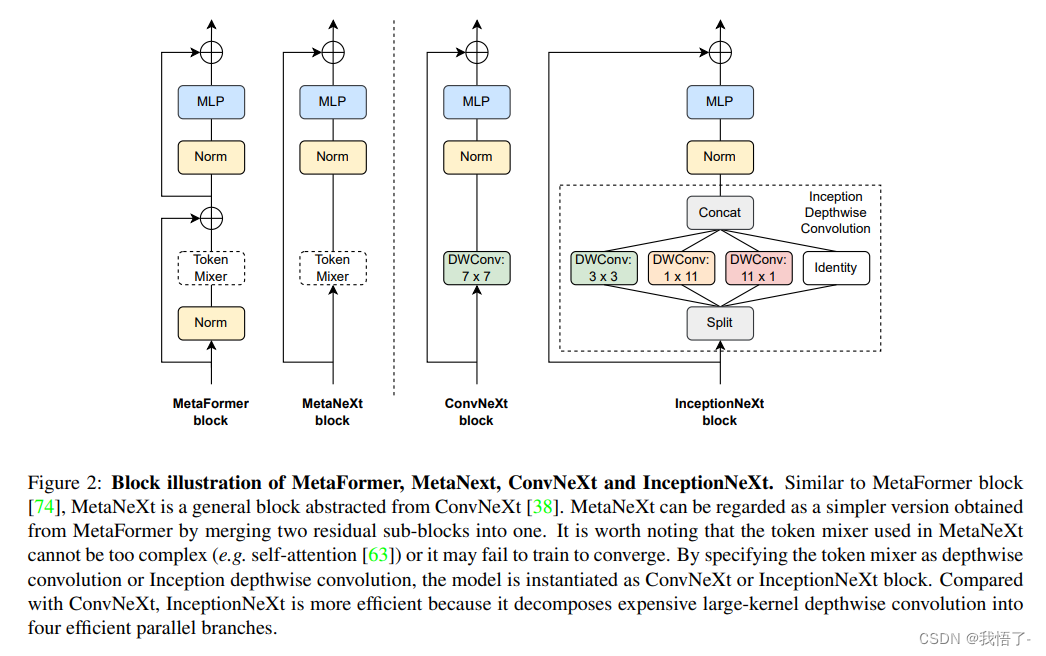
InceptionNeXt
受 Vision Transformer 长距离依赖关系建模能力的启发,最近一些视觉模型开始上大 Kernel 的 Depth-Wise 卷积,比如一篇出色的工作 ConvNeXt。虽然这种 Depth-Wise 的算子只消耗少量的 FLOPs,但由于高昂的内存访问成本 (memory access cost),在高性能的计算设备上会损害模型的效率。举例来说,ConvNeXt-T 和 ResNet-50 的 FLOPs 相似,但是在 A100 GPU 上进行全精度训练时,只能达到 60% 的吞吐量。
原文地址:InceptionNeXt: When Inception Meets ConvNeXt
针对这个问题,一种提高速度的方法是减小 Kernel 的大小,但是会导致显著的性能下降。目前还不清楚如何在保持基于大 Kernel 的 CNN 模型性能的同时加速。
为了解决这个问题,受 Inception 的启发,本文作者提出将大 Kernel 的 Depth-Wise 卷积沿 channel 维度分解为四个并行分支,即小的矩形卷积核:两个正交的带状卷积核和一个恒等映射。通过这种新的 Inception Depth-Wise 卷积,作者构建了一系列网络,称为 IncepitonNeXt,这些网络不仅具有高吞吐量,而且还保持了具有竞争力的性能。例如,InceptionNeXt-T 的训练吞吐量比 ConvNeXt-T 高1.6倍,在 ImageNet-1K 上的 top-1 精度提高了 0.2%。
论文目标不是扩大卷积核。相反是以效率为目标,在保持相当的性能的前提下,以简单和速度友好的方式分解大卷积核。
InceptionNeXt代码实现
"""
InceptionNeXt implementation, paper: https://arxiv.org/abs/2303.16900
Some code is borrowed from timm: https://github.com/huggingface/pytorch-image-models
"""from functools import partialimport torch
import torch.nn as nn
import numpy as npfrom timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models import checkpoint_seq, to_2tuple
from timm.models.layers import trunc_normal_, DropPath
from timm.models.registry import register_model__all__ = ['inceptionnext_tiny', 'inceptionnext_small', 'inceptionnext_base', 'inceptionnext_base_384']class InceptionDWConv2d(nn.Module):""" Inception depthweise convolution"""def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=11, branch_ratio=0.125):super().__init__()gc = int(in_channels * branch_ratio) # channel numbers of a convolution branchself.dwconv_hw = nn.Conv2d(gc, gc, square_kernel_size, padding=square_kernel_size//2, groups=gc)self.dwconv_w = nn.Conv2d(gc, gc, kernel_size=(1, band_kernel_size), padding=(0, band_kernel_size//2), groups=gc)self.dwconv_h = nn.Conv2d(gc, gc, kernel_size=(band_kernel_size, 1), padding=(band_kernel_size//2, 0), groups=gc)self.split_indexes = (in_channels - 3 * gc, gc, gc, gc)def forward(self, x):x_id, x_hw, x_w, x_h = torch.split(x, self.split_indexes, dim=1)return torch.cat((x_id, self.dwconv_hw(x_hw), self.dwconv_w(x_w), self.dwconv_h(x_h)), dim=1,)class ConvMlp(nn.Module):""" MLP using 1x1 convs that keeps spatial dimscopied from timm: https://github.com/huggingface/pytorch-image-models/blob/v0.6.11/timm/models/layers/mlp.py"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU,norm_layer=None, bias=True, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresbias = to_2tuple(bias)self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, bias=bias[0])self.norm = norm_layer(hidden_features) if norm_layer else nn.Identity()self.act = act_layer()self.drop = nn.Dropout(drop)self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1, bias=bias[1])def forward(self, x):x = self.fc1(x)x = self.norm(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)return xclass MlpHead(nn.Module):""" MLP classification head"""def __init__(self, dim, num_classes=1000, mlp_ratio=3, act_layer=nn.GELU,norm_layer=partial(nn.LayerNorm, eps=1e-6), drop=0., bias=True):super().__init__()hidden_features = int(mlp_ratio * dim)self.fc1 = nn.Linear(dim, hidden_features, bias=bias)self.act = act_layer()self.norm = norm_layer(hidden_features)self.fc2 = nn.Linear(hidden_features, num_classes, bias=bias)self.drop = nn.Dropout(drop)def forward(self, x):x = x.mean((2, 3)) # global average poolingx = self.fc1(x)x = self.act(x)x = self.norm(x)x = self.drop(x)x = self.fc2(x)return xclass MetaNeXtBlock(nn.Module):""" MetaNeXtBlock BlockArgs:dim (int): Number of input channels.drop_path (float): Stochastic depth rate. Default: 0.0ls_init_value (float): Init value for Layer Scale. Default: 1e-6."""def __init__(self,dim,token_mixer=InceptionDWConv2d,norm_layer=nn.BatchNorm2d,mlp_layer=ConvMlp,mlp_ratio=4,act_layer=nn.GELU,ls_init_value=1e-6,drop_path=0.,):super().__init__()self.token_mixer = token_mixer(dim)self.norm = norm_layer(dim)self.mlp = mlp_layer(dim, int(mlp_ratio * dim), act_layer=act_layer)self.gamma = nn.Parameter(ls_init_value * torch.ones(dim)) if ls_init_value else Noneself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):shortcut = xx = self.token_mixer(x)x = self.norm(x)x = self.mlp(x)if self.gamma is not None:x = x.mul(self.gamma.reshape(1, -1, 1, 1))x = self.drop_path(x) + shortcutreturn xclass MetaNeXtStage(nn.Module):def __init__(self,in_chs,out_chs,ds_stride=2,depth=2,drop_path_rates=None,ls_init_value=1.0,act_layer=nn.GELU,norm_layer=None,mlp_ratio=4,):super().__init__()self.grad_checkpointing = Falseif ds_stride > 1:self.downsample = nn.Sequential(norm_layer(in_chs),nn.Conv2d(in_chs, out_chs, kernel_size=ds_stride, stride=ds_stride),)else:self.downsample = nn.Identity()drop_path_rates = drop_path_rates or [0.] * depthstage_blocks = []for i in range(depth):stage_blocks.append(MetaNeXtBlock(dim=out_chs,drop_path=drop_path_rates[i],ls_init_value=ls_init_value,act_layer=act_layer,norm_layer=norm_layer,mlp_ratio=mlp_ratio,))in_chs = out_chsself.blocks = nn.Sequential(*stage_blocks)def forward(self, x):x = self.downsample(x)if self.grad_checkpointing and not torch.jit.is_scripting():x = checkpoint_seq(self.blocks, x)else:x = self.blocks(x)return xclass MetaNeXt(nn.Module):r""" MetaNeXtA PyTorch impl of : `InceptionNeXt: When Inception Meets ConvNeXt` - https://arxiv.org/pdf/2203.xxxxx.pdfArgs:in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000depths (tuple(int)): Number of blocks at each stage. Default: (3, 3, 9, 3)dims (tuple(int)): Feature dimension at each stage. Default: (96, 192, 384, 768)token_mixers: Token mixer function. Default: nn.Identitynorm_layer: Normalziation layer. Default: nn.BatchNorm2dact_layer: Activation function for MLP. Default: nn.GELUmlp_ratios (int or tuple(int)): MLP ratios. Default: (4, 4, 4, 3)head_fn: classifier headdrop_rate (float): Head dropout ratedrop_path_rate (float): Stochastic depth rate. Default: 0.ls_init_value (float): Init value for Layer Scale. Default: 1e-6."""def __init__(self,in_chans=3,num_classes=1000,depths=(3, 3, 9, 3),dims=(96, 192, 384, 768),token_mixers=nn.Identity,norm_layer=nn.BatchNorm2d,act_layer=nn.GELU,mlp_ratios=(4, 4, 4, 3),head_fn=MlpHead,drop_rate=0.,drop_path_rate=0.,ls_init_value=1e-6,**kwargs,):super().__init__()num_stage = len(depths)if not isinstance(token_mixers, (list, tuple)):token_mixers = [token_mixers] * num_stageif not isinstance(mlp_ratios, (list, tuple)):mlp_ratios = [mlp_ratios] * num_stageself.num_classes = num_classesself.drop_rate = drop_rateself.stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),norm_layer(dims[0]))self.stages = nn.Sequential()dp_rates = [x.tolist() for x in torch.linspace(0, drop_path_rate, sum(depths)).split(depths)]stages = []prev_chs = dims[0]# feature resolution stages, each consisting of multiple residual blocksfor i in range(num_stage):out_chs = dims[i]stages.append(MetaNeXtStage(prev_chs,out_chs,ds_stride=2 if i > 0 else 1, depth=depths[i],drop_path_rates=dp_rates[i],ls_init_value=ls_init_value,act_layer=act_layer,norm_layer=norm_layer,mlp_ratio=mlp_ratios[i],))prev_chs = out_chsself.stages = nn.Sequential(*stages)self.num_features = prev_chsself.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]@torch.jit.ignoredef set_grad_checkpointing(self, enable=True):for s in self.stages:s.grad_checkpointing = enable@torch.jit.ignoredef no_weight_decay(self):return {'norm'}def forward(self, x):input_size = x.size(2)scale = [4, 8, 16, 32]features = [None, None, None, None]x = self.stem(x)features[scale.index(input_size // x.size(2))] = xfor idx, layer in enumerate(self.stages):x = layer(x)if input_size // x.size(2) in scale:features[scale.index(input_size // x.size(2))] = xreturn featuresdef _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def _cfg(url='', **kwargs):return {'url': url,'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),'crop_pct': 0.875, 'interpolation': 'bicubic','mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,'first_conv': 'stem.0', 'classifier': 'head.fc',**kwargs}def update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dictdefault_cfgs = dict(inceptionnext_tiny=_cfg(url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_tiny.pth',),inceptionnext_small=_cfg(url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_small.pth',),inceptionnext_base=_cfg(url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_base.pth',),inceptionnext_base_384=_cfg(url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_base_384.pth',input_size=(3, 384, 384), crop_pct=1.0,),
)def inceptionnext_tiny(pretrained=False, **kwargs):model = MetaNeXt(depths=(3, 3, 9, 3), dims=(96, 192, 384, 768), token_mixers=InceptionDWConv2d,**kwargs)model.default_cfg = default_cfgs['inceptionnext_tiny']if pretrained:state_dict = torch.hub.load_state_dict_from_url(url=model.default_cfg['url'], map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return modeldef inceptionnext_small(pretrained=False, **kwargs):model = MetaNeXt(depths=(3, 3, 27, 3), dims=(96, 192, 384, 768), token_mixers=InceptionDWConv2d,**kwargs)model.default_cfg = default_cfgs['inceptionnext_small']if pretrained:state_dict = torch.hub.load_state_dict_from_url(url=model.default_cfg['url'], map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return modeldef inceptionnext_base(pretrained=False, **kwargs):model = MetaNeXt(depths=(3, 3, 27, 3), dims=(128, 256, 512, 1024), token_mixers=InceptionDWConv2d,**kwargs)model.default_cfg = default_cfgs['inceptionnext_base']if pretrained:state_dict = torch.hub.load_state_dict_from_url(url=model.default_cfg['url'], map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return modeldef inceptionnext_base_384(pretrained=False, **kwargs):model = MetaNeXt(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], mlp_ratios=[4, 4, 4, 3],token_mixers=InceptionDWConv2d,**kwargs)model.default_cfg = default_cfgs['inceptionnext_base_384']if pretrained:state_dict = torch.hub.load_state_dict_from_url(url=model.default_cfg['url'], map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return modelif __name__ == '__main__':model = inceptionnext_tiny(pretrained=False)inputs = torch.randn((1, 3, 640, 640))for i in model(inputs):print(i.size())
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif isinstance(m, str):t = mm = timm.create_model(m, pretrained=args[0], features_only=True)c2 = m.feature_info.channels()elif m in {inceptionnext_tiny, inceptionnext_small}: #可添加更多Backbonem = m(*args)c2 = m.channelelse:c2 = ch[f]if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
创建.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, inceptionnext_tiny, [False]], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]