项目地址:IMDB电影评论的情感分析 - 飞桨AI Studio星河社区 (baidu.com)
1. 实验介绍
1.1 实验目的
- 理解并掌握循环神经网络的基础知识点,包括模型的时序结构、模型的前向传播、反向传播等
- 掌握长短时记忆网络LSTM和门控循环单元网络GRU的设计原理
- 熟悉如何使用飞桨深度学习开源框架构建循环神经网络
1.2 实验内容
自然语言是人类传递信息的一种载体,同时它也能表达人类交流时的一种情感。一段对话或者一句评论都能蕴含着丰富的感情色彩:比如高兴、快乐、喜欢、讨厌、忧伤等等。
如图2 所示,利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。通常情况下,往往将情感分析任务定义为一个分类问题,即使用计算机判定给定的一段文字所表达的情感属于积极情绪,还是消极情绪。
本实验将基于LSTM建模情感分析模型,对IMDB电影评论进行情感倾向分析,这有助于帮助消费者了解一部电影的质量,也可用于电影的推荐。
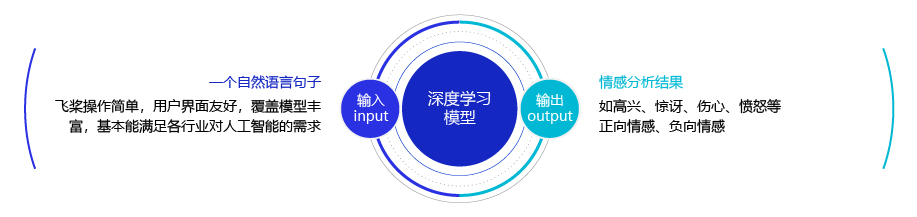
图2 情感分析图
1.3 实验环境
本实验支持在实训平台或本地环境操作,建议使用实训平台。
- 实训平台:如果选择在实训平台上操作,无需安装实验环境。实训平台集成了实验必须的相关环境,代码可在线运行,同时还提供了免费算力,即使实践复杂模型也无算力之忧。
- 本地环境:如果选择在本地环境上操作,需要安装Python3.7、飞桨开源框架2.0等实验必须的环境,具体要求及实现代码请参见《本地环境安装说明》。
可以通过如下代码导入实验环境。
# 导入paddle及相关包
import paddle
import paddle.nn.functional as F
import re
import random
import tarfile
import requests
import numpy as nppaddle.seed(0)
random.seed(0)
np.random.seed(0)
print(paddle.__version__)1.4 实验设计
本实验的模型实现方案如 图3 所示,模型的输入是文本数据,模型的输出就是文本的情感标签。在建模过程中,对于输入的电影评论文本,首先需要进行数据处理(比如分词,构建词表,过长文本截断,过短文本填充等);然后使用长短时记忆网络LSTM对文本序列进行编码,获得文本的语义向量表示;最后经过全连接层和softmax处理得到文本分类为积极情感和消极情感的概率。
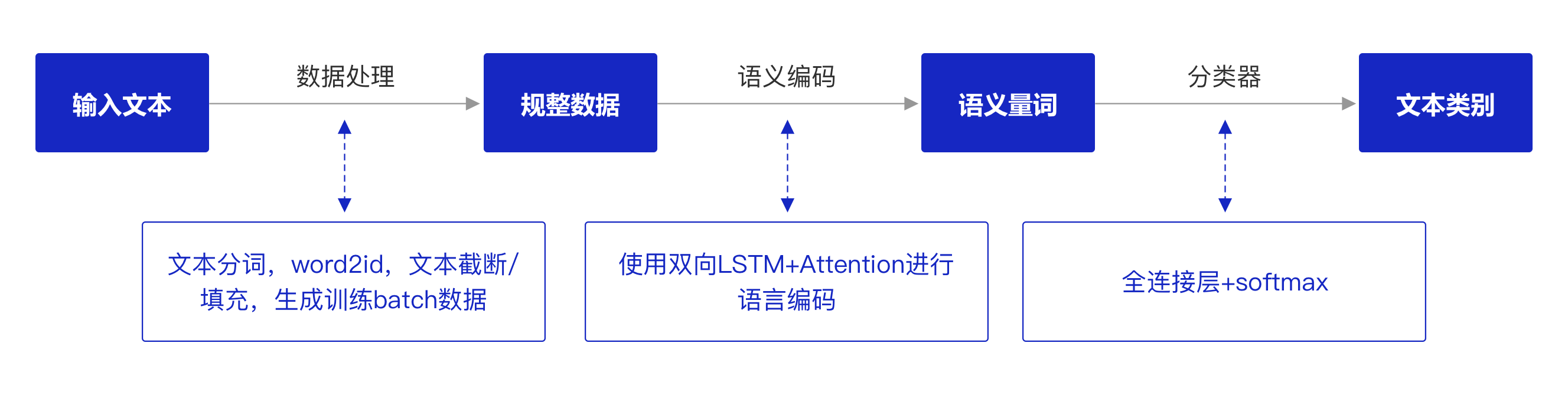
图3 电影评论情感分析设计方案
2. 实验详细实现
IMDB电影评论情感分析实验流程如 图4 所示,包含如下7个步骤:
- 数据处理:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
- 模型构建:设计情感分析模型,判断文本的情感倾向;
- 训练配置:实例化模型,选择模型计算资源(CPU或者GPU),指定模型迭代的优化算法;
- 模型训练:执行多轮训练不断调整参数,以达到较好的效果;
- 模型保存:将模型参数保存到指定位置,便于后续推理或继续训练使用;
- 模型评估:对训练好的模型进行评估测试,观察准确率和Loss;
- 模型推理:选取一段电影评论数据,通过模型推理出评论文本所属的情感类别。

图4 IMDB电影评论的情感分析实验流程
2.1 数据处理
数据处理部分包含数据集介绍、IMDB数据集下载、读取数据至内存、转换数据格式并组装数据为mini-batch形式,以便模型处理。数据处理的总体流程如 图5 所示。

图5 数据处理流程
2.1.1 数据集介绍
本实验使用的数据为IMDB电影评论数据集。IMDB是一份关于电影评论的数据集,消费者对电影进行评论时可以进行打分,满分是10分。IMDB将消费者对电影的评论按照评分的高低筛选出了积极评论和消极评论,如果评分>=7,则认为是积极评论;如果评分<=4,则认为是消极评论。所以IMDB数据集是一份关于情感分析的经典二分类数据集,其中训练集和测试集数量各为25000条。
2.1.2 数据下载
首先,需要下载IMDB数据集,该数据集包括训练和测试集。数据集下载的代码如下:
def download():# 通过python的requests类,下载存储在# https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz的文件corpus_url = "https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz"web_request = requests.get(corpus_url)corpus = web_request.content# 将下载的文件写在当前目录的aclImdb_v1.tar.gz文件内with open("./aclImdb_v1.tar.gz", "wb") as f:f.write(corpus)f.close()download()2.1.3 数据读取
下载后的数据集aclImdb_v1.tar.gz是一个压缩文件,可以使用python的rarfile库进行解压,解压代码如下所示:
# 数据解压代码
!tar -xzvf aclImdb_v1.tar.gzaclImdb/train/unsup/38074_0.txtIOPub data rate exceeded. The notebook server will temporarily stop sending output to the client in order to avoid crashing it. To change this limit, set the config variable `--NotebookApp.iopub_data_rate_limit`.Current values: NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec) NotebookApp.rate_limit_window=3.0 (secs)
解压之后目录结构如 图6 所示:

图6 IMDB数据集解压目录
本实验主要用到目录train(训练集)和test(测试集)的内容,训练集和测试集的目录结构的含义解释是一致的。以训练集为例,训练数据按照标签分别放到了目录pos(积极的评论)和neg(消极的评论)下,每个子目录均由若干小文件组成,每个小文件内部都是一段用户关于某个电影的真实评价,以及观众对这个电影的情感倾向。
接下来,根据IMDB数据集的组织形式,便可将IMDB数据读取到内存,代码如下:
# 读取数据
def load_imdb(is_training):# 将读取的数据放到列表data_set里data_set = []# data_set中每个元素都是一个二元组:(句子,label),其中label=0表示消极情感,label=1表示积极情感for label in ["pos", "neg"]:with tarfile.open("./aclImdb_v1.tar.gz") as tarf:path_pattern = "aclImdb/train/" + label + "/.*\.txt$" if is_training \else "aclImdb/test/" + label + "/.*\.txt$"path_pattern = re.compile(path_pattern)tf = tarf.next()while tf != None:if bool(path_pattern.match(tf.name)):sentence = tarf.extractfile(tf).read().decode()sentence_label = 0 if label == 'neg' else 1data_set.append((sentence, sentence_label)) tf = tarf.next()return data_settrain_corpus = load_imdb(True)
test_corpus = load_imdb(False)# 打印第一条数据,查看数据格式:(句子,label)
print(train_corpus[0])2.1.4 数据格式转换
模型是无法直接处理文本数据的,在自然语言处理中,常规的做法是先将文本进行分词,然后将每个词映射为该词在词典中的id,方便模型后续根据这个id找到该词的词向量。那这里就涉及到了这样几个流程:分词、组建词表、将文本中的词映射为词典id。
- 分词
先来看分词问题,因为IMDB数据集本身是英文语料,所以只需要根据空格进行分词即可,代码如下:
def data_preprocess(corpus):data_set = []for sentence, sentence_label in corpus:# 将所有的句子转换为小写,一方面可以减小词表的大小,另一方面也有助于效果提升sentence = sentence.strip().lower()sentence = sentence.split(" ")data_set.append((sentence, sentence_label))return data_settrain_set = data_preprocess(train_corpus)
test_set = data_preprocess(test_corpus)# 打印训练集中的第一条数据
print(train_set[0])(['zentropa', 'has', 'much', 'in', 'common', 'with', 'the', 'third', 'man,', 'another', 'noir-like', 'film', 'set', 'among', 'the', 'rubble', 'of', 'postwar', 'europe.', 'like', 'ttm,', 'there', 'is', 'much', 'inventive', 'camera', 'work.', 'there', 'is', 'an', 'innocent', 'american', 'who', 'gets', 'emotionally', 'involved', 'with', 'a', 'woman', 'he', "doesn't", 'really', 'understand,', 'and', 'whose', 'naivety', 'is', 'all', 'the', 'more', 'striking', 'in', 'contrast', 'with', 'the', 'natives.<br', '/><br', '/>but', "i'd", 'have', 'to', 'say', 'that', 'the', 'third', 'man', 'has', 'a', 'more', 'well-crafted', 'storyline.', 'zentropa', 'is', 'a', 'bit', 'disjointed', 'in', 'this', 'respect.', 'perhaps', 'this', 'is', 'intentional:', 'it', 'is', 'presented', 'as', 'a', 'dream/nightmare,', 'and', 'making', 'it', 'too', 'coherent', 'would', 'spoil', 'the', 'effect.', '<br', '/><br', '/>this', 'movie', 'is', 'unrelentingly', 'grim--"noir"', 'in', 'more', 'than', 'one', 'sense;', 'one', 'never', 'sees', 'the', 'sun', 'shine.', 'grim,', 'but', 'intriguing,', 'and', 'frightening.'], 1)
- 组建词表
在经过切词后,需要构造一个词典,后续把每个词都转化成一个ID,便于神经网络训练。按照如下方式生成词典:
- 统计训练语料中的单词的频率,然后根据频率大小生成词典,频率高的词在词典的前边,频率低的词在后边。
- 添加单词"[oov]",它表示词表中没有覆盖到的词,即模型在预测时,很可能遇到词表中没有的单词,这样的单词也叫未登录词,这时候会将未登录词统一映射为"[oov]"
- 添加单词"[pad]",它用于填充文本到指定的文本长度,以便每次传入到模型中的一批文本的长度是一致的
为了方便记忆,习惯将这些特殊单词放在词典的最前边,代码如下:
# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):word_freq_dict = dict()for sentence, _ in corpus:for word in sentence:if word not in word_freq_dict:word_freq_dict[word] = 0word_freq_dict[word] += 1word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)word2id_dict = dict()word2id_freq = dict()# 一般来说,我们把oov和pad放在词典前面,给他们一个比较小的id,这样比较方便记忆,并且易于后续扩展词表word2id_dict['[oov]'] = 0word2id_freq[0] = 1e10word2id_dict['[pad]'] = 1word2id_freq[1] = 1e10for word, freq in word_freq_dict:word2id_dict[word] = len(word2id_dict)word2id_freq[word2id_dict[word]] = freqreturn word2id_freq, word2id_dictword2id_freq, word2id_dict = build_dict(train_set)
vocab_size = len(word2id_freq)
print("there are totoally %d different words in the corpus" % vocab_size)
for _, (word, word_id) in zip(range(5), word2id_dict.items()):print("word %s, its id %d, its word freq %d" % (word, word_id, word2id_freq[word_id]))there are totoally 252173 different words in the corpus word [oov], its id 0, its word freq 10000000000 word [pad], its id 1, its word freq 10000000000 word the, its id 2, its word freq 322174 word a, its id 3, its word freq 159949 word and, its id 4, its word freq 158556
- 映射为词典id
在完成word2id词典建立之后,还需要将语料中的所有文本处理成ID序列,具体是将每个文本中的单词映射为词典的id。如果句子中的词不在词表内,则替换成单词"[oov]",相应的代码如下:
# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):data_set = []for sentence, sentence_label in corpus:sentence = [word2id_dict[word] if word in word2id_dict \else word2id_dict['[oov]'] for word in sentence] data_set.append((sentence, sentence_label))return data_settrain_set = convert_corpus_to_id(train_set, word2id_dict)
test_set = convert_corpus_to_id(test_set, word2id_dict)# 打印训练数据中的第一条文本
print(train_set[0])([22216, 41, 76, 8, 1136, 17, 2, 874, 979, 167, 69425, 24, 283, 707, 2, 19881, 5, 16628, 11952, 37, 100421, 52, 7, 76, 5733, 415, 912, 52, 7, 32, 1426, 299, 36, 195, 2299, 644, 17, 3, 282, 27, 141, 61, 7447, 4, 555, 25364, 7, 35, 2, 51, 3590, 8, 2691, 17, 2, 69426, 13, 688, 428, 26, 6, 142, 11, 2, 874, 160, 41, 3, 51, 14841, 4458, 22216, 7, 3, 218, 6262, 8, 10, 6919, 382, 10, 7, 100422, 12, 7, 1394, 15, 3, 100423, 4, 242, 12, 104, 5041, 54, 2368, 2, 4828, 109, 13, 255, 20, 7, 32280, 100424, 8, 51, 68, 30, 29571, 30, 102, 1010, 2, 4142, 18952, 11069, 18, 11636, 4, 12644], 1)
2.1.5 组装mini-batch
在训练模型时,通常将数据分批传入模型进行训练,每批数据作为一个mini-batch。所以还需要将所有数据按批次(mini-batch)划分,每个batch数据包含两部分:文本数据和文本对应的情感标签label。但是这里涉及到一个问题,一个mini-batch数据中通常包含若干条文本,每条文本的长度不一致,这样就会给模型训练带来困难。
通常的做法是设定一个最大长度max_seq_len,对于大于该长度的文本进行截断,小于该长度的文本使用"[pad]"进行填充。这样就能将每个batch的所有文本长度进行统一,以便模型训练。组装mini-batch的代码如下:
def build_batch(word2id_dict, corpus, batch_size, epoch_num, max_seq_len, shuffle = True, drop_last = True):sentence_batch = []sentence_label_batch = []for _ in range(epoch_num): #每个epoch前都shuffle一下数据,有助于提高模型训练的效果。但是对于预测任务,不要做数据shuffleif shuffle:random.shuffle(corpus)for sentence, sentence_label in corpus:sentence_sample = sentence[:min(max_seq_len, len(sentence))]if len(sentence_sample) < max_seq_len:for _ in range(max_seq_len - len(sentence_sample)):sentence_sample.append(word2id_dict['[pad]'])sentence_batch.append(sentence_sample)sentence_label_batch.append([sentence_label])if len(sentence_batch) == batch_size:yield np.array(sentence_batch).astype("int64"), np.array(sentence_label_batch).astype("int64")sentence_batch = []sentence_label_batch = []if not drop_last and len(sentence_batch) > 0:yield np.array(sentence_batch).astype("int64"), np.array(sentence_label_batch).astype("int64")batch_iters = build_batch(word2id_dict, train_set, batch_size=3, epoch_num=3, max_seq_len=30)
# 答应第一个batch,查看数据shape
batch = next(batch_iters)
print("batch type: ", type(batch))
print("text shape: ", batch[0].shape)
print("label shape: ", batch[1].shape)batch type: <class 'tuple'> text shape: (3, 30) label shape: (3, 1)
2.2 模型构建
2.2.1 模型结构
上一节已经完成了数据处理部分,接下来将构建模型结构。本节将利用长短时记忆网络(LSTM)进行情感分析建模,LSTM模型是一个时序模型,如 图7 所示,每个时间步骤接收当前的单词输入和上一步的状态进行处理,同时每个时间步骤会输出一个单词和当前步骤的状态。每个时间步骤在时序上可以看做对应着一个LSTM单元,它对应着两个状态:单元状态和隐状态,其中单元状态代表遗忘之前单元信息并融入新的单词信息后,当前LSTM单元的状态;隐状态是单元状态对外的输出状态,每个时间步骤生成单词时利用的就是隐状态。
LSTM会根据时序关系依次处理每个时间步骤的输入,在将一个文本的所有单词全部传入LSTM模型后,LSTM模型最后输出的隐状态可以被看作是融合了之前所有单词的状态向量,因此这个状态变量也可以视为整串文本的语义向量。
将这个语义向量传入到线性层,再经过softmax处理后便可得到文本属于积极情感和消极情感的概率。
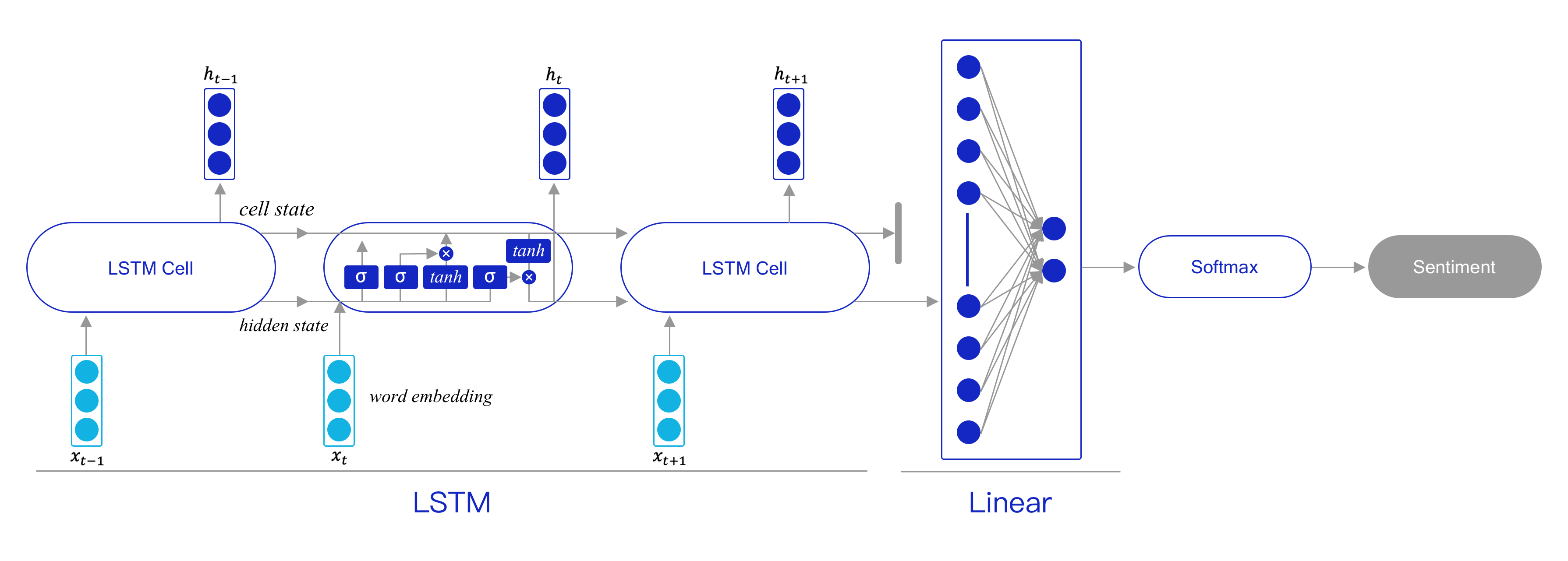
图7 情感分析模型网络结构示意图
2.2.2 模型计算
在了解了本实验建模的大致流程后,本节详细剖析下该网络计算时发生的事情,其中模型计算的部分可参考 图8 :
-
模型训练时通常以batch的形式按批训练模型,每个batch包含训练文本和文本对应的情感标签,假设当前batch的训练文本数据的shape为:[batch_size, max_seq_len],它代表本次迭代训练语料共有batch_size个,每条语料长度均为max_seq_len。这里需要注意,该文本数据从数据处理阶段获得,已经将单词映射为了字典id。
-
模型的输入包含两个部分,训练文本和文本对应的情感标签。模型在计算之前,需要将训练文本中每个单词的id转换为词向量(也成为word embedding),这个根据单词id查找词向量的操作成为embedding lookup。 在实现过程中,本节将利用飞桨提供的paddle.nn.Embedding,通过这个类能够很方便地根据单词id查找词向量,假设词向量的维度为embedding_size,则以上[batch_size, max_seq_len]的文本数据映射之后,将变成[batch_size, max_seq_len, embedding_size]的向量,它代表每个训练batch共batch_size条文本,每个文本长度均包含max_seq_len个单词,每个单词的维度为embedding_size。
-
在映射完词向量之后,便可以将batch数据[batch_size, max_seq_len, embedding_size]传入给LSTM模型,这里将借助paddle.nn.LSTM进行建模,在计算之后,便可得到该batch文本对应的语义向量,假设该语义向量的维度为hidden_size,其shape为[batch_size, hidden_size],它代表共有batch_size个语义向量,即每条文本对应一个语义向量,每个向量维度为hidden_size。
-
将该语义向量传入线性层中,经过矩阵计算便可得到一个2维向量。具体来讲,语义向量的shape为[batch_size, hidden_size],线性层的权重shape为[hidden_size, 2],这里的2主要是考虑到IMDB数据集是个2分类任务,在两者进行矩阵相乘后,便可得到[batch_size, 2]的矩阵,前边一列的数字代表消极情感,后边一列的数字代表积极情感。
-
然后将此[batch_size, 2]的矩阵通过softmax进行归一化处理,要求前边一列的数字加上后边一列的数字为1,并且每个数字取值范围为[0, 1],经过这步处理后,可以将前边一列的数字看成这条文本是消极情感的概率,后边一列的数字可以看成这条文本是积极情感的概率。
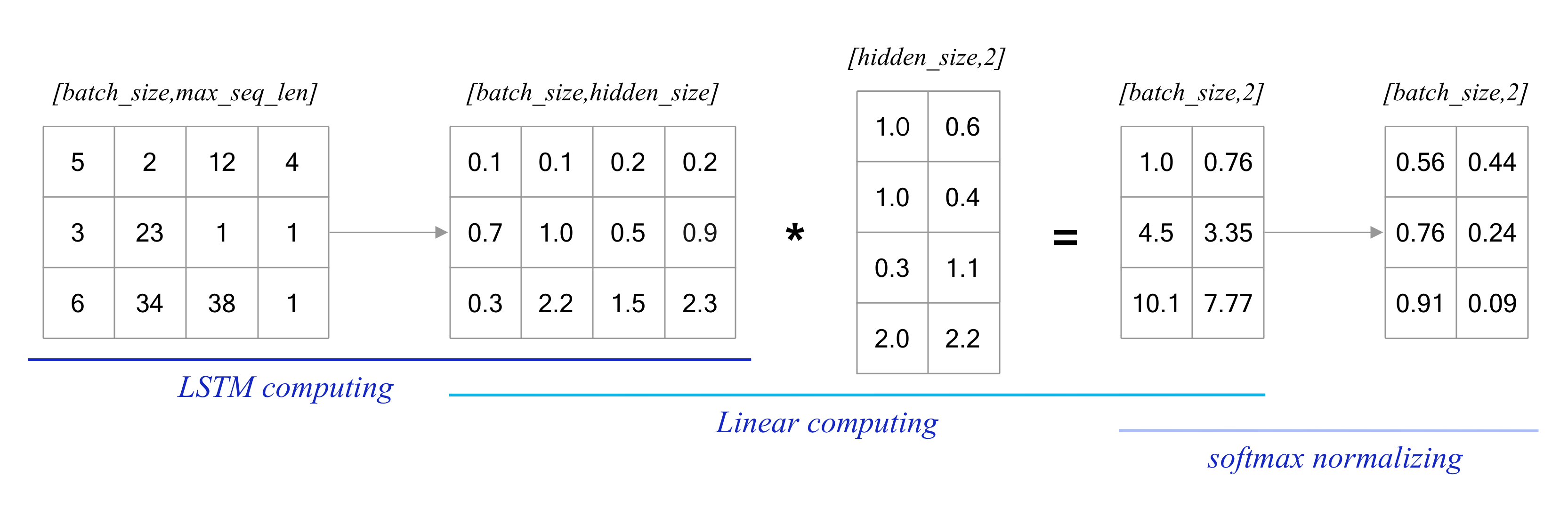
图8 模型计算样例
class paddle.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, sparse=False, weight_attr=None, name=None)
关键参数含义如下:
- num_embeddings (int) - 嵌入字典的大小, input中的id必须满足 0 =< id < num_embeddings 。
- embedding_dim (int) - 每个嵌入向量的维度。
- padding_idx (int|long|None) - padding_idx的配置区间为 [-weight.shape[0], weight.shape[0]],如果配置了padding_idx,那么在训练过程中遇到此id时会被用
- sparse (bool) - 是否使用稀疏更新,在词嵌入权重较大的情况下,使用稀疏更新能够获得更快的训练速度及更小的内存/显存占用。
- weight_attr (ParamAttr|None) - 指定嵌入向量的配置,包括初始化方法,具体用法请参见 ParamAttr ,一般无需设置,默认值为None。
class paddle.nn.LSTM(input_size, hidden_size, num_layers=1, direction='forward', dropout=0., time_major=False, weight_ih_attr=None, weight_hh_attr=None, bias_ih_attr=None, bias_hh_attr=None)
关键参数含义如下:
- input_size (int) - 输入的大小。
- hidden_size (int) - 隐藏状态大小。
- num_layers (int,可选) - 网络层数。默认为1。
- direction (str,可选) - 网络迭代方向,可设置为forward或bidirect(或bidirectional)。默认为forward。
- time_major (bool,可选) - 指定input的第一个维度是否是time steps。默认为False。
- dropout (float,可选) - dropout概率,指的是出第一层外每层输入时的dropout概率。默认为0。
- weight_ih_attr (ParamAttr,可选) - weight_ih的参数。默认为None。
- weight_hh_attr (ParamAttr,可选) - weight_hh的参数。默认为None。
- bias_ih_attr (ParamAttr,可选) - bias_ih的参数。默认为None。
- bias_hh_attr (ParamAttr,可选) - bias_hh的参数。默认为None。
网络计算对应的代码如下:
# 定义一个用于情感分类的网络实例,SentimentClassifier
class SentimentClassifier(paddle.nn.Layer):def __init__(self, hidden_size, vocab_size, embedding_size, class_num=2, num_steps=128, num_layers=1, init_scale=0.1, dropout_rate=None):# 参数含义如下:# 1.hidden_size,表示embedding-size,hidden和cell向量的维度# 2.vocab_size,模型可以考虑的词表大小# 3.embedding_size,表示词向量的维度# 4.class_num,情感类型个数,可以是2分类,也可以是多分类# 5.num_steps,表示这个情感分析模型最大可以考虑的句子长度# 6.num_layers,表示网络的层数# 7.dropout_rate,表示使用dropout过程中失活的神经元比例# 8.init_scale,表示网络内部的参数的初始化范围,长短时记忆网络内部用了很多Tanh,Sigmoid等激活函数,\# 这些函数对数值精度非常敏感,因此我们一般只使用比较小的初始化范围,以保证效果super(SentimentClassifier, self).__init__()self.hidden_size = hidden_sizeself.vocab_size = vocab_sizeself.embedding_size = embedding_sizeself.class_num = class_numself.num_steps = num_stepsself.num_layers = num_layersself.dropout_rate = dropout_rateself.init_scale = init_scale# 声明一个LSTM模型,用来把每个句子抽象成向量self.simple_lstm_rnn = paddle.nn.LSTM(input_size=hidden_size, hidden_size=hidden_size, num_layers=num_layers)# 声明一个embedding层,用来把句子中的每个词转换为向量self.embedding = paddle.nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_size, sparse=False, weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Uniform(low=-init_scale, high=init_scale)))# 声明使用上述语义向量映射到具体情感类别时所需要使用的线性层self.cls_fc = paddle.nn.Linear(in_features=self.hidden_size, out_features=self.class_num, weight_attr=None, bias_attr=None)# 一般在获取单词的embedding后,会使用dropout层,防止过拟合,提升模型泛化能力self.dropout_layer = paddle.nn.Dropout(p=self.dropout_rate, mode='upscale_in_train')# forwad函数即为模型前向计算的函数,它有两个输入,分别为:# input为输入的训练文本,其shape为[batch_size, max_seq_len]# label训练文本对应的情感标签,其shape维[batch_size, 1]def forward(self, inputs):# 获取输入数据的batch_sizebatch_size = inputs.shape[0]# 本实验默认使用1层的LSTM,首先我们需要定义LSTM的初始hidden和cell,这里我们使用0来初始化这个序列的记忆init_hidden_data = np.zeros((self.num_layers, batch_size, self.hidden_size), dtype='float32')init_cell_data = np.zeros((self.num_layers, batch_size, self.hidden_size), dtype='float32')# 将这些初始记忆转换为飞桨可计算的向量,并且设置stop_gradient=True,避免这些向量被更新,从而影响训练效果init_hidden = paddle.to_tensor(init_hidden_data)init_hidden.stop_gradient = Trueinit_cell = paddle.to_tensor(init_cell_data)init_cell.stop_gradient = True# 对应以上第2步,将输入的句子的mini-batch转换为词向量表示,转换后输入数据shape为[batch_size, max_seq_len, embedding_size]x_emb = self.embedding(inputs)x_emb = paddle.reshape(x_emb, shape=[-1, self.num_steps, self.embedding_size])# 在获取的词向量后添加dropout层if self.dropout_rate is not None and self.dropout_rate > 0.0:x_emb = self.dropout_layer(x_emb)# 对应以上第3步,使用LSTM网络,把每个句子转换为语义向量# 返回的last_hidden即为最后一个时间步的输出,其shape为[self.num_layers, batch_size, hidden_size]rnn_out, (last_hidden, last_cell) = self.simple_lstm_rnn(x_emb, (init_hidden, init_cell))# 提取最后一层隐状态作为文本的语义向量,其shape为[batch_size, hidden_size]last_hidden = paddle.reshape(last_hidden[-1], shape=[-1, self.hidden_size])# 对应以上第4步,将每个句子的向量表示映射到具体的情感类别上, logits的维度为[batch_size, 2]logits = self.cls_fc(last_hidden)return logits2.3 训练配置
本节将定义模型训练时用到的一些组件和资源,包括定义模型的实例化对象,选择模型训练和或评估时需要使用的计算资源(CPU或者GPU),指定模型训练迭代的优化算法。 其中,本节实验将默认使用GPU进行训练,通过调用 paddle.get_device() 来查看当前实验环境是否有GPU可用,优先使用GPU进行训练。
paddle.get_device()
- 该功能返回当前程序运行的全局设备,返回的是一个类似于 cpu 或者 gpu:0 字符串,如果没有设置全局设备,当cuda可用的时候返回 gpu:0 ,当cuda不可用的时候返回 cpu 。
另外,本实验将使用 paddle.optimizer.Adam() 算法进行模型迭代优化。
class paddle.optimizer.Adam(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, parameters=None, weight_decay=None, grad_clip=None, name=None, lazy_mode=False)
关键参数含义如下:
- learning_rate (float|_LRScheduler) - 学习率,用于参数更新的计算。可以是一个浮点型值或者一个_LRScheduler类,默认值为0.001
- beta1 (float|Tensor, 可选) - 一阶矩估计的指数衰减率,是一个float类型或者一个shape为[1],数据类型为float32的Tensor类型。默认值为0.9
- beta2 (float|Tensor, 可选) - 二阶矩估计的指数衰减率,是一个float类型或者一个shape为[1],数据类型为float32的Tensor类型。默认值为0.999
- epsilon (float, 可选) - 保持数值稳定性的短浮点类型值,默认值为1e-08
- parameters (list, 可选) - 指定优化器需要优化的参数。
- weight_decay (float|WeightDecayRegularizer,可选) - 正则化方法。
- grad_clip (GradientClipBase, 可选) – 梯度裁剪的策略。 默认值为None,此时将不进行梯度裁剪。
- name (str, 可选)- 该参数供开发人员打印调试信息时使用,具体用法请参见 Name ,默认值为None
- lazy_mode (bool, 可选) - 设为True时,仅更新当前具有梯度的元素。
训练配置的代码如下:
# 定义训练参数
epoch_num = 5
batch_size = 128learning_rate = 0.01
dropout_rate = 0.2
num_layers = 1
hidden_size = 256
embedding_size = 256
max_seq_len = 128
vocab_size = len(word2id_freq)# 检测是否可以使用GPU,如果可以优先使用GPU
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:paddle.set_device('gpu:0')# 实例化模型
sentiment_classifier = SentimentClassifier(hidden_size, vocab_size, embedding_size, num_steps=max_seq_len, num_layers=num_layers, dropout_rate=dropout_rate)# 指定优化策略,更新模型参数
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, beta1=0.9, beta2=0.999, parameters= sentiment_classifier.parameters()) W0414 16:53:49.788056 99 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0414 16:53:49.800664 99 device_context.cc:372] device: 0, cuDNN Version: 7.6.
2.4 模型训练
2.4.1 训练过程
上文已经实现了模型结构,并且完成了训练的配置,接下来就可以开始训练模型了。在训练过程中,可以分为四个步骤:获取数据、传入模型进行前向计算、反向传播和参数更新。训练过程中的每次迭代基本都是在循环往复地执行这四个步骤。具体的模型训练代码如下:
# 记录训练过程中的损失变化情况,可用于后续画图查看训练情况
losses = []
steps = []def train(model):# 开启模型训练模式model.train()# 建立训练数据生成器,每次迭代生成一个batch,每个batch包含训练文本和文本对应的情感标签train_generator = build_batch(word2id_dict, train_set, batch_size, epoch_num, max_seq_len)for step, (sentences, labels) in enumerate(train_generator):# 获取数据,并将张量转换为Tensor类型sentences = paddle.to_tensor(sentences)labels = paddle.to_tensor(labels)# 前向计算,将数据feed进模型,并得到预测的情感标签和损失logits = model(sentences)# 计算损失loss = F.cross_entropy(input=logits, label=labels, soft_label=False)loss = paddle.mean(loss)# 后向传播loss.backward()# 更新参数optimizer.step()# 清除梯度optimizer.clear_grad()if step % 100 == 0:# 记录当前步骤的loss变化情况losses.append(loss.numpy()[0])steps.append(step)# 打印当前loss数值print("step %d, loss %.3f" % (step, loss.numpy()[0]))train(sentiment_classifier)step 0, loss 0.694 step 100, loss 0.696 step 200, loss 0.477 step 300, loss 0.368 step 400, loss 0.093 step 500, loss 0.072 step 600, loss 0.008 step 700, loss 0.004 step 800, loss 0.007 step 900, loss 0.021
2.4.2 训练可视化
训练过程中,每隔100 steps记录一下loss值,图9 展示了这些loss变化的情况,其中纵轴代表loss数值,横轴代表训练的step。整体来看,loss随着训练步数的增加而不断下降,最终平稳,这说明本次实验中模型的训练是有效的。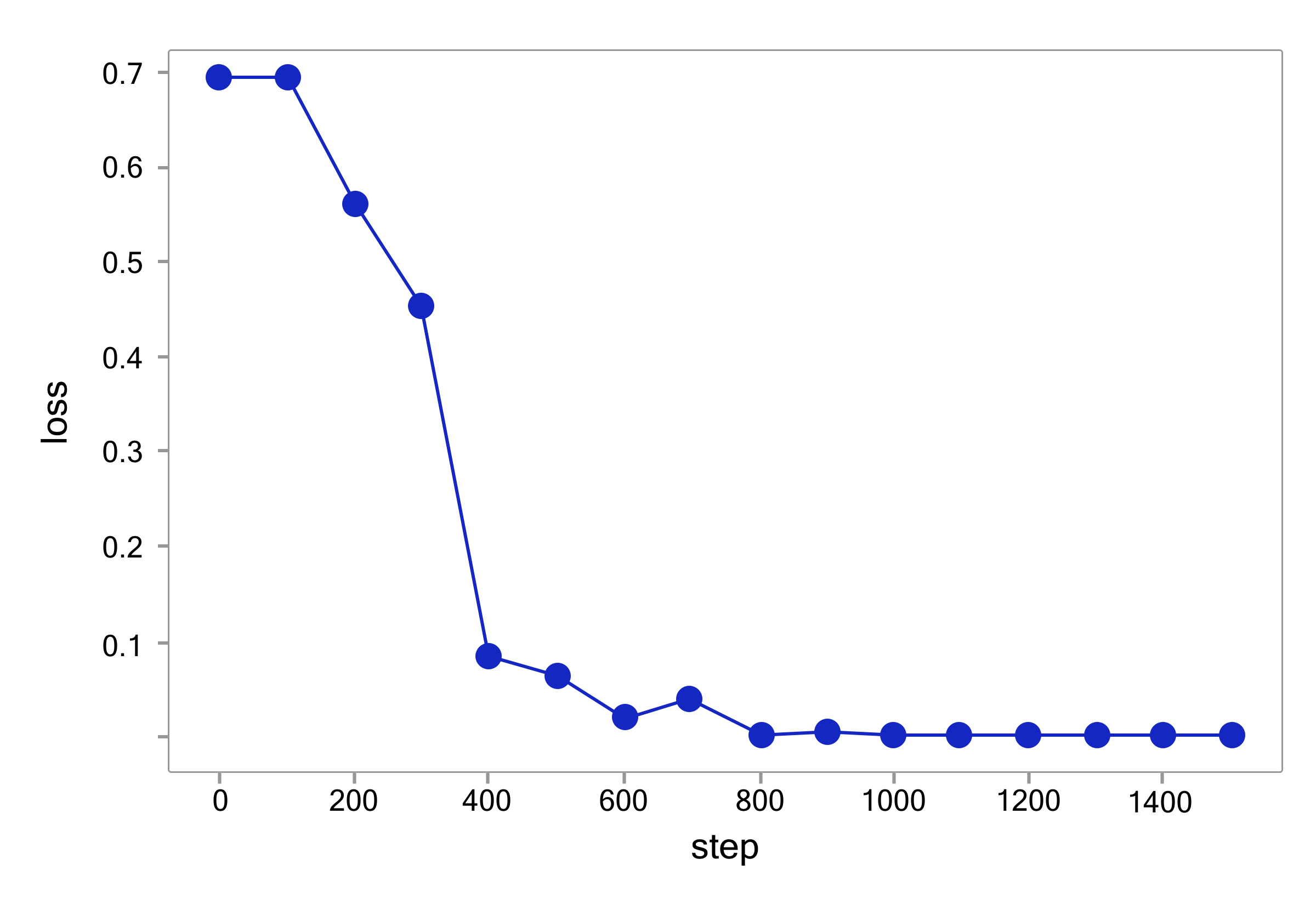
图9 训练过程中loss变化图
根据loss数值画图的代码如下:
import matplotlib.pyplot as plt# 开始画图,横轴是训练step,纵轴是损失
plt.plot(steps, losses, "-o")
plt.xlabel("step")
plt.ylabel("loss")
plt.savefig("./loss.png")/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingfrom collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingfrom collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingfrom collections import Sized 2022-04-14 16:54:39,166 - INFO - font search path ['/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/afm', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts'] 2022-04-14 16:54:39,656 - INFO - generated new fontManager /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingif isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingreturn list(data) if isinstance(data, collections.MappingView) else data
2.5 模型保存
在模型训练完成后,需要将模型和优化器参数保存到磁盘,用于模型推理或继续训练。保存模型的代码如下,通过paddle.save API实现模型参数和优化器参数的保存。
model_name = "sentiment_classifier"# 保存训练好的模型参数
paddle.save(sentiment_classifier.state_dict(), "{}.pdparams".format(model_name))
# 保存优化器参数,方便后续模型继续训练
paddle.save(optimizer.state_dict(), "{}.pdopt".format(model_name))2.6 模型评估
在模型训练完成后,需要使用测试集对模型进行评估,验证模型效果。首先需要加载训练好的模型,然后就可以开始测试模型了。具体地,先以batch的形式获取测试数据,然后传入模型进行前向计算,最后根据模型计算得出的情感分类标签统计结果。
本节将采用一个混淆矩阵的方式统计结果,混淆矩阵是用来统计分类结果的分析表,如下图所示,它根据测试集真实的类别和模型预测的类别进行汇总,共可以分为如下四种情况:
- 真正例(Ture Positive):样本的真实标签是正例,模型预测结果也是正例,简称TP
- 假正例(False Positive):样本的真实标签是反例,模型预测结果却是正例,简称FP
- 真反例(True Negative):样本的真实标签是反例,模型预测结果也是反例,简称TN
- 假反例(False Negative):样本的真实标签是正例,模型预测结果却是反例,简称FN
以上四种情况中,TP和TN代表模型预测对的结果,FP和FN代表模型预测错误的结果,可以通过这四个指标大小判断模型训练的效果。另外还可以根据这几个统计值计算模型的整体准确率:accuracy = (TP+TN)/(TP+FP+TN+FN)
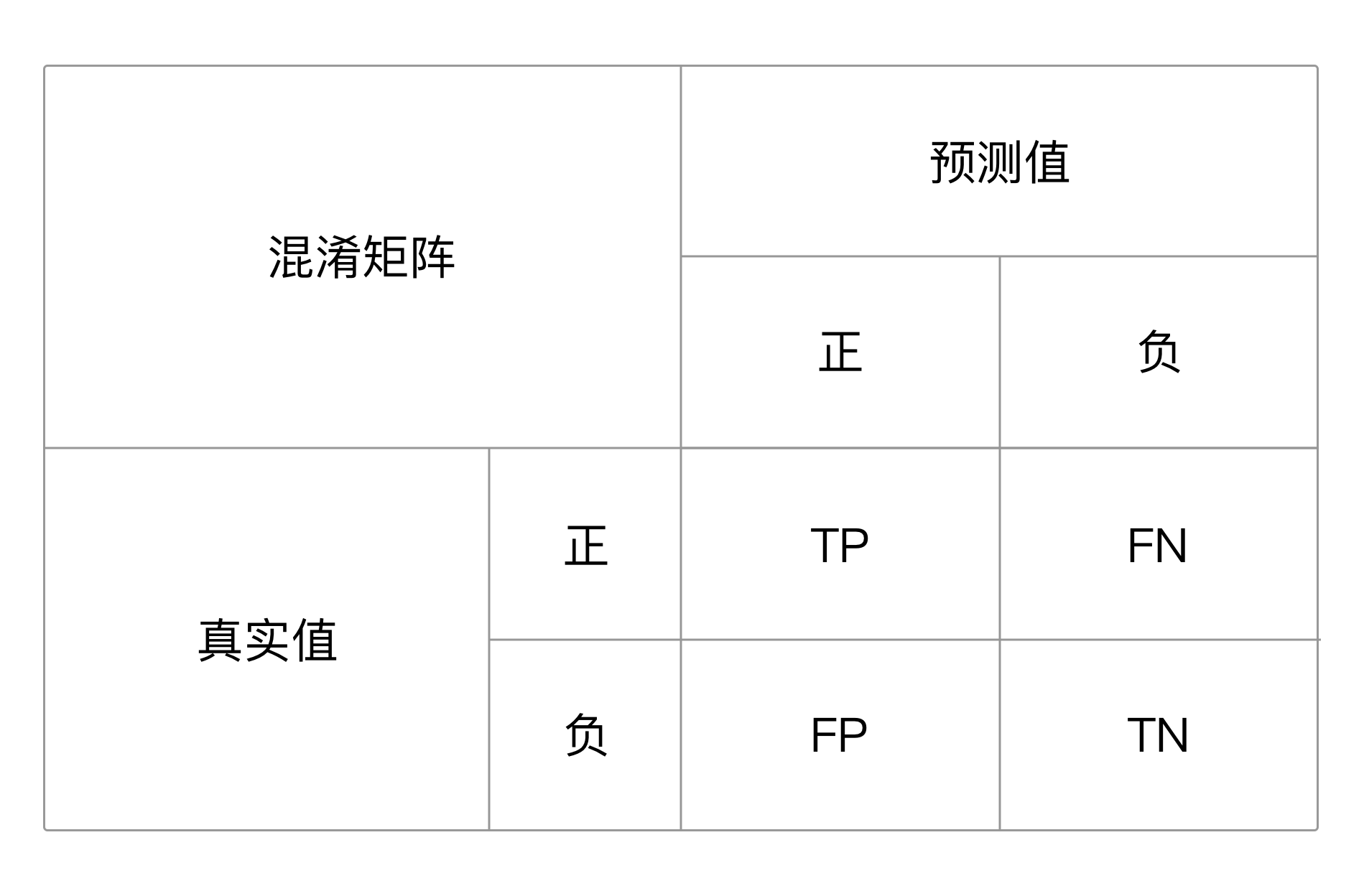
图10 混淆矩阵
在本实验中,假设将积极的样本视为正例,消极的样本视为负例,那就可以根据混淆矩阵进行统计结果了。从上节可以得知,模型输出的标签是个[batch_size, 2]的矩阵,是经过softmax后的结果,前一列代表相应样本是负例的概率,后一列代表是正例的概率,两者之和为1。对于一个样本,如果正例的概率大于反例的概率,这代表模型预测结果是正例,否则是反例。具体的模型评估代码如下:
def evaluate(model):# 开启模型测试模式,在该模式下,网络不会进行梯度更新model.eval()# 定义以上几个统计指标tp, tn, fp, fn = 0, 0, 0, 0# 构造测试数据生成器test_generator = build_batch(word2id_dict, test_set, batch_size, 1, max_seq_len)for sentences, labels in test_generator:# 将张量转换为Tensor类型sentences = paddle.to_tensor(sentences)labels = paddle.to_tensor(labels)# 获取模型对当前batch的输出结果logits = model(sentences)# 使用softmax进行归一化probs = F.softmax(logits)# 把输出结果转换为numpy array数组,比较预测结果和对应label之间的关系,并更新tp,tn,fp和fnprobs = probs.numpy()for i in range(len(probs)):# 当样本是的真实标签是正例if labels[i][0] == 1:# 模型预测是正例if probs[i][1] > probs[i][0]:tp += 1# 模型预测是负例else:fn += 1# 当样本的真实标签是负例else:# 模型预测是正例if probs[i][1] > probs[i][0]:fp += 1# 模型预测是负例else:tn += 1# 整体准确率accuracy = (tp + tn) / (tp + tn + fp + fn)# 输出最终评估的模型效果print("TP: {}\nFP: {}\nTN: {}\nFN: {}\n".format(tp, fp, tn, fn))print("Accuracy: %.4f" % accuracy)# 加载训练好的模型进行预测,重新实例化一个模型,然后将训练好的模型参数加载到新模型里面
saved_state = paddle.load("./sentiment_classifier.pdparams")
sentiment_classifier = SentimentClassifier(hidden_size, vocab_size, embedding_size, num_steps=max_seq_len, num_layers=num_layers, dropout_rate=dropout_rate)
sentiment_classifier.load_dict(saved_state)# 评估模型
evaluate(sentiment_classifier)TP: 8938 FP: 2324 TN: 10156 FN: 3542 Accuracy: 0.7650
2.7 模型推理
任意输入一个电影评论方面的文本,如:“this movie is so wonderful. I watched it three times”,通过模型推理验证模型训练效果,实现代码如下。
# 模型预测代码
def infer(model, text):model.eval()# 数据处理sentence = text.split(" ")tokens = [word2id_dict[word] if word in word2id_dict \else word2id_dict['[oov]'] for word in sentence] # 截断或者填充序列到tokens = tokens[:max_seq_len]tokens = tokens+[word2id_dict['[pad]']]*(max_seq_len-len(tokens))# 构造输入模型的数据tokens = paddle.to_tensor(tokens, dtype="int64").unsqueeze(0)# 计算发射分数logits = model(tokens)probs = F.softmax(logits)# # 解析出分数最大的标签id2label={0:"消极情绪", 1:"积极情绪"}max_label_id = paddle.argmax(logits, axis=1).numpy()[0]pred_label = id2label[max_label_id]print("Label: ", pred_label)title = "this movie is so great. I watched it three times already"
infer(sentiment_classifier, title)Label: 积极情绪
3. 实验总结
本实验基于长短时记忆网络LSTM实现了IMDB电影评论的情感分析模型。通过本实验掌握了通过飞桨实现电影评论情感分析任务实验流程。大家可以在此实验的基础上,尝试开发对电商商品评论的情感分析模型。

![ElasticSearch扫盲概念篇[ES系列] - 第500篇](https://img-blog.csdnimg.cn/img_convert/aba21b37d7995dfb8a954ef15ed02eda.jpeg)