键盘输入
实现使用的设备
intel架构32位CPU, 思路为嵌入式系统工程师,使用的操作系统是《30天自制操作系统》里面的系统进行讲解
硬件实现
按键
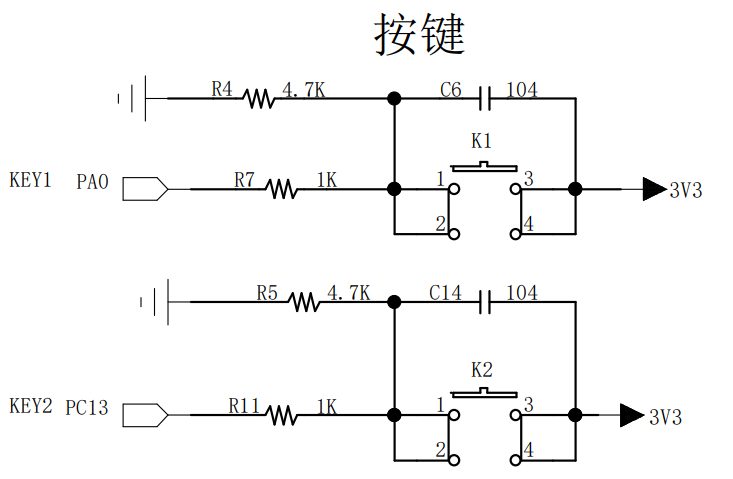
使用单片机等的引脚可以获取电平状态从而获得按键的状态(单片机是一种集成到一块硅片上构成的一个小而完善的微型计算机系统, 用在一些不需要很高的性能的地方, 比如遥控器, 手表等)
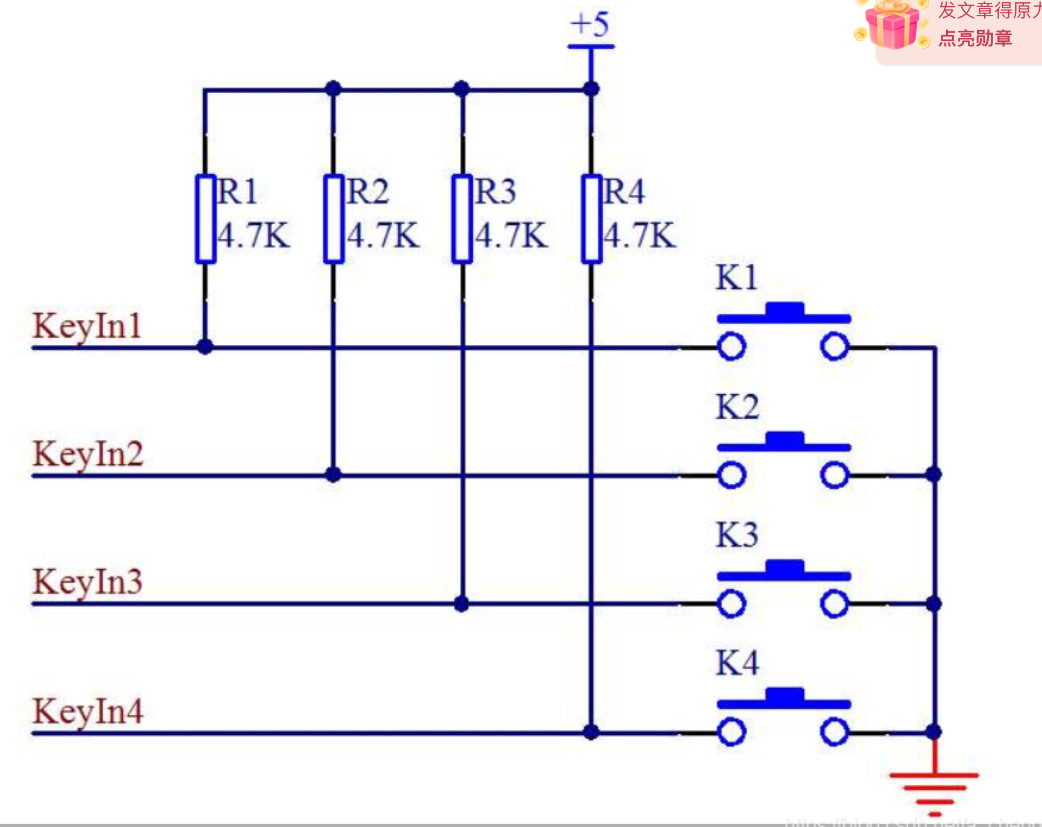

一般使用轮询的方式获取矩阵键盘上面的按键的状态
例: 在上方第一个端口通高电平同时检测右侧四个端口, 这时候如果某一个端口为低电平表示按键按下, 检测之后再在上侧端口2进行通电然后检测, 以此类推, 快速循环即可获得按键状态
单片机的速度很快, 所以你看来就会认为这些按键是同时检测的

实际的键盘原理图(稚晖君作品), 会加入一些其他的处理
如何让电脑识别为键盘
电脑识别按钮为键盘按键
- 获取到的信号会通过USB HID协议传输到电脑, 从调试数据分析USB通信协议——USB键盘鼠标【HID类设备】(四)_usb键盘协议-CSDN博客, 由于USB协议很复杂不过多讲解, 感兴趣同学自行了解(可以直接使用现成的键盘驱动板)
- 电脑采集信号后使用软件进行转化, 例如通过串口发送一个数据, 电脑上启动一个程序, 接收到这个数据以后就会转化为对应的按键
import pyautogui if(按键按下)# 模拟按下'A'键pyautogui.press('a')# 模拟按下组合键Ctrl+Cpyautogui.hotkey('ctrl', 'c')
- Linux在设备树上面添加节点时候进行设置(在操作系统中进行专门设置)
- …
注: 以下解释的是使用USB进行通讯的方式
软件
一般来说电脑的硬件会自带一些处理的设备, 我们不需要关心底层的时序, 只需要对处理过的信息进行采集就行了
不同情况下获取按键的状态的方式
- 方式1使用BIOS(16位模式), 在电脑刚上电的时候没有加载操作系统时候使用, 类似于C语言函数的调用
; 相当于int get_status(int data);
MOV AH,0x02 ;设置参数, 把参数保存在AH寄存器里面
INT 0x16 ; 调用BIOS函数获取状态,使用的是16号函数
MOV [LEDS],AL ; 进行存储, 返回的信息保存在AL寄存器里面
这里的AL, AH等是Intel架构下面的寄存器, 是一块可以和CPU的速度相匹配的内存, 用于在计算机计算的时候暂时保存数据
这一个调用主要用于获取键盘的指示灯的状态(大小写切换等)
BIOS: 可以理解为一个固定在主板上面的程序, 帮助初始化一些内容, 在电脑刚上电的时候使用的是16位的模式, 需要在初始化一些内容以后切换为32位模式, 这样做的主要目的是兼容之前的CPU
在示例使用的系统中此时候读取的信息会被记录, 用于之后的按键输入判断
- 其他时候获取按键的按下情况(32位), 使用汇编指令读取对应的端口获取信息
_io_in8: ; int io_in8(int port);实际调用的时候相当于这一个C语言代码调用;传入读取的端口, 返回读取到的值MOV EDX,[ESP+4] ; port, 从栈中获取传进来的参数MOV EAX,0 ;对于另一个参数进行设置IN AL,DX ;使用IN汇编指令对对应的端口进行读取, EAX会保存返回值RET_io_out8: ; void io_out8(int port, int data);MOV EDX,[ESP+4] ; portMOV AL,[ESP+8] ; dataOUT DX,AL ; 向DX保存的端口写入AL的数值RET
使用的两个外设端口读取的函数, 一般会在中断中进行调用, 检测是哪一个按键按下
中断

中断发生后, 原先的程序执行会被打断, 之后CPU会检查发生的是哪一个中断, 从中断向量表中获取到对应的处理函数, 跳转到对应的函数进行执行
中断向量表: 可以理解一个记录有各个中断处理函数的数组, CPU会根据发生的中断的编号到对应的位置进行查找对应的处理函数
Intel使用的中断处理使用的是PIC(这里不进行过多解释)一文读懂多架构的中断控制器 - 知乎 (zhihu.com)
_asm_inthandler21:PUSH ESPUSH DSPUSHADMOV EAX,ESPPUSH EAX ;对使用的寄存器保存数据, 防止中断返回的时候程序无法正常运行MOV AX,SS MOV DS,AX MOV ES,AX ;准备C语言需要的环境(这几个段寄存的数值要求一样)CALL _inthandler21 ; 调用实际的处理函数POP EAX ;复原使用的寄存器POPADPOP DSPOP ESIRETD
中断发生后会自动运行这一个函数(地址保存在中断向量表里面), 我们需要在里面进行中断事件的处理
首先需要将之前程序运行的状态保存在栈里面, 之后调用对键盘数据的读取函数
这里使用的PUSH以及POP指令是对于栈的操作
栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。使用这一种结构对数据进行保存, 在调用其他函数之间会将数据入栈, 返回以后出栈
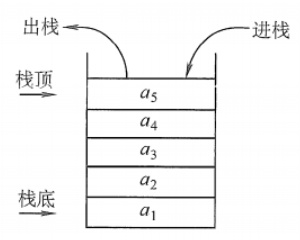
void inthandler21(int *esp)
{int data;io_out8(PIC0_OCW2, 0x61); /* IRQ-01接收完毕的通知 */data = io_in8(PORT_KEYDAT); //向键盘端口发送一个信号fifo32_put(keyfifo, data + keydata0); //从键盘的端口获取一个键盘的数据,之后保存起来return;
}
实际的中断处理函数
多按键先后输入处理
由于可能在短时间内有多个按键进行输入, 事件短于处理函数, 所以使用FIFO(First in First out)的数据结构对传入的数据进行存储(实际的操作系统中用来进行多个事件先后的处理)
/* fifo.c */
struct FIFO8 {unsigned char *buf; //一个数组, 实际数据存储的位置int p, q, size, free, flags; //记录读指针, 写指针以及总大小, 剩余空间, 是否初始化的标志
};
实际的C语言实现

具体实现的代码(仅参考不进行讲解)
/* FIFO实现 */#include "bootpack.h"#define FLAGS_OVERRUN 0x0001void fifo8_init(struct FIFO8 *fifo, int size, unsigned char *buf)
/* FIFO的初始化 */
{fifo->size = size;fifo->buf = buf;fifo->free = size; /* 为空 */fifo->flags = 0;fifo->p = 0; /* 写指针记录初为始位置 */fifo->q = 0; /* 读指针记录为初始位置 */return;
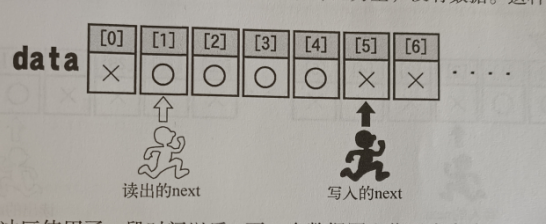
}int fifo8_put(struct FIFO8 *fifo, unsigned char data)
/* FIFO写入一个数据 */
{if (fifo->free == 0) {/* 没有位置进行写入了 */fifo->flags |= FLAGS_OVERRUN;return -1;}fifo->buf[fifo->p] = data;fifo->p++;if (fifo->p == fifo->size) {fifo->p = 0;}fifo->free--;return 0;
}int fifo8_get(struct FIFO8 *fifo)
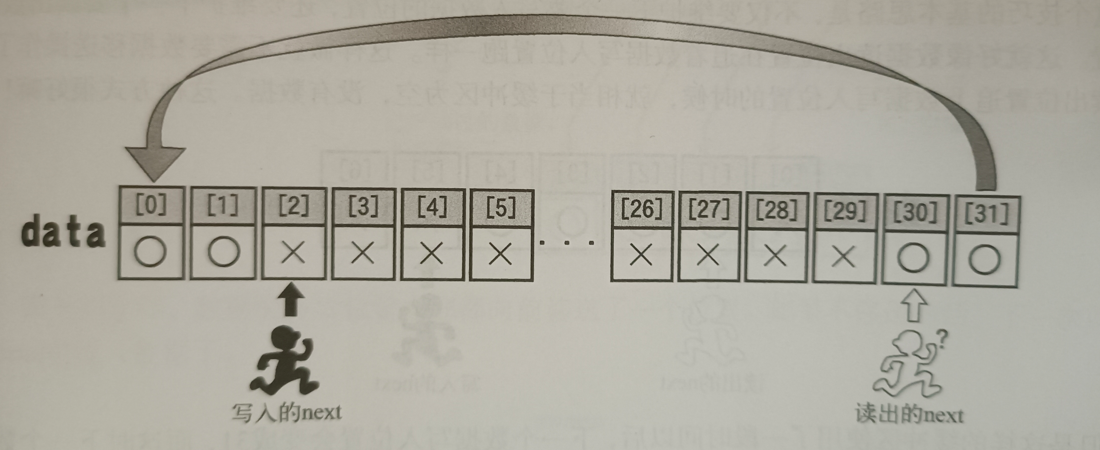
/* FIFO获取一个数据 */
{int data;if (fifo->free == fifo->size) {/* 没有可以获取的数据 */return -1;}data = fifo->buf[fifo->q];fifo->q++;if (fifo->q == fifo->size) {fifo->q = 0;}fifo->free++;return data;
}int fifo8_status(struct FIFO8 *fifo)
/* 获取当前没有读取的数量数据 */
{return fifo->size - fifo->free;
}
信号的处理
- 在中断中获取信号
- 对信号进行解析
使用按键数值表进行获取实际按下的按键
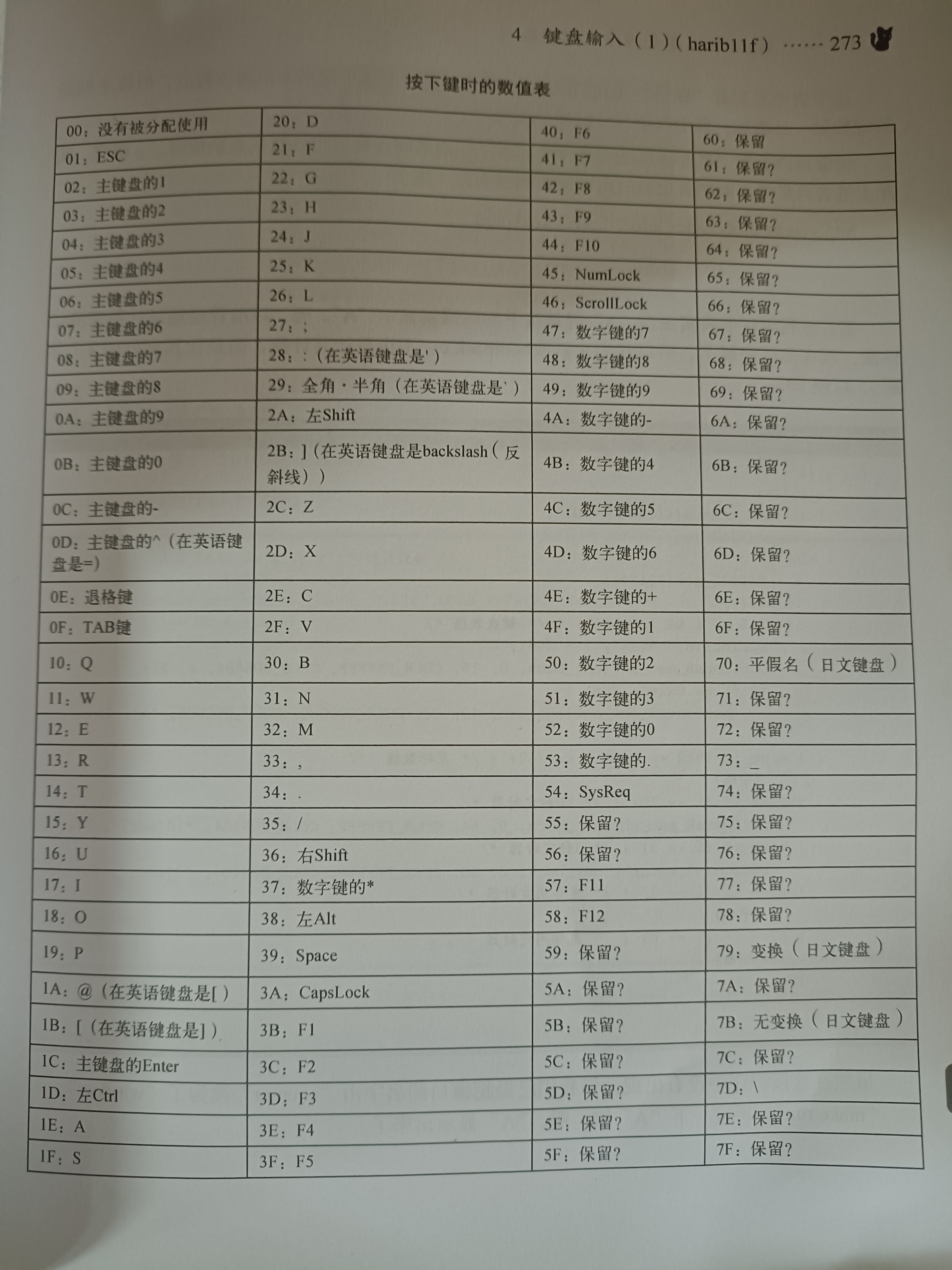
系统需要做的就是回上面的信息进行处理
static char keytable0[0x80] = { 0, 0, '1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '-', '^', 0, 0, 'Q', 'W', 'E', 'R', 'T', 'Y', 'U', 'I', 'O', 'P', '@', '[', 0, 0, 'A', 'S', 'D', 'F', 'G', 'H', 'J', 'K', 'L', ';', ':', 0, 0, ']', 'Z', 'X', 'C', 'V', 'B', 'N', 'M', ',', '.', '/', 0, '*', 0, ' ', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, '7', '8', '9', '-', '4', '5', '6', '+', '1', '2', '3', '0', '.', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0x5c, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0x5c, 0, 0 }; static char keytable1[0x80] = { 0, 0, '!', 0x22, '#', '$', '%', '&', 0x27, '(', ')', '~', '=', '~', 0, 0, 'Q', 'W', 'E', 'R', 'T', 'Y', 'U', 'I', 'O', 'P', '`', '{', 0, 0, 'A', 'S', 'D', 'F', 'G', 'H', 'J', 'K', 'L', '+', '*', 0, 0, '}', 'Z', 'X', 'C', 'V', 'B', 'N', 'M', '<', '>', '?', 0, '*', 0, ' ', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, '7', '8', '9', '-', '4', '5', '6', '+', '1', '2', '3', '0', '.', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, '_', 0, 0, 0, 0, 0, 0, 0, 0, 0, '|', 0, 0 };使用两个数组对这些数据进行判断, 有两组的原因是, 在Shift和Capslock状态不同的输入的数据是不同的
- 处理
- 对于普通的按键获取到实际的按键数值, 之后系统进行处理或者传递给应用
- 对于切换状态的按键, 对之前保存的状态进行切换, 在之后的输入的时候对事件进行处理
实际按键的处理函数(修改版)
//key_shift等是全局变量, 用来保存一些按键是不是按下了
i = fifo8_get($Key_FIFO); //获取一个按键
if (i < 0x80) { /* 判断输入的是什么 */if (key_shift == 0) {//判断shift按键的状态, 进而获取实际输入的字符//获取字母以及数字s[0] = keytable0[i];} else {//获取字母以及标点符号s[0] = keytable1[i];}
} else {s[0] = 0;
}
if ('A' <= s[0] && s[0] <= 'Z') { /* 分析输入的文字 */if (((key_leds & 4) == 0 && key_shift == 0) ||((key_leds & 4) != 0 && key_shift != 0)) {s[0] += 0x20; /* 大小写字母的换算 */}
}
if (s[0] != 0 && key_win != 0) { /* 通常文字、显示文字的窗口存在、Enter *///对于任务存在时候发送数据到任务...
}
if (i == 0x0f && key_win != 0) { /* Tab *///某个按键有特殊作用时候单独处理...
}
//状态类的按键的处理
if (i == 0x2a) { /* 左侧Shift ON */key_shift |= 1;
}
....if (i == 0x45) { /* NumLock */...
}
//组合键的处理
if (i == 0x3b && key_shift != 0 && key_win != 0) { /* Shift+F1 */...
}
文字的显示
- 字符编码
ASCII只有255个字符并且只能显示英文, 中文也有自己的字符编码
补充常用的中文字符集
GB2312: 兼容ASCII前127位, 两个大于127的数字连用表示一个汉字, 一共有八千多个符号, 包含6763个汉字, ASCII之中的的有的也是用两个字节进行编码, 叫做全角, 一般使用半角, 一般使用0xa1开始表示
GBK: 在GB2312的基础上增加了14240个新的汉字, 由于原来的格式原来的格式已经存放不下, 所以要求第一个编码大于127就可以了
GB18030: 在GBK上面进一步扩展, 第二个字节未使用的0x30-0x39编码表示扩充为四个字节, 兼容前几个, 只要增加了中日韩统一汉字编码扩充
Unicode: 各个国家制作的统一的字符集, 兼容ASCII, 还有一些表情emoji, 只是进行编号, 没有进行编码, 就是只是用一个数字代表一个字符, 但是没有使用具体的电脑解析的规范
utf-32: 编码和编号一样, 每一个字符使用4个字节进行表示, 前面的0不能省略, 会导致ASCII等编码变长
utf-16: 使用两个或者四个字节进行编写, 由于发现Unicode没有使用0xD800到0xDBFF所以利用这片空间表示映射 , 使用这一空间达到变长的目的
utf-8: 网页上使用的比较多, 也是一种变长的编码格式, 第一位设置为0, 就可以兼容ASCII的0-127, 其他的字符, 两个字节的时候第一个字节使用110开头, 第二个字节使用10开头, 三个字节的时候会使用1110开头, 之后是使用10开头, 以此类推, 将Unicode编码填入空位, 从最后一个字节开始填写, 不够的在前面加0
具体获取你输入的是哪一个字符是输入软件的工作
- 字模数据
只有数字编码你只知道这是某一个汉字, 但是这个字是怎么显示的呢?
实际上字符可以是一个图形, 可以保存在内存中, 记录了每一个像素的显示
使用取模软件获取一个字符的字模
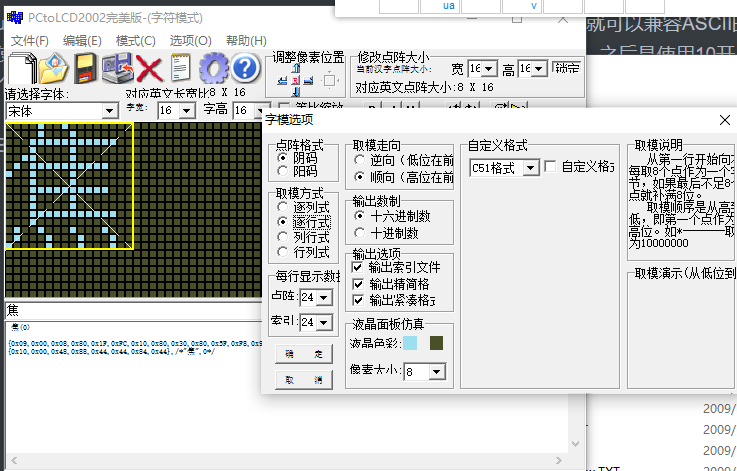
使用这个软件进行生成,
GB2312: Addr = (((CodeH - 0xA0-1)*94)+(CodeL - 0xA0 -1))*16*16/8
焦(0)
{0x09,0x00,0x08,0x80,0x1F,0xFC,0x10,0x80,0x30,0x80,0x5F,0xF8,0x90,0x80,0x10,0x80,0x1F,0xF8,0x10,0x80,0x10,0x80,0x1F,0xFC},
{0x10,0x00,0x48,0x88,0x44,0x44,0x84,0x44},/*"焦",0*/
0x09 => 0000 1001 0x00 => 0000 0000
详细讲解: 【单片机】野火STM32F103教学视频 (配套霸道/指南者/MINI)【全】(刘火良老师出品) (无字幕)-虚神疯-稍后再看-哔哩哔哩视频 (bilibili.com)
编码和字模数据的使用关系, 一般会可以按照字符编码的顺序进行保存字模数据, 在之后进行显示的时候按照字符编码对对应的字模数据进行寻找, 可以使用这个软件进行生成
**注: **之后使用的时候可以按照字符编码进行一些运算以后在字模表里面寻找对应的字模
- 示例GB2312的解析
实际使用的编码位是0xA1A1-FEFE, 汉字的区域是B0A1-F7FE, 原因是为了兼容ASCII, 最高位为1, 并且预留0x20个控制位
GB2312编码对收录的字符进行分区, 分为94个区, 每一个区有94个位, 一共有8836个码位
第16个区开始是汉字, 0-9是682个汉字以外的字符
10-15是空白区域没有使用
16-55是一级汉字, 按照拼音进行排序
56-87区收录3008个二级汉字, 按照部首进行排序
88-94是空白区没有使用
实际使用的时候就是: 区码加位码+A0A0, 比如’‘啊’'是16区第一个, 就是0x1001+0xA0A0
实际在使用字模库的时候由于没有进行兼容偏移, 所以使用的是字符的在总个数的排序
Addr = (((ColdH - 0xA0 - 1)* 94) + (CodeL - 0xA0-1))*32*32/8
Addr 地址偏移
CodeH区码
CodeL位码
32: 字模的长和宽
- 显存
一块用于记录屏幕信息的内存, 直接堆内存进行读写就可以控制一块屏幕的显示
此模式下使用8位表示一个像素的颜色
由于8只能表示255种颜色=>使用色盘(一个保存颜色的数组, 比如0位置保存红色, 我向显存写入0之后会先从色盘获取红色, 然后把红色显示在对应的像素上面)
void putfont8(char *vram, int xsize, int x, int y, char c, char *font)
{//参数1: 显存的位置//参数2: 屏幕的宽度//参数3,4: 显示的位置//参数5: 显示的颜色//参数6: 显示的字的字模int i;char *p, d /* data */;for (i = 0; i < 16; i++) {p = vram + (y + i) * xsize + x;//计算某一行数据的实际对应的显存位置d = font[i]; //获取某一行的字模if ((d & 0x80) != 0) { p[0] = c; } //按照字模数据依次写入对应的显存if ((d & 0x40) != 0) { p[1] = c; }if ((d & 0x20) != 0) { p[2] = c; }if ((d & 0x10) != 0) { p[3] = c; }if ((d & 0x08) != 0) { p[4] = c; }if ((d & 0x04) != 0) { p[5] = c; }if ((d & 0x02) != 0) { p[6] = c; }if ((d & 0x01) != 0) { p[7] = c; }}return;
}
通过循环获取字模的每一个位, 之后通过这一个位的保存的数据进行判断对显存写入的颜色
显示总结(官方术语)
外码=>内码=> 交换码=>字形码
外码: 输入码, 平常键盘拼音输入的字母, 是一个索引码
内码: 计算机存储的二进制, 输入的汉字要转化为二进制形式, 集合叫做字符集
交换码: 国标码, 和别的计算机交换信息的时候使用的编码
字形码: 汉字字模, 二进制转化为可视化的图形, 集合叫做字库
实际效果演示
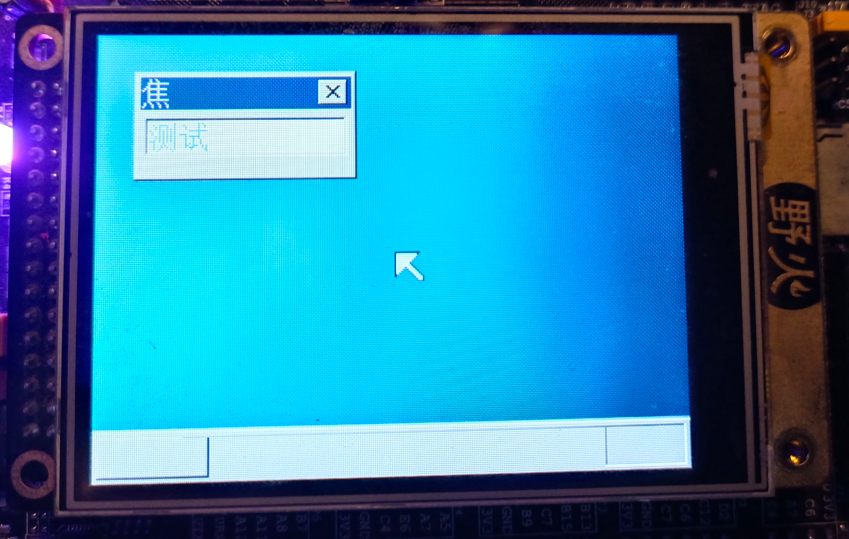
上面使用的操作系统没有保存照片, 使用一个我写的嵌入式操作系统展示字符显示的结果(由上述操作系统移植过来的ARM架构下的图形化操作系统)
XuSenfeng/jiaoOS: 一个基于stm32f103的图形化操作系统 (github.com)
总结
- 读取按键是否按下
- 将按键的信号传递给电脑
- 电脑对信号进行处理获得输入的数据
- 将信号显示在屏幕上
版权补充
引用资料:
- peng-zhihui/HelloWord-Keyboard (github.com)稚晖君翰文键盘部分图纸
- 《30天自制操作系统》部分代码
- 自制17键数字机械键盘(2)——电路原理图及PCB设计、元器件焊接 - 知乎 (zhihu.com)
- XuSenfeng (github.com)我自己的笔记
- 野火stm32相关教程
其他资料
Expanded Main Page - OSDev Wiki
intel编程手册
XuSenfeng (github.com)