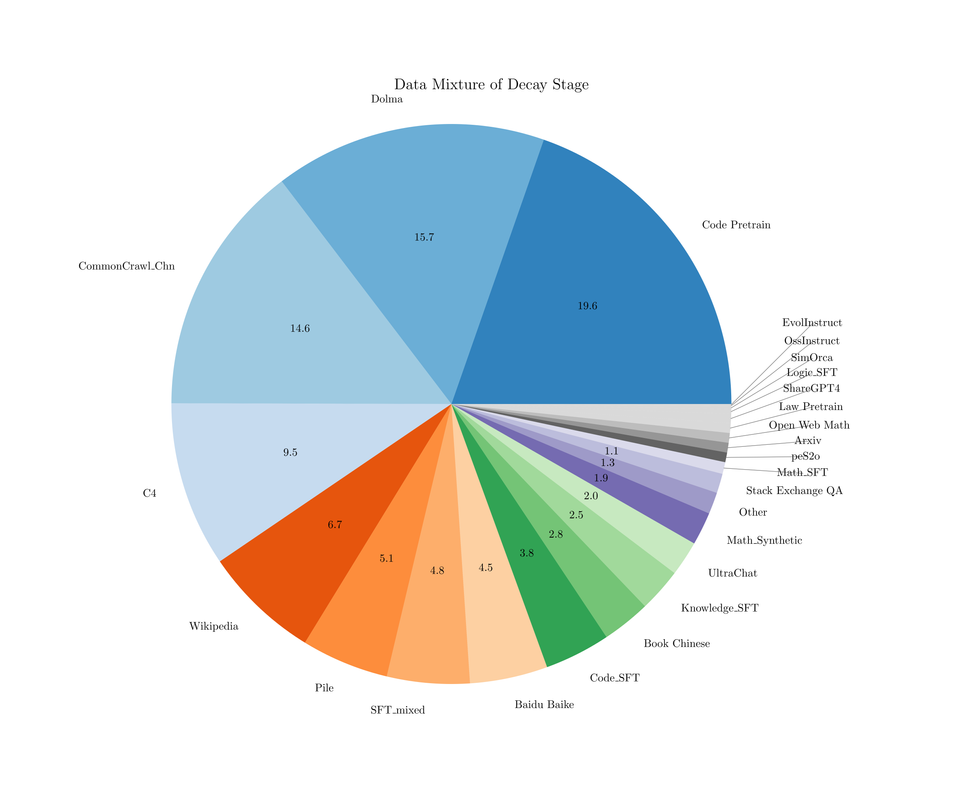
文章目录
- 7.1 识别和应对 CAPTCHA
- 7.1.1 重点基础知识讲解
- 7.1.2 重点案例:使用Tesseract OCR识别简单CAPTCHA
- 7.1.3 拓展案例 1:使用深度学习模型识别复杂CAPTCHA
- 7.1.4 拓展案例 2:集成第三方 CAPTCHA 解决服务
- 7.2 IP 轮换与代理的使用
- 7.2.1 重点基础知识讲解
- 7.2.2 重点案例:使用 requests 库与代理 IP 进行数据抓取
- 7.2.3 拓展案例 1:结合 Scrapy 和 Scrapy-Redis 使用代理
- 7.2.4 拓展案例 2:自动切换代理 IP
- 7.3 用户代理和 Cookie 的管理
- 7.3.1 重点基础知识讲解
- 7.3.2 重点案例:使用 requests 库设置用户代理和 Cookie
- 7.3.3 拓展案例 1:动态更换用户代理
- 7.3.4 拓展案例 2:使用 session 对象管理 Cookie
7.1 识别和应对 CAPTCHA
在爬虫的世界里,CAPTCHA(全自动区分计算机和人类的公开图灵测试)像是一道守护网站不被自动化工具侵扰的魔法屏障。但对于执着于获取数据的我们来说,总有几种方法可以尝试绕过这个障碍。
7.1.1 重点基础知识讲解
- OCR(光学字符识别):OCR技术可以识别图片中的文字,对于一些简单的文字型CAPTCHA,使用OCR可能直接破解。
- 人工智能模型:近年来,随着深度学习技术的发展,一些训练有素的模型能够识别更加复杂的CAPTCHA图像。
- 第三方解决方案:存在一些服务,如Anti-Captcha、2Captcha等,提供了API接口,可以代替人工识别CAPTCHA。
- 手动输入:在一些情况下,如果CAPTCHA识别不是频繁的需求,简单直接的方法就是手动输入。
7.1.2 重点案例:使用Tesseract OCR识别简单CAPTCHA
假设你遇到了一个使用简单数字和字母组合的CAPTCHA,我们可以使用Tesseract OCR来尝试自动识别。
from PIL import Image
import pytesseract
import requests
from io import BytesIO# 获取CAPTCHA图片
response = requests.get('http://example.com/captcha.jpg')
img = Image.open(BytesIO(response.content))# 使用Tesseract进行OCR识别
captcha_text = pytesseract.image_to_string(img)
print(f"识别的CAPTCHA文本: {captcha_text}")
7.1.3 拓展案例 1:使用深度学习模型识别复杂CAPTCHA
对于复杂的CAPTCHA,可以使用预先训练好的深度学习模型进行识别。这需要大量的标记数据来训练模型,或者使用现有的模型。
# 这是一个概念性示例,实际使用时需要根据具体模型进行调整
# 假设我们有一个训练好的模型 model.h5 可以加载来识别CAPTCHAfrom tensorflow.keras.models import load_model
from PIL import Image
import numpy as np# 加载模型
model = load_model('model.h5')# 加载并预处理CAPTCHA图像
img = Image.open('captcha.jpg').convert('L') # 转换为灰度图像
img = np.resize(img, (1, 28, 28, 1)) # 调整大小和维度以匹配模型# 预测
prediction = model.predict(img)
captcha_text = ''.join([str(np.argmax(i)) for i in prediction])
print(f"识别的CAPTCHA文本: {captcha_text}")
7.1.4 拓展案例 2:集成第三方 CAPTCHA 解决服务
当自动化方法不可行或不够准确时,可以使用第三方服务来解决CAPTCHA。
import requests# 使用2Captcha服务解决CAPTCHA
api_key = 'YOUR_2CAPTCHA_API_KEY'
captcha_file = 'captcha.jpg'
with open(captcha_file, 'rb') as file:response = requests.post(f'http://2captcha.com/in.php?key={api_key}',files={'file': file})
if response.ok:request_id = response.text.split('|')[1]# 检索解决结果resolve_url = f'http://2captcha.com/res.php?key={api_key}&action=get&id={request_id}'for _ in range(5): # 尝试5次获取结果solve_response = requests.get(resolve_url)if solve_response.text.startswith('OK'):print(f"CAPTCHA解决方案: {solve_response.text.split('|')[1]}")break
通过这些方法,我们可以在不同情况下尝试绕过CAPTCHA的挑战。重要的是要记住,我们应当尊重网站的防爬策略,合理合法地使用这些技术。在使用第三方服务时,也要考虑到成本和响应时间的因素。

7.2 IP 轮换与代理的使用
在网络爬虫的探险旅程中,使用代理IP轮换是一种巧妙的伪装技术,可以帮助你的爬虫避开网站的IP封锁,就像是变色龙一样在数据丛林中隐身。
7.2.1 重点基础知识讲解
- 代理IP的选择:选择高质量的代理IP是关键。这些代理可以是公开的代理,也可以是付费的私有代理服务,关键在于稳定性和匿名度。
- 轮换策略:合理地轮换代理IP可以避免因频繁请求同一网站而被封禁。轮换策略可以基于时间、请求次数等因素来设置。
- 请求头设置:使用代理时,还应注意修改请求头中的一些字段,如
User-Agent,以更好地模拟正常用户的行为。 - 错误处理:在使用代理IP时,可能会遇到代理失效的情况,合理的错误处理和重试机制是必不可少的。
7.2.2 重点案例:使用 requests 库与代理 IP 进行数据抓取
假设我们有一系列的代理IP,需要使用这些代理去抓取某个网站的数据。
import requests# 代理IP列表
proxies_list = [{"http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080"},{"http": "http://10.10.1.11:3128", "https": "http://10.10.1.11:1080"},# 更多代理IP
]url = "http://example.com/data"# 轮换使用代理IP抓取数据
for proxy in proxies_list:try:response = requests.get(url, proxies=proxy, timeout=5)print(f"成功获取数据: {response.text[:100]}")break # 成功获取数据后跳出循环except Exception as e:print(f"代理 {proxy} 请求失败,切换到下一个代理。错误信息:{e}")
7.2.3 拓展案例 1:结合 Scrapy 和 Scrapy-Redis 使用代理
当使用Scrapy框架进行大规模爬虫开发时,结合Scrapy-Redis和代理池可以有效实现分布式爬虫和IP轮换。
# 假设你的Scrapy项目中有一个中间件或代理池服务来管理代理IP
class ProxyMiddleware(object):def process_request(self, request, spider):# 从代理池中获取代理IPproxy = get_proxy_from_pool() # 假设的函数,需要根据实际情况实现request.meta['proxy'] = proxy
7.2.4 拓展案例 2:自动切换代理 IP
在一些情况下,可能需要根据请求的成功与否自动切换代理IP。
import requests# 初始化代理IP列表和当前代理索引
proxies_list = [...]
current_proxy_index = 0def fetch_with_auto_rotate_proxy(url):global current_proxy_indexwhile current_proxy_index < len(proxies_list):proxy = proxies_list[current_proxy_index]try:response = requests.get(url, proxies=proxy, timeout=5)print(f"使用代理 {proxy} 成功获取数据")return responseexcept:print(f"使用代理 {proxy} 请求失败,尝试下一个代理")current_proxy_index += 1print("所有代理尝试完毕,未能成功获取数据")url = "http://example.com/data"
fetch_with_auto_rotate_proxy(url)
通过这些策略和案例的学习,我们可以更加灵活地使用代理IP来提高爬虫的隐蔽性和效率。记住,使用代理时要遵循网站的规定,合理合法地收集数据。

7.3 用户代理和 Cookie 的管理
在数据侠的工具箱里,用户代理(User-Agent)和 Cookie 的管理是进行有效的网络爬虫活动时不可或缺的技能。这些工具帮助我们的爬虫更像一个普通用户而不是一个机器人,从而更加自由地在数据的世界里遨游。
7.3.1 重点基础知识讲解
- 用户代理(User-Agent):用户代理是 HTTP 请求的一部分,它告诉服务器是哪种类型的设备(如桌面、手机)、操作系统和浏览器正在发起请求。通过更换用户代理,爬虫可以伪装成不同的浏览器或设备。
- Cookie 管理:Cookie 是服务器发送到用户浏览器并保存的小数据片段,用于追踪浏览器会话。管理 Cookie 可以帮助爬虫维持登录状态,访问需要认证的数据。
7.3.2 重点案例:使用 requests 库设置用户代理和 Cookie
让我们来看一个使用 Python requests 库,同时设置用户代理和 Cookie 来抓取需要登录后才能访问的页面的例子。
import requestsurl = "http://example.com/secret-data"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
cookies = {'session_token': 'YOUR_SESSION_TOKEN_HERE'
}response = requests.get(url, headers=headers, cookies=cookies)
print(response.text)
7.3.3 拓展案例 1:动态更换用户代理
为了让爬虫在每次请求时都使用不同的用户代理,我们可以使用 fake_useragent 库来动态生成用户代理字符串。
from fake_useragent import UserAgent
import requestsua = UserAgent()
url = "http://example.com"# 每次请求使用不同的用户代理
for _ in range(5):headers = {'User-Agent': ua.random}response = requests.get(url, headers=headers)print(f"使用用户代理 {headers['User-Agent']} 访问 {url}")
7.3.4 拓展案例 2:使用 session 对象管理 Cookie
requests 库的 Session 对象可以自动管理 Cookie,使得爬虫在多次请求之间保持某些状态(如登录状态)。
import requests# 创建一个 session 对象
session = requests.Session()# 首先登录以获取 Cookie
login_url = "http://example.com/login"
credentials = {'username': 'user', 'password': 'pass'}
session.post(login_url, data=credentials)# 现在 session 中已经保存了登录状态,我们可以访问需要认证的页面
secret_url = "http://example.com/secret-data"
response = session.get(secret_url)
print(response.text)
通过掌握用户代理和 Cookie 的管理技巧,你的爬虫将能够更加自由地在网络世界中探索,获取那些隐藏的、需要认证才能访问的珍贵数据。记得,使用这些技术时要遵守目标网站的使用条款,尊重用户数据的隐私和安全。